实时语音交互数字人VideoChat,可自定义形象与音色,支持音色克隆,首包延迟低至3s
简介
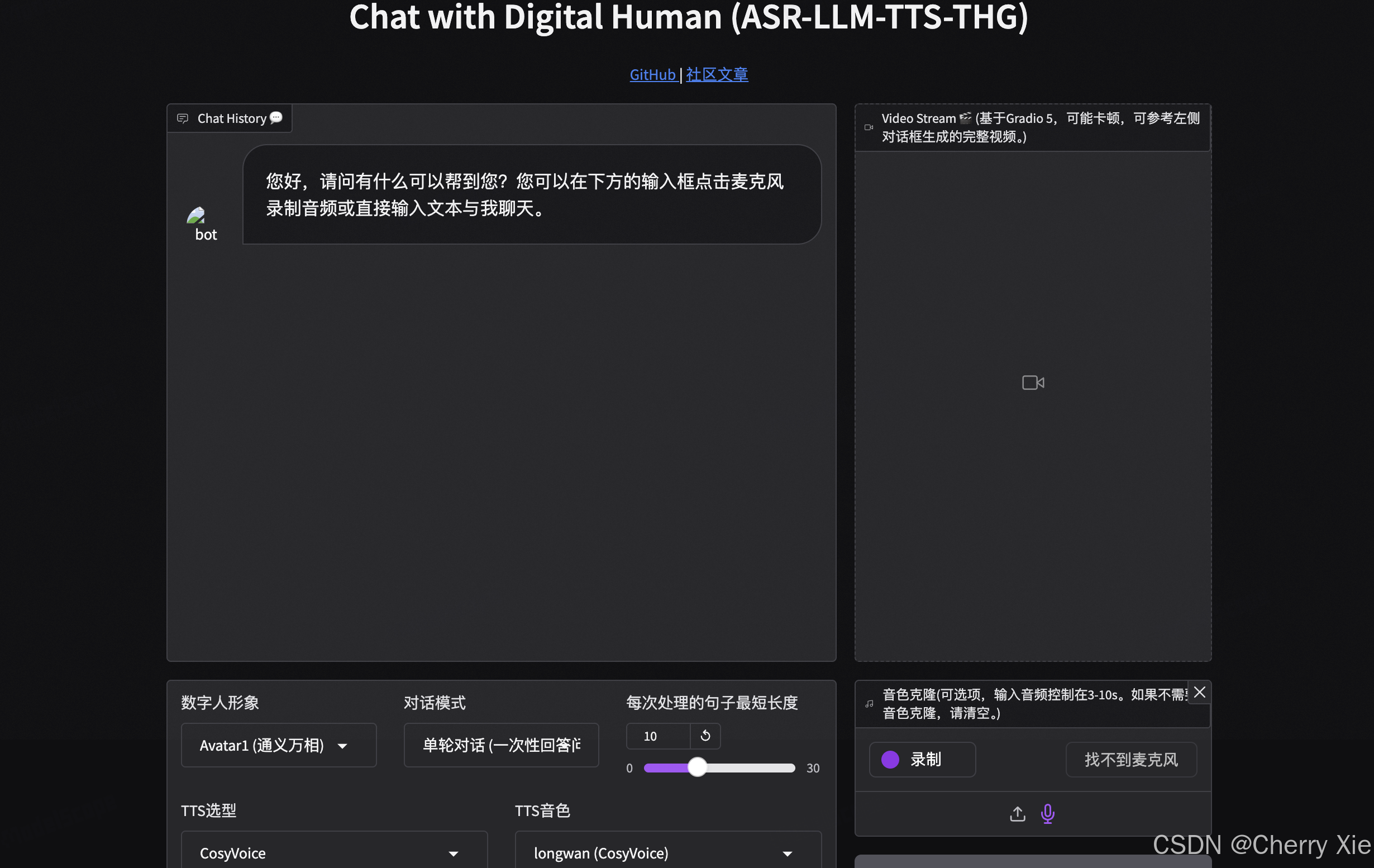
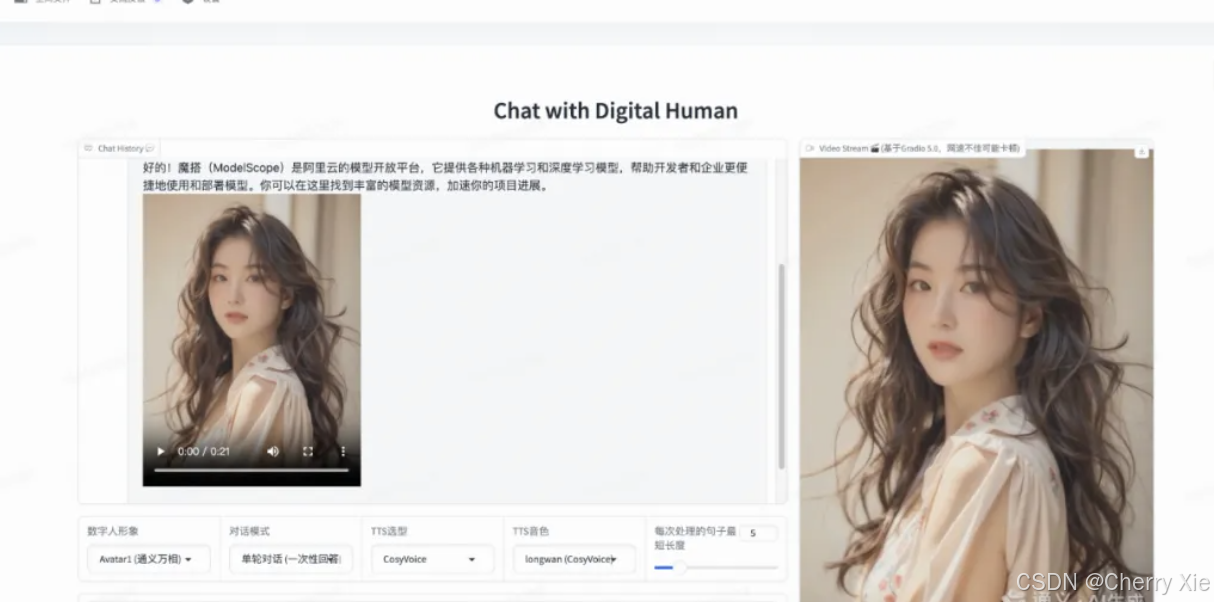
实时语音交互数字人,支持端到端语音方案(GLM-4-Voice - THG)和级联方案(ASR-LLM-TTS-THG)。用户可通过麦克风或文本输入,与数字人进行语音或视频交互。
目前支持的功能
- 支持自定义形象
- TTS模块添加音色克隆功能
- TTS支持edge-tts、cosyvoice、GPT-SoVITS-TTS
- LLM模块添加qwen本地推理
- 支持GLM-4-Voice,提供ASR-LLM-TTS-THG和MLLM-THG两种生成方式
- 支持funasr
技术选型

显存要求
-
级联方案(ASR-LLM-TTS-THG):约8G,首包约3s。
-
端到端语音方案(MLLM-THG):约20G,首包约7s。
环境配置
- ubuntu 22.04
- python 3.10
- pCUDA 12.2
- ptorch 2.3.0
$ git lfs install
$ git clone https://www.modelscope.cn/studios/AI-ModelScope/video_chat.git
