Spark-SQL
一. Spark-SQL的概述
1. 什么是Spark-SQL
Spark-SQL 是 Spark 用于结构化数据处理的 Spark 模块。
Spark-SQL 的前身是 Shark,Shark是给熟悉 RDBMS 但又不理解 MapReduce 的技术人员提供的快速上手的工具。
其中 Shark 是伯克利实验室 Spark 生态环境的组件之一,是基于 Hive 所开发的工具,它修改了内存管理、物理计划、执行三个模块,并使之能运行在 Spark 引擎上。
Shark 的出现,使得 SQL-on-Hadoop 的性能比 Hive 有了 10-100 倍的提高。
但是,随着 Spark 的发展,Shark 对于 Hive 的太多依赖,制约了 Spark 的 One Stack Rule Them All 的既定方针,制约了 Spark 各个组件的相互集成,所以提出了 SparkSQL 项目。
数据兼容方面 SparkSQL 不但兼容 Hive,还可以从 RDD、parquet 文件、JSON 文件中 获取数据,未来版本甚至支持获取 RDBMS 数据以及 cassandra 等 NOSQL 数据;
性能优化方面 除了采取 In-Memory Columnar Storage、byte-code generation 等优化技术 外、将会引进 Cost Model 对查询进行动态评估、获取最佳物理计划等等;
组件扩展方面无论是 SQL 的语法解析器、分析器还是优化器都可以重新定义,进行扩 展。
所以实际工作中,基本上采用的就是 SparkSQL。Spark SQL 为了简化 RDD 的开发, 提高开发效率,提供了 2 个编程抽象,类似 Spark Core 中的 RDD:DataFrame和DataSet
2. Spark-SQL的特点
1)易整和
2)统一的数据访问
3)兼容Hive
4)标准数据连接
3. 什么是DataFrame
