【AI论文】CLIMB:基于聚类的迭代数据混合自举语言模型预训练
摘要:预训练数据集通常是从网络内容中收集的,缺乏固有的领域划分。 例如,像 Common Crawl 这样广泛使用的数据集并不包含明确的领域标签,而手动整理标记数据集(如 The Pile)则是一项劳动密集型工作。 因此,尽管预训练数据混合对预训练性能有显著的好处,但确定最佳的预训练数据混合仍然是一个具有挑战性的问题。 为了应对这些挑战,我们提出了基于聚类的迭代数据混合引导(CLIMB),这是一个自动化的框架,可以在预训练设置中发现、评估和优化数据混合。 具体而言,CLIMB将大规模数据集嵌入并聚类到语义空间中,然后使用较小的代理模型和预测器迭代搜索最优混合。 当使用这种混合物对400B令牌进行连续训练时,我们的1B模型超过了最先进的Llama-3.2-1B的2.0%。 此外,我们观察到,针对特定领域(如社会科学)进行优化,比随机抽样提高了5%。 最后,我们介绍了ClimbLab,这是一个经过筛选的1.2万亿令牌语料库,包含20个集群,作为一个研究游乐场,以及ClimbMix,这是一个紧凑但功能强大的4000亿令牌数据集,专为高效的预训练而设计,在相同的令牌预算下提供卓越的性能。 我们分析了最终的数据混合,阐明了最佳数据混合的特征。 我们的数据可在以下网址获取:CLIMB,Huggingface链接:Paper page,论文链接:2504.13161
研究背景和目的
随着大型语言模型(LLMs)的快速发展,预训练数据集在其性能提升中扮演了至关重要的角色。然而,预训练数据集通常是从网络内容中收集的,缺乏固有的领域划分。例如,广泛使用的Common Crawl数据集并不包含明确的领域标签,而手动整理标记数据集如The Pile则是一项劳动密集型工作。因此,尽管预训练数据混合对预训练性能有显著的好处,但确定最佳的预训练数据混合仍然是一个具有挑战性的问题。
本研究的目的是提出一种自动化的框架,即基于聚类的迭代数据混合引导(CLIMB),以在预训练设置中发现、评估和优化数据混合。CLIMB旨在通过大规模数据集在语义空间中的嵌入和聚类,以及使用较小的代理模型和预测器迭代搜索最优混合,从而在不依赖手动定义领域标签的情况下,提高预训练模型的性能。
研究方法
1. 数据预处理
- 文本嵌入:使用嵌入模型将文档映射到嵌入空间中,以便在相同集群内的文档之间实现更深的语义对齐。
- 嵌入聚类:采用k-means等聚类算法将嵌入后的文档分组为初始集群。为了后续处理的精细度,初始集群数量K_init设置为相对较大的值(如1000)。
- 集群合并:通过模型基分类器进行集群级别的修剪,去除低质量集群,并基于质心距离将剩余的高质量集