多模态融合学习(九)——PIAFusion 武汉大学马佳义团队(一)
更了很多期关于红外和可见光融合的论文了,现在必须要介绍一下国内的武汉大学马佳义团队的工作,在这一领域个人感觉是国内名列前茅的大组。
论文链接:https://www.sciencedirect.com/science/article/abs/pii/S156625352200032X
github:https://github.com/Linfeng-Tang/PIAFusion
题目:PIAFusion: A progressive infrared and visible image fusion network based on illumination aware (一种基于光照感知的渐进式红外与可见光图像融合网络)
目录
一.摘要
1.1 摘要翻译
1.2 摘要解析
研究背景与问题:
PIAFusion 的创新点:
方法优势:
二. Introduction
2.1 Introduction翻译
2.2 Introduction 解析
1. 背景与动机
2. 传统方法的局限性
3. 数据驱动方法的兴起
4. 当前挑战
5. PIAFusion 的创新
1. 红外与可见光图像融合
1.1. 传统图像融合
1.2. 基于AE的图像融合
1.3. 基于CNN的图像融合
1.4. 基于GAN的图像融合
2. 基于光照感知的视觉应用
1. 红外与可见光图像融合综述
1.1 传统方法
1.2 基于AE的方法
1.3 基于CNN的方法
1.4 基于GAN的方法
2. 基于光照感知的视觉应用
3. 本文的定位
四.方法
4.1 方法翻译
1. 问题分析
2. 损失函数
2.1. 渐进式融合网络的损失函数
2.2. 光照感知子网络的损失函数
3. 网络架构
3.1. 渐进式融合网络架构
3.2. 光照感知子网络架构
4.2 方法解析
1. 问题分析
评价
2. 损失函数
2.1 渐进式融合网络损失
2.2 光照感知子网络损失
评价
3. 网络架构
3.1 渐进式融合网络
3.2 光照感知子网络
4. 技术优势与创新
五.实验
5.1 实验翻译
1. 数据集构建
2. 实验配置
3. 实现细节
4. 比较实验
4.1. 定性结果
4.2. 定量结果
5. 泛化实验
5.1. 定性结果
5.2. 定量结果
6. 效率比较
7. 自适应特征选择
8. 语义分割应用
9. 消融研究
9.1. 光照感知损失分析
9.2. 跨模态差异感知融合模块分析
5.2实验解析
1. 数据集构建
2. 实验配置
3. 实现细节
4. 比较实验
4.1 定性结果
4.2 定量结果
5. 泛化实验
5.1 定性结果
5.2 定量结果
6. 效率比较
7. 自适应特征选择
8. 语义分割应用
9. 消融研究
9.1 光照感知损失
9.2 CMDAF模块
六. 结论
一.摘要
1.1 摘要翻译
红外与可见光图像融合旨在合成一幅单一的融合图像,即使在极端光照条件下也能包含显著目标和丰富的纹理细节。然而,现有的图像融合算法在建模过程中未能考虑光照因素。在本文中,我们提出了一种基于光照感知的渐进式图像融合网络,称为 PIAFusion,它能够自适应地维持显著目标的强度分布并保留背景中的纹理信息。具体来说,我们设计了一个光照感知子网络来估计光照分布并计算光照概率。此外,我们利用光照概率构建了光照感知损失函数,以指导融合网络的训练。跨模态差异感知融合模块和半程融合策略在光照感知损失的约束下,完全整合了源图像中的共有信息和互补信息。此外,我们发布了一个新的红外与可见光图像融合基准数据集,即多光谱道路场景(Multi-Spectral Road Scenarios,可在 https://github.com/Linfeng-Tang/MSRS 获取),以支持网络训练和全面评估。大量实验证明,我们的方法在目标维持和纹理保留方面优于最先进的替代方案。特别是,我们的渐进式融合框架能够根据光照条件全天候整合源图像中的有意义信息。此外,将其应用于语义分割展示了 PIAFusion 在高级视觉任务中的潜力。我们的代码将在 https://github.com/Linfeng-Tang/PIAFusion 上提供。
1.2 摘要解析
研究背景与问题:
红外与可见光图像融合的目标是生成一幅综合图像,结合红外图像的热信息(如显著目标的轮廓)和可见光图像的视觉细节(如纹理)。然而,光照条件(如白天强光或夜晚无光)的变化显著影响融合效果。现有的融合算法通常假设光照条件恒定或忽略其影响,导致在极端环境下融合图像质量下降,例如目标丢失或纹理模糊。
PIAFusion 的创新点:
- 光照感知子网络(Illumination-Aware Sub-Network)
- 功能:该子网络估计输入图像的光照分布并输出光照概率。这一概率反映了当前场景的光照强度和特性(如强光、低光)。
- 意义:使网络能够根据光照条件动态调整融合策略,避免“一刀切”式的融合。
- 光照感知损失(Illumination-Aware Loss)
- 作用:利用光照概率设计损失函数,指导网络优化。例如,在低光照下可能更强调红外目标的强度,在强光下更注重可见光纹理的保留。
- 优势:增强了模型对光照变化的鲁棒性,确保融合图像在不同场景下均保持高质量。
- 跨模态差异感知融合模块(Cross-Modality Differential Aware Fusion Module)
- 功能:识别红外与可见光图像的共有信息(如目标边缘)和互补信息(如红外热信号与可见光颜色)。
- 意义:避免信息冗余或丢失,最大化融合图像的信息量。
- 半程融合策略(Halfway Fusion Strategy)
- 含义:融合过程分阶段进行,可能先融合低级特征(如边缘),再逐步整合高级特征(如语义信息)。
- 优点:渐进式融合减少了直接融合可能引入的噪声或伪影,提升了细节保留能力。
- 新数据集:Multi-Spectral Road Scenarios (MSRS)
- 内容:多光谱道路场景数据集,包含多种光照条件下的红外与可见光图像对。
- 价值:为训练和评估提供了标准化基准,尤其适合测试光照自适应能力。公开数据集还能推动领域研究。
方法优势:
- 全天候适应性:通过光照感知,PIAFusion 能在白天、夜晚等不同条件下有效工作。
- 目标与纹理平衡:显著目标(如车辆、行人)的强度分布和背景纹理(如道路细节)均得到优化。
- 高级任务潜力:应用于语义分割表明融合图像不仅视觉效果好,还能支持下游任务(如目标检测)。
二. Introduction
2.1 Introduction翻译
单一模态传感器或单一拍摄设置捕获的信息无法有效且全面地描述成像场景,这是由于硬件设备的理论和技术限制[1]。因此,图像融合技术应运而生,其目的是结合多模态传感器或不同拍摄设置下拍摄的互补信息。根据模态差异的存在与否,图像融合可分为多模态图像融合和数字摄影图像融合。在多模态图像融合任务中,红外与可见光图像融合因其源图像的充分互补性,已广泛应用于军事行动、目标检测[2]、跟踪[3]、行人重识别[4]和语义分割[5]。红外与可见光图像融合的典型应用如图1所示。
 可以注意到,红外图像能够有效突出热目标(如行人),但忽略其他物体(如静止的车辆和自行车),因为红外图像捕获的是物体发出的热辐射。因此,检测器无法从红外图像中检测到自行车,并可能将自行车误识别为行人。相反,可见光图像捕获的是反射信息,因此可以检测到自行车,但隐藏在黑暗或烟雾中的显著目标会被忽略。值得注意的是,与单一模态图像相比,融合图像能够检测到所有行人和更多的自行车,因为融合图像充分整合了源图像的互补信息。在过去几十年中,开发了许多图像融合技术,包括传统方法[8-10]和数据驱动方法[7,11,12]。传统方法利用数学变换将源图像转换到变换域,并在变换域中进行活跃度测量和设计融合规则以实现图像融合。传统图像融合技术包括基于多尺度分解的方法[13,14]、基于子空间聚类的方法[15]、基于稀疏表示的方法[16]、基于优化的方法[17]以及混合方法[18]。上述方法合成的图像能够在特定场景下满足后续任务的需求。然而,传统方法的发展目前正面临瓶颈。一方面,为了实现更出色的融合性能,传统方法采用的变换或表示变得越来越复杂,无法满足实时计算机应用的要求[19]。另一方面,手工设计的活跃度测量和融合规则无法适应复杂的场景。近年来,深度学习的繁荣激励图像融合社区探索数据驱动的图像融合方案。根据所使用的基线,主流数据驱动方法大致可分为三类,即基于自编码器(AE)的方法[6,20,21]、基于卷积神经网络(CNN)的方法[22-24]和基于生成对抗网络(GAN)的方法[7,25,26]。