LLM-as-Judge真的更偏好AI输出?
论文标题
Do LLM Evaluators Prefer Themselves for a Reason?
论文地址
https://arxiv.org/pdf/2504.03846
代码地址
https://github.com/wlchen0206/llm-sp
作者背景
弗吉尼亚大学,乔治华盛顿大学
实践建议
- 在将LLM部署为评估器之前,应严格评估其在目标任务上的效果;
- 尽可能使用更大的模型作为评估器,并采用test-time scaling;
- 可以使用多组评估器分别评估各自擅长的任务
动机
得益于LLM强大的通用能力,学术界与各工业界越来越喜欢使用大模型来作为评估器,即LLM-as-judge。然而这种评估方法可能存在比较多的偏见,比如更喜欢自己产生的输出、更长更详细的输出、特定风格的输出等等,其中“更长更详细”、“特定风格”等偏好是显式的,基本上可以通过提示词来优化,而“自己产生的输出”是隐式的,不体现为某一具体特征,所以无法通过提示词来限制与优化
本文旨在系统性探究“自我偏好”的真实性,以及相应的优化手段
本文方法
在存在客观正确答案的任务上(数学、事实、代码)进行验证,着重考察以下3个量化指标:
- 自我偏好比率: 评估器偏好自己生成结果的比例。
- 合法自我偏好比率: 评估器偏好自己生成结果,且结果是正确的比例。
- 有害自我偏好倾向: 评估器偏好自己生成的错误结果的比例。
实验结果
测试对象:
- 评估器: Llama、Qwen、Gemma、Mistral、Phi、GPT和DeepSeek等涵盖多种的参数规模;
- 被评估者: Llama-3.2-1B、Gemma-2-2B、Mistral-7B
一、更好的生成器就是更好的评估器
各尺寸、家族的大模型,评估准确性与它们自己完成相应任务的准确性高度相关
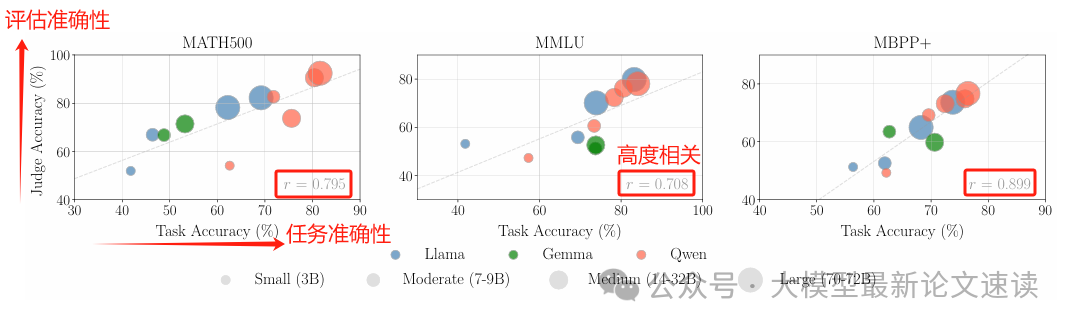
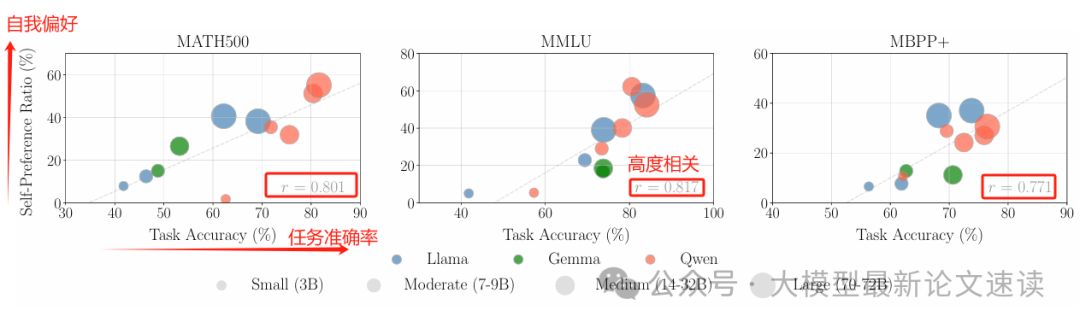
二、自我偏好确实存在,但大部分情况下是正确的
下图可见,越大尺寸的模型自我偏好越强,但同时其准确率也越强,即大部分“偏见”都是正确的
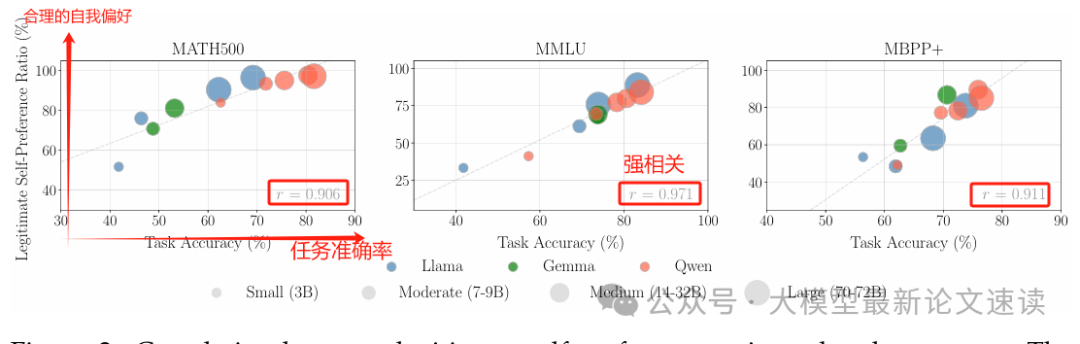
错误的自我偏好确实存在,但未必体现“模型越强偏见越大”
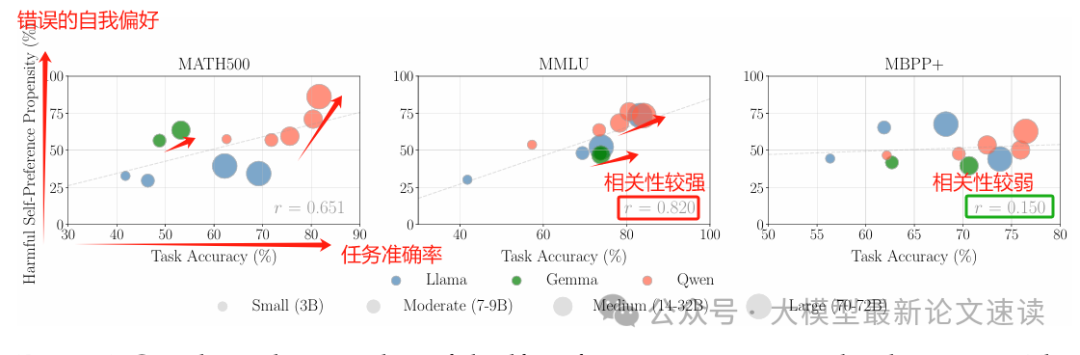
三、推理越长,有害的偏好越少
