高性能编程之分支预测
文章目录
- CPU Instruction pipelining(为什么需要分支预测器)
- 减缓分支技术
- 使用计算方法代替branch
- 可预测的分支概率(Likely/Unlikely)
- CMOV 指令(条件移动)
- 查表法
- 循环展开
- 总结
- 参考文献
CPU Instruction pipelining(为什么需要分支预测器)
果要解释这个问题,我们需要先了解现代处理器的工作原理,任何一条指令在CPU中的执行都必须经历如下这些步骤:
- 取指(Fetch):取指阶段从存储器读取指令字节,地址为程序计数器(PC)的值。
- 译码(Decode):译码阶段完成指令的翻译,从寄存器文件读入最多两个操作数。
- 执行(Execute):执行指令,如果是执行的是一条跳转指令的话,这个阶段会检查条件码和分支条件,决定是否选择分支。
- 写回(Write Back):将指令执行结果保存到内存中。
现代处理器使用流水线架构主要是为了提高程序执行效率,比如在第一条指令进入执行阶段时,第二条指令已经开始译码,第三条指令处于取指阶段……相对于第一条指令完全执行完并写回内存再开始第二条指令的取指,效率提高了很多倍。当然,现代处理器一般流水线深度高达10-31级,对程序执行速度有着显著提高。
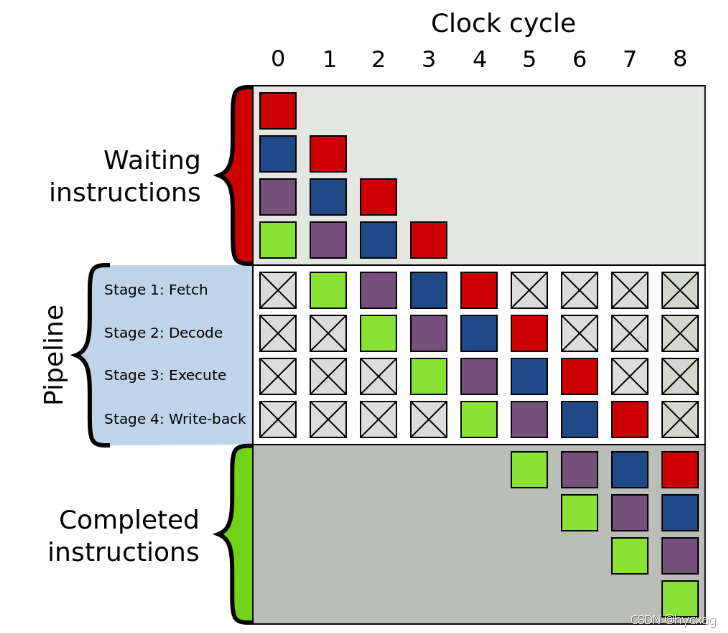
上述流水线架构对于顺序执行的命令,效果提高显著,但是遇到跳转命令时效率便会急剧下降,对于分支跳转指令,我们在执行完该指令之前是不知道是否发生跳转的,也就是说,我们在分支指令执行完之前,我们无法确定分支指令的下一条指令的地址,所以也就没法把分支指令的下一条命令放入流水线中,只能等待分支指令执行完毕才能开始下一条命令的取指步骤,所以流水线中就会出现气泡(Bubble),这会大大降低流水线的吞吐能力。
为了解决上述问题,分支预测器应运而生。当指令执行到分支跳转指令时,CPU不再是空等待分支跳转指令执行完毕给出下一条命令的地址,而是根据模型预测分支是否发生跳转以及跳转到哪里,CPU将预测到的指令直接放入流水线,去执行指令的取指、译码等工作。
当分支跳转指令完成执行阶段后,给出是否跳转的结果,CPU即可判断分支跳转预测是否正确,如果指令执行后的跳转结果与分支预测器预测结果相一致,则流水线继续往下执行,如果发现分支预测结果出现错误,则需要清空流水线,将前面不该进入流水线的指令清空,然后将正确的指令放入流水线重新执行。
于是出现了在编译器上面做分支预测,以及在CPU上面做分支预测。不管在哪里做分支预测,总会有预测失败的时候。在程序端我们也可以做到减少分支,从而提供代买的吞吐,下面重点介绍程序代码中减少分支代码技术
减缓分支技术
分支预测失败(Branch Misprediction)会导致 CPU 流水线清空,损失 10~20 个时钟周期,对性能影响极大。下面提供了一系列方法来减少分支。
使用计算方法代替branch
- 使用算术运算替代if-else
// 传统分支写法
int max(int a, int b) {
if (a > b) return a;
else return b;
}
// 无分支写法(CMOV 或掩码)
int max(int a, int b) {
return a * (a > b) + b * (a <= b); // 逻辑运算代替分支
}
- 利用位运算方法替代if
// 计算绝对值(无分支)
int abs(int x) {
int mask = x >> 31; // 如果 x < 0,mask = 0xFFFFFFFF(-1)
return (x ^ mask) - mask; // 等同于 x < 0 ? -x : x
}
我们来看传统的二分查找方法:
int binary_search(int* arr, int n, int target) {
int left = 0, right = n - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (arr[mid] == target) return mid; // 分支 1
if (arr[mid] < target) left = mid + 1; // 分支 2
else right = mid - 1; // 分支 3
}
return -1;
}
上述循环语句中存在这三个分支语句,为了提供分支预测性:我们可以将bool转为int(false为0,true为1) 方式
#include <stdint.h> // 用于 int64_t
int branchless_binary_search(int* arr, int n, int target) {
int64_t left = 0, right = n - 1;
while (left <= right) {
int mid = (left + right) >> 1; // 等价于 (left + right) / 2
int cmp = (arr[mid] <= target) - 1; // arr[mid] <= target → 0 or -1
left = mid + 1 + cmp; // if (arr[mid] < target) → left = mid + 1
right = mid + cmp; // else → right = mid - 1
}
return (right >= 0 && arr[right] == target) ? right : -1;
}