$ conda create -n metahuman python=3.10
$ conda activate metahuman
$ cd video_chat
$ pip install -r requirements.txt
权重下载
创空间下载(推荐)
创空间仓库已设置git lfs追踪权重文件,如果是通过
git clone https://www.modelscope.cn/studios/AI-ModelScope/video_chat.git
克隆,则无需额外配置
手动下载
可参考:https://github.com/TMElyralab/MuseTalk/blob/main/README.md#download-weights
目录如下:
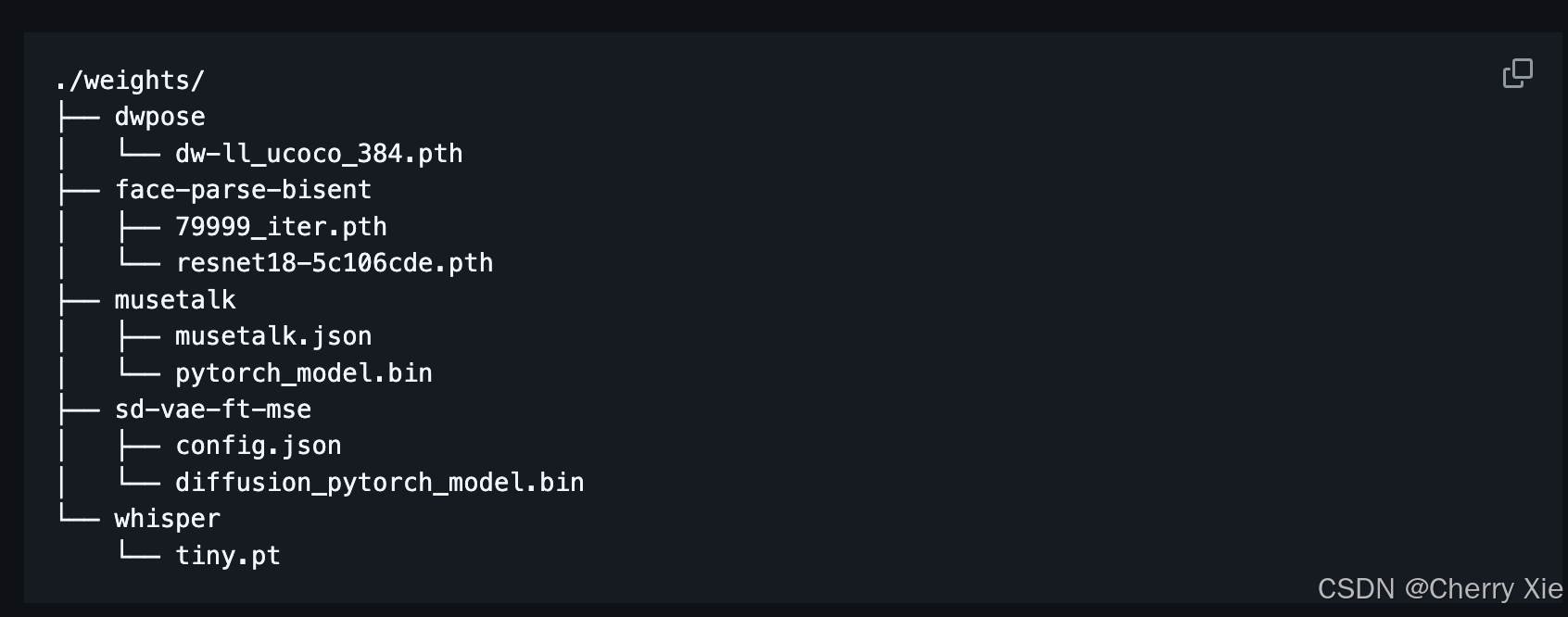
更详细的信息可见官方github的readme.md文件。
看看效果
相关文献
在线体验地址:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
项目地址:https://github.com/Henry-23/VideoChat/tree/master?tab=readme-ov-file