关于大型语言模型的“生物学”
我知道我们已经聊过很多次,关于LLM是怎么运作的,它们的影响力,还有它们的使用场景。但尽管现在有那么多讲LLM的文章,它们本质上还是个黑箱。
但我们真正要问自己的问题是,为什么理解这些系统的内部结构很重要?我们需要这种理解,是为了不被这些系统的能力搞混淆。LLM很容易让我们以为它们是靠推理在解决问题,而不是靠记忆。
而今天这篇博客,我们就要更深入地看看内部结构,探一探LLM的“生物学”,搞明白它到底是怎么动起来的。
目录
• 人工智能可解释性的背景
• 什么是单义性(Monosemanticity)?
• 稀疏自编码器(SAE)
• 多步骤推理
• 诗歌中的规划
• LLM中的加法
• 链式思维不忠实性与语言模型中的隐藏目标
• 最后一点说明
人工智能可解释性的背景
深度学习模型可以学到人类可以理解的算法。这些模型是可以被理解的,但默认情况下,它们没有动力让自己对我们“可读”。
在深度学习里的“机械可解释性”(Mechanistic Interpretability),是要深入模型的内部运作机制,理解每个组件是怎么对整体行为产生影响的。技术点说,就是我们想搞明白模型里每一个神经元、每一层、每一条路径的功能,它们是怎么处理输入,怎么影响最终输出的。
但我们是怎么敢说深度学习模型是可以被分解和解释的?这种直觉是来自这样一个想法:说到底,DL模型就是一堆在做线性代数的神经元,所以理论上,我们应该是可以把它拆成一种人类可以理解的方式的。
“机械可解释性”其实就是想反向工程神经网络,就像你要反编译一个二进制的计算机程序一样。毕竟神经网络的参数,从某种意义上来说,也就是一个跑在某种神秘虚拟机上的二进制程序,这个虚拟机我们就叫它神经网络架构。
什么是单义性?
在机械可解释性里,“单义性”就是说模型里每一个组件或机制,都应该有一个清晰明确、毫不含糊的功能或含义。
单义性的目标,是想做出一本“词典”,可以查到每组特征到底代表什么概念。这个过程被称为“字典学习(dictionary learning)”,而在这个案例中,他们用的是稀疏自编码器来构造这本“词典”。
唉,要是生活能这么简单就好了,但它不是。
因为在深度学习结构中,很多概念是叠加在一起的(superposition),这也正是为什么解释性这么难搞。所以在我们深入讲Anthropic是怎么用自编码器实现单义性之前,先来详细搞明白这个问题。
深度学习模型中的叠加(Superposition)
如果人工神经网络中的每个神经元,都刚好对应输入中的某个可解释特征,那可太省事了。比如,在一个“理想”的ImageNet图像分类器中,每个神经元只在某个特定的视觉特征出现时才激活,比如红色、一个朝左的弯曲、或是一只狗鼻子。
在我们研究过的一些模型中,确实有些神经元确实能清晰地映射到特定特征。但并不是每次都这么干净,特别是在大型语言模型中,神经元和清晰特征的对应关系非常罕见。这就引发了很多问题:为什么有些模型或任务里有很多这样的清晰神经元,而另一些却几乎没有?