bool转为int(false为0,true为1)虽然任何语言都是未定义行为,但是在主流编译器中都实现成false为0,true为1。因此可以使用
上述二分查找代码我们还可以进一步优化,核心思想:使用 符号位掩码
int branchless_binary_search_v2(int* arr, int n, int target) {
int64_t left = 0, right = n - 1;
while (left <= right) {
int mid = (left + right) >> 1;
int cmp = (arr[mid] - target) >> 31; // 取符号位(0 or -1)
left = mid + 1 + cmp; // if (arr[mid] < target) → left = mid + 1
right = mid + ~cmp; // else → right = mid - 1
}
return (right >= 0 && arr[right] == target) ? right : -1;
}
SIMD(如 SSE/AVX)或位运算掩码:
// 传统分支
void clamp(int* arr, int n, int min, int max) {
for (int i = 0; i < n; i++) {
if (arr[i] < min) arr[i] = min;
else if (arr[i] > max) arr[i] = max;
}
}
// 无分支掩码写法
void clamp(int* arr, int n, int min, int max) {
for (int i = 0; i < n; i++) {
arr[i] = (arr[i] < min) * min + (arr[i] > max) * max
+ (arr[i] >= min && arr[i] <= max) * arr[i];
}
}
可预测的分支概率(Likely/Unlikely)
如果分支概率可预测,用 __builtin_expect 提示编译器。当然C++20已将likely/unlikely纳入条件提示中了
#define likely(x) __builtin_expect(!!(x), 1)
#define unlikely(x) __builtin_expect(!!(x), 0)
if (likely(condition)) { // 告诉编译器 condition 大概率成立
// 快速路径
} else {
// 慢速路径
}
它适用于错误处理(unlikely 标记罕见分支)以及循环中的热点路径(likely 标记高频分支)。
CMOV 指令(条件移动)
在 C 语言中,if-else 和 ?:(三目运算符)都可以用来做条件判断,但它们的底层实现和性能表现有所不同。原因在于:未优化时,?: 可能更快
- ?: 更倾向于编译成无分支代码(如 CMOV)。
- if-else 可能编译成跳转指令(JMP),导致分支预测失败惩罚(~10-20 CPU 周期)。
if-else 和 ?: 在开启优化(如 -O2 / -O3)后,生成的汇编代码通常相同。
在某些情况下if-else 可能更优,看如下代码
// 三目运算符(两个函数都会调用!)
int val = (cond) ? foo() : bar();
// if-else(只调用一个函数)
int val;
if (cond) val = foo();
else val = bar();
如果 A 或 B 是 复杂计算(如函数调用),?: 会 全部计算,而 if-else 只计算符合条件的部分
CMOV(Conditional Move)是 x86/x86-64 架构提供的一种 无分支条件赋值指令,它能在 不引入跳转 的情况下,根据标志位(Flags)决定是否执行数据移动操作。它的核心作用是 避免分支预测失败带来的性能惩罚,适用于关键路径上的条件逻辑优化。
查表法
如果分支逻辑可以枚举,用 数组查表 代替 switch-case 或 if-else:
// 传统分支写法
char getChar(int type) {
if (type == 0) return 'A';
else if (type == 1) return 'B';
else return '?';
}
// 无分支查表法
char getChar(int type) {
const char table[] = {'A', 'B', '?'};
return table[(type >= 0 && type < 2) ? type : 2];
}
进一步语言中的switch的实现原理其一也用到查表方法。因此需要合理选择switch和if语句。
循环展开
减少循环内的分支次数:
// 传统循环(每次迭代都有分支)
for (int i = 0; i < n; i++) {
sum += data[i];
}
// 循环展开(减少分支)
for (int i = 0; i < n; i += 4) {
sum += data[i];
sum += data[i+1];
sum += data[i+2];
sum += data[i+3];
}
总结
在分支预测中,优先用无分支技术(如 CMOV、位运算、查表)。进一步避免高频小分支(如循环内的 if)。 可以利用提示编译器分支概率(likely/unlikely)。最后办法SIMD 和循环展开适用于数据并行场景。
参考文献
浅谈 CPU 分支预测技术