基于AE的方法首先在大规模自然图像数据集上训练自编码器作为特征提取器和图像重建器。然后,特征提取器用于从多模态图像中提取互补信息,并使用特定的融合规则(如拼接[24]、逐元素加法[27]、逐元素加权求和[6]和逐元素最大值[28])合并这些特征。最后,图像重建器负责从融合特征中重建融合图像。然而,基于AE的融合框架并非完全可学习的,因为使用了手工设计的融合规则来合并深度特征。因此,其他研究者专注于探索端到端的基于CNN的图像融合网络,这些网络依赖于优越的网络结构和精心设计的损失函数来确保融合性能。鉴于图像融合任务缺乏地面真值(ground truth),一些工作尝试将图像融合定义为生成器与判别器之间的博弈。更具体地说,他们通过约束融合图像与源图像之间的概率分布,强制融合图像具有丰富的纹理细节。需要强调的是,过于强烈的约束可能会在融合图像中引入人工纹理。尽管数据驱动的图像融合方法能够合成相对满意的融合结果,但仍有一些值得关注的障碍。首先,红外与可见光图像融合社区目前缺乏用于训练鲁棒融合网络的大型基准数据集。主流数据集(如TNO数据集[29]和RoadScene数据集[30])包含的图像对数量较少,且场景简单,尤其是TNO数据集。在这些数据集上训练的融合网络容易过拟合,无法应对更复杂的场景。因此,开发包含大量图像对的新基准数据集对于红外与可见光图像融合具有前景。此外,还存在一个关键问题,即光照不平衡从未被研究。光照不平衡指的是白天和夜间场景之间光照条件的差异[31]。
可以注意到,红外图像能够有效突出热目标(如行人),但忽略其他物体(如静止的车辆和自行车),因为红外图像捕获的是物体发出的热辐射。因此,检测器无法从红外图像中检测到自行车,并可能将自行车误识别为行人。相反,可见光图像捕获的是反射信息,因此可以检测到自行车,但隐藏在黑暗或烟雾中的显著目标会被忽略。值得注意的是,与单一模态图像相比,融合图像能够检测到所有行人和更多的自行车,因为融合图像充分整合了源图像的互补信息。在过去几十年中,开发了许多图像融合技术,包括传统方法[8-10]和数据驱动方法[7,11,12]。传统方法利用数学变换将源图像转换到变换域,并在变换域中进行活跃度测量和设计融合规则以实现图像融合。传统图像融合技术包括基于多尺度分解的方法[13,14]、基于子空间聚类的方法[15]、基于稀疏表示的方法[16]、基于优化的方法[17]以及混合方法[18]。上述方法合成的图像能够在特定场景下满足后续任务的需求。然而,传统方法的发展目前正面临瓶颈。一方面,为了实现更出色的融合性能,传统方法采用的变换或表示变得越来越复杂,无法满足实时计算机应用的要求[19]。另一方面,手工设计的活跃度测量和融合规则无法适应复杂的场景。近年来,深度学习的繁荣激励图像融合社区探索数据驱动的图像融合方案。根据所使用的基线,主流数据驱动方法大致可分为三类,即基于自编码器(AE)的方法[6,20,21]、基于卷积神经网络(CNN)的方法[22-24]和基于生成对抗网络(GAN)的方法[7,25,26]。基于AE的方法首先在大规模自然图像数据集上训练自编码器作为特征提取器和图像重建器。然后,特征提取器用于从多模态图像中提取互补信息,并使用特定的融合规则(如拼接[24]、逐元素加法[27]、逐元素加权求和[6]和逐元素最大值[28])合并这些特征。最后,图像重建器负责从融合特征中重建融合图像。然而,基于AE的融合框架并非完全可学习的,因为使用了手工设计的融合规则来合并深度特征。因此,其他研究者专注于探索端到端的基于CNN的图像融合网络,这些网络依赖于优越的网络结构和精心设计的损失函数来确保融合性能。鉴于图像融合任务缺乏地面真值(ground truth),一些工作尝试将图像融合定义为生成器与判别器之间的博弈。更具体地说,他们通过约束融合图像与源图像之间的概率分布,强制融合图像具有丰富的纹理细节。需要强调的是,过于强烈的约束可能会在融合图像中引入人工纹理。尽管数据驱动的图像融合方法能够合成相对满意的融合结果,但仍有一些值得关注的障碍。首先,红外与可见光图像融合社区目前缺乏用于训练鲁棒融合网络的大型基准数据集。主流数据集(如TNO数据集[29]和RoadScene数据集[30])包含的图像对数量较少,且场景简单,尤其是TNO数据集。在这些数据集上训练的融合网络容易过拟合,无法应对更复杂的场景。因此,开发包含大量图像对的新基准数据集对于红外与可见光图像融合具有前景。此外,还存在一个关键问题,即光照不平衡从未被研究。光照不平衡指的是白天和夜间场景之间光照条件的差异[31]。
 直观地,我们在图2中提供了一个示例来展示光照不平衡,可以观察到白天可见光图像具有比红外图像更清晰的纹理细节,但红外图像能够突出显著的行人。相比之下,夜间红外图像提供更多显著目标且纹理比可见光图像更丰富。不幸的是,现有方法[7,17,26]通常假设纹理仅存在于可见光图像中,这在白天场景中是合理的。然而,这种假设可能导致夜间融合图像丢失纹理细节。此外,基于AE的方法[6]使用不恰当的融合规则合并深度特征,可能会削弱纹理细节和显著目标。最后,现有技术更专注于如何融合图像/特征,而忽略了何时融合图像/特征。更具体地说,研究者致力于设计更精细的融合规则和损失函数以提升融合性能,但很少研究在哪个阶段融合图像/特征。目前,融合发生在两个阶段,即输入融合和半路融合。输入融合意味着将多模态输入级联在一起作为融合网络的输入[7,26],这可能导致网络无法融合源图像的语义信息。半路融合意味着使用特定的融合规则合并特征提取器提取的深度特征[6,20,22,24]。在这种情况下,所选融合规则至关重要,因为不恰当的规则无法充分整合互补信息。为了解决上述问题,我们提出了一种基于光照感知的渐进式红外与可见光图像融合框架,称为 PIAFusion,并发布了一个用于红外与可见光图像融合的大型基准数据集。首先,我们从现有的 MFNet 数据集[5]中收集了大量红外与可见光图像对,该数据集是为多模态图像语义分割拍摄的。MFNet 数据集包含大量对比度和信噪比较低的红外图像以及一些未对齐的图像对。因此,我们对红外图像进行锐化和增强,并移除未对齐的图像对。随后,我们设计了一个光照感知子网络来评估光照条件。更具体地说,预训练的光照感知子网络计算当前场景是白天还是夜间的概率。然后,这些概率用于构建光照感知损失,以指导融合网络的训练。最后,一个包含跨模态差异感知融合(CMDAF)模块的渐进式特征提取器被用于充分提取和融合多模态图像中的互补信息。此后,互补特征和共同特征通过半路融合方式融合,图像重建器将融合特征转换为融合图像域。在光照感知损失的指导下,我们的融合框架能够根据光照条件自适应地整合关键信息,如显著目标和纹理细节。此外,CMDAF 模块和半路融合策略使我们的网络能够在不同阶段融合共同和互补信息。因此,无论光照条件如何,我们的融合图像都能充分保留纹理,同时突出显著目标,这一点可以从图2中观察到。总之,我们的主要贡献有四方面:
直观地,我们在图2中提供了一个示例来展示光照不平衡,可以观察到白天可见光图像具有比红外图像更清晰的纹理细节,但红外图像能够突出显著的行人。相比之下,夜间红外图像提供更多显著目标且纹理比可见光图像更丰富。不幸的是,现有方法[7,17,26]通常假设纹理仅存在于可见光图像中,这在白天场景中是合理的。然而,这种假设可能导致夜间融合图像丢失纹理细节。此外,基于AE的方法[6]使用不恰当的融合规则合并深度特征,可能会削弱纹理细节和显著目标。最后,现有技术更专注于如何融合图像/特征,而忽略了何时融合图像/特征。更具体地说,研究者致力于设计更精细的融合规则和损失函数以提升融合性能,但很少研究在哪个阶段融合图像/特征。目前,融合发生在两个阶段,即输入融合和半路融合。输入融合意味着将多模态输入级联在一起作为融合网络的输入[7,26],这可能导致网络无法融合源图像的语义信息。半路融合意味着使用特定的融合规则合并特征提取器提取的深度特征[6,20,22,24]。在这种情况下,所选融合规则至关重要,因为不恰当的规则无法充分整合互补信息。为了解决上述问题,我们提出了一种基于光照感知的渐进式红外与可见光图像融合框架,称为 PIAFusion,并发布了一个用于红外与可见光图像融合的大型基准数据集。首先,我们从现有的 MFNet 数据集[5]中收集了大量红外与可见光图像对,该数据集是为多模态图像语义分割拍摄的。MFNet 数据集包含大量对比度和信噪比较低的红外图像以及一些未对齐的图像对。因此,我们对红外图像进行锐化和增强,并移除未对齐的图像对。随后,我们设计了一个光照感知子网络来评估光照条件。更具体地说,预训练的光照感知子网络计算当前场景是白天还是夜间的概率。然后,这些概率用于构建光照感知损失,以指导融合网络的训练。最后,一个包含跨模态差异感知融合(CMDAF)模块的渐进式特征提取器被用于充分提取和融合多模态图像中的互补信息。此后,互补特征和共同特征通过半路融合方式融合,图像重建器将融合特征转换为融合图像域。在光照感知损失的指导下,我们的融合框架能够根据光照条件自适应地整合关键信息,如显著目标和纹理细节。此外,CMDAF 模块和半路融合策略使我们的网络能够在不同阶段融合共同和互补信息。因此,无论光照条件如何,我们的融合图像都能充分保留纹理,同时突出显著目标,这一点可以从图2中观察到。总之,我们的主要贡献有四方面:
- 我们提出了一种新颖的光照引导红外与可见光图像融合框架,能够通过感知光照情况全天候融合源图像的有意义信息。
- 我们将跨模态差异感知融合模块与半路融合策略相结合,以在不同阶段整合互补和共同信息。
- 我们基于 MFNet 数据集构建了一个新的基准数据集,用于红外与可见光图像融合的训练和评估,称为多光谱道路场景(MSRS),可在 https://github.com/Linfeng-Tang/MSRS 获取。
- 大量实验证明了我们的算法相较于现有最佳竞争者的优越性。与其他方法相比,我们的方法能够根据光照条件自适应地融合互补和共同信息。
本文的剩余部分组织如下。第2节简要描述了图像融合和基于光照感知的计算机视觉应用的相关工作。第3节详细介绍了我们提出的 PIAFusion,包括问题分析、损失函数和网络架构。第4节展示了我们的方法在三个基准数据集上与其他方法的融合性能比较,最后在第5节给出了一些结论性评论。
2.2 Introduction 解析
1. 背景与动机
- 问题来源:单一模态传感器(如仅红外或仅可见光)受限于硬件的理论和技术限制,无法全面捕捉场景信息。例如,红外图像擅长突出热目标(如行人),但对无热辐射的物体(如自行车)无能为力;可见光图像则依赖光照条件,在黑暗或烟雾中失效。
- 图像融合的必要性:通过融合多模态图像(如红外与可见光),可以利用它们的互补性提升目标检测、跟踪等任务的性能。文中通过图1的例子直观展示了融合图像的优势。
- 分类:图像融合分为多模态融合(不同传感器,如红外+可见光)和数字摄影融合(同一传感器不同设置)。本文聚焦前者,尤其是红外与可见光融合,因其在军事和民用领域的广泛应用。
2. 传统方法的局限性
- 传统方法概述:
- 多尺度分解:如小波变换,将图像分解为不同尺度,再按规则融合。
- 子空间聚类:基于特征子空间的聚类融合。
- 稀疏表示:用稀疏系数表示图像特征并融合。
- 优化方法:通过优化目标函数实现融合。
- 混合方法:结合多种技术。
- 瓶颈:
- 复杂性:为提升性能,变换和表示越来越复杂,计算成本高,无法满足实时需求。
- 适应性差:手工设计的活跃度测量和融合规则难以应对多样化场景,尤其在动态光照条件下。
3. 数据驱动方法的兴起
- 分类:
- 基于自编码器(AE):
- 训练AE提取特征,手工规则(如加法、最大值)融合特征,再重建图像。
- 缺点:融合规则不可学习,限制了灵活性。
- 基于CNN:
- 端到端网络,依赖网络结构和损失函数。
- 优点:全可学习,适应性强。
- 挑战:缺乏地面真值,需设计合适的损失。
- 基于GAN:
- 将融合视为生成器与判别器的博弈,约束分布一致性。
- 风险:强约束可能引入伪影。
- 基于自编码器(AE):
- 优势:深度学习方法利用大数据驱动,克服了传统方法对手工规则的依赖。
4. 当前挑战
- 数据集不足:
- TNO和RoadScene数据集规模小、场景单一,易导致过拟合。
- 解决:需要大规模、多样化的基准数据集。
- 光照不平衡:
- 白天:可见光纹理丰富,红外突出目标。
- 夜间:红外纹理和目标更显著,可见光信息少。
- 现有方法假设纹理仅在可见光中,夜间融合易丢失细节。
- 融合时机:
- 输入融合:直接拼接输入,语义融合不足。
- 半路融合:特征提取后融合,规则选择关键。
- 问题:缺乏对融合阶段的系统研究。
5. PIAFusion 的创新
- 核心思想:
- 光照感知:通过子网络评估白天/夜间概率,构建光照感知损失,自适应融合信息。
- 渐进式融合:使用跨模态差异感知融合(CMDAF)模块,在不同阶段提取和融合特征。
- 新数据集:基于MFNet构建MSRS数据集,增强红外图像质量并对齐。
- 技术细节:
- 光照感知子网络:预训练模型计算光照条件概率,指导融合网络训练。
- CMDAF模块:捕获跨模态差异,逐步融合互补信息。
- 半路融合:结合共同和互补特征,重建融合图像。
- 优势:
- 自适应性:根据光照条件调整融合策略。
- 全面性:保留纹理和突出目标。
- 数据支持:MSRS提供多样化训练数据。
三. related work
3.1 related work翻译
在本节中,我们首先回顾现有的红外与可见光图像融合算法,包括传统图像融合方法、基于自编码器(AE)的图像融合方法、基于卷积神经网络(CNN)的图像融合方法以及基于生成对抗网络(GAN)的图像融合方法。然后,简要介绍一些基于光照感知的视觉任务。
1. 红外与可见光图像融合
1.1. 传统图像融合
特征提取、融合和重建是典型传统图像融合方法的三个基本要素。此外,这些算法的关键在于特征提取和融合,因为特征重建是特征提取的逆操作。已经提出了许多特征提取函数以实现更好的特征表示,大致可分为三类,即多尺度变换、稀疏表示和子空间聚类。多尺度变换,如拉普拉斯金字塔、离散小波[32]、剪切波[33]、曲线波[34]和非下采样轮廓波[35]变换,是最经典的特征提取技术。稀疏表示,包括联合稀疏表示[36]、卷积稀疏表示[16]和潜在低秩表示[13],是另一种与人类视觉感知一致的特征提取方法。子空间聚类,如独立成分分析[15]、主成分分析[37]和非负矩阵分解[38],可以提取相互独立的子成分。此外,一些特定的融合规则,包括逐元素加法[27]、逐元素加权求和[6]和逐元素最大值[28],被用来整合提取的特征/表示。除了典型方法外,一些基于优化的方法也为图像融合社区提供了新的视角。特别是,梯度传递融合(GTF)为基于CNN和基于GAN的方法奠定了坚实基础,它将图像融合的目标函数定义为整体强度保真度和纹理结构保持[17]。此外,一些混合模型结合了不同组件的优点来提升融合性能[18,39]。具体来说,Hou 等人提出了一种新颖的红外与可见光图像融合方法,通过结合非下采样剪切波变换(NSST)、视觉显著性和多目标人工蜂群(MOABC)优化的脉冲皮层模型(SCM),可以缓解边缘模糊、低对比度和细节丢失等问题[39]。
1.2. 基于AE的图像融合
凭借神经网络出色的非线性拟合能力,深度学习已成为各种计算机视觉任务的新宠。图像融合社区也探索了数据驱动方法,其中一个成功的例子是基于自编码器的方法。基于AE的方法继承了传统图像融合算法的基线,即特征提取、融合和重建。Prabhakar 等人通过两个固定参数的卷积层创新地实现了特征提取[27]。特征重建也被三个预训练的卷积层所替代。此外,逐元素加法融合规则被用来合并特征图。然而,两个卷积层无法提取包含语义信息的特征。Li 等人加强了编码器并引入了密集连接以提取深度特征并实现特征重用[6]。除了密集连接外,Li 等人还引入了多尺度编码器-解码器网络架构和嵌套连接以提取更全面的特征[20,21]。不幸的是,手工设计的融合规则严重限制了融合性能的提升。
1.3. 基于CNN的图像融合
为了避免手工设计融合规则的限制,研究者们开发了端到端的基于CNN的图像融合算法。Zhang 等人探索了一个端到端框架,通过强度和梯度路径保持梯度和强度的比例[40]。他们建模了一个通用的损失函数,并调整超参数以适应不同的图像融合任务。为了促使网络有目的地提取和融合有意义的特征,Ma 等人通过引入显著目标掩码定义了红外与可见光图像融合的期望信息[24]。他们的网络可以同时融合红外和可见光图像并实现显著目标检测。此外,Xu 等人通过弹性权重整合训练了一个多融合任务的统一模型,考虑了不同图像融合任务之间的相互促进[30]。然而,由于融合任务的特殊性,即缺乏地面真值,融合网络无法充分发挥其全部潜力。
1.4. 基于GAN的图像融合