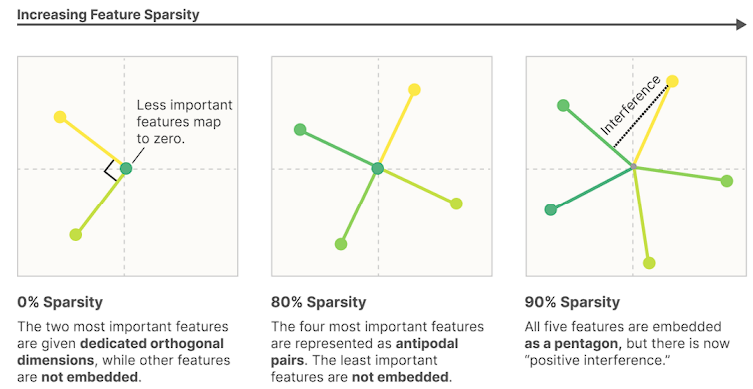
研究人员发现,模型其实是可以容忍干扰的,从而把更多的特征“叠加”存进去。而且他们还展示了,至少在某些有限的情况下,模型是可以在这种“叠加”状态下做计算的。(比如,他们展示了模型可以在叠加中跑一个简单的绝对值函数电路。)
这让他们提出一个假设:我们现实中看到的神经网络,在某种意义上,其实是“带噪声地”在模拟一个更大、稀疏得多的神经网络。换句话说,我们可以把现在训练的模型,看作是在执行一个“更大的虚拟模型”的行为,只不过它们把所有特征塞在了一起。
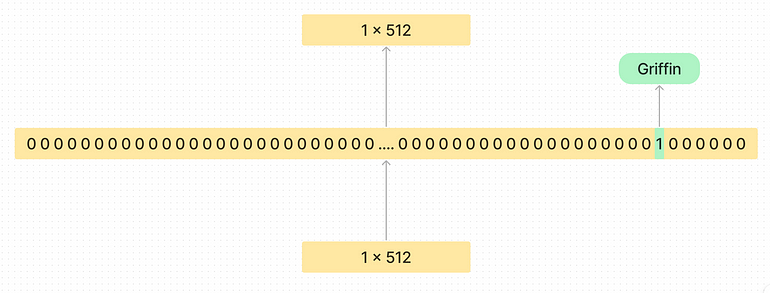
使用稀疏自编码器
自编码器的基本做法是:拿一个输入,把它映射成一个新的值集合,然后再从这个新的集合中重建原来的输入。通常,自编码器用来把信息从高维压缩成低维,比如从1024维压成32维,然后再还原回1024。
但为了提取单义性的特征,他们反其道而行之:不是压缩,而是把信息编码到一个更高维的空间里。
这就叫“稀疏自编码器”。因为每个神经元里可能代表了多个概念,所以我们要把它分解成比神经元数量还多的特征。
稀疏自编码器
稀疏自编码器(SAE)
SAE是由两层组成的。第一层是“编码器”,它通过一个可学习的线性变换,加上ReLU非线性函数,把激活值映射到一个更高维度的空间。这些高维空间的单元我们称为“特征”。
第二层是“解码器”,它尝试通过这些特征的激活值线性组合,重建模型原来的激活值。训练的目标是最小化两个东西:(1)重建误差,(2)特征激活值的L1正则项,也就是促使稀疏性。
SAE训练好之后,它可以帮我们把模型激活值近似分解成“特征方向”的线性组合(也就是SAE解码器的权重),其系数就是特征的激活值。
稀疏性这东西能确保,在模型输入某个值时,只有极少数特征会被激活。因此,模型在任意上下文中处理某个token时,它的激活值可以由一小撮特征来解释(尽管整个特征池子很大)。
他们把SAE应用在模型中途的残差流(residual stream)上。

因为残差流比MLP层小很多,这让训练SAE的成本更低。而且它正好处在模型中间的信息流通节点,有一定程度的抽象能力。
局部替代模型(Local Replacement Model)
这个模型是针对特定提示(prompt)构建的。它在原始模型的attention模式保持不变的基础上,加入了一个误差修正项。结果是,它的输出和原模型完全一样,但内部尽可能多地用“特征”来替代原来的计算。
归因图(Attribution Graph)
从输入追踪到输出,沿着激活的特征路径,剪掉那些不影响输出的路径。

通过分析局部替代模型中,特征之间的交互,我们可以追踪模型在产生响应时的中间步骤。更具体地说,我们会生成归因图,也就是一个图形化表示,描绘模型是怎么一步一步推导出最终输出的。在图中,节点代表特征,边代表它们之间的因果关系。
由于归因图往往很复杂,我们会通过剪枝来精简,只保留对输出有显著影响的节点和边。
当我们拿到这个剪枝后的归因图后,常常能看到一些语义相关、在图中起类似作用的特征被聚集在一起。我们会手动把这些特征节点合并成“超级节点”,从而得到一个更简化的模型计算流程图。
多步骤推理(Multi-Step Reasoning)
比如我们有一个提示:
Fact: “the capital of the state containing Dallas is?”
LLM如果要完成这句,它需要两个步骤——第一步,判断Dallas在哪个州(Texas),第二步,Texas的首府是啥(Austin)。但真正的问题是,LLM是不是确实在内部完成了这两步?还是说它用了某种“捷径”?(比如它可能见过类似的句子,直接记住了结果?)
