【HDFS入门】HDFS性能调优实战:从基准测试到优化策略
目录
引言
1 HDFS性能评估体系
1.1 性能评估体系架构
1.2 基准测试工具对比
2 TestDFSIO基准测试实战
2.1 TestDFSIO工作原理
2.2 测试执行步骤
2.3 结果分析指标
3 TeraSort基准测试实战
3.1 TeraSort测试流程
3.2 测试执行命令
3.3 关键性能指标
4 HDFS性能调优策略
4.1 配置优化矩阵
4.2 数据分布优化
4.3 硬件配置建议
5 性能监控与分析
5.1 监控指标体系
5.2 关键监控命令
6 总结与最佳实践
引言
在大数据平台运维和开发过程中,HDFS集群的性能直接影响着整个数据处理管道的效率。本文将带您全面了解HDFS性能评估与调优的实战方法,重点介绍如何使用TestDFSIO和TeraSort进行基准测试以及性能优化策略。
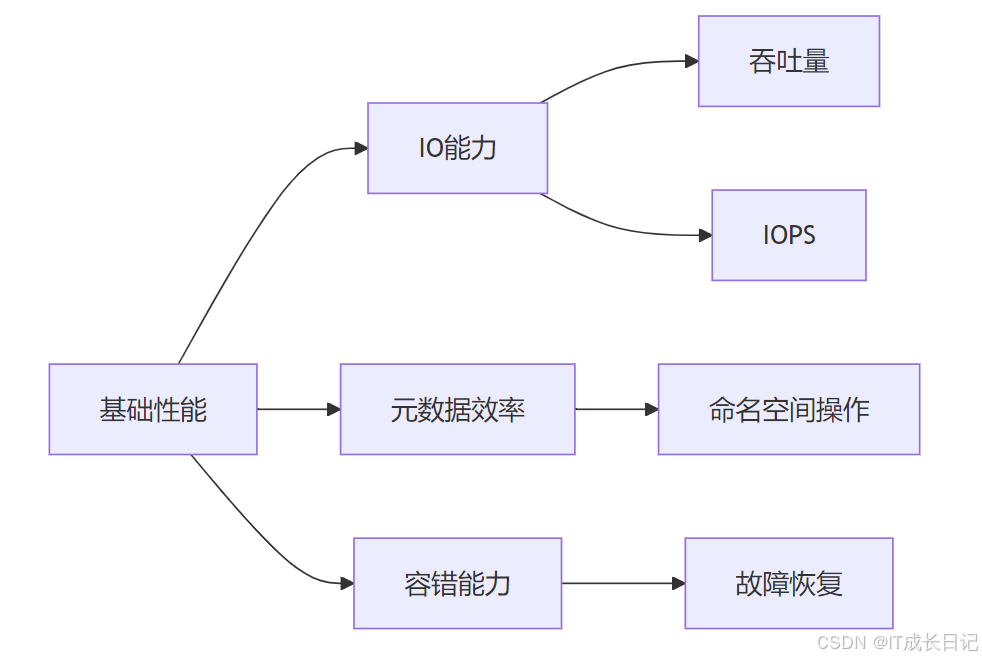
1 HDFS性能评估体系
1.1 性能评估体系架构
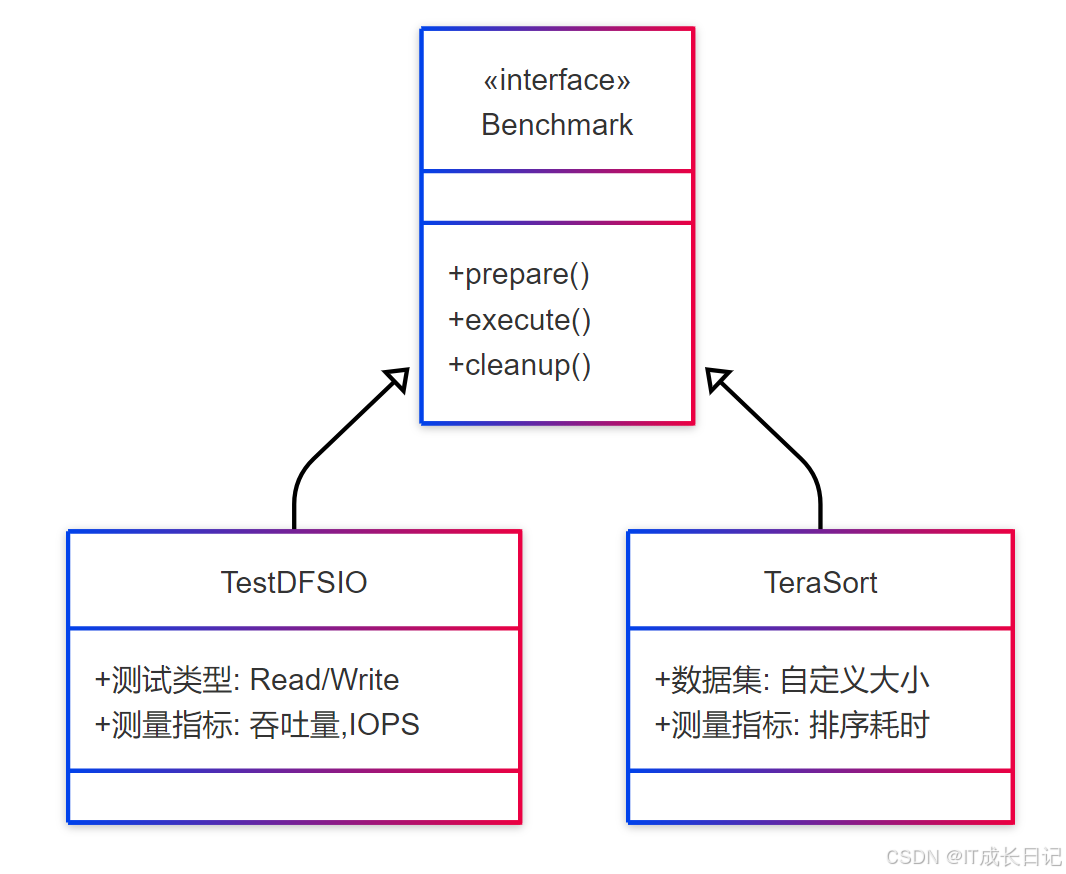
1.2 基准测试工具对比
2 TestDFSIO基准测试实战
2.1 TestDFSIO工作原理