在 Spark 中,DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库中 的二维表格。DataFrame 与 RDD 的主要区别在于,前者带有 schema 元信息,即 DataFrame 所表示的二维表数据集的每一列都带有名称和类型。这使得 Spark SQL 得以洞察更多的结构信息,从而对藏于 DataFrame 背后的数据源以及作用于 DataFrame 之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。反观 RDD,由于无从得知所存数据元素的具体内部结构,Spark Core 只能在 stage 层面进行简单、通用的流水线优化。
4. 什么是DataSet
DataSet 是分布式数据集合。DataSet 是 Spark 1.6 中添加的一个新抽象,是 DataFrame 的一个扩展。它提供了 RDD 的优势以及 Spark SQL 优化执行引擎的优点。DataSet 也可以使用功能性的转换
二. Spark-SQl核心编程
1. 从 Spark 数据源进行创建DataFrame
1.1 在 spark 的 bin/data 目录中创建 user.json 文件其中包含如下数据:
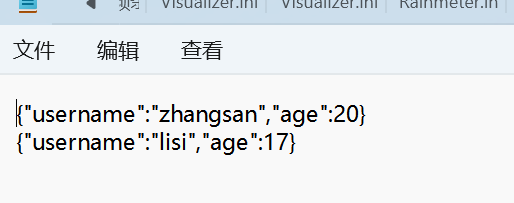
{"username":"zhangsan","age":20}
{"username":"lisi","age":17}
1.2 读取 json 文件创建 DataFrame
![]()
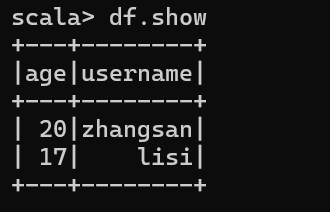
1.3 查看表格展示数据
2. SQL语法创建DataFrame
2.1 读取 JSON 文件创建 DataFrame

2.2对 DataFrame 创建一个临时表
![]()
2.3 查询全表
![]()
2.4 展示数据
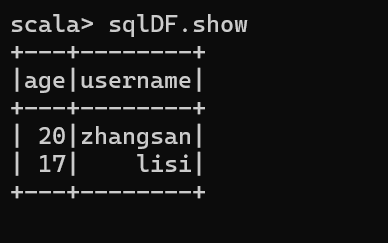
3 DSL语法创建DataFrame
3.1 创建一个 DataFrame 查看表的Shaema信息
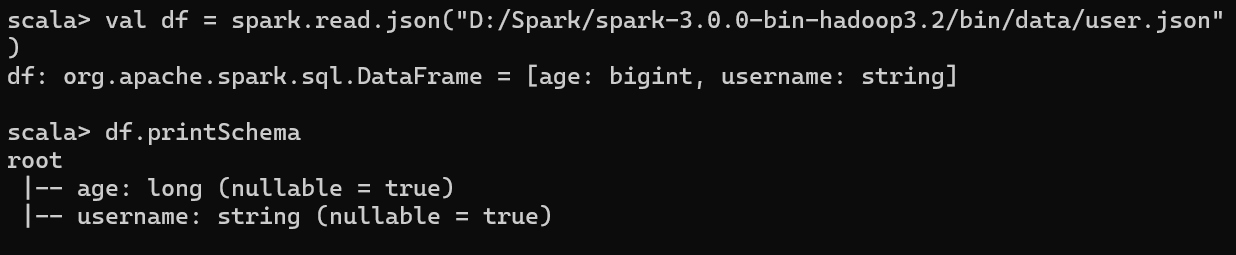
3.2 只查看"username"列数据
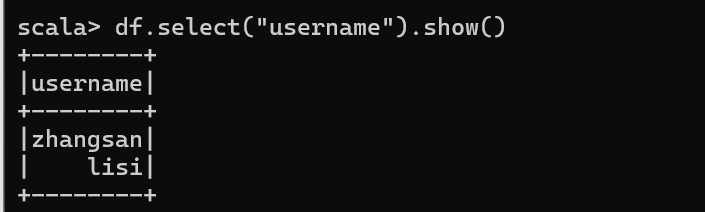
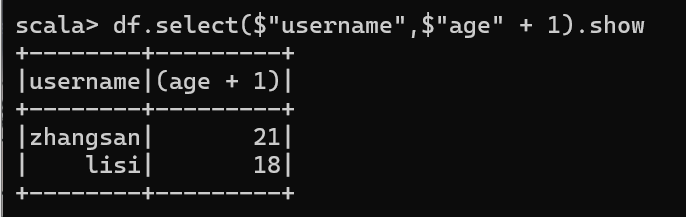