由于对抗损失在分布层面约束网络,生成对抗网络非常适合无监督任务,如图像融合[7,41]和图像到图像转换[42,43]。Ma 等人创新地将红外与可见光图像融合视为生成器与判别器之间的博弈。判别器迫使生成器合成包含更多纹理的融合图像[7]。然而,单一判别器往往会打破红外与可见光图像之间的数据分布平衡。因此,Ma 等人进一步提出了双判别器条件生成对抗网络(DDcGAN)以维持不同源图像之间的分布平衡[26]。随后,Li 等人将多尺度注意力机制集成到基于GAN的融合框架中[44]。双判别器在注意力损失函数的指导下可以更专注于注意力区域。此外,Ma 等人提出了一种基于GAN的多分类融合方法,将图像融合转化为多分布同时估计[45]。多分类器促使融合图像以更平衡的方式具有显著对比度和丰富纹理。然而,图像融合社区仍面临许多挑战,例如现有基准数据集仅包含有限的场景,传统方法和数据驱动方法都忽略了光照变化。值得注意的是,实际多模态数据集中存在一个重要的先验,即白天可见光图像包含大量有意义信息,而夜间红外图像捕获更丰富的信息。不幸的是,现有的图像融合方法未在建模过程中考虑这一先验。特别是,基于CNN和基于GAN的方法将红外与可见光图像融合定义为红外图像的强度保持和可见光图像的纹理保留。这一假设在白天是合理的。然而,融合图像应在夜间保留更多红外图像的纹理细节以增强场景描述。因此,鲁棒的融合算法应感知光照条件并在光照指导下自适应整合有意义信息。
2. 基于光照感知的视觉应用
事实上,一些实用的计算机视觉应用在建模时已考虑了光照因素。Wang 等人提出了一种全局光照感知和细节保留网络(GLADNet)用于低光图像增强[46]。GLADNet 首先为低光图像计算全局光照估计,然后根据估计调整光照并与原始图像拼接以增强细节。此外,Sakkos 等人开发了一种三重多任务生成对抗网络,将不同光照下的特征整合到分割分支中,大大提高了前景分割性能[47]。此外,许多研究者探索了利用光照信息提升多光谱行人检测性能的可行性。例如,Li 等人提出了一种光照感知更快区域卷积神经网络(Faster R-CNN),通过光照感知网络输出的门控函数自适应融合红外和可见光子网络[48]。巧合的是,Guan 等人提出了一个基于光照感知行人检测和语义分割的多光谱行人检测框架[49]。他们利用一种新颖的光照感知加权机制描述光照条件,并将光照信息整合到双流CNN中,以在不同光照情况下获得与人体相关的特征。此外,MBNet 以更灵活和平衡的方式促进优化过程并提高检测器性能[31]。特别是,光照感知特征对齐模块用于根据光照条件自适应选择互补信息。在这项工作中,我们提出了一种基于光照感知的渐进式红外与可见光融合框架,以消除光照不平衡问题。更具体地说,我们首先开发了一个光照感知子网络来估计光照条件。然后,利用光照概率构建光照感知损失。最后,精心设计的渐进式网络在光照感知损失的指导下自适应整合红外与可见光图像的有意义信息。
3.2 related work解析
1. 红外与可见光图像融合综述
1.1 传统方法
- 核心流程:特征提取 → 融合 → 重建。
- 特征提取:多尺度变换(如拉普拉斯金字塔、小波变换)分解图像为不同频率分量;稀疏表示(如卷积稀疏表示)符合视觉感知;子空间聚类(如PCA)提取独立特征。
- 融合规则:手工设计(如加法、最大值),简单但缺乏灵活性。
- 重建:逆变换还原图像。
- 代表性方法:
- GTF(梯度传递融合):优化强度和纹理保持,为深度学习方法奠基。
- 混合模型:如NSST+MOABC+SCM,结合多尺度变换和优化,解决边缘模糊等问题。
- 局限性:
- 计算复杂度高,实时性差。
- 规则固定,无法适应多样化场景。
1.2 基于AE的方法
- 流程:编码器提取特征 → 手工规则融合 → 解码器重建。
- 进展:
- Prabhakar [27]:用固定参数卷积层提取特征,简单但语义不足。
- Li [6,20,21]:引入密集连接、多尺度架构和嵌套连接,提升特征表达。
- 问题:
- 融合规则不可学习(如加法),限制性能。
- 特征提取深度有限,难以捕捉复杂语义。
1.3 基于CNN的方法
- 特点:端到端训练,避免手工规则。
- 关键工作:
- Zhang [40]:通过强度和梯度路径平衡融合,通用损失函数适应多任务。
- Ma [24]:引入显著目标掩码,融合同时检测目标。
- Xu [30]:统一模型支持多任务融合。
- 挑战:
- 缺乏地面真值,损失设计困难。
- 任务特异性限制性能发挥。
1.4 基于GAN的方法
- 优势:对抗损失适合无监督任务。
- 进展:
- Ma [7]:生成器与判别器博弈,增强纹理。
- DDcGAN [26]:双判别器平衡分布。
- Li [44]:多尺度注意力提升关注区域。
- Ma [45]:多分类GAN平衡对比度和纹理。
- 问题:
- 数据集场景有限,泛化性不足。
- 忽略光照变化,白天/夜间假设不一致。
2. 基于光照感知的视觉应用
- 应用案例:
- GLADNet [46]:低光增强,全球光照估计+细节保留。
- Sakkos [47]:多任务GAN,融合不同光照特征提升分割。
- Li [48]:光照感知Faster R-CNN,自适应融合子网络。
- Guan [49]:光照加权机制,优化多光谱行人检测。
- MBNet [31]:特征对齐模块,根据光照选择信息。
- 共性:
- 利用光照条件指导特征选择或融合。
- 提升任务在多样光照下的鲁棒性。
- 启发:
- 图像融合可借鉴光照感知,提升夜间性能。
3. 本文的定位
- 创新点:
- 提出光照感知渐进式融合框架,解决光照不平衡。
- 子网络估计光照,指导损失设计和特征融合。
- 技术细节:
- 光照感知子网络:可能基于分类器(如白天/夜间)。
- 渐进式融合:多阶段提取和整合特征。
- 意义:
- 填补光照感知在图像融合中的空白。
- 为自适应融合提供新思路。
四.方法
4.1 方法翻译
在本节中,我们全面描述了基于光照感知的渐进式红外与可见光图像融合框架。首先,我们提供了所提出的PIAFusion的问题分析。然后,我们详细介绍了融合网络的光照感知损失和光照感知子网络的交叉熵损失。最后,展示了渐进式融合网络和光照感知子网络的架构。
1. 问题分析
给定红外图像 和可见光图像
,融合图像
可通过特征提取、整合和重建生成。为了提升融合性能,我们设计了光照感知损失来约束上述三个步骤。基于光照引导的渐进式红外与可见光图像融合网络如图3所示。
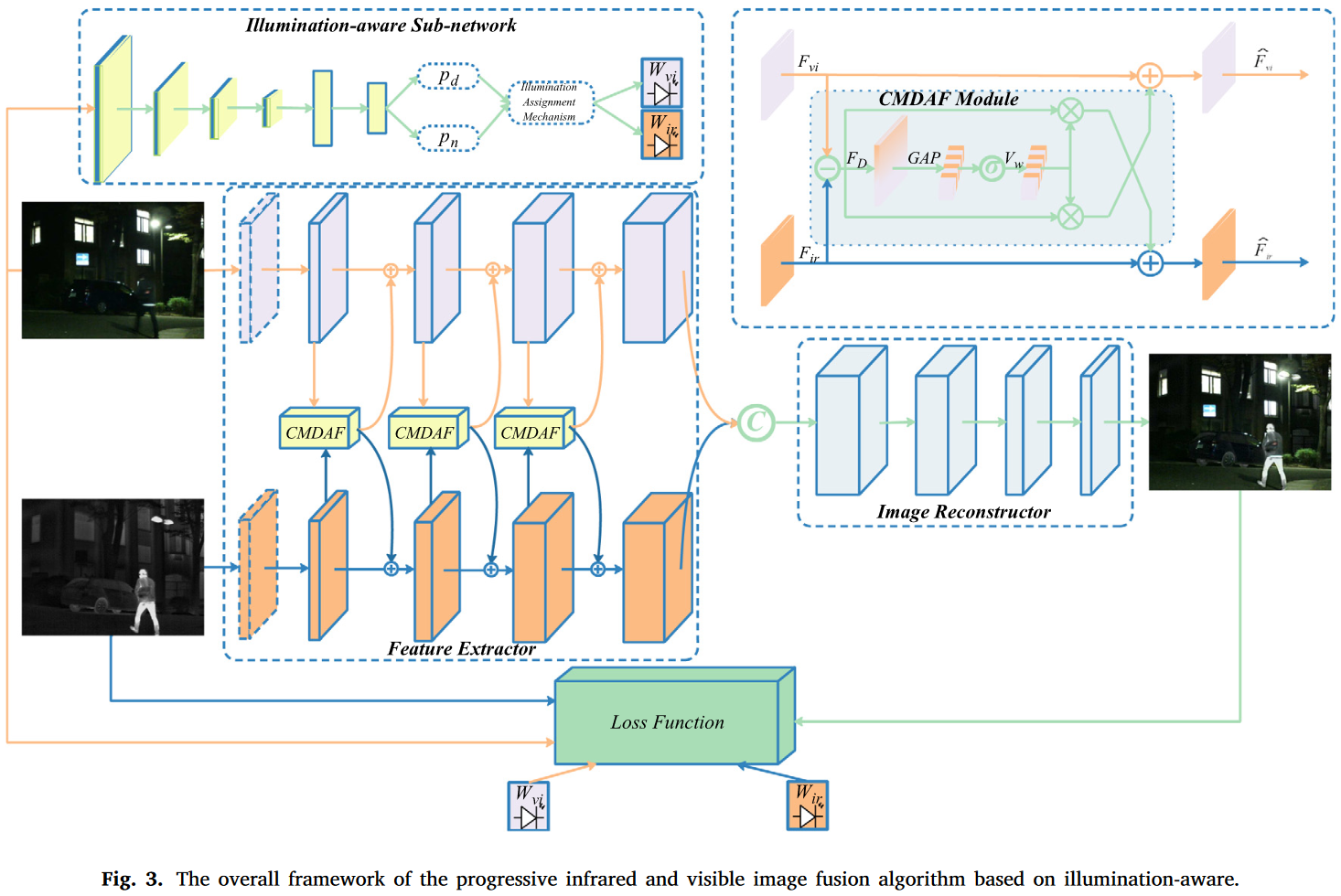 考虑到光照不平衡影响信息分布,我们开发了一个光照感知子网络来估计可见光图像的光照。给定可见光图像
考虑到光照不平衡影响信息分布,我们开发了一个光照感知子网络来估计可见光图像的光照。给定可见光图像,光照感知过程定义为:
其中 表示光照感知子网络,
和
分别表示图像属于白天和夜间的概率。值得一提的是,
和
是非负标量。由于白天的大部分信息集中在可见光图像中,而夜间的红外图像包含更多有意义的信息,光照概率从侧面反映了源图像的信息丰富程度。因此,我们利用光照概率通过光照分配机制计算光照感知权重,表示源图像对融合过程的贡献。为了简化计算,我们的光照分配机制采用简单的归一化函数,定义如下:
其中 和
分别表示红外图像和可见光图像对融合过程的贡献。此外,我们还设计了一个渐进式融合网络,以完全整合互补和共同信息。更具体地说,我们首先应用特征编码器
从红外和可见光图像中提取深度特征,可表示为:
其中 和
表示红外特征和可见光特征。此外,我们将第 i 个卷积层从红外和可见光图像中提取的特征定义为
和
。此外,我们提出了跨模态差异感知融合(CMDAF)模块来补偿差异信息。具体来说,
和
可以用共同部分和互补部分表示如下:
其中共同部分表示共同特征,互补部分反映不同模态的互补特征。方程(4)解释了差异分解原理,类似于差分放大电路。CMDAF模块的关键思想是通过通道加权完全整合互补信息。因此,CMDAF模块的具体定义为:
其中 表示逐元素加法,
表示通道乘法,
和
分别表示sigmoid函数和全局平均池化。方程(5)表示全局平均池化将互补特征压缩为向量,然后通过sigmoid函数归一化到[0, 1]以生成通道权重。最后,互补特征乘以通道权重,结果加到原始特征上作为模态补充信息。因此,我们的特征编码器可以通过CMDAF模块提取并预整合不同模态的互补特征。此外,红外和可见光图像的共同和互补特征通过半路融合方式(即拼接)完全合并。半路融合策略表达如下:
其中 表示通道维度的拼接。最后,融合图像
通过图像重建器
从融合特征
中恢复,表达为:
2. 损失函数
2.1. 渐进式融合网络的损失函数
为了促进我们的渐进式融合框架根据光照条件自适应整合有意义信息,我们创新性地提出了光照感知损失。光照感知损失 的精确定义如下:
其中 和
分别表示红外和可见光图像的强度损失,
和
是方程(2)中定义的光照感知权重。强度损失项的具体定义如下。强度损失测量融合图像与源图像在像素级别的差异。因此,我们将红外和可见光图像的强度损失定义为:
其中 H和 W 分别是输入图像的高度和宽度,表示
范数。事实上,融合图像的强度分布应根据光照情况与不同的源图像一致。因此,我们使用光照感知权重
和