我们可以通过计算这个prompt的归因图来回答这个问题,看看模型到底用了哪些特征,它们之间怎么互动。首先,我们看特征的可视化图,然后把它们归类成“超级节点”。
语言模型是通过不同的、关联的特征来识别首府的,来看几个例子:
- 词汇特征:找到精确的词,比如我们这里的“capital”。
- 概念特征:识别“capital”在各种上下文中的含义,因为“capital”这个词可以用在好几种情况里:
- 跟州首府有关的问题;
- 多语言场景下的“capital”(比如土耳其语“başkenti”,印地语“राजधानी”等)。
- 输出特征:驱动模型输出特定的首府名字:
- 有些特征就是为了输出“Austin”而激活;
- 有些用于输出各种美国州的首府;
- 还有些用于输出国家首都。
- 上下文特征:识别类似“Texas”这种地点,但不是具体到城市。
系统把这些相关的特征合并成“超级节点”,这些节点可以代表诸如“说出一个首府”或“Texas”这类概念,即便单个特征只是这些概念的某一部分。
创建完超级节点后,我们可以在归因图界面看到,比如“capital”这个超级节点会促使“say a capital”节点激活,后者又促使“say Austin”节点激活。我们用棕色箭头在图中把每个超级节点依次连起来,大概像下面这个图片段那样: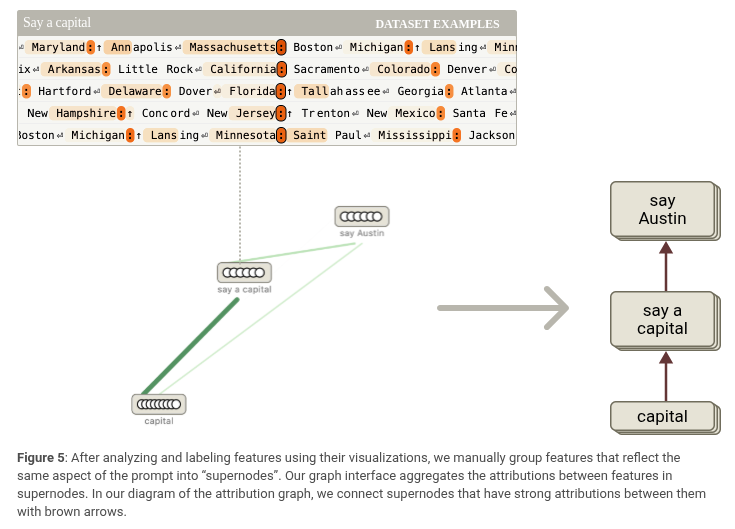
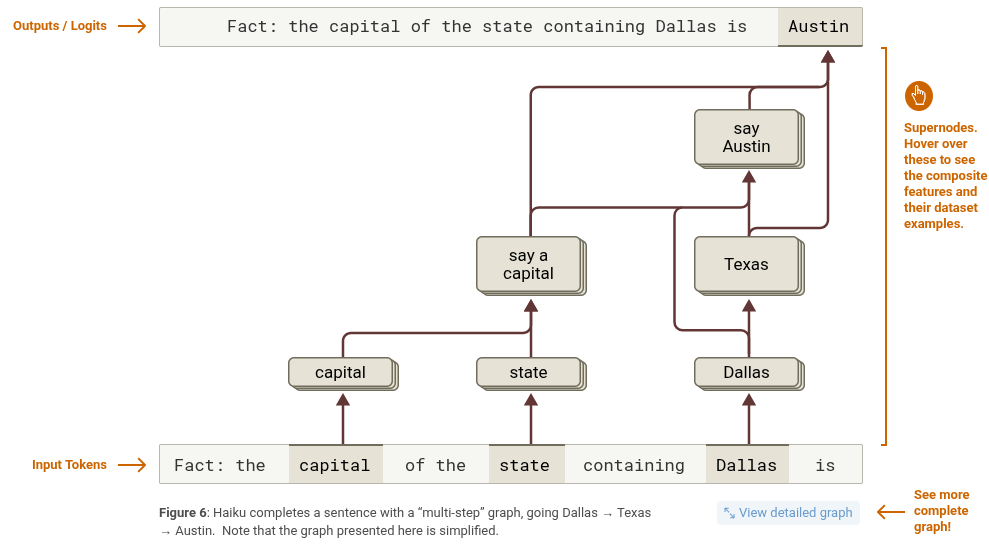
归因图里包含了很多有意思的路径,下面是总结:
• “Dallas”特征(再加上一些州的特征)会激活代表德克萨斯州的那一组特征。
• 与此同时,我们也看到,“capital”这个词激活的特征,会激活另一组输出特征,让模型说出一个首府的名字。
• “Texas”特征和“say a capital”特征合在一起,会提高模型说出“Austin”的概率。这是通过两条路径完成的:
— 直接影响“Austin”输出,
— 间接地,通过激活“say Austin”那一组输出特征。
• 还有一条“捷径”边,是从“Dallas”直接通向“say Austin”的。你看,这种东西就明显是靠记忆来的。这条捷径就是记忆的直接结果。
上面这个图清楚地说明,替代模型确实做了“多跳推理” —— 它决定说“Austin”是经过了一连串中间计算步骤的(Dallas → Texas,然后 Texas + capital → Austin)。
这个图其实把真实的机制简化了不少,我也建议大家亲自去看看更完整的可视化图,才能真正感受到它背后有多复杂。
诗歌中的规划(Planning In Poem)
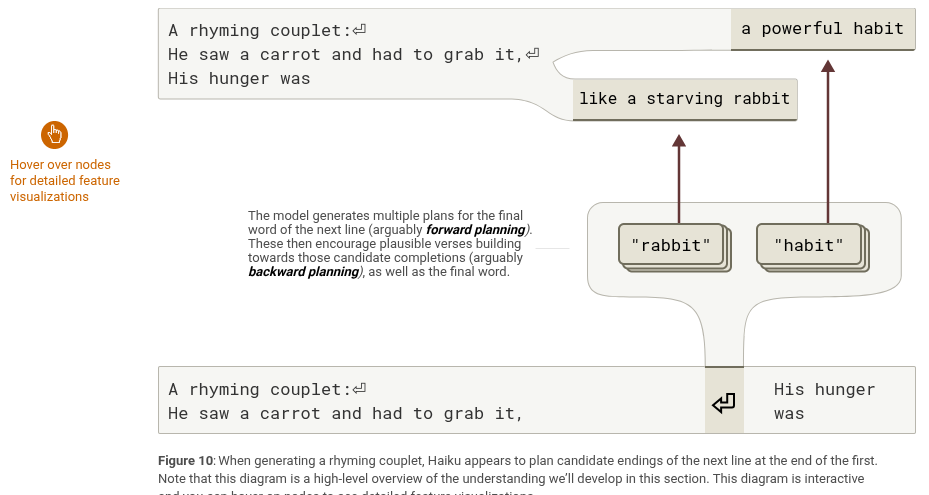
我们都知道LLM能写出很押韵的诗,但它到底是怎么做到的?就算是最厉害的人类写手都挺难的。所以我们来深入看看这个事儿。
当LLM写押韵诗的时候,它不是一句一句即兴来写的。它其实用了一种“规划机制”:
- 提前规划:写完第一行,比如结尾是“grab it”,LLM立马就会激活表示可能押韵词的特征(像“rabbit”或者“habit”)。这个对LLM来说很容易,因为它基本上知道整个字典。
- 反向构思:一旦它想好了结尾可能是哪些词,它就开始构造上一整行内容,让这一行自然地通向那个结尾。反向构思肯定是需要规划的,但这更像是图案匹配出来的,而不是像上面回答德州首府那种做概念构建。
- 多个选项同时考虑:LLM会同时考虑好几个押韵结尾词,然后选一个最合适的。
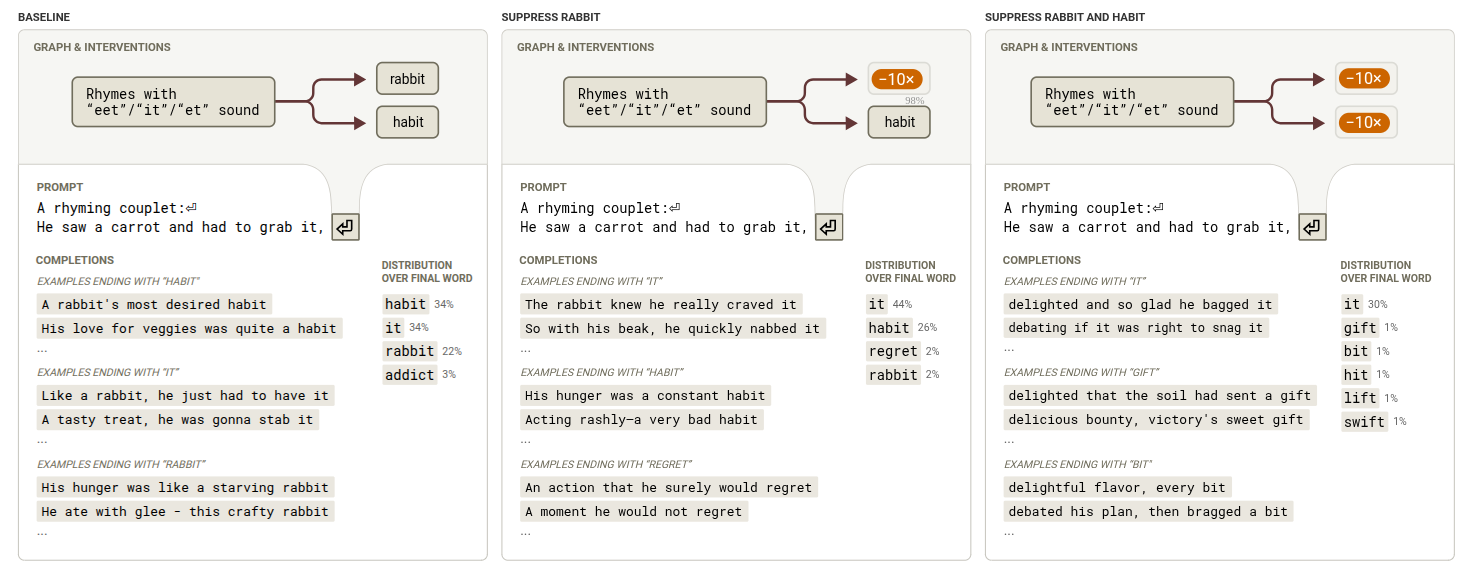
于是我们开始测试它的极限,试着“封锁”某些词:
• 当我们封掉了和“rabbit”相关的特征后,LLM就换成以“habit”结尾。
• 当所有押韵的词都被封掉,LLM就很难把诗写下去。这说明LLM并不是先构建一个大概念来讲故事,然后再把词写出来,它其实更像是在找看起来差不多的句子来押韵。
