Oracle 23ai Vector Search 系列之6 向量相似性搜索(Similarity Search)
文章目录
- Oracle 23ai Vector Search 系列之6 向量相似性搜索(Similarity Search)
- 向量相似性搜索(Similarity Search)概述
- 向量距离度量
- 欧式距离(Euclidean Distances)
- 欧式平方距离(Euclidean Squared Distances)
- 余弦距离(Cosine Similarity)
- 点积距离(Dot Product Similarity)
- 曼哈顿距离(Manhattan Distance)
- 汉明距离(Hamming Distance)
- 杰卡德距离(Jaccard Similarity)
- 常见相似性/距离度量方法对比
- VECTOR_DISTANCE()
- VECTOR_DISTANCE 语法格式
- VECTOR_DISTANCE()测试例
- 欧式距离
- 余弦距离
- 内积(Inner Product) 和 点积(Dot Product) 距离
- 参考
Windows 环境图形化安装 Oracle 23ai
Oracle 23ai Vector Search 系列之1 架构基础
Oracle 23ai Vector Search 系列之2 ONNX(Open Neural Network Exchange)
Oracle 23ai Vector Search 系列之3 集成嵌入生成模型(Embedding Model)到数据库示例,以及常见错误
Oracle 23ai Vector Search 系列之4 VECTOR数据类型和基本操作
Oracle 23ai Vector Search 系列之5 向量索引(Vector Indexes)
Oracle 23ai Vector Search的典型工作流程:
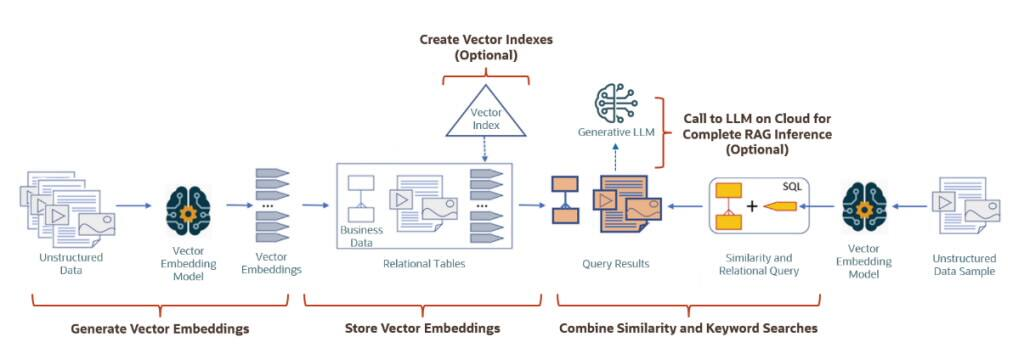
来源:https://blogs.oracle.com/coretec/post/getting-started-with-vectors-in-23ai
Oracle 23ai Vector Search 系列之6 向量相似性搜索(Similarity Search)
向量相似性搜索(Similarity Search)概述
Oracle的向量相似性搜索(Similarity Search)是其AI Vector Search功能的核心组成部分,旨在通过高效处理高维向量数据,支持多种人工智能驱动的应用场景。
向量相似性搜索,说白了就是让电脑像人一样“懂”我们想找啥,而不是死磕关键字。
举个例子:
假设你在网上输入一句中文,传统搜索只会硬找包含相同词语的网页。
但向量搜索会“理解”你的意思——比如你搜“想买辆省油的车”,它能get到你想找省油车,哪怕网页里没写“省油”这俩字,只要内容相关(比如提到“低油耗”“省油技巧”),就会推荐给你。
它是咋做到的?
