c++模版进阶
文章目录
- C++模版进阶
- 非类型模版参数
- 模板的特化
- 概念
- 函数模版的特化
- 类模版的特化
- 全特化
- 偏特化(半特化)
- 模版分离编译
- 模版总结
- 结语
欢迎进入我的博客,给生活加点impetus!!开启今天的编程之路!!
我们今天学习模版进阶,探索深层的模版之美!!
作者:٩( ‘ω’ )و260
我的专栏:C++初阶,数据结构初阶,题海探骊,c语言
感谢点赞,关注!!

C++模版进阶
非类型模版参数
模板参数分类类型形参与非类型形参
类型形参即:出现在模板参数列表中,跟在class或者typename之类的参数类型名称。即自定义类型
非类型形参,就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中可将该参数当成常量来使用。注意:在c++20之前的时候,浮点数以及自定义类型如string是不能做非类型模版参数的。
来看一个代码:
namespace bite
{// 定义一个模板类型的静态数组template<class T, size_t N = 10>class array{public:T& operator[](size_t index) { return _array[index]; }const T& operator[](size_t index)const { return _array[index]; }size_t size()const { return _size; }bool empty()const { return 0 == _size; }private:T _array[N];size_t _size;};
}
也许你想问,问什么不能够使用#define来定义常量呢?
假设这段代码:
#define N 10
int a[N];//想要20的空间
int b[N];//想要100的空间
这种情形的话#定义常量是不能够完成的。
同时,我还想要介绍另外一个知识点:

有一个容器也是静态数组,那我们直接array<int,10> a1和int a2[10]有什么区别呢?
结论:区别不大,主要体现在越界访问时的处理问题:
静态数组:越界读,不检查,越界写,抽查,会设立标记位,只会在数组后面的一或两个位置上标记,后面下标越界写的话会检查不到的。
array数组:越界读和越界写都能够检查到
检查错误的方式,断言检查,直接强制中断,抛异常检查,捕获后程序还能够正常运行
这里因为是下标的解引用,是断言报错检查。
但是,array数组是不会初始化的,与其用array数组,本人更推荐vector,因为vector是能够进行初始化的
总结:
1.浮点数、类对象以及字符串是不允许作为非类型模板参数的。
2.非类型的模板参数必须在编译期就能确认结果。
模板的特化
概念
通常情况下,使用模板可以实现一些与类型无关的代码,但对于一些特殊类型的可能会得到一些错误的结果,需要特殊处理。
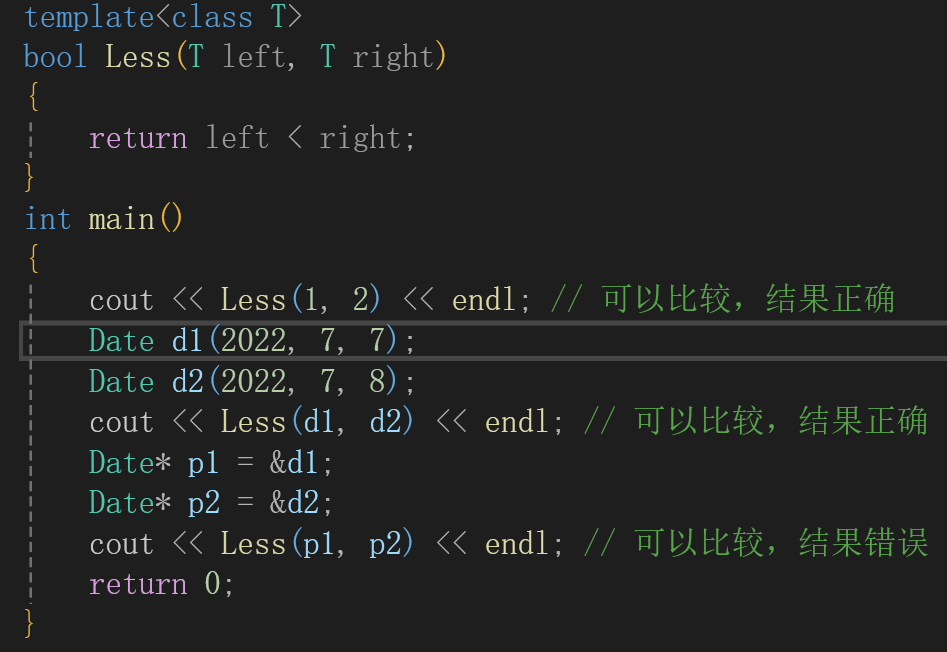
可以看到,Less绝对多数情况下都可以正常比较,但是在特殊场景下就得到错误的结果。上述示例中,p1指向的d1显然小于p2指向的d2对象,但是Less内部并没有比较p1和p2指向的对象内容,而比较的是p1和p2指针的地址,这就无法达到预期而错误。
此时,就需要对模板进行特化。即:在原模板类的基础上,针对特殊类型所进行特殊化的实现方式。模板特化中分为函数模板特化与类模板特化。
函数模版的特化
模版特化-模版特殊化处理,理解为直接对模版进行显示实例化。
前提:一定要有原模版,在此基础上,对原模版进行特化,两个模版构成重载,传参会调用更加匹配的模版
来看特化步骤:
函数模板的特化步骤:
1.必须要先有一个基础的函数模板
2.关键字template后面接一对空的尖括号<>(里面是没有东西的)
3.函数名后跟一对尖括号,尖括号中指定需要特化的类型
4.函数形参表: 必须要和模板函数的基础参数类型完全相同,如果不同编译器可能会报一些奇怪的错误。
来看上例,我们对Date*的数据类型来进行特化:
template<class T>
bool Less(T left,T right)
{return left < right;
}
template<>
bool Less<Date*>(Date* left,Date*right)
{return *left<*right;
}
int main()
{Date* p1 = &d1;Date* p2 = &d2;cout << Less(p1, p2) << endl; // 调用特化之后的版本,而不走模板生成了,有现成吃现成
}
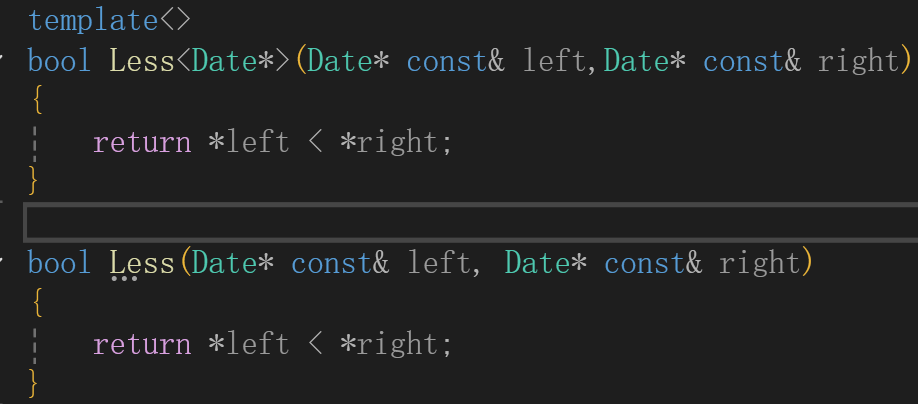
细心的话你能够发现,这里面不就是很类似一个函数重载吗?其实,我们很少使用函数模版特化,更偏向于函数重载,因为能够实现相同的功能,而且函数模版特化有一个肯考验语法的问题,来看下方示例:

奇怪了,我这里明明是是写函数模版的特化,为啥这里他说这里不是函数模版的特化呢?
本质在于这里的const。
来看上述非模版特化中const是不是修饰的是left,模版特化中const修饰什么了?是不是修饰*left了,所以我们应该将const修改至 *号的后面。改之后:

总结:涉及const与指针的位置,const在 *号前面,修饰 *变量,反之只修饰变量,反正注意const的位置就行了。
如果我们又存在函数重载,又存在模版特化的时候会优先匹配哪一个呢?
来看结果:

类模版的特化
类模版的特化与函数模版的特化有什么区别呢?
类模版只能够特化,函数模版既能够特化,又能够写函数重载
我们来看一个示例即可:
template<class T1, class T2>
class Data
{
public:Data() { cout << "Data<T1, T2>" << endl; }
private:T1 _d1;T2 _d2;
};
全特化
如果我们对模版参数T1和T2全部进行特化,这样就叫做全特化
看代码:
template<>
class Data<int, char>
{
public:Data() { cout << "Data<int, char>" << endl; }
private:int _d1;char _d2;
};
偏特化(半特化)
如果我们只对类模版参数中部分模版参数进行特化,这样就叫做偏特化:
看代码:
template<class T2>
class Data<int>
{
public:Data() { cout << "Data<int, T2>" << endl; }
private:int _d1;T2 _d2;
};
偏特化还有一个作用,就是对于参数进一步限制
偏特化并不仅仅是指特化部分参数,而是针对模板参数更进一步的条件限制所设计出来的一个特化版本。来看下例代码:

当我们使用偏特化来进行参数限制的时候,template中模版参数不用删,因为能保证多个数据类型能够来声明多种数据类型不同的变量。
例如:T为int,T为int,这样下方代码可以用T,也可以用T*
模版分离编译
一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件链接起来形成单一的可执行文件的过程称为分离编译模式。
在预处理和编译和链接中我们已经提到过,这里我们简单复习一下,不理解的话可以跳转这两篇文章重新理解:

从上述的过程中我们是可以发现的,除了.h文件以外,因为在预处理的时候,.h文件已经被展开了,不同的cpp文件在链接之前是独自走独自的过程的,最终生成一个obj文件,在链接之前,各个文件是分离编译的。
有了前面的基础,我们先来说明一个结论:
函数模版和类模版声明和定义不能分离,如果实在需要分离,需要分离在一个文件中。
倘若我们分离,是一定会发生错误的,这里1发生的是链接错误。接下来我们来讲解具体原理。
首先,先来讲解,为什么有点h文件和源文件呢,就是为什么会存在定义和声明分离呢?
1:方便模块化管理,所有文件的代码合并成一个文件的话这样会造成代码的可视化降低。
2:在一些项目售卖的时候,只给出头文件,包含类和成员函数,不给出核心实现代码。
其次:函数声明的时候我们是不会生成二进制指令的,因为函数声明的时候只是一个承诺,告诉编译器我有这个函数,必须是在函数定义的时候才会生成指定的二进制指令,函数的地址就是整个函数生成的二进制指令中的第一个二进制指令的地址。有了这个函数的地址,在汇编完成生成二进制指令的时候,call的这个地址就会被填上,说明我此时需要去调用这个函数。
我们来看这样一个案例:

此时我的模版是声明和定义分离到两个文件了,此时我的a.cpp文件如果运行到汇编已经生成.obj文件的时候,请问里面有没有这个定义的二进制指令呢?
答案是没有的。
因为我这里是一个模版,因为在a.cpp文件中,里面只包含了a.h头文件,由于前面是分离编译的,所以在汇编的时候,编译器是不知道a.cpp中的T是什么,因为我们还没有给他实例化。所以此时我们还没有关于Add函数的二进制指令。
在main.cpp文件中,我包含了a.h头文件,在这里,我们能够发现模版参数T是被实例化为整形和浮点型的,为什么呢?因为我们传递的参数是整形和浮点型,此时我去调用的话,我发现我还没有Add函数的定义,找不到这个函数,所以这个时候会报错链接错误。
那我们该怎么解决这个问题呢?
首先还是前面提到的,不管是类模版还是函数模版,声明和定义都不要分离到两个文件中如果你铁了心要分离,那我们直接就先给模版显示实例化即可。但是这种方法只是语法上支持,现实其实可能会包含很多冗余代码:
来看代码:
// 显式实例化定义,针对int类型
template int Add<int>(const int& left, const int& right);
// 显式实例化定义,针对double类型
template double Add<double>(const double& left, const double& right);
注意: 这里我只是对我已经实现的Add函数的声明,声明的话这里template后面可以不用添加<>
在这里声明也是可以编译得过去的,定义也肯定能够编译得过去的,但是定义就要写<>了
// 显式实例化定义,针对int类型
template<> int Add<int>(const int& left, const int& right)
{return left+right;
}
// 显式实例化定义,针对double类型
template<> double Add<double>(const double& left, const double& right)
{return left+right;
}
由于版本原因,这里可能2022和2019可能实现的略有差异。
这里我们再来看一个例子,我们显示实例化的话是直接:

来看代码,显示实例化:
// 显示实例化
template
void Print<vector<int>>(const vector<int>& con);// 显示实例化
template
void Print<list<int>>(const list<int>& con);
还有其他类型,还需要显示实例化,太麻烦
总结:
1:模板,建议直接在.h定义,或者声明和定义分离的话,就分离在.h文件,不要把定义分离到.cpp
2:本质不需要链接了,因为哪个.cpp用这个模板,直接就可以实例化,编译阶段就有地址,直接确定地址,不需要链接了
3:2022版本下,函数模版的实例化只写声明也是可以实现我的需求的,此时可以不用写<>,当然,也可以写出来定义,但是此时需要写<>,后面的模版参数T记得替换成实例化的类型。(不是很重要,了解即可)
最后还有一个知识点:
我们先俩看一段代码:
template<class Container>
void Print(const Container& con)
{Container::const_iterator it = con.begin();while (it != con.end()){cout << *it << " ";++it;}cout << endl;
}
这里我的目标是实现一个泛型的打印迭代器中的数据,请问这里有问题没有呢?
答案是有的。这里会报错缺分号。
因为我的模版参数Container(目标是代表容器)不知道传递容器是什么,但是后面有访问限定符::,Container肯定是命名空间域或者是类域,那么编译器大致可以推测const_iterator要么是一个变量,要么是一个类型,由于前面是模版,Container肯定是类域,这里不可能将命名空间域设置成一个模版吧,那么const_iterator到底是什么呢?我们本质是想要这个是一个迭代器,但是由于没有实例化,我需要告诉编译器这里是一个类型,所以前面需要加上typename,表示类型。因为只是一个模版参数,编译器也不干去这个模版参数中找。
改为:
typename Container::const_iterator it = con.begin();
总结:
1:如果此时模版没有实例化的时候,比如函数模版的情形,我需要取这个模版中的数据类型(假设这个模版此时为自定义类型),前面一定需要加上typename表示我这里要取的是这个自定义类型中的类型。
2:如果代码报错缺分号,大概率是类型出了问题
模版总结
优点:
1.模板复用了代码,节省资源,更快的迭代开发,C++的标准模板库(STL)因此而产生
2.增强了代码的灵活性
缺点:
1.模板会导致代码膨胀问题,也会导致编译时间变长
2.出现模板编译错误时,错误信息非常凌乱,不易定位错误
结语
感谢大家阅读我的博客,不足之处欢迎评论区指正讨论,感谢大家支持!!
天行健,君子以自强不息。地势坤,君子以厚德载物
加油!!