来调整融合图像的强度约束。光照损失驱动渐进式融合网络根据光照条件动态保留源图像的强度信息,但它并未保持融合图像的最佳强度分布。为此,我们进一步引入辅助强度损失,表示为:
其中 表示逐元素最大值选择。此外,我们希望融合图像同时保持最佳强度分布并保留丰富的纹理细节。根据大量实验,我们发现融合图像的最佳纹理可以表示为红外和可见光图像纹理的最大集合。因此,引入纹理损失以迫使融合图像包含更多纹理信息,定义如下:
其中表示测量图像纹理信息的梯度算子。本文中使用Sobel算子计算梯度,
表示绝对值操作。最后,渐进式融合网络的完整目标函数是光照损失、辅助强度损失和纹理损失的加权组合,表达如下:
总之,我们的渐进式融合网络在光照损失和辅助强度损失的指导下,可以根据光照场景动态保留最佳强度分布,并在纹理损失的指导下获得理想的纹理细节。因此,融合网络可以全天候融合红外和可见光图像中的有意义信息。
2.2. 光照感知子网络的损失函数
在我们的方法中,融合性能在很大程度上依赖于光照感知子网络的准确性。光照感知网络本质上是一个分类器,计算图像属于白天和夜间的概率。因此,我们采用交叉熵损失来约束光照感知子网络的训练过程,表示为:
其中 z 表示输入图像的光照标签, 表示光照感知子网络的输出,
表示softmax函数,将光照概率归一化到[0, 1]。
3. 网络架构
3.1. 渐进式融合网络架构
如图3所示,我们采用基于端到端的CNN框架作为主干网络,我们的渐进式网络包括特征提取器和图像重建器。特征提取器中有五个卷积层,旨在充分提取互补和共同特征。首先,1×1卷积层旨在减少红外和可见光图像之间的模态差异。因此,我们分别对红外和可见光图像训练第一层。之后,使用四个共享权重的卷积层提取红外和可见光图像的深度特征。值得注意的是,第2、3和4层的输出后接CMDAF模块,以交换模态互补特征。CMDAF模块使我们的网络能够在特征提取阶段以渐进方式整合互补信息。因此,我们的特征提取器可以从红外和可见光图像中完全提取共同和互补特征。特征提取器中所有卷积层的详细信息(如核大小、输出通道和激活函数)在表1中列出。
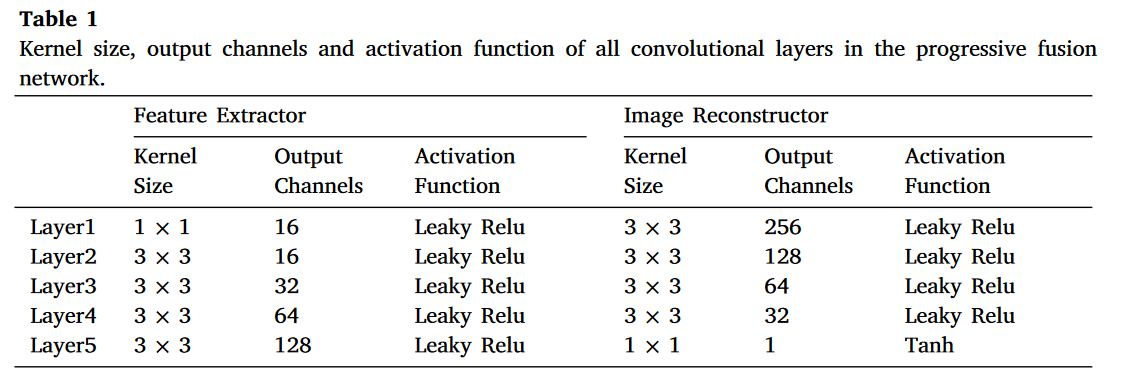 除第一层外,所有卷积层的核大小为3。特征提取器的所有层使用Leaky ReLU作为激活函数。随后,从红外和可见光图像中提取的深度特征被拼接,作为图像重建器的输入。图像重建器包含五个卷积层,负责完全整合共同和互补信息并生成融合图像。图像重建器的详细配置在表1中展示。除最后一层外,所有层的核大小为3×3,最后一层的核大小为1×1。此外,图像重建器在图像重建过程中逐渐减少特征图的通道数。图像重建器中的所有卷积层采用Leaky ReLU作为激活函数,除了最后一层使用Tanh激活函数。我们知道,信息丢失是图像融合过程中的灾难性问题。因此,渐进式融合网络中所有卷积层的填充设置为“same”,步幅设置为1,除了第一层和最后一层。因此,我们的网络不引入任何下采样,融合图像的大小与源图像一致。
除第一层外,所有卷积层的核大小为3。特征提取器的所有层使用Leaky ReLU作为激活函数。随后,从红外和可见光图像中提取的深度特征被拼接,作为图像重建器的输入。图像重建器包含五个卷积层,负责完全整合共同和互补信息并生成融合图像。图像重建器的详细配置在表1中展示。除最后一层外,所有层的核大小为3×3,最后一层的核大小为1×1。此外,图像重建器在图像重建过程中逐渐减少特征图的通道数。图像重建器中的所有卷积层采用Leaky ReLU作为激活函数,除了最后一层使用Tanh激活函数。我们知道,信息丢失是图像融合过程中的灾难性问题。因此,渐进式融合网络中所有卷积层的填充设置为“same”,步幅设置为1,除了第一层和最后一层。因此,我们的网络不引入任何下采样,融合图像的大小与源图像一致。
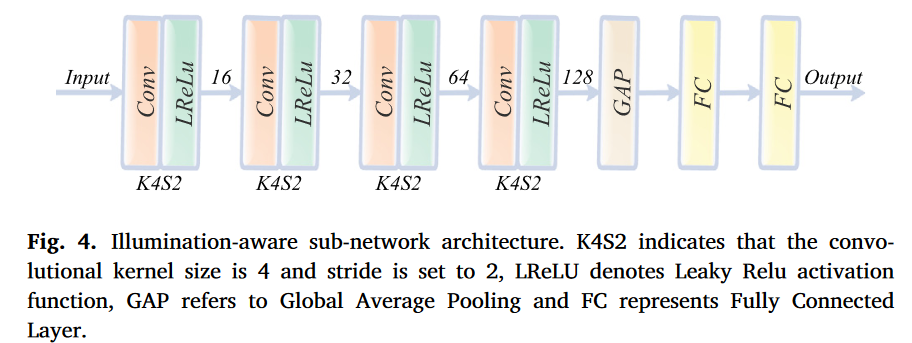
3.2. 光照感知子网络架构
光照感知子网络旨在估计场景的光照分布,其输入是可见光图像,输出是光照概率。光照感知子网络的架构如图4所示。它包括四个卷积层、一个全局平均池化和两个全连接层。4×4卷积层(步幅设置为2)压缩空间信息并提取光照信息。所有卷积层使用Leaky ReLU作为激活函数并设置填充为“same”。然后,使用全局平均池化操作整合光照信息。最后,两个全连接层从光照信息中计算光照概率。
4.2 方法解析
1. 问题分析
- 目标:融合红外图像
和可见光图像
生成
,提升性能。
- 挑战:光照不平衡(白天可见光信息丰富,夜间红外信息主导)。
- 解决方案:
- 光照感知子网络:估计白天/夜间概率
,反映信息分布。
- 光照权重:通过归一化函数
和
自适应调整红外和可见光的贡献。
- 渐进式融合:通过CMDAF模块和半路融合整合互补和共同特征。
- 光照感知子网络:估计白天/夜间概率
- 创新点:
- 光照感知权重动态调整融合策略。
- CMDAF模块基于差异分解,类比电路设计,增强互补特征提取。
评价
- 光照权重:简单而直观,基于概率归一化,避免复杂计算。但可能过于线性,未考虑场景复杂度(如阴天)。
- CMDAF原理:将特征分解为共同和互补部分,理论上合理,但公式(4)中的分解形式(平均加差分)可能过于简化,未充分利用通道间的多样性。
2. 损失函数
2.1 渐进式融合网络损失
- 光照感知损失
:
。
- 强度损失
和
使用
范数,测量像素级差异。
- 作用:根据光照条件动态调整红外和可见光的强度保留。
- 辅助强度损失
:
。
- 作用:确保融合图像保留最大强度分布。
- 纹理损失
:
。
- 使用Sobel算子提取梯度,保留最大纹理。
- 总损失:
。
2.2 光照感知子网络损失
- 交叉熵损失
:
。
- z 为光照标签,
为预测概率。
- 作用:训练子网络准确分类白天/夜间。
评价
- 光照感知损失:加权强度损失根据光照动态调整,设计合理。但仅关注像素级差异,未引入感知损失(如VGG),可能限制纹理质量。
- 辅助强度损失:使用最大值作为参考,简单有效,但可能导致过强目标突出,忽略低强度区域。
- 纹理损失:基于Sobel梯度的最大纹理保留是创新点,但Sobel算子较为基础,可能无法捕捉复杂纹理。
- **超参数
**:文中未讨论如何调优,可能影响损失间的平衡。
3. 网络架构
3.1 渐进式融合网络
- 特征提取器:
- 5个卷积层,第1层(1×1)独立训练减少模态差异,其余共享权重。
- 第2-4层后接CMDAF模块,渐进整合互补特征。
- 激活函数:Leaky ReLU。
- 图像重建器:
- 5个卷积层,逐步减少通道数,最后层用Tanh激活。
- 无下采样,保持分辨率。
- 半路融合:
- 拼接特征
。
- 拼接特征
3.2 光照感知子网络
- 4个卷积层(首层4×4,步幅2)+全局平均池化+2个全连接层。
- 输出白天/夜间概率。
评价
- CMDAF模块:
- 使用GAP和sigmoid生成通道权重,类似注意力机制,增强互补特征。
- 渐进式融合(多层CMDAF)优于单次融合,但计算成本增加。
- 网络设计:
- 无下采样保留分辨率,适合像素级任务。
- 共享权重减少参数,但可能限制模态特异性特征提取。
- 子网络:结构简单,适合分类任务,但对复杂光照(如黄昏)分类能力待验证。
4. 技术优势与创新
- 光照自适应:通过
和
动态调整融合策略,解决光照不平衡。
- 渐进融合:CMDAF模块多阶段整合特征,提升信息保留。
- 损失设计:结合强度和纹理损失,目标明确。
五.实验
5.1 实验翻译
在本节中,我们首先介绍数据集构建、实验配置和实现细节。然后,通过比较实验和泛化实验来展示我们算法的优越性。接下来,我们分析不同方法的运行效率。此外,我们不仅展示了我们的方法在自适应特征选择方面的能力,还展示了其在高级视觉任务中的潜力。进行了一些消融研究,以验证我们特定设计的有效性,包括光照感知损失和跨模态差异感知融合模块。
1. 数据集构建
我们基于MFNet数据集[5]构建了一个新的多光谱数据集,用于红外与可见光图像融合。MFNet数据集包含1569对图像(白天820对,夜间749对),空间分辨率为480×640。然而,MFNet数据集中存在许多未对齐的图像对,且大多数红外图像信噪比低、对比度低。为此,我们首先通过移除125对未对齐的图像对,收集了715对白天图像对和729对夜间图像对。此外,我们利用基于暗通道先验[50]的图像增强算法优化红外图像的对比度和信噪比。因此,发布的新多光谱道路场景(MSRS)数据集包含1444对高质量对齐的红外与可见光图像。
2. 实验配置