- “翻译”成数学密码:
把文字、图片甚至声音,都转成一串数字(这叫“向量”)。就像给每个东西贴个数学标签,相似的标签数字会接近。
比如:
句子“我想看科幻片”会被转成类似[0.1, 0.5, 0.9, ...]的向量。
猫的图片会被转成代表毛色、耳朵形状等特征的向量。
- 找“邻居”:
当你输入一个请求(比如一句中文),电脑先把它也转成向量,然后在数据库里找“住得最近”的向量——这些就是和你需求最像的内容。
比如你搜“科幻片”,它会匹配向量最接近的电影,可能包括《星际穿越》《流浪地球》等。
Oracle数据库提供了“向量搜索+结构化查询+安全防护”的一站式服务,在一个库里直接用SQL就能搞定。
具体而言,在传统SQL的框架上,通过相似性计算函数VECTOR_DISTANCE()来实现向量相似性搜索(Similarity Search)。
向量距离度量
欧式距离(Euclidean Distances)
欧式距离就是我们日常生活中最常用的“直线距离”。简单来说,就是两个点在空间中连成一条线段的长度,就像用尺子直接量出来的最短距离。
举个例子:
平面地图:如果你在地图上看到A点(比如你家)和B点(比如学校),它们之间的直线距离就是欧式距离。比如A点坐标(1,2),B点坐标(4,6),用勾股定理算:√[(4-1)² + (6-2)²] = 5,这就是直线距离5公里。
多维数据:比如网购时,系统比较两件商品的“价格”和“评分”。商品A是[100元,4.5分],商品B是[150元,3.8分],欧式距离能算出它们的综合差异(约53.3),帮你推荐更相似的商品。
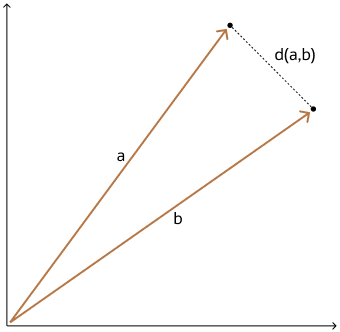
图片来源:Euclidean and Euclidean Squared Distances
欧式平方距离(Euclidean Squared Distances)
欧式平方距离 就是欧式距离的“省流版”——把两点坐标差值的平方直接相加,省去了最后开根号的步骤。它保留了距离的相对大小,但数值不是实际直线距离。
欧式平方距离 就是欧式距离的“省流版”——把两点坐标差值的平方直接相加,省去了最后开根号的步骤。它保留了距离的相对大小,但数值不是实际直线距离。
举个例子:
二维坐标:点A (1, 2) 和点B (4, 6)
欧式距离:√[(4-1)² + (6-2)²] = √(9+16) = 5
平方距离:直接算 (4-1)² + (6-2)² = 9+16 = 25
虽然25不是实际距离,但能看出A和B比A和C(比如平方距离是16)离得更远。
欧式平方距离是“删掉最后一步的欧式距离”,用计算速度换实际距离数值,适合不差相对大小、只求效率的场景。
余弦距离(Cosine Similarity)
余弦距离就是看两个向量的“方向差异”,而不是它们的位置或长度。就像比较两个人的兴趣倾向是否一致,而不是比较他们兴趣的强烈程度。
举个例子:
文本相似度比如两篇文章的词频向量:文章A:[“科技”出现5次,“教育”出现3次] → 向量A = [5, 3]文章B:[“科技”出现10次,“教育”出现6次] → 向量B = [10, 6]虽然B的词频是A的两倍,但方向一致(比例相同),余弦距离为0,说明两篇文章主题高度相似。
用户兴趣匹配用户A喜欢[电影4分,美食1分],用户B喜欢[电影1分,美食4分]。余弦距离会判断两人兴趣方向完全相反(一个爱电影,一个爱美食),距离接近最大值2,匹配度低。
余弦距离是“方向差异探测器”,用来判断两个向量是否指向同一个趋势,适合比心(兴趣、语义)不比钱(绝对值)。
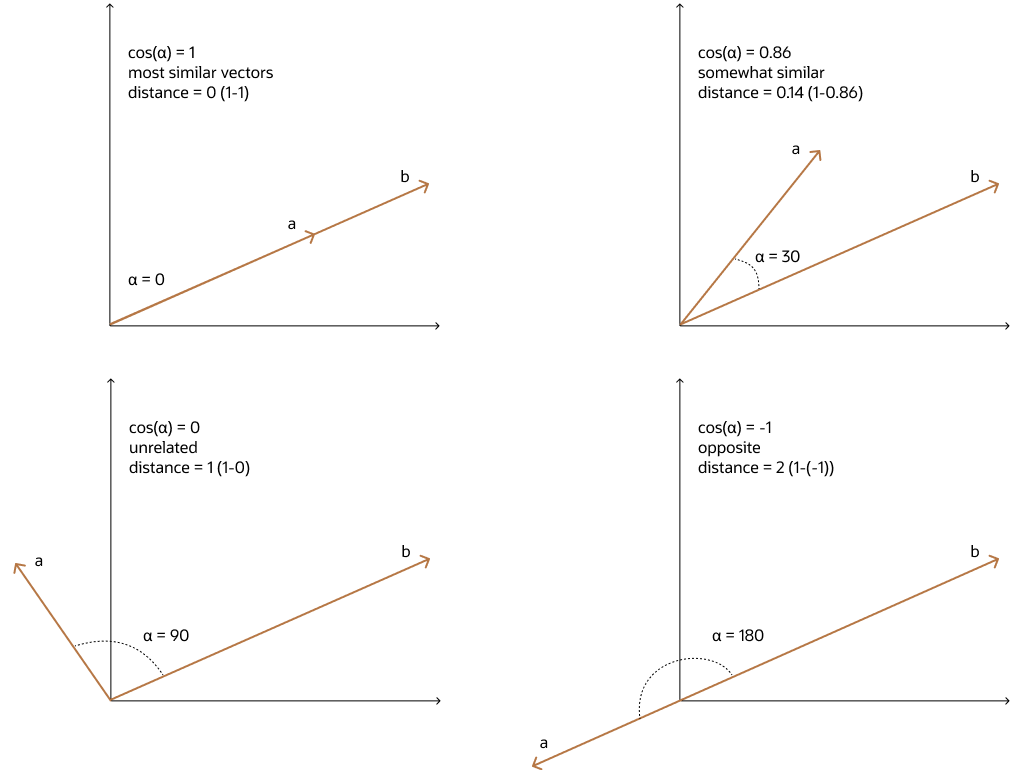
图片来源:Cosine Similarity
