【项目实训个人博客】数据集搜集
在当今的商业环境中,版权问题一直是一个敏感且重要的议题。由于版权的限制,商业推广的实时数据往往价格不菲,其高昂的成本超出了我们的预算范围。面对这一困境,我们经过深思熟虑,不得不采取一种折中的解决方案。于是,我们安排了专人,耐心地手动下载了 appgrowing 平台所发布的 4 月份的最新数据。在下载过程中,我们严格确保数据的完整性和准确性,因为我们期望这些真实可靠的数据,能够为 deepseekapi 提供坚实的依托,使其在后续的应用与分析中,能够有据可依,进而为我们的商业推广决策等提供有力的支持。
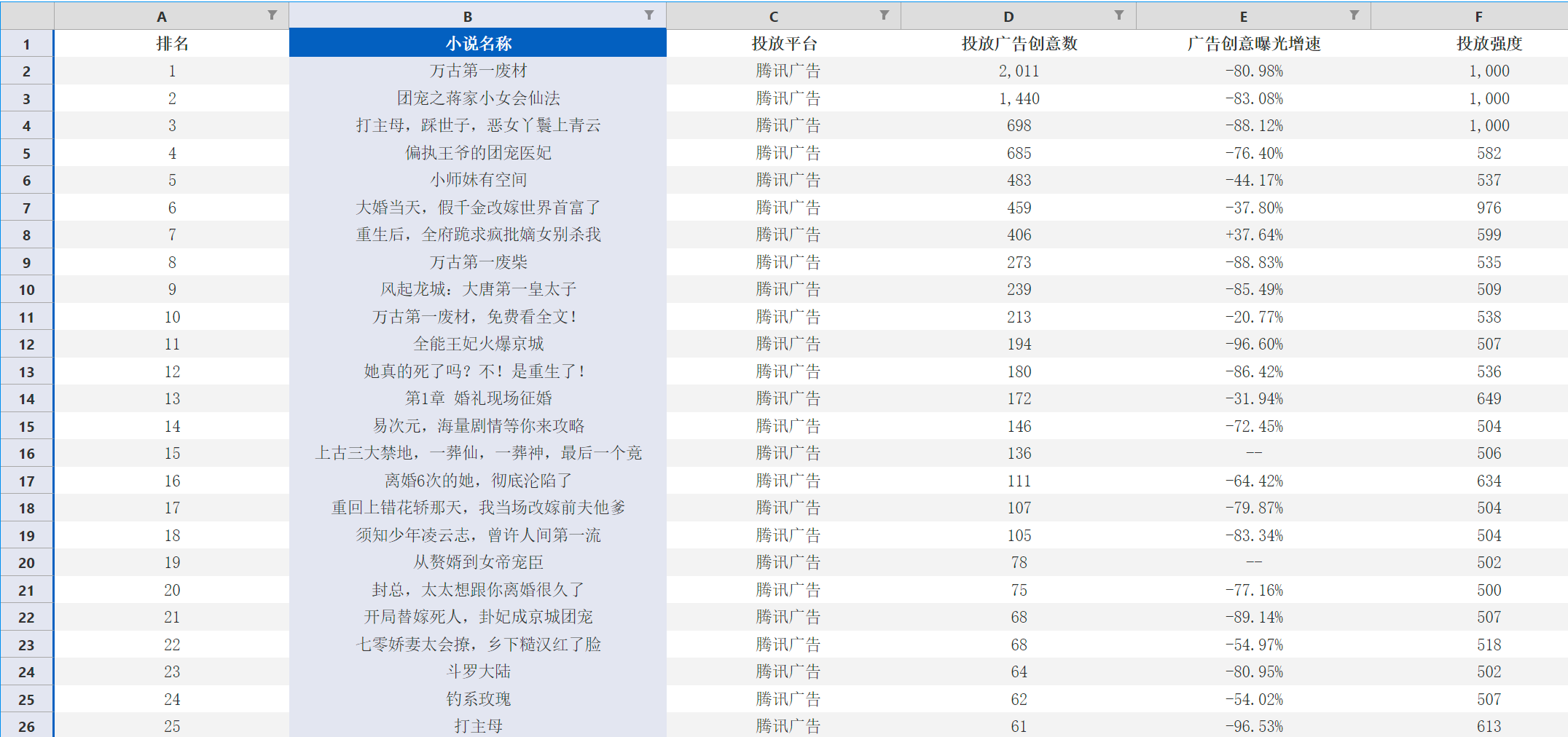
搜集的数据内容样例如下:
数据存储
方案:使用 JSON 存储行数据
这是目前处理半结构化或结构多变数据比较流行和灵活的方式,尤其适合 SQLite。
-
数据库表设计:
- Files 表: 用于记录处理过的 Excel 文件信息。
- file_id (INTEGER, 主键, 自增): 文件的唯一标识。
- file_path (TEXT, UNIQUE): Excel 文件的相对路径 (相对于 推广 目录)。
- sheet_name (TEXT): 文件中的工作表名称。
- headers (TEXT): 该文件/工作表的实际表头列表,存储为 JSON 数组字符串。例如:'["排名", "名称", "来源", "详情"]'。
- import_timestamp (DATETIME): 数据导入时间。
- DataRows 表: 用于存储每一行的数据。
- row_id (INTEGER, 主键, 自增): 行的唯一标识。
- file_id (INTEGER, 外键, 关联 Files.file_id): 这行数据属于哪个文件。
- row_index (INTEGER): 该行在原始 Excel 文件中的行号(可选,用于溯源)。
- row_data (TEXT): 核心字段。将 Excel 中的一整行数据(根据该文件的实际表头)转换成 JSON 对象字符串 存储。例如:'{"排名": 15, "名称": "六翼短剧", "来源": "抖音小程序", "详情": "重生之我才是乖乖小公..."}'。
-
数据导入过程 (预处理脚本):
- 遍历 推广 目录下的所有 .xlsx 文件。
- 对每个文件中的每个工作表(Sheet):
- 读取第一行作为表头 (headers)。
- 在 Files 表中查找或插入该文件和工作表的信息,记录 file_id 和 headers JSON 字符串。
- 逐行读取数据。
- 将每一行的数据与表头对应,构建一个 Python 字典。
- 将该字典转换为 JSON 字符串。
- 将 file_id, row_index, 和 row_data JSON 字符串插入到 DataRows 表中。
-
DataCrawling.execute 中使用:
- 连接数据库。
- 根据需要查询 DataRows 表。可以:
- 获取所有数据: SELECT row_data FROM DataRows;
- 获取特定文件的数据: SELECT dr.row_data FROM DataRows dr JOIN Files f ON dr.file_id = f.file_id WHERE f.file_path = ?;
- 取出的 row_data 是 JSON 字符串。
- 在 Python 代码中使用 json.loads() 将其解析回字典。
- 后续处理这些字典列表,整合成 seminar_conclusion 需要的格式。
-
优点:
- 极高灵活性: 无需关心 Excel 文件的具体表头是什么,也无需修改数据库表结构就能适应新的表头。
- 结构保留: JSON 格式保留了原始的键值对关系。
- SQLite 友好: SQLite 对 TEXT 类型支持良好。
-
缺点:
- 查询受限: 无法直接在 SQL 中对 JSON 内部的特定“列”(如 WHERE 名称 = '六翼短剧')进行高效查询或索引(除非使用较新版 SQLite 的 JSON 函数,但仍有局限)。大部分筛选逻辑需要在 Python 代码中完成。
- 存储开销: JSON 字符串比原生类型存储可能稍大。
最后
这一版方案存在数据加载量过大导致网页崩溃的问题,还得优化