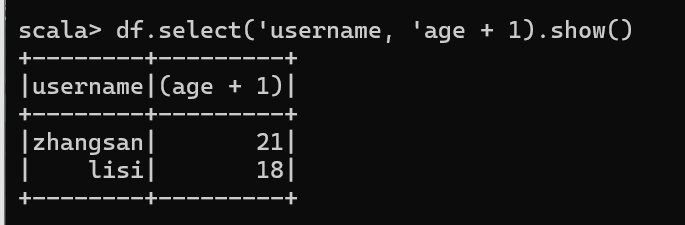
3.3 查看"username"列数据以及"age+1"数据
涉及到运算的时候, 每列都必须使用$, 或者采用引号表达式:单引号+字段名
1)每列使用$
2)采用引号表达式
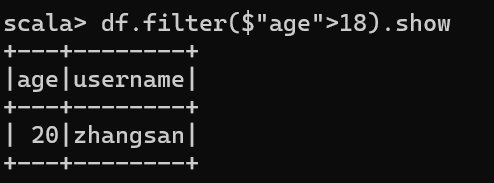
3.4 查看"age"大于"18"的数据
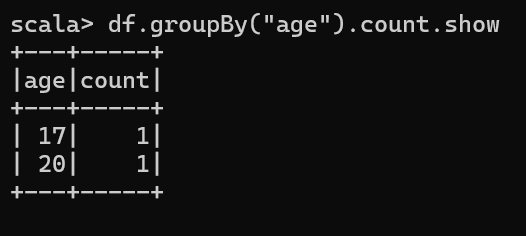
3.5 按照"age"分组,查看数据条数
4 RDD 转换为 DataFrame
4.1 先在bin/data目录下创建id.txt文件
4.2 读取id.txt文件创建idRDD
![]()
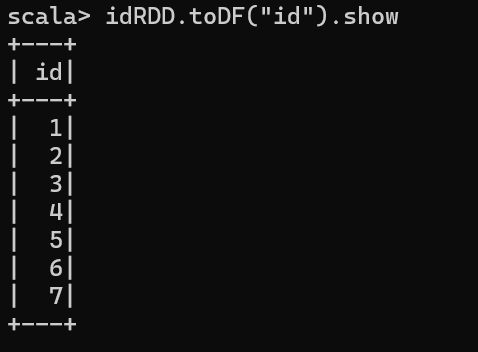
4.3 查看表中的id数据
4.4 创建一个名为 User 的 case class

4.5 创建一个 Spark分布式数据集 ,把 RDD 里的数据转换为User对象,再将其转换为 DataFrame,最后展示 DataFrame 的内容。

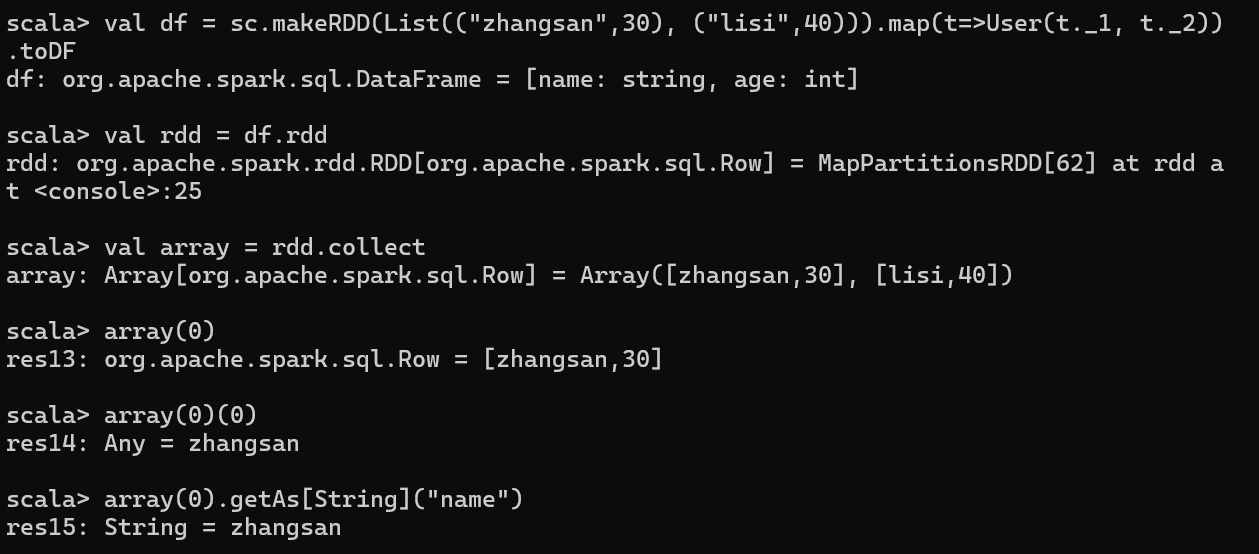
5 DataFrame 转换为 RDD
实例
6. DataSet
DataSet 是具有强类型的数据集合,需要提供对应的类型信息。
6.1 创建 DataSet
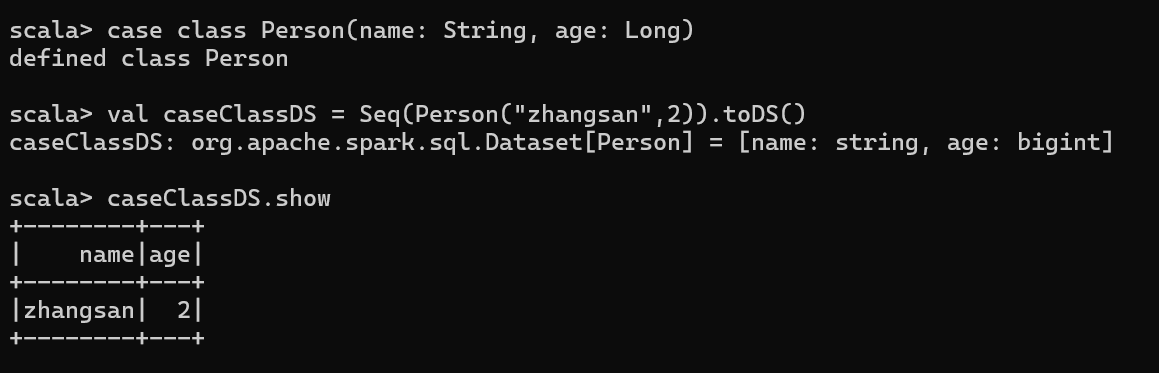
1)使用样例类序列创建 DataSet
2)使用基本类型的序列创建 DataSet 查看数据
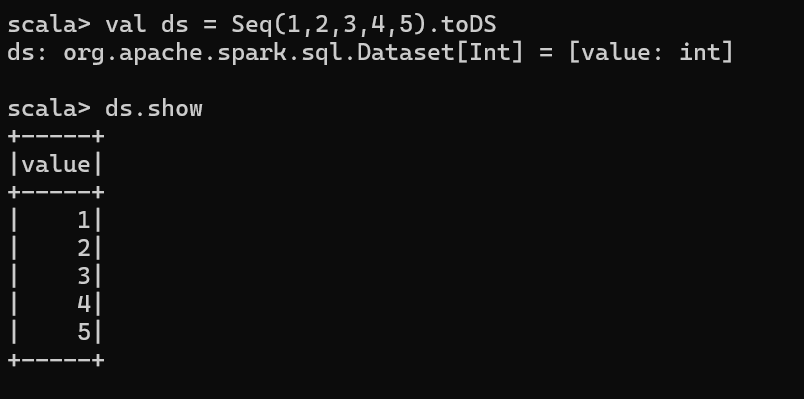
RDD 转换为 DataSet
SparkSQL 能够自动将包含有 case 类的 RDD 转换成 DataSet,case 类定义了 table 的结 构,case 类属性通过反射变成了表的列名。Case 类可以包含诸如 Seq 或者 Array 等复杂的结构。
实例

DataSet 转换为 RDD
实例

DataFrame 和 DataSet 转换
DataFrame 其实是 DataSet 的特例,所以它们之间是可以互相转换的。