点积距离(Dot Product Similarity)
向量点积距离(Dot Product Similarity) 可以理解为“用乘法算默契值”——两个向量对应位置的值相乘再全部相加,结果越大,说明它们越“合拍”。
它既看方向是否一致,又看数值大小是否匹配,比如“用户兴趣”和“商品属性”的契合度。
举个例子:
推荐系统:用户A的喜好向量:[电影5分,游戏3分,美食1分]电影《星际穿越》的特征向量:[科幻9分,特效8分,爱情2分]点积相似度 = (5×9) + (3×8) + (1×2) = 45 + 24 + 2 = 71值越高,说明用户兴趣和电影特征越匹配,系统就会推荐这部电影。对比方向 vs 长度:向量A:[3, 4](长度5)向量B:[6, 8](长度10,方向与A相同)向量C:[4, -3](长度5,方向与A垂直)点积结果:A·B = 3×6 + 4×8 = 18+32 = 50A·C = 3×4 + 4×(-3) = 12-12 = 0虽然A和B方向一致,但B长度更大,点积结果更高;A和C方向垂直,点积为0。
点积相似度是“默契值计算器”——方向一致且数值越大,默契值越高,适合既要看趋势又要看力道的场景。
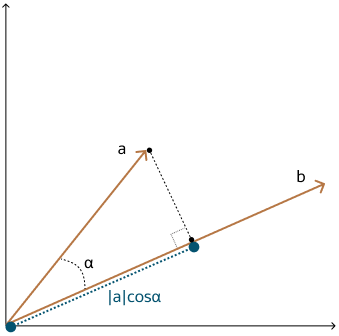
图片来源:Dot Product Similarity
内积(Inner Product) 和 点积(Dot Product) 本质上是同一种计算,只是名称不同。它们都是两个向量对应位置的数值相乘再全部相加的操作。但根据具体场景的应用需求,可能会对结果做不同处理,导致实际使用中的差异。
曼哈顿距离(Manhattan Distance)
曼哈顿距离(也叫“出租车距离”)就是两点在只能横平竖直移动的网格路径中走过的总路程。它像现实中的城市街区,你没法穿楼而过,只能拐直角走路或开车,把每一小段距离加起来。
举个例子:
地图导航:点A(你家)坐标(1,2),点B(超市)坐标(4,6)。你开车需要先横向走 |4-1|=3 公里,再纵向走 |6-2|=4 公里,总距离 3+4=7 公里(而直线欧式距离是5公里)。
棋盘走法:国际象棋的“车”从(1,1)到(4,5),必须走横竖格子,曼哈顿距离是 |4-1| + |5-1| = 7步。
曼哈顿距离是“拐弯抹角的总路程”,适合算格子世界里的实际移动距离,或者数据中更关注各维度独立贡献的场景。
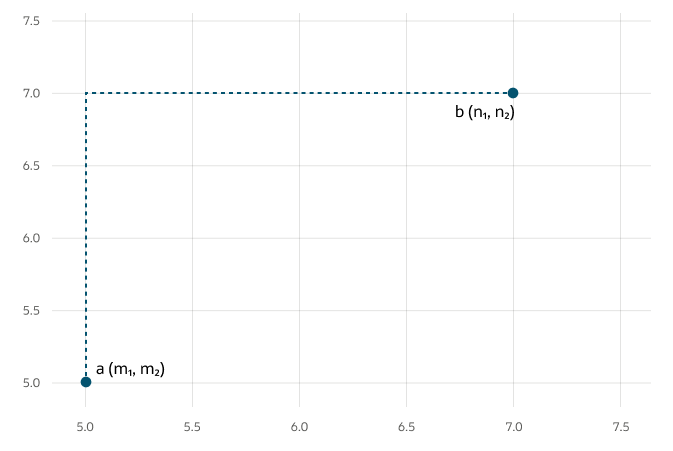
图片来源:Manhattan Distance
汉明距离(Hamming Distance)
汉明距离就是“找不同”的距离——对比两个相同长度的字符串,数一数有多少个位置上的字符不一样。它像玩“大家来找茬”游戏,统计两段信息在细节上的差异点数量。
一般适用于二进制向量场景。
举个例子:
二进制传输纠错:发送方发 101010,接收方收到 100011逐个位置对比:第3位(1 vs 0)、第5位(1 vs 1)、第6位(0 vs 1)汉明距离 = 3,说明传输中出现了3个比特的错误。
密码锁验证:正确密码是 3527,你输入了 3597只有第3位(2 vs 9)不同,汉明距离 = 1,系统会提示“接近正确密码”。
生物DNA比对:基因序列A:A-T-G-C基因序列B:A-C-G-T第2位(T vs C)和第4位(C vs T)不同,汉明距离 = 2,差异越大亲缘关系可能越远。
汉明距离是“数不同之处的直男”——只看位置对不对得上,不管差异多严重,适合对比密码、编码、DNA这类“非黑即白”的数据。
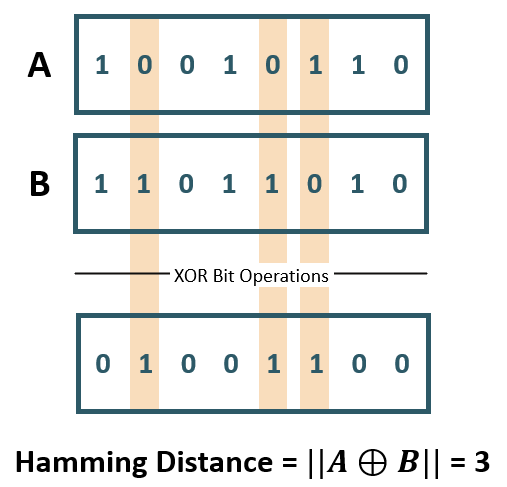
图片来源:Hamming Distance