• 当我们注入像“green”这样的新词特征,LLM会把整句话重写来以那个词结尾。
没写过诗的人一开始看到AI写诗会觉得特别厉害。LLM确实是匹配风格的高手,但诗是既要风格也要故事。所以,AI写出来的诗经常缺乏连贯性。

LLM是如何押韵的拆解分析
LLM是怎么押韵的
尽管LLM有不少限制,但它能写诗这件事还真挺厉害的,因为它表明LLM不是只在按顺序预测下一个词,它还能提前规划,甚至从目标倒推回来 —— 这比简单即兴写作要复杂得多。
LLM里的加法(Addition In LLMs)
对了,你知道吗,LLM在做简单数学的时候,其实用的是完全不同的一套概念?我们一起来看看这些神奇的机器内部到底发生了什么。
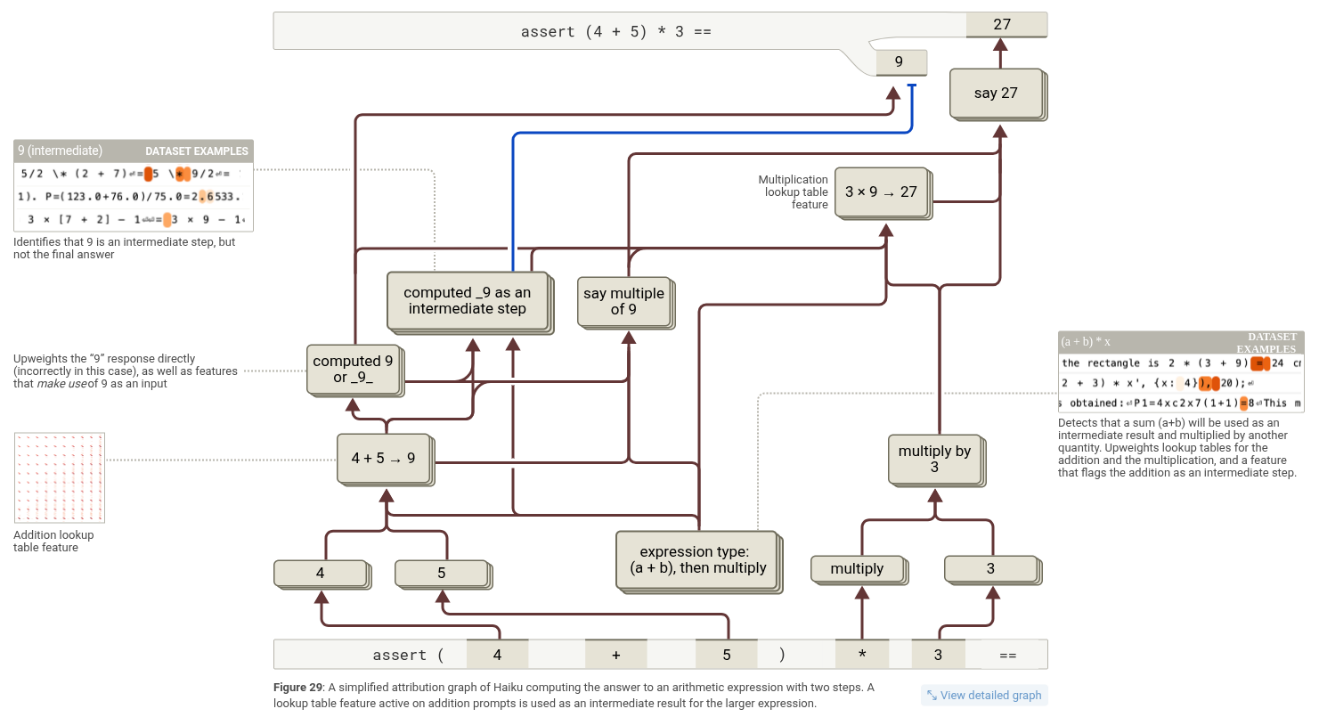
我们从一个简单例子出发来看,当LLM在解像36+59=95这种数学题时,它其实用了并行路径:
- 近似路径:它会大概估算,比如 ~36 + ~60 ≈ 92。为啥它会用这种方式,我们也说不准。但我猜,在它训练压缩互联网上的内容时,它发现这样是个最优解。
- 精确路径:它会用一些“查表”特征,知道像 6+9=15,所以个位是5。但注意啊,它不是一下子看整个数字,而是只盯着某些特定位数。而且我们没法控制它到底在看哪些位数。
- 组合:最后,它把这两条路径的信息合并在一起,得出最终答案 95。
这个方式和人类做数学题完全不一样 —— LLM是记住了某些数字组合,但处理方式跟人类标准算法完全不同。
特征类型
LLM内部的特征,在可视化后能看到一些明显的模式:
• 对角线图案:表示能检测加法和乘法结果的特征。
• 水平/垂直图案:对输入数字特别敏感的特征,它们跟提示词里的具体数字有关。
• 点状图案:像“查表”功能,识别具体的数字组合。这些查表是它自己训练过程中生成的,不是人造的,所以结果不是很一致。