为了全面评估我们提出的方法,我们在MSRS、RoadScene[30]和TNO[29]数据集上进行了广泛的定性和定量实验。我们将算法与九种最先进的方法进行比较,包括两种传统方法(GTF[17]和MDLatLRR[13])、三种基于自编码器的方法(DenseFuse[6]、DRF[51]和CSF[11])、一种基于生成对抗网络的方法(FusionGAN[7])、三种基于卷积神经网络的方法(IFCNN[22]、PMGI[40]和U2Fusion[30])。所有九种方法的实现均公开可用,我们按照原始论文中报告的参数进行设置。选择了四个评估指标来量化评估,包括互信息(MI)[52]、标准差(SD)、视觉信息保真度(VIF)[53]和。MI指标从信息论角度测量从源图像到融合图像的信息传递量。SD指标从统计角度反映融合图像的分布和对比度。VIF指标从人类视觉系统角度评估融合图像的信息保真度。\
测量从源图像到融合图像传递的边缘信息量。MI、SD、VIF和
值越大,表示融合性能越好。
3. 实现细节
我们在MSRS数据集上训练我们的渐进式融合模型和光照感知模型。我们选择了427张白天场景图像和376张夜间场景图像来训练光照感知子网络。采用裁剪和分解数据增强方法生成足够的训练数据。具体来说,我们将这些图像裁剪为64×64的块,步幅设置为64。因此,我们共收集了29,960个白天块和26,320个夜间块。此外,我们利用376对白天图像对(即26,320个块)和376对夜间图像对(即26,320个块)来学习渐进式融合模型的参数。所有图像块在输入网络前均归一化到[0, 1]。我们使用独热编码标签作为光照感知子网络的参考,白天场景和夜间场景的标签分别设置为二维向量[1, 0]和[0, 1]。光照感知子网络和渐进式融合网络按顺序训练。更具体地说,我们首先训练光照感知子网络。之后,预训练的光照感知网络用于在训练渐进式融合网络时计算光照概率并构建光照感知损失。批大小设置为 b,一个epoch的训练步数设置为 p,训练一个模型需要M个epoch。对于光照感知子网络,我们经验性地设置、
、
。对于渐进式融合网络,
设置为64,
设置为30,
。模型参数通过Adam优化器更新,学习率初始为0.001,然后指数衰减。对于方程(12)的超参数,我们设置为
、
、
。我们进一步在算法1中总结了PIAFusion的训练过程。所提方法在TensorFlow平台[54]上实现。所有实验在NVIDIA TITAN V GPU和2.00 GHz Intel(R) Xeon(R) Gold 5117 CPU上进行。值得强调的是,在测试阶段,源图像直接输入到渐进式融合网络中。由于MSRS和RoadScene数据集包含彩色可见光图像,我们使用特定的融合策略[27]保留融合图像中的颜色信息。具体来说,我们首先将可见光图像转换为YCbCr颜色空间。然后,使用不同的融合方法合并可见光图像的Y通道和红外图像。最后,通过结合可见光图像的Cb和Cr通道,将融合图像转换回RGB颜色空间。
4. 比较实验
为了全面评估我们方法的性能,我们将所提出的PIAFusion与MSRS数据集上的其他九种方法进行比较。
4.1. 定性结果
为了直观展示基于光照感知的融合方法对光照变化的适应性,我们选择了三张白天图像和两张夜间图像进行主观评估。可视化结果如图5-9所示。
 在白天场景中,红外图像的热辐射信息可用作可见光图像的补充信息。因此,优越的融合算法应保留可见光图像的纹理细节,同时突出显著目标,且不引入光谱污染。如图5和图6所示,
在白天场景中,红外图像的热辐射信息可用作可见光图像的补充信息。因此,优越的融合算法应保留可见光图像的纹理细节,同时突出显著目标,且不引入光谱污染。如图5和图6所示,

 GTF和FusionGAN无法保留可见光图像的细节信息。虽然MDLatLRR、DenseFuse、DRF、CSF、IFCNN和U2Fusion整合了可见光图像的纹理信息和红外图像的显著目标信息,但背景区域遭受不同程度的光谱污染。我们放大红色框中的背景区域来说明这一现象。只有我们的方法和PMGI完全保留了纹理细节。然而,PMGI、MDLatLRR、DenseFuse和U2Fusion削弱了红外目标。此外,PMGI在某些情况下还引入了额外信息,如图7的绿色框所示。
GTF和FusionGAN无法保留可见光图像的细节信息。虽然MDLatLRR、DenseFuse、DRF、CSF、IFCNN和U2Fusion整合了可见光图像的纹理信息和红外图像的显著目标信息,但背景区域遭受不同程度的光谱污染。我们放大红色框中的背景区域来说明这一现象。只有我们的方法和PMGI完全保留了纹理细节。然而,PMGI、MDLatLRR、DenseFuse和U2Fusion削弱了红外目标。此外,PMGI在某些情况下还引入了额外信息,如图7的绿色框所示。
 在夜间场景中,可见光图像仅包含有限的细节信息。幸运的是,红外图像包含显著目标和丰富的纹理细节,可以补充可见光图像的纹理。然而,根据光照场景自适应整合红外和可见光图像的纹理信息是一项挑战。在图8中,尽管所有算法都保留了显著目标,但MDLatLRR、DenseFuse、CSF、IFCNN和U2Fusion无法清楚显示隐藏在黑暗中的树干。
在夜间场景中,可见光图像仅包含有限的细节信息。幸运的是,红外图像包含显著目标和丰富的纹理细节,可以补充可见光图像的纹理。然而,根据光照场景自适应整合红外和可见光图像的纹理信息是一项挑战。在图8中,尽管所有算法都保留了显著目标,但MDLatLRR、DenseFuse、CSF、IFCNN和U2Fusion无法清楚显示隐藏在黑暗中的树干。
 此外,GTF忽略了可见光图像中的文字(即蓝色框),PMGI在融合过程中引入了噪声。FusionGAN和DRF分别模糊了目标和文字。我们的方法能够有效整合红外和可见光图像的互补信息。类似的现象出现在图9中。除了我们的方法和PMGI外,所有方法都无法同时包含树干和围栏的信息。因此,受益于光照感知损失,我们的渐进式融合能够根据光照条件自适应融合有意义信息。
此外,GTF忽略了可见光图像中的文字(即蓝色框),PMGI在融合过程中引入了噪声。FusionGAN和DRF分别模糊了目标和文字。我们的方法能够有效整合红外和可见光图像的互补信息。类似的现象出现在图9中。除了我们的方法和PMGI外,所有方法都无法同时包含树干和围栏的信息。因此,受益于光照感知损失,我们的渐进式融合能够根据光照条件自适应融合有意义信息。
4.2. 定量结果
在150对图像对上,四个互补指标的定量结果如表2所示。
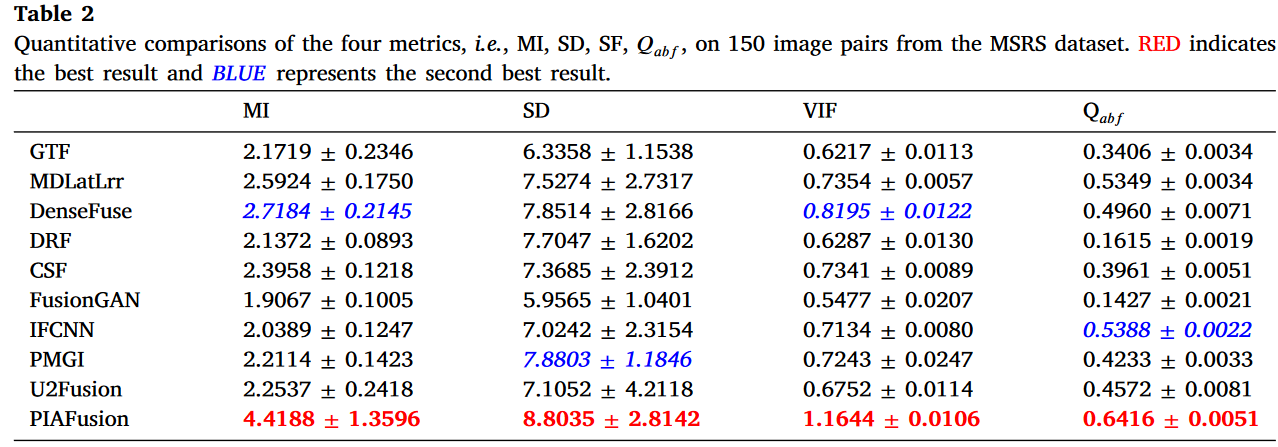 值得注意的是,我们的方法在所有四个指标上均表现出显著的优越性。最佳MI指标意味着PIAFusion根据光照条件从源图像到融合图像传递了最多信息。此外,我们提出的方法实现了最高的SD和VIF,表明我们的融合图像具有高对比度和令人满意的视觉效果。此外,我们的PIAFusion显示出最佳的
值得注意的是,我们的方法在所有四个指标上均表现出显著的优越性。最佳MI指标意味着PIAFusion根据光照条件从源图像到融合图像传递了最多信息。此外,我们提出的方法实现了最高的SD和VIF,表明我们的融合图像具有高对比度和令人满意的视觉效果。此外,我们的PIAFusion显示出最佳的,这意味着融合结果中保留了更多的边缘信息,受益于我们提出的跨模态差异感知融合模块。
5. 泛化实验
众所周知,泛化性能是评估数据驱动方法的重要因素。因此,我们在RoadScene和TNO数据集上进行了泛化实验,以验证PIAFusion的泛化能力。值得注意的是,我们的融合模型在MSRS数据集上训练,并在RoadScene和TNO数据集上直接测试。
5.1. 定性结果
不同算法在RoadScene数据集上的定性比较如图10-12所示。

 可以注意到,所有算法在显著目标区域保持了强度分布。然而,GTF和FusionGAN无法保留目标的锐利边缘。此外,其他方法,尤其是GTF、FusionGAN、DRF、CSF和PMGI,遭受不同程度的光谱污染,这可以从天空区域观察到。如图10的红色框所示,GTF、IFCNN和U2Fusion在融合结果中引入了伪影,降低了融合图像的视觉效果。此外,其他方法因信息整合不足而丢失了可见光图像的纹理细节(例如图11和图12的红色框)。我们的方法通过CMDAF模块和半路融合方式完全整合了源图像的互补和共同特征。因此,上述问题(如热目标退化、光谱污染和纹理模糊)在我们的融合结果中未出现。不同方法在TNO数据集上的可视化结果如图13-15所示。