杰卡德距离(Jaccard Similarity)
杰卡德距离就是“算共同好友比例”——两个集合的交集占并集的比例越高,相似度就越高,距离就越近。它像相亲时看两人有多少共同爱好,重合越多越合适。
杰卡德相似度仅适用于二进制向量,且仅考虑每个向量的非零位。
举个例子:
购物车推荐:用户A买了 {牛奶, 面包, 鸡蛋}用户B买了 {牛奶, 啤酒, 尿布}交集(共同商品):{牛奶} → 1个并集(所有商品):{牛奶, 面包, 鸡蛋, 啤酒, 尿布} → 5个杰卡德相似度 = 1/5 = 0.2,距离 = 1 - 0.2 = 0.8 → 距离远,推荐关联度低。
文章关键词比对:文章X关键词:{经济, 复苏, 政策}文章Y关键词:{经济, 衰退, 市场}交集:{经济} → 1个并集:{经济, 复苏, 政策, 衰退, 市场} → 5个相似度 = 1/5 = 0.2 → 两篇文章主题差异大。
杰卡德距离是“共同好友计算器”——你俩重合的标签越多,距离越近,适合比人脉、比标签这种“有或无”的数据。
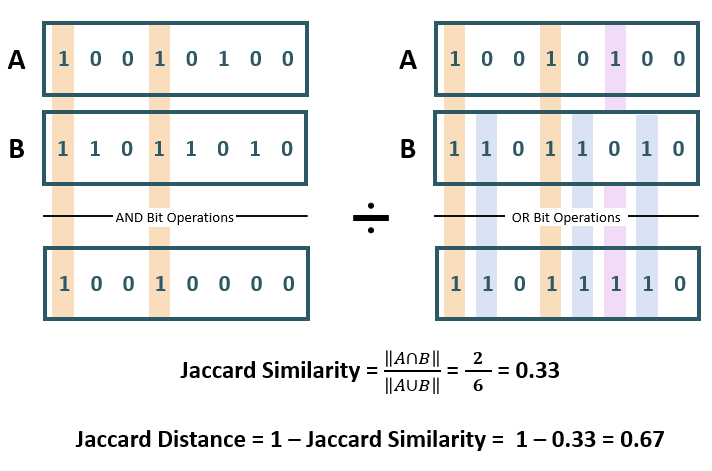
图片来源:Jaccard Similarity
常见相似性/距离度量方法对比
常见相似性/距离度量方法对比总结如下:
| 方法名称 | 核心公式/思想 | 适用场景 | 优点 | 缺点 | 示例 |
|---|---|---|---|---|---|
| 欧式距离 | √(Σ(xᵢ - yᵢ)²) → 直线距离 | 数值型数据(坐标、价格) | 直观,符合物理空间认知 | 对异常值和量纲敏感 | 两地直线距离5公里 |
| 欧式平方距离 | Σ(xᵢ - yᵢ)² → 省去开根号 | 快速比较远近(K-Means) | 计算高效,排序不变 | 数值无实际距离意义 | 聚类平方值25 |
| 曼哈顿距离 | Σ|xᵢ - yᵢ| → 拐直角路程 | 网格数据、物流路径 | 对异常值鲁棒 | 高维累加可能失真 | 城市驾车绕行7公里 |
| 余弦相似度 | (A·B)/(|A||B|) → 方向一致性 | 文本向量、高维稀疏数据 | 抗量纲干扰 | 忽略长度信息 | 文章主题相似度0.92 |
| 点积相似度 | A·B = Σ(xᵢyᵢ) → 方向+强度 | 推荐系统、用户-商品匹配 | 综合方向和数值大小 | 需防大值主导 | 商品匹配度58分 |
| 杰卡德相似度 | |A∩B| / |A∪B| → 共同元素比例 | 集合数据(标签、购物车) | 抗数值干扰 | 忽略元素重复和顺序 | 购物车重合度30% |
| 汉明距离 | Σ(位不同) → 找不同字符数 | 等长序列(二进制、DNA) | 计算简单,适合纠错 | 要求等长,忽略差异度 | 密码“101” vs “001”距离1 |
参考:
Oracle AI Vector Search User’s Guide
》Vector Distance Metrics
VECTOR_DISTANCE()
VECTOR_DISTANCE()用于计算两个向量之间的数学距离,支持多种距离度量,用于实现向量相似性搜索。
例:
SELECT TO_NUMBER(VECTOR_DISTANCE(VECTOR('[0,0]', 2, float32), VECTOR('[4,3]', 2, float32), EUCLIDEAN
)) AS DISTANCE; -- 输出5.0
SQL> SELECT TO_NUMBER(VECTOR_DISTANCE(VECTOR('[0,0]', 2, float32), VECTOR('[4,3]', 2, float32), EUCLIDEAN)) AS DISTANCE; 2 3 4 5 DISTANCE