• 重复图案:追踪模运算信息(比如个位数)的特征。
泛化到其他场景
这些加法特征,在一些出人意料的地方也起作用:
• 学术引用里算出版年份(所以LLM引用经常错)。
• 天文数据里预测时间(别信LLM给你算星星,差一个点就全错了)。
• 财务报表中计算序列值(同上,信不过)。
• 把加法当作复杂表达式中的中间步骤来用。
当加法是某个多步骤问题的一部分时(比如(4+5)×3),LLM会把“9”当成一个中间结果,而不是最终答案。
有趣的是,LLM虽然能在一组特定数字上算得很准,但你要问它怎么算的,它给你的还是标准人类算法说明 —— 因为它自己也不知道它是怎么得出这个答案的。所以啊,它一说“让我再想想”,你下次别被它骗了。
LLM的计算本质上靠的是记忆,它甚至可能会在简单数学题上出错,而你自己还不知道。尤其一碰到大数,错得就更容易了。
LLM在长乘法里崩了
链式思维不忠实与隐藏目标(Chain-of-Thought Unfaithfulness and Hidden Goals In Language Models)
链式思维(CoT)是LLM社交时最装的那一招。
现在已经有很多研究表明,这种链式思维其实和模型真实的内部处理逻辑并不一致。研究者用归因图分析模型行为后,发现了三种不同的推理模式:
观察到的推理类型
- 忠实推理:比如算 sqrt(0.64),模型确实是算了平方根,然后乘以5。有时候模型确实能学会真正的通用性。有人把一堆无关权重都归零了,它还能正常跑。
- 胡扯型:比如让它算 cos(23423),它可能会说“我用计算器算的”(其实根本没有)。这类情况,它是装的,它根本没算。
- 目标驱动型:比如你暗示它答案是4,它就反向推,想出一套中间值来“凑”这个结果,而不是老老实实计算。就像你在引导它到正确答案,但前提是你自己先知道答案。
LLM背后的隐藏机制
我们来问自己:“AI在回答我们的时候,背后到底发生了啥?”