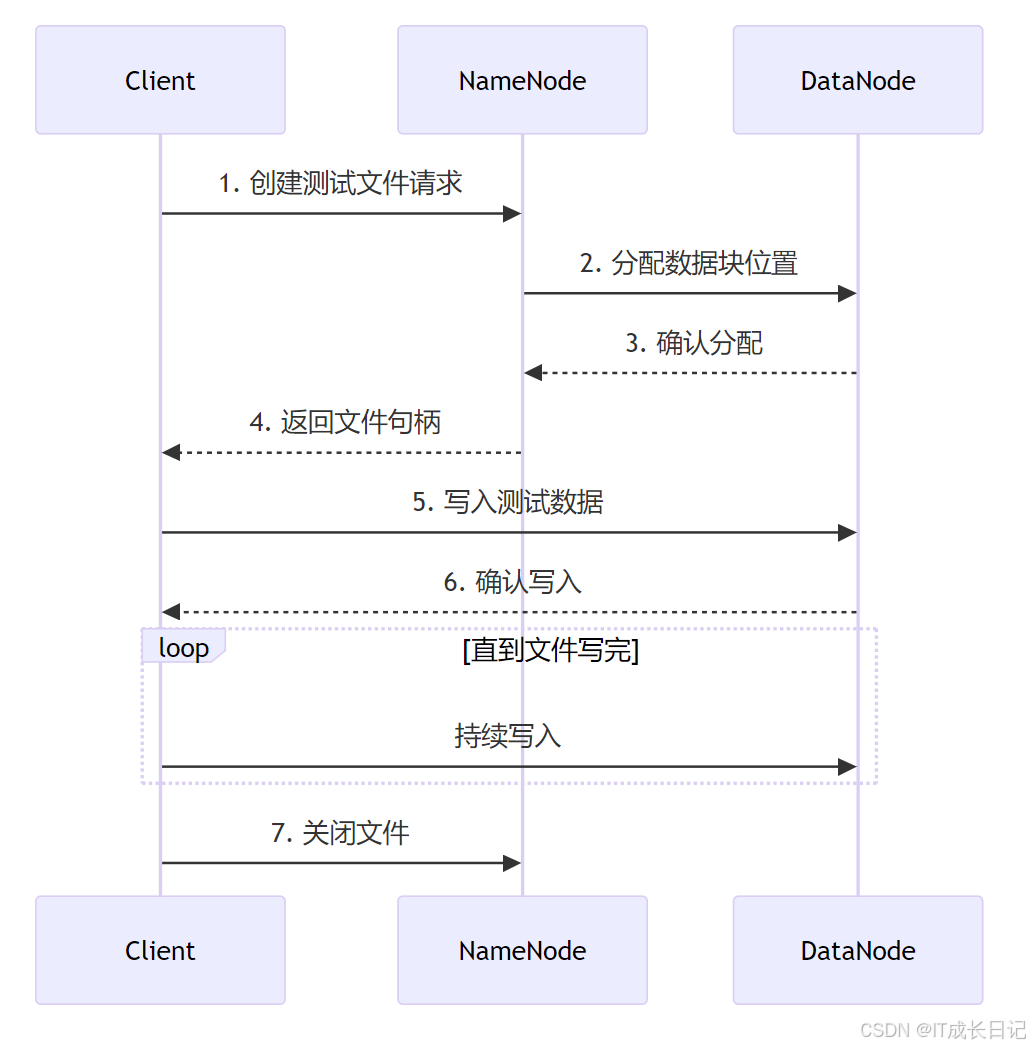
2.2 测试执行步骤
# 写入测试(10个文件,每个1GB)
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-*-tests.jar \
TestDFSIO -write -nrFiles 10 -size 1GB# 读取测试
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-*-tests.jar \
TestDFSIO -read -nrFiles 10 -size 1GB# 清理测试文件
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-*-tests.jar \
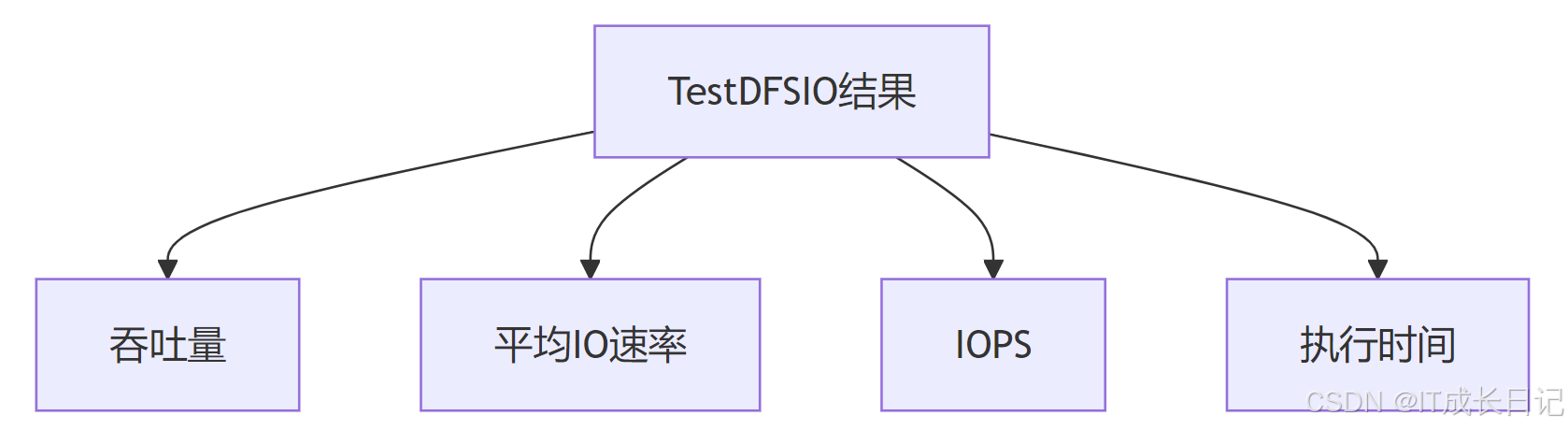
TestDFSIO -clean2.3 结果分析指标
3 TeraSort基准测试实战
3.1 TeraSort测试流程

3.2 测试执行命令
# 生成100GB测试数据
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar \
teragen 1000000000 /teragen# 执行排序