----------5SQL> VECTOR_DISTANCE 语法格式
VECTOR_DISTANCE 语法格式如下:
VECTOR_DISTANCE ( expr1 , expr2 [ , metric ] )
注:
- expr1/expr2:必须为同格式、同维度的向量,若为 JACCARD 或 HAMMING 度量,需为二进制向量(BINARY 类型)。
- metric(可选):指定距离度量标准,未指定时按规则自动选择默认值。
度量标准(metric )详细总结如下:
| 度量标准(metric ) | 说明 | 简写函数 | 操作符 | 示例 |
|---|---|---|---|---|
| COSINE | 计算向量的余弦距离(默认度量,非二进制向量场景)。 | COSINE_DISTANCE | <=> | VECTOR_DISTANCE(v1, v2, 'COSINE') 或 v1 <=> v2 |
| DOT | 计算负的向量点积(内积的相反数)。 | - | <#> | VECTOR_DISTANCE(v1, v2, 'DOT') 或 v1 <#> v2 |
| EUCLIDEAN | 计算欧氏距离(L2 距离)。 | L2_DISTANCE | <-> | VECTOR_DISTANCE(v1, v2, 'EUCLIDEAN') 或 v1 <-> v2 |
| EUCLIDEAN_SQUARED | 计算欧氏距离的平方(不进行开根号)。 | - | - | VECTOR_DISTANCE(v1, v2, 'EUCLIDEAN_SQUARED') |
| HAMMING | 计算汉明距离(二进制向量中不同维度的数量,默认度量于二进制向量场景)。 | HAMMING_DISTANCE | - | VECTOR_DISTANCE(bv1, bv2, 'HAMMING') |
| MANHATTAN | 计算曼哈顿距离(L1 距离 / 出租车距离)。 | L1_DISTANCE | - | VECTOR_DISTANCE(v1, v2, 'MANHATTAN') |
| JACCARD | 计算杰卡德距离(二进制向量的交集与并集比值的补集)。 | JACCARD_DISTANCE | - | VECTOR_DISTANCE(bv1, bv2, 'JACCARD') |
| 内积(特殊场景) | 计算向量点积,等价于 -1 * VECTOR_DISTANCE(..., 'DOT')。 | INNER_PRODUCT | - | INNER_PRODUCT(v1, v2) |
参考:
SQL Language Reference
》VECTOR_DISTANCE
VECTOR_DISTANCE()测试例
下面比较一下cat、dog以及durian的相似性。
欧式距离
SQL> SELECT TO_NUMBER(VECTOR_DISTANCE(VECTOR_EMBEDDING(ALL_MINILM_L12_V2 USING 'cat' as DATA) , VECTOR_EMBEDDING(ALL_MINILM_L12_V2 USING 'dog' as DATA) , EUCLIDEAN
)) AS DISTANCE; 2 3 4 5 DISTANCE
----------
.963576036SQL> SELECT TO_NUMBER(VECTOR_DISTANCE(VECTOR_EMBEDDING(ALL_MINILM_L12_V2 USING 'cat' as DATA) , VECTOR_EMBEDDING(ALL_MINILM_L12_V2 USING 'durian' as DATA) , EUCLIDEAN