可以注意到,所有算法在显著目标区域保持了强度分布。然而,GTF和FusionGAN无法保留目标的锐利边缘。此外,其他方法,尤其是GTF、FusionGAN、DRF、CSF和PMGI,遭受不同程度的光谱污染,这可以从天空区域观察到。如图10的红色框所示,GTF、IFCNN和U2Fusion在融合结果中引入了伪影,降低了融合图像的视觉效果。此外,其他方法因信息整合不足而丢失了可见光图像的纹理细节(例如图11和图12的红色框)。我们的方法通过CMDAF模块和半路融合方式完全整合了源图像的互补和共同特征。因此,上述问题(如热目标退化、光谱污染和纹理模糊)在我们的融合结果中未出现。不同方法在TNO数据集上的可视化结果如图13-15所示。
 从图13的红色框可以看出,MDLatLRR、DenseFuse和U2Fusion削弱了显著目标。此外,DRF和FusionGAN模糊了热目标的边缘,并在背景区域遭受严重的光谱污染。只有我们的方法、CSF、IFCNN和PMGI成功保持了显著目标的强度并保留了可见光图像的纹理细节。类似的现象可以在图14和图15中找到。值得强调的是,与其他替代方法相比,我们的渐进式融合网络有效地保留了可见光图像的纹理细节,这可以从图14和图15的红色框中观察到。
从图13的红色框可以看出,MDLatLRR、DenseFuse和U2Fusion削弱了显著目标。此外,DRF和FusionGAN模糊了热目标的边缘,并在背景区域遭受严重的光谱污染。只有我们的方法、CSF、IFCNN和PMGI成功保持了显著目标的强度并保留了可见光图像的纹理细节。类似的现象可以在图14和图15中找到。值得强调的是,与其他替代方法相比,我们的渐进式融合网络有效地保留了可见光图像的纹理细节,这可以从图14和图15的红色框中观察到。

 因此,在各种数据集上的广泛可视化结果证明了我们的算法在显著目标保持和纹理保留方面的优越性。我们将优势归因于以下方面。一方面,我们定义了光照感知损失,约束网络根据特定光照条件整合有意义信息。另一方面,我们设计了跨模态差异感知融合模块,完整融合红外和可见光图像的互补信息。
因此,在各种数据集上的广泛可视化结果证明了我们的算法在显著目标保持和纹理保留方面的优越性。我们将优势归因于以下方面。一方面,我们定义了光照感知损失,约束网络根据特定光照条件整合有意义信息。另一方面,我们设计了跨模态差异感知融合模块,完整融合红外和可见光图像的互补信息。
5.2. 定量结果
我们还从RoadScene和TNO数据集中选择了25对图像对进行定量评估。不同方法在四个指标上的比较结果如图16和图17所示。
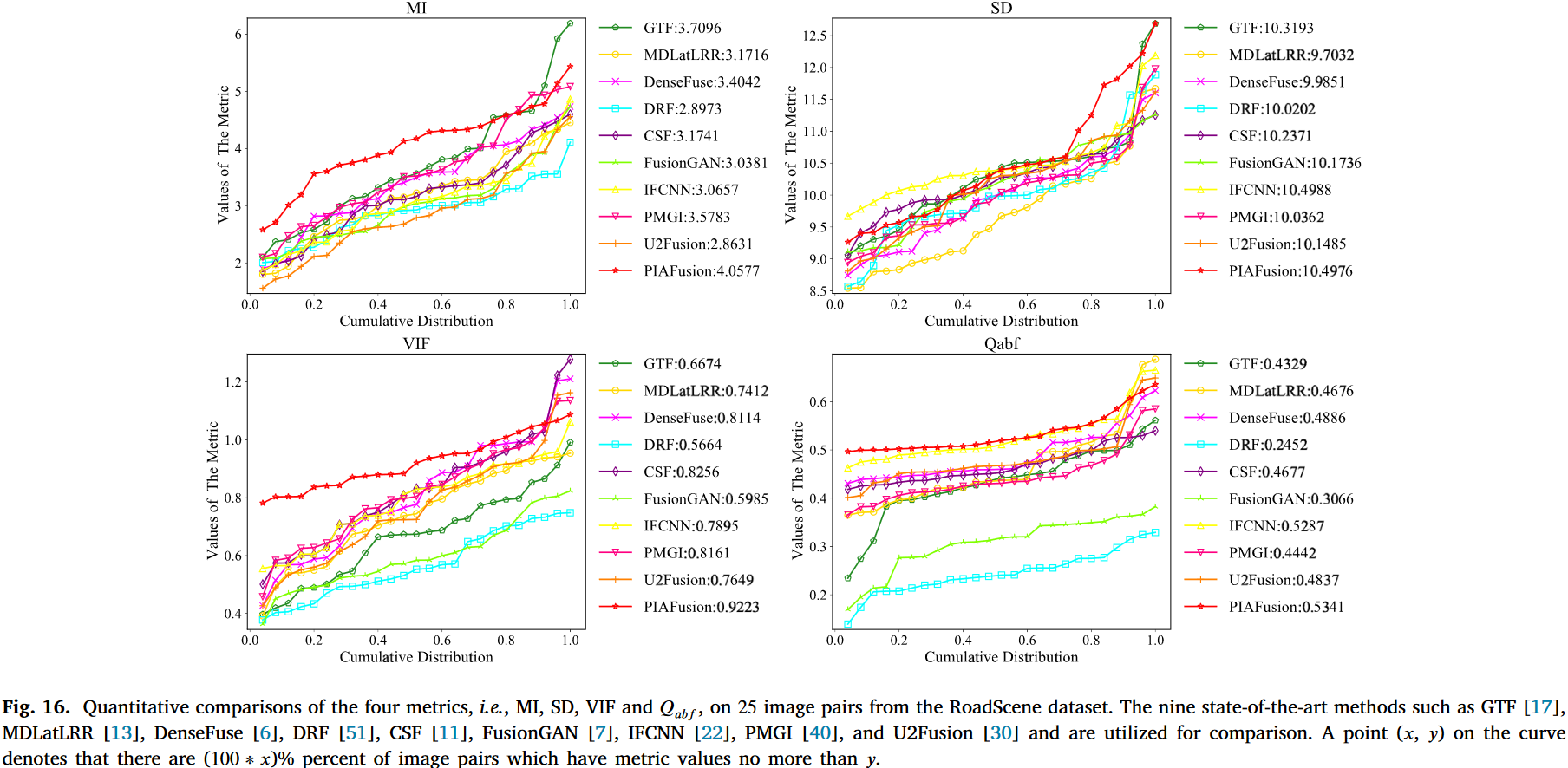
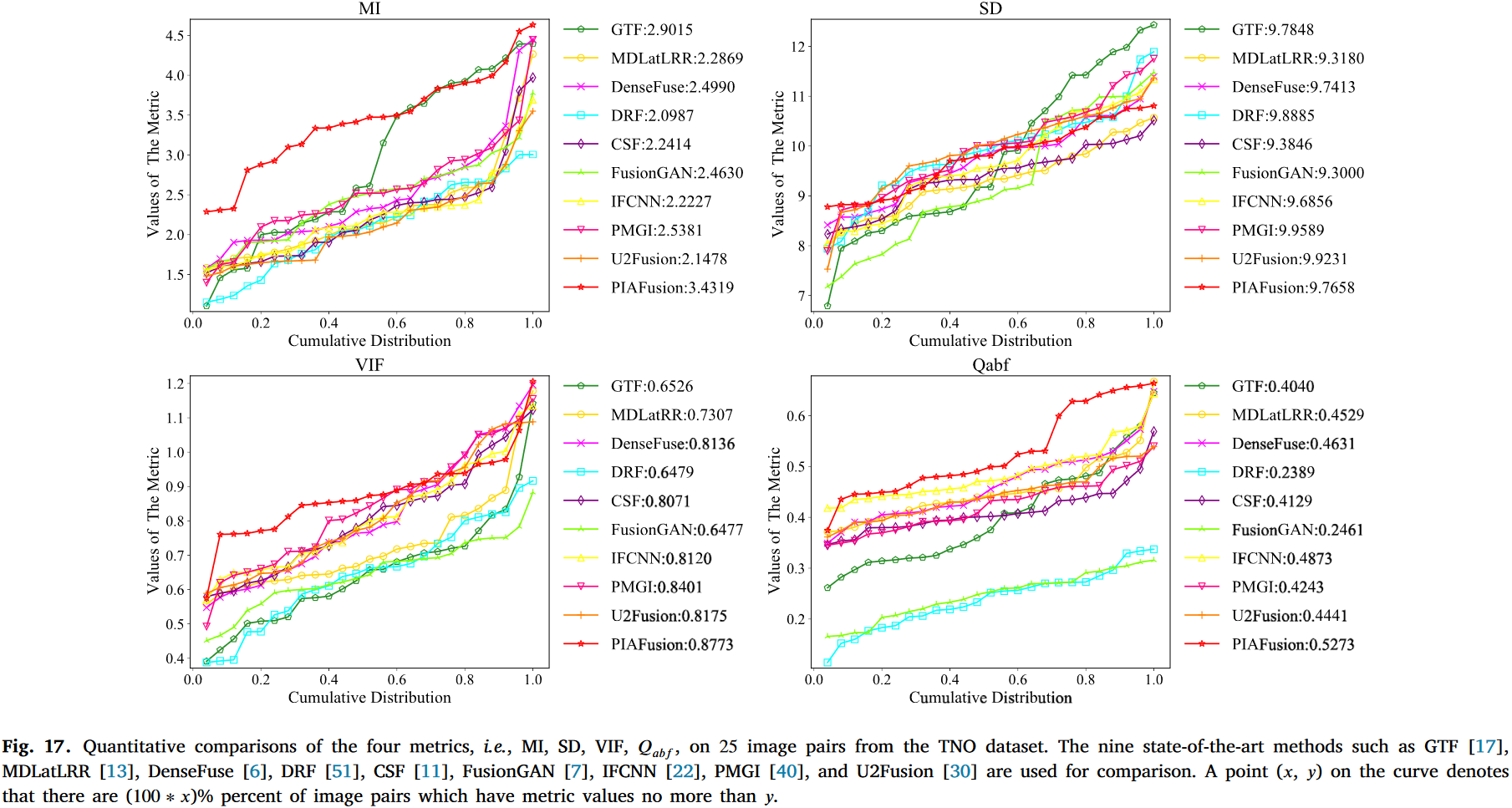 从图16可以看出,PIAFusion在MI和VIF指标上表现出明显的优越性。这些结果意味着我们的方法可以将更多信息从源图像传递到融合图像,并生成令人满意的融合结果。在
从图16可以看出,PIAFusion在MI和VIF指标上表现出明显的优越性。这些结果意味着我们的方法可以将更多信息从源图像传递到融合图像,并生成令人满意的融合结果。在指标上,我们的方法也排名第一,表明PIAFusion保留了足够的边缘信息。此外,提出的方法在SD指标上仅以微小差距落后于IFCNN。如图17所示,PIAFusion在MI、VIF和
指标上以显著优势排名第一。对于SD指标,我们的方法仅具有可比较的性能。这是合理的,因为TNO数据集主要包含白天场景,我们的方法在白天倾向于保持可见光图像的强度,从而降低了融合图像的对比度。总之,定性和定量结果均表明PIAFusion具有出色的泛化性能。此外,我们提出的方法有效保持了目标区域的强度分布,并保留了背景区域的纹理细节,受益于所提出的光照感知损失和CMDAF模块。
6. 效率比较
为了全面评估不同算法,我们在表3中提供了不同方法的平均运行时间。
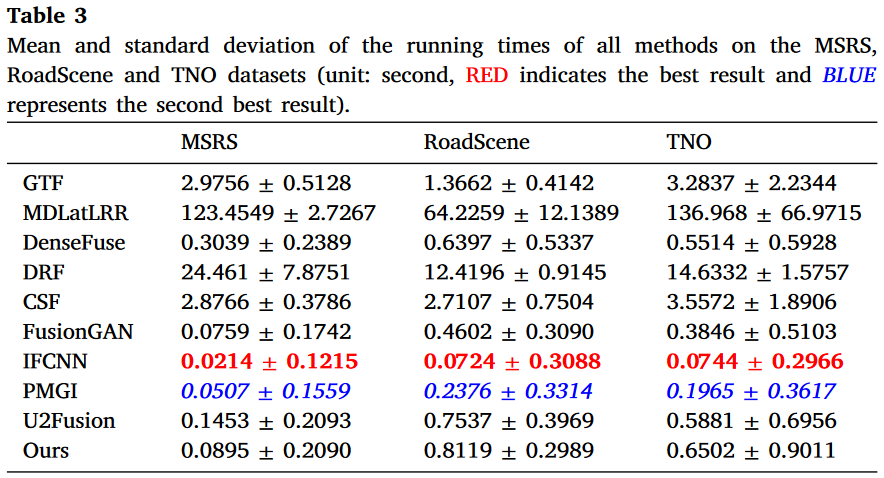 可以观察到,传统方法在合成融合图像时耗费更多时间。特别是,MDLatLRR通过多尺度分解获取低秩表示,极其耗时。相比之下,数据驱动方法在运行效率方面表现出明显优势,受益于GPU加速。尤其是IFCNN在所有数据集上是最快的算法。我们的渐进式融合网络通过跨模态差异感知融合模块实现互补特征的预融合,并以拼接方式整合共同和互补信息。因此,我们的PIAFusion相对耗时。幸运的是,我们的方法仍与其他方法具有可比较的运行效率。
可以观察到,传统方法在合成融合图像时耗费更多时间。特别是,MDLatLRR通过多尺度分解获取低秩表示,极其耗时。相比之下,数据驱动方法在运行效率方面表现出明显优势,受益于GPU加速。尤其是IFCNN在所有数据集上是最快的算法。我们的渐进式融合网络通过跨模态差异感知融合模块实现互补特征的预融合,并以拼接方式整合共同和互补信息。因此,我们的PIAFusion相对耗时。幸运的是,我们的方法仍与其他方法具有可比较的运行效率。
7. 自适应特征选择
所提出的框架能够在光照场景的指导下,通过精心设计的损失函数隐式实现特征提取、特征选择和图像重建。为了直观展示融合网络根据光照变化的隐式特征选择功能,我们分别在白天和夜间场景中提供了特征整合阶段后的部分特征图,如图18和图19所示。

 可以观察到,我们的融合模型能够在光照感知损失的指导下,根据光照条件有目的地实现特征选择。在白天场景中,我们的融合网络能够很好地保留可见光特征,同时将少量红外特征信息整合到融合特征图中作为补充。相反,在夜间场景中,融合特征主要继承红外特征图的分布,同时也整合了少量可见光特征的细粒度细节。这些可视化结果证明,我们的神经网络能够如预期根据光照变化实现有效特征选择。
可以观察到,我们的融合模型能够在光照感知损失的指导下,根据光照条件有目的地实现特征选择。在白天场景中,我们的融合网络能够很好地保留可见光特征,同时将少量红外特征信息整合到融合特征图中作为补充。相反,在夜间场景中,融合特征主要继承红外特征图的分布,同时也整合了少量可见光特征的细粒度细节。这些可视化结果证明,我们的神经网络能够如预期根据光照变化实现有效特征选择。
8. 语义分割应用
我们研究了红外与可见光图像融合对语义分割[55]的积极作用。具体来说,我们分别在源图像和融合图像上训练语义分割算法[56]。我们选择了1000张图像作为训练集,并在360张图像上测试不同模型的分割性能。可视化结果和定量比较如图20和表4所示。
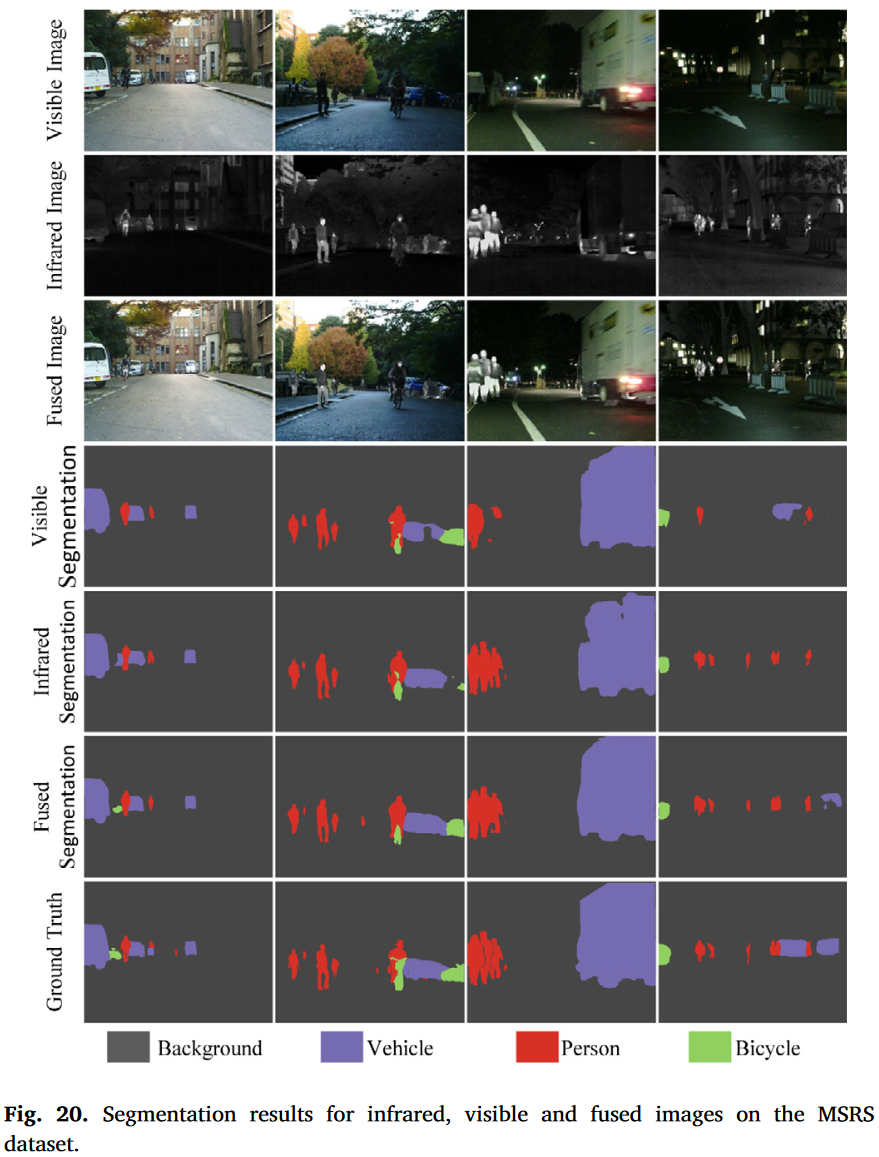
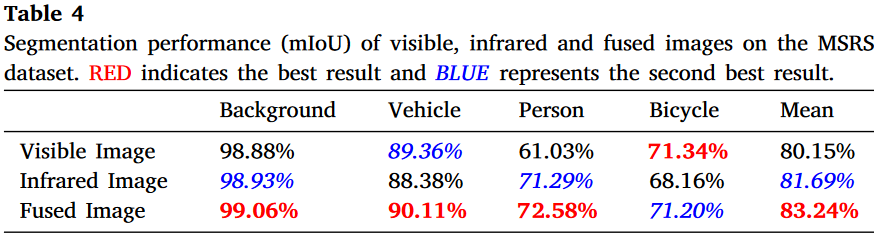 在白天场景中,可见光图像包含大量有意义信息,因此在可见光图像上执行的分割在白天具有高准确性。然而,由于夜间光照较差,可见光传感器无法捕获足够信息。因此,分割网络在夜间无法有效分割对象,尤其是人。相反,红外图像捕获热信息,即使在极端光照条件下也能突出目标(如行人)。因此,分割网络在红外图像上分割人的准确性高于可见光图像。然而,红外图像对车辆和自行车的信息有限,这降低了车辆和自行车的分割准确性。值得一提的是,我们的渐进式融合网络充分整合了源图像的有意义信息。此外,多模态图像中的互补特征有助于增强融合图像的语义信息。因此,我们的车辆和行人分割性能优于单模态图像。此外,自行车分割准确性与可见光图像相当。最后,融合图像上的平均分割准确性高于红外和可见光图像。
在白天场景中,可见光图像包含大量有意义信息,因此在可见光图像上执行的分割在白天具有高准确性。然而,由于夜间光照较差,可见光传感器无法捕获足够信息。因此,分割网络在夜间无法有效分割对象,尤其是人。相反,红外图像捕获热信息,即使在极端光照条件下也能突出目标(如行人)。因此,分割网络在红外图像上分割人的准确性高于可见光图像。然而,红外图像对车辆和自行车的信息有限,这降低了车辆和自行车的分割准确性。值得一提的是,我们的渐进式融合网络充分整合了源图像的有意义信息。此外,多模态图像中的互补特征有助于增强融合图像的语义信息。因此,我们的车辆和行人分割性能优于单模态图像。此外,自行车分割准确性与可见光图像相当。最后,融合图像上的平均分割准确性高于红外和可见光图像。
9. 消融研究
9.1. 光照感知损失分析
我们设计了光照感知损失来指导渐进式融合网络的训练,考虑到不同光照条件下不同源图像包含有意义信息。为了验证光照感知损失的合理性,我们进行了关于光照感知损失的消融实验。更具体地说,我们设置并保持其他配置不变。一些典型示例如图21所示。
 可以观察到,没有光照感知损失,渐进式融合网络无法自适应融合红外和可见光图像的有意义信息。特别是,白天场景中的融合图像遭受光谱污染和纹理模糊。此外,渐进式融合模型在夜间无法保持热目标的对比度或用红外图像中的细节信息补偿背景区域。相反,我们的PIAFusion根据光照条件自适应实现对比度保持和纹理保留。