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar \
terasort /teragen /terasort# 验证结果
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar \
teravalidate /terasort /teravalidate3.3 关键性能指标
排序时间 (Sort Time)
- 总排序时间:从作业启动到完成的总耗时
- Map阶段时间:数据读取、分区和本地排序的时间
- Shuffle阶段时间:数据在节点间传输的时间
- Reduce阶段时间:最终合并和排序的时间
吞吐量 (Throughput)
- 数据排序速率:数据集大小(GB或TB)除以总排序时间(秒)
- 通常表示为GB/秒或TB/小时
资源利用率
- CPU利用率:集群CPU使用率
- 内存使用:各节点内存使用情况
- 磁盘I/O:读写吞吐量和延迟
- 网络带宽:节点间数据传输速率
4 HDFS性能调优策略
4.1 配置优化矩阵
| 参数 | 默认值 | 优化建议 | 影响范围 |
| dfs.block.size | 128MB | 根据文件大小调整(256MB/512MB) | 吞吐量 |
| io.file.buffer.size | 4096 | 增大到65536 | IO效率 |
| dfs.namenode.handler.count | 10 | 根据CPU核心数调整 | 并发能力 |
| dfs.datanode.max.xcievers | 256 | 增大到4096 | 连接数 |
4.2 数据分布优化

- 执行数据平衡
hdfs balancer -threshold 104.3 硬件配置建议
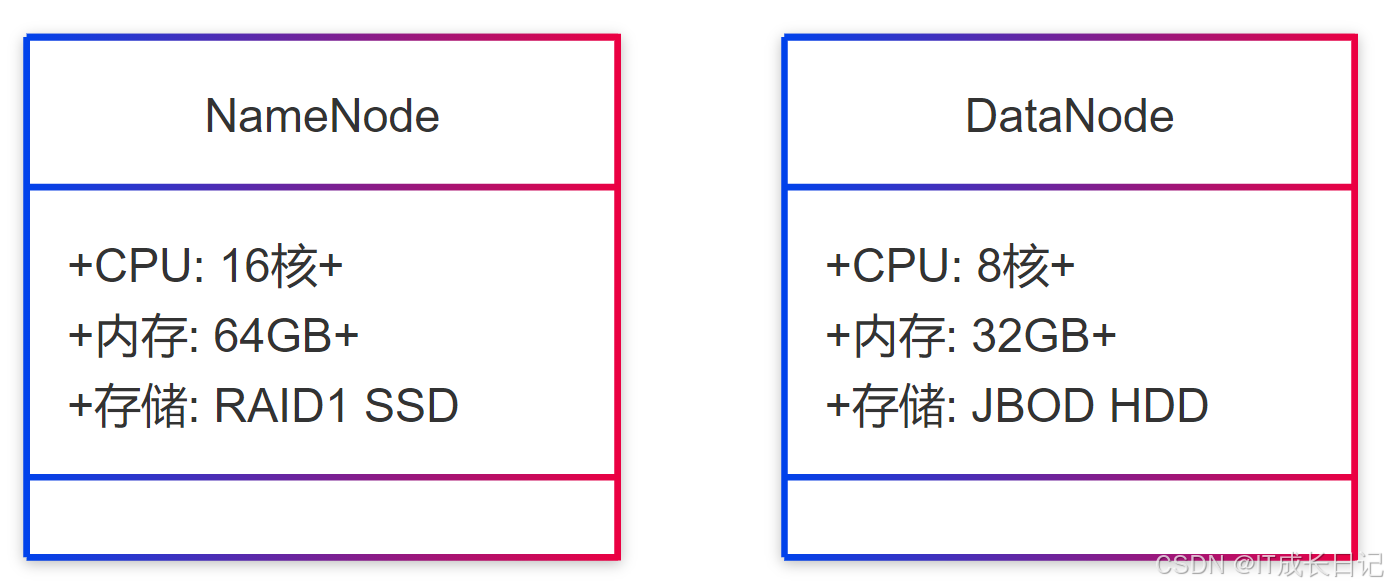
5 性能监控与分析
5.1 监控指标体系
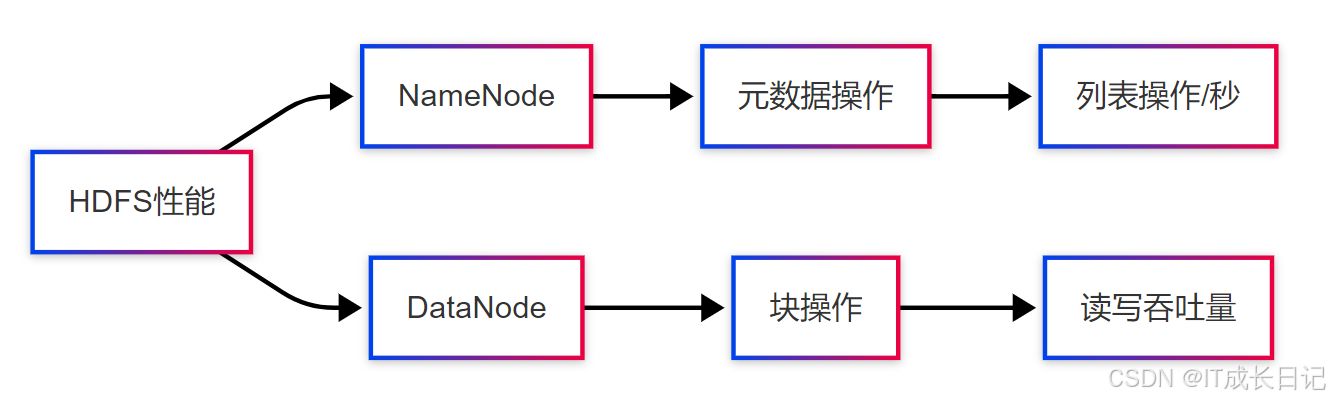
5.2 关键监控命令
# NameNode状态
hdfs dfsadmin -report# 磁盘使用情况
hdfs dfs -df# 文件系统检查
hdfs fsck / -files -blocks6 总结与最佳实践
- 定期基准测试:建立性能基线
- 渐进式优化:每次只调整1-2个参数
- 监控验证:每次变更后重新测试
- 文档记录:保留完整的调优记录
通过本文介绍的方法论和工具,了解了系统性地评估和提升HDFS集群性能。性能调优是一个持续的过程,需要根据业务需求和数据特征不断调整优化策略。