对美团leaf的初步学习
我的项目中使用的雪花算法生成的全局订单号。但是考虑到了雪花算法可能会由于时钟回拨导致生成的全局id重复。于是去研究了美团的leaf服务:Leaf——美团点评分布式ID生成系统 - 美团技术团队,并总结出该文章。
自己项目中的应用
由于对订单表做了分表,所以应用了基因法的思想将分表结果编码到了订单号中
public class DistributeID {/*** 系统标识码*/private String businessCode;/*** 表下标*/private String table;/*** 序列号*/private String seq;/*** 分表策略*/private static DefaultShardingTableStrategy shardingTableStrategy = new DefaultShardingTableStrategy();public DistributeID() {}/*** 利用雪花算法生成一个唯一ID*/public static String generateWithSnowflake(BusinessCode businessCode, long workerId,String externalId) {long id = IdUtil.getSnowflake(workerId).nextId();return generate(businessCode, externalId, id);}/*** 生成一个唯一ID:10(业务码) 1769649671860822016(sequence) 1023(分表)*/public static String generate(BusinessCode businessCode,String externalId, Long sequenceNumber) {DistributeID distributeId = create(businessCode, externalId, sequenceNumber);return distributeId.businessCode + distributeId.seq + distributeId.table;}@Overridepublic String toString() {return this.businessCode + this.seq + this.table;}public static DistributeID create(BusinessCode businessCode,String externalId, Long sequenceNumber) {DistributeID distributeId = new DistributeID();distributeId.businessCode = businessCode.getCodeString();String table = String.valueOf(shardingTableStrategy.getTable(externalId, businessCode.tableCount()));distributeId.table = StringUtils.leftPad(table, 4, "0");distributeId.seq = String.valueOf(sequenceNumber);return distributeId;}public static String getShardingTable(DistributeID distributeId){return distributeId.table;}public static String getShardingTable(String externalId, int tableCount) {return StringUtils.leftPad(String.valueOf(shardingTableStrategy.getTable(externalId, tableCount)), 4, "0");}public static String getShardingTable(String id){return getShardingTable(valueOf(id));}public static DistributeID valueOf(String id) {DistributeID distributeId = new DistributeID();distributeId.businessCode = id.substring(0, 2);distributeId.seq = id.substring(2, id.length() - 4);distributeId.table = id.substring(id.length() - 4, id.length());return distributeId;}
}
使用:
String orderId = DistributeID.generateWithSnowflake(业务码, 机器的woerId, userId);
最终生成的订单号形如:10(业务码) 1769649671860822016(sequence) 1023(分表)
其中,sequence就是通过雪花算法生成的。
雪花算法:
-
符号位(1bit):预留的符号位,始终为0,占用1位
-
时间戳(41bit):精确到毫秒级别,41位的时间戳可以容纳的毫秒数是2的41次幂,一年所使用的毫秒数是:365*24*60*60*1000,算下来可以使用69年。
-
数据中心标识(5bit):可以用来区分不同的数据中心。
-
机器标识(5bit):可以用来区分不同的机器。
-
序列号(12bit):可以生成4096个不同的序列号。

当发生时钟回拨,时间跳到过去某个时间上,时间戳就和过去某个时间戳重复了,因为又是在一台机器上,所以数据中心和机器标识也一样,这时保证唯一只有靠序列号了。但当瞬时数据量非常大,就很容易导致雪花算法生成的id重复。
使用mysql生成全局唯一id
有这样一张表:
CREATE TABLE Tickets64 (id BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,stub CHAR(1) NOT NULL UNIQUE
);
执行sql:
begin;
REPLACE INTO Tickets64 (stub) VALUES ('a');
SELECT LAST_INSERT_ID();
commit;
sql解释:REPLACE INTO是 MySQL 的一种特殊语法,用于插入或替换记录。如果表中已经存在与新记录冲突的主键或唯一索引,则会先删除旧记录,然后插入新记录。如果不存在冲突,则直接插入新记录。
select LAST_INSERT_ID()是会话级别的,得到该次会话上次插入的id。在前面的REPLACE INTO操作中:如果是插入新记录,则返回新记录的自增主键值。如果是替换旧记录,则返回新插入记录的自增主键值(因为旧记录被删除,新记录重新生成了主键)。
然后再设置auto_increment_increment=1和auto_increment_offset=1表示主键从1开始自增,每次增加1。
以后每个应用来获取分布式id时,就可以执行这段sql,依靠mysql自身的行级锁机制,保证了获取的分布式id都是单调递增的。
缺点:1.强依赖DB,当DB异常时整个系统不可用,属于致命问题。配置主从复制可以尽可能的增加可用性,但是数据一致性在特殊情况下难以保证。主从切换时的不一致可能会导致重复发号;2.ID发号性能瓶颈限制在单台MySQL的读写性能。
对于单台mysql的读写瓶颈问题,可以多部署几台mysql。比如:部署两台mysql,server1的初始值为1,步长为2,server2的初始值为2,步长也为2。这样server1发号:1,3,5,7,9…,server2发号:2,4,6,8,10。这样貌似解决了单台mysql的性能问题。但会带来一个新的问题:我想增加mysql实例数,怎么水平扩展?
比如定义好了步长和机器台数之后,如果要添加机器该怎么做?假设现在只有一台mysql,发号是1,2,3,4,5(步长是1),这个时候需要扩容机器一台。可以这样做:把第二台机器的初始值设置得比第一台超过很多,比如14(假设在扩容时间之内第一台不可能发到14),同时设置步长为2,那么这台机器下发的号码都是14以后的偶数。让ID值生成到奇数,比如7,然后摘掉第一台,修改第一台的步长为2。让它符合我们定义的号段标准,对于这个例子来说就是让第一台以后只能产生奇数。扩容方案看起来复杂吗?貌似还好,现在想象一下如果我们线上有100台机器,这个时候要扩容该怎么做?简直是噩梦。所以系统水平扩展方案复杂难以实现。
其次这种方案,每次获取分布式id都要到mysql中读写,数据库的压力还是很大的,只能靠堆机器来提升吞吐量。
引出美团Leaf
美团Leaf
(leaf就是是一个服务,用来生成分布式id的服务。具体到java服务中,可以认为就是springboot服务。)
leaf支持两种模式:号段模式,和雪花算法模式
Leaf-segment数据库方案(号段模式)
数据库表设计如下:

重要字段说明:biz_tag用来区分业务,max_id表示该biz_tag目前所被分配的ID号段的最大值,step表示每次分配的号段长度。原来获取ID每次都需要写数据库,现在只需要把step设置得足够大,比如1000。那么只有当1000个号被消耗完了之后才会去重新读写一次数据库。读写数据库的频率从1减小到了1/step。
前面的mysql方案中存在每次都要到mysql中读写和难以水平扩展问题。Leaf-segment做了这样的改变:改为每次取出一批也就是一个号段(范围大小由step决定)的数据,用完之后再去获取新的号段。并且用于不同业务的分布式id用biz_tag标识。每个biz-tag下的id获取相互隔离,互不影响。但不同业务生成的分布式id可以重复,比如用户id和订单id可以重复。
举例说明:

用于生成用户分布式id的user_tag。用户服务A第一次获取一个号段:[1,1000],更新max_id为1000,然后给自己的服务串行分配。分配完后又来获取一个新的号段,假如这时已经有另一个用户服务B获取了一次号段:[1001,2000],更新max_id为2000,这时用户服务A再获取的号段应该是[20001,3000],更新max_id为3000
Leaf-snowflake方案(雪花算法模式)
Leaf-segment方案可以生成趋势递增的ID,同时ID号是可计算的,不适用于订单ID生成场景,比如竞对在两天中午12点分别下单,通过订单id号相减就能大致计算出公司一天的订单量,这个是不能忍受的。面对这一问题,美团leaf提供了 Leaf-snowflake方案。
Leaf-snowflake方案完全沿用snowflake方案的bit位设计,即是“1+41+10+12”的方式组装ID号。利用zookeeperzk顺序节点生成的int类型ID号作为雪花算法的workerId。
解决时钟回拨问题
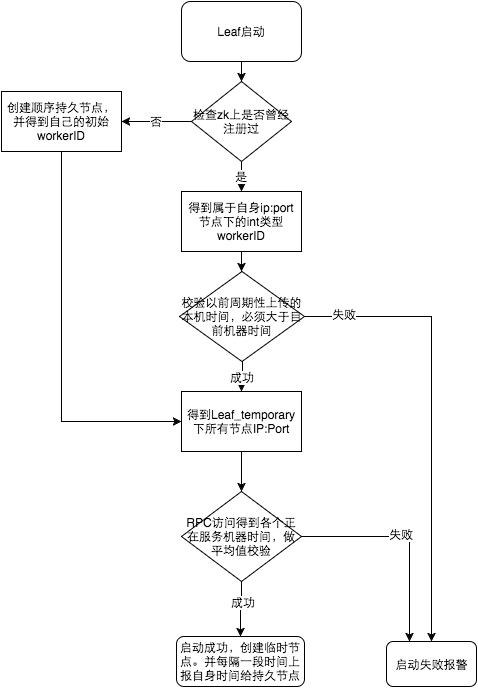
大致思路为:每个Leaf运行时定时向zk上报时间戳。每次Leaf服务启动时,先校验本机时间与上次发id的时间,再校验与zk上所有节点的平均时间戳。如果任何一个阶段有异常,那么就启动失败报警。
其次在每次获取雪花id时也进行了校验
rkerId。
解决时钟回拨问题
[外链图片转存中…(img-l3AhtD8t-1745053605521)]
大致思路为:每个Leaf运行时定时向zk上报时间戳。每次Leaf服务启动时,先校验本机时间与上次发id的时间,再校验与zk上所有节点的平均时间戳。如果任何一个阶段有异常,那么就启动失败报警。
其次在每次获取雪花id时也进行了校验