)) AS DISTANCE; 2 3 4 5 DISTANCE
----------
1.17489175SQL>
可以看到猫和狗的欧式距离小,猫和榴莲的欧式距离大些,所以猫和狗更具有相似性。
余弦距离
SQL> SELECT TO_NUMBER(VECTOR_DISTANCE(VECTOR_EMBEDDING(ALL_MINILM_L12_V2 USING 'cat' as DATA) , VECTOR_EMBEDDING(ALL_MINILM_L12_V2 USING 'dog' as DATA) , COSINE
)) AS DISTANCE; 2 3 4 5 DISTANCE
----------
.464239355SQL> SELECT TO_NUMBER(COSINE_DISTANCE(VECTOR_EMBEDDING(ALL_MINILM_L12_V2 USING 'cat' as DATA) , VECTOR_EMBEDDING(ALL_MINILM_L12_V2 USING 'dog' as DATA)
)) AS DISTANCE; 2 3 4 DISTANCE
----------
.464239355SQL> SELECT TO_NUMBER(COSINE_DISTANCE(VECTOR_EMBEDDING(ALL_MINILM_L12_V2 USING 'cat' as DATA) , VECTOR_EMBEDDING(ALL_MINILM_L12_V2 USING 'durian' as DATA)
)) AS DISTANCE; 2 3 4 DISTANCE
----------
.690185448SQL> 内积(Inner Product) 和 点积(Dot Product) 距离
SQL> SELECT TO_NUMBER(INNER_PRODUCT(VECTOR_EMBEDDING(ALL_MINILM_L12_V2 USING 'cat' as DATA) , VECTOR_EMBEDDING(ALL_MINILM_L12_V2 USING 'dog' as DATA)
)) AS DISTANCE; 2 3 4 DISTANCE
----------
.535760716SQL>
SQL>
SQL> SELECT TO_NUMBER(
VECTOR_EMBEDDING(ALL_MINILM_L12_V2 USING 'cat' as DATA) <#> VECTOR_EMBEDDING(ALL_MINILM_L12_V2 USING 'dog' as DATA)
) AS DISTANCE; 2 3 DISTANCE
----------
-.53576072SQL>
SQL> SELECT TO_NUMBER(VECTOR_EMBEDDING(ALL_MINILM_L12_V2 USING 'cat' as DATA) <#> VECTOR_EMBEDDING(ALL_MINILM_L12_V2 USING 'durian' as DATA)
) AS DISTANCE; 2 DISTANCE
----------
-.30981447SQL>
在Oracle Vector Search中点积度量(DOT metric)计算两个向量的负点积,内积函数(INNER_PRODUCT function)计算点积。
参考
Oracle AI Vector Search User’s Guide
》Vector Distance Metrics
SQL Language Reference
》VECTOR_DISTANCE