这些模型不是只用一种办法来解决问题 —— 它们是同时激活多个路径的。比如你问 Michael Jordan 是搞什么运动的,模型可能同时激活了和篮球相关的神经元,还有跟“运动类别”相关的一般路径。这些并行过程有时候是合作,有时候互相打架。而我们研究者完全控制不了它到底哪条路径在生效。
这是因为模型在训练时压缩了互联网,自动提炼出一种“泛化方式”。这泛化到底准不准,我们控制不了,只能希望喂得数据越多,泛化就越准。
这不是理论 —— 你可以直接看到模型是怎么解36+59这种简单题的。它会用不同神经路径分别处理个位数和整体估值。
抽象能力(Abstraction Abilities)
这些模型真的学会了可以跨场景通用的抽象概念。比如:
• 加法特征也能用于算学术出版年;
• 用于预测天文时间段;
• 用于算财务表格里的序列值。
这说明,模型内部也许在发展一种“通用的心理语言”。越先进的系统,这种语言越成熟。但问题是,有时我们希望模型自由发挥,有时又想严格控制。这点我们现在做不到,将来也不一定能。
“幻觉”对LLM来说不是bug,而正是它擅长的原因 —— 幻觉是LLM的本质属性。
规划,而不是即兴
AI并不是只在预测下一个词。比如写需要押“grab it”的诗时,它不是一句一句瞎写的 —— 它会提前激活像“rabbit”“habit”这些结尾的特征,甚至还没开始写这行。
研究者可以操控这些“规划特征”,逼模型把整行重写成押这些词的结尾。这不是简单的词预测 —— 是一种复杂的规划。或者更准确说,是“大概记起来”然后顺着往下写。
它们还能做“倒推链式”,也就是从最终目标反推中间步骤。它有时候会先决定答案,再倒推一套看起来逻辑通的过程,而不是一步一步真算。
所以你看到模型写的“推理过程”时,别太当真。有论文指出,这些推理过程可能完全是编的,结果却是对的。大多数研究只是因为结果对了就以为过程也对,其实不一定。
LLM是在构建自我意识吗?
有些神经特征会代表“我知道答案” vs “我不知道”的概念。这些特征会跟模型认识的某些实体有关。当研究者操控这些特征时,可以让模型对它根本不知道的事变得很自信,这说明它的“元认知”其实还挺原始的。
为什么这不只是学术问题?
这些发现不仅仅是好玩的,它们有很严重的影响。研究者其实早就知道LLM内部有这些问题。但现在是一个主流AI实验室把它写出来了,这就有意义了,特别是现在AI在现实社会里影响这么大。
随着这些模型越来越融入社会,我们必须理解它们的内部机制来确保安全。现有方法可能能抓到一些问题,但也有很多会漏掉。不过这些探索给未来做更好的审计工具打了基础。
这种从底层往上挖的方式,揭示了很多之前靠猜测根本想不到的细节,比如:
• 模型生成文字时,是怎么在多种可能词中切换的;
• 哪些路径会抑制有害输出(要是我们能锁定这些路径,就能直接关掉某些神经元,让模型更安全);
• 哪些特征在多个上下文之间泛化得很广。
随着语言模型越来越大,我们越难理解它们的工作机制。探索工具 + 精准测试,会是理解这些系统的关键。
理解AI,不只是一个技术活 —— 这是一场高风险的探索。
这些发现告诉我们,虽然这些系统很复杂,但我们还是能开发工具看清它们的内部结构。它们归根结底,仍然是人类推理和聪明才智的产物。