可以观察到,没有光照感知损失,渐进式融合网络无法自适应融合红外和可见光图像的有意义信息。特别是,白天场景中的融合图像遭受光谱污染和纹理模糊。此外,渐进式融合模型在夜间无法保持热目标的对比度或用红外图像中的细节信息补偿背景区域。相反,我们的PIAFusion根据光照条件自适应实现对比度保持和纹理保留。
9.2. 跨模态差异感知融合模块分析
我们融合模型的另一个重要组成部分是跨模态差异感知融合模块,它预融合多模态图像的互补信息。因此,我们还实施了关于CMDAF模块的消融实验,并展示了实验结果,如图21所示。在消融实验中,我们从特征提取器中移除CMDAF模块,这意味着红外和可见光图像的特征通过半路融合策略合并。从结果中,我们可以发现,白天场景中的融合图像保留了可见光图像的纹理细节,但削弱了显著目标。此外,夜间融合图像类似于红外图像,但忽略了可见光图像中的一些细节信息。相比之下,我们的渐进式融合网络同时保持了显著目标的强度分布并保留了背景区域的纹理细节。因此,所提出的PIAFusion根据光照条件自适应合并共同和互补信息,受益于我们的特殊设计,即光照感知损失和跨模态差异感知融合模块。
5.2实验解析
这段文本是论文第4节“实验验证”,详细介绍了PIAFusion的实验设计、数据集构建、比较实验、泛化实验、效率分析、特征选择验证、应用验证和消融研究。
1. 数据集构建
- MSRS数据集:
- 基于MFNet数据集(1569对图像,820白天+749夜间,分辨率480×640)。
- 移除125对未对齐图像,保留715白天+729夜间,共1444对。
- 使用暗通道先验算法增强红外图像,改善信噪比和对比度。
- 评价:
- 优势:MSRS数据集规模适中,覆盖白天/夜间场景,适合验证光照感知融合。增强红外图像质量提升了训练可靠性。
- 局限性:
- 未说明未对齐图像的具体标准,可能影响数据集一致性。
- 暗通道先验可能引入伪影,未讨论增强算法对融合性能的影响。
- 数据集场景多样性有限(仅道路场景),可能限制泛化性。
2. 实验配置
- 数据集:MSRS、RoadScene、TNO。
- 对比方法:
- 传统:GTF、MDLatLRR。
- 基于AE:DenseFuse、DRF、CSF。
- 基于GAN:FusionGAN。
- 基于CNN:IFCNN、PMGI、U2Fusion。
- 评估指标:
- 互信息(MI):信息传递量。
- 标准差(SD):对比度和分布。
- 视觉信息保真度(VIF):视觉质量。
: 边缘信息保留。
- 评价:
- 指标选择:四个指标覆盖信息论、统计学和人类视觉,全面且合理。但缺乏主观评分,可能无法完全反映用户感知。
- 对比方法:涵盖传统和深度学习方法,代表性强。但部分方法(如FusionGAN)较老,可能无法体现最新进展。
- 公平性:使用公开实现和原论文参数,确保可重复性。
3. 实现细节
- 训练:
- 光照感知子网络:427白天+376夜间图像,裁剪为64×64块,共56,280块。
- 融合网络:752对图像(26,320块/场景)。
- 数据增强:裁剪+归一化。
- 标签:独热编码(白天[1,0],夜间[0,1])。
- 训练策略:先训练子网络,再用预训练子网络指导融合网络。
- 超参数:批大小、epoch、学习率明确,损失权重 λ1=3,λ2=7,λ3=50 =3,。
- 测试:
- 直接输入源图像,融合后转换YCbCr空间保留颜色。
- 硬件:NVIDIA TITAN V GPU,Intel Xeon CPU。
- 评价:
- 训练设计:分阶段训练合理,避免子网络和融合网络相互干扰。数据增强增加样本量,缓解过拟合。
- 超参数:权重设置基于经验,未提供调优细节,可能影响再现性。
- 颜色处理:YCbCr转换保留彩色信息,适合实际应用,但未讨论对灰度数据集(如TNO)的影响。
4. 比较实验
4.1 定性结果
- 白天场景(图5-7):
- PIAFusion和PMGI保留纹理细节,GTF/FusionGAN丢失细节,其他方法有光谱污染。
- PIAFusion避免削弱红外目标,优于PMGI(后者引入伪信息)。
- 夜间场景(图8-9):
- PIAFusion整合红外纹理和可见光细节,优于其他方法(丢失树干/文字或引入噪声)。
- 评价:
- 优势:PIAFusion在光照感知下自适应融合,白天突出纹理,夜间保留目标和细节。
- 局限性:
- 仅展示5张图像,样本量小,未覆盖复杂场景(如雾天)。
- 红/绿/蓝框标注直观,但未提供量化污染程度。
4.2 定量结果
- MSRS(150对图像,表2):
- PIAFusion在MI、SD、VIF、
- MI高:信息传递最多。
- SD/VIF高:高对比度和视觉质量。
- PIAFusion在MI、SD、VIF、
- 评价:
- 意义:全面领先证明光照感知和CMDAF模块的有效性。
- 问题:未提供统计显著性分析(如p值),难以判断优势的稳健性。
5. 泛化实验
5.1 定性结果
- RoadScene(图10-12):
- PIAFusion避免伪影、光谱污染,保留纹理和目标。
- GTF/FusionGAN边缘模糊,其他方法丢失细节。
- TNO(图13-15):
- PIAFusion与CSF/IFCNN/PMGI保留目标和纹理,但PIAFusion纹理更优。
- 评价:
- 优势:在未训练的数据集上表现优异,证明泛化能力强。
- 局限性:TNO以白天为主,可能未充分验证夜间泛化。
5.2 定量结果
- RoadScene/TNO(25对图像,图16-17):
- MI/VIF/
- SD: RoadScene稍逊IFCNN,TNO与主流相当(因白天倾向可见光,降低对比度)。
- MI/VIF/
- 评价:
- 意义:跨数据集验证了PIAFusion的信息传递和边缘保留能力。
- 问题:SD较低可能因光照权重过于偏向可见光,未分析权重对指标的影响。
6. 效率比较
- 表3:
- 传统方法(MDLatLRR)最慢,因多尺度分解。
- 数据驱动方法更快,IFCNN最快。
- PIAFusion耗时中等,因CMDAF和拼接。
- 评价:
- 现实性:PIAFusion效率可接受,但未达最优。
- 改进方向:优化CMDAF(如减少层数)可提升实时性。
7. 自适应特征选择
- 图18-19:
- 白天:融合特征偏向可见光,补充少量红外信息。
- 夜间:偏向红外,整合可见光细节。
- 评价:
- 创新:可视化证明光照感知损失指导特征选择。
- 局限性:
- 仅展示部分特征图,未量化选择效果。
- 未比较其他方法的特征分布。
8. 语义分割应用
- 实验:
- 训练:1000张图像。
- 测试:360张图像。
- 结果(图20,表4):
- 白天:可见光分割准确性高,夜间较差。
- 红外:夜间行人分割优,但车辆/自行车较差。
- PIAFusion:行人/车辆优于单模态,自行车与可见光相当,均值最高。
- 评价:
- 意义:融合图像增强语义信息,验证PIAFusion的高级任务潜力。
- 问题:
- 未说明分割算法细节(如损失函数)。
- 测试样本量小,未覆盖边缘场景。
9. 消融研究
9.1 光照感知损失
- 实验:固定
- 结果(图21):
- 无光照感知:白天光谱污染、纹理模糊,夜间丢失对比度和细节。
- PIAFusion:自适应保留对比度和纹理。
- 评价:
- 验证:光照感知损失对自适应融合至关重要。
- 局限性:仅比较固定权重,未测试其他动态权重策略。
9.2 CMDAF模块
- 实验:移除CMDAF,仅用半路融合。
- 结果(图21):
- 无CMDAF:白天削弱目标,夜间丢失可见光细节。
- PIAFusion:平衡目标和纹理。
- 评价:
- 验证:CMDAF提升互补信息整合。
- 局限性:未分析CMDAF不同层的贡献,可能存在冗余。
六. 结论
在这项工作中,我们提出了一种基于光照感知的渐进式红外与可见光图像融合框架,称为 PIAFusion,该框架根据光照条件自适应地整合有意义的信息。我们设计了一个光照感知子网络来估计输入图像的光照分布并计算光照概率。此外,光照概率被用于构建光照感知损失函数。在光照感知损失函数的指导下,融合网络通过跨模态差异感知融合模块和半路融合策略,自适应地融合共同信息和互补信息。因此,渐进式融合网络能够全天候生成包含显著目标和丰富纹理信息的融合图像。此外,我们构建了一个新的红外与可见光数据集,称为多光谱道路场景(MSRS),用于图像融合的训练和基准评估。我们进行了广泛的实验,证明了我们的方法在目标保持、纹理保留和光照适应方面的优越性。此外,在语义分割上的扩展实验证明了我们提出的方法在高级视觉任务中的潜力。