DataFrame 转换为 DataSet
实例
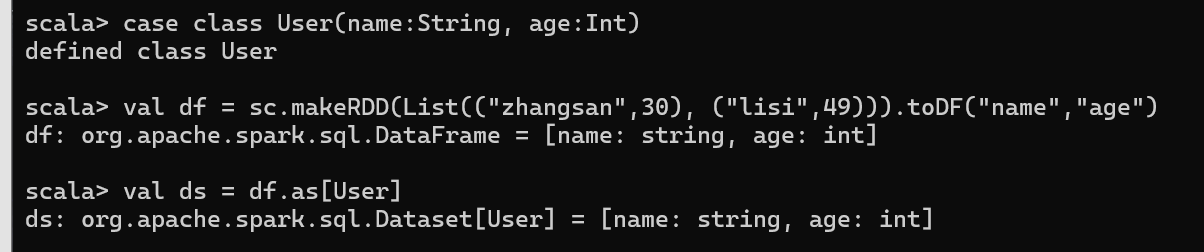
DataSet 转换为 DataFrame
实例

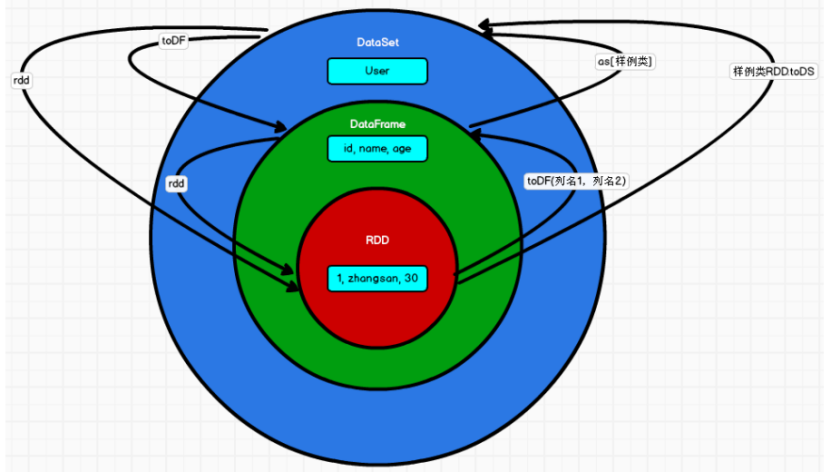
RDD、DataFrame、DataSet 三者的关系
1. 三者的共性
RDD、DataFrame、DataSet 全都是 spark 平台下的分布式弹性数据集,为处理超大型数
据提供便利;
三者都有惰性机制,在进行创建、转换,如 map 方法时,不会立即执行,只有在遇到
Action 如 foreach 时,三者才会开始遍历运算;
三者有许多共同的函数,如 filter,排序等;
在对 DataFrame 和 Dataset 进行操作许多操作都需要这个包:
import spark.implicits._(在创建好 SparkSession 对象后尽量直接导入)
三者都会根据 Spark 的内存情况自动缓存运算,这样即使数据量很大,也不用担心会
内存溢出
三者都有分区的概念
DataFrame 和 DataSet 均可使用模式匹配获取各个字段的值和类型
2. 三者的区别
1)RDD
RDD 一般和 spark mllib 同时使用
RDD 不支持 sparksql 操作
2) DataFrame
与 RDD 和 Dataset 不同,DataFrame 每一行的类型固定为Row,每一列的值没法直
接访问,只有通过解析才能获取各个字段的值
DataFrame 与 DataSet 一般不与 spark mllib 同时使用
DataFrame 与 DataSet 均支持 SparkSQL 的操作
DataFrame 与 DataSet 支持一些特别方便的保存方式
3) DataSet
Dataset 和 DataFrame 拥有完全相同的成员函数,区别只是每一行的数据类型不同。
DataFrame 其实就是 DataSet 的一个特例 type DataFrame = Dataset[Row]
DataFrame 也可以叫 Dataset[Row],每一行的类型是 Row,不解析,每一行究竟有哪些字段
三者转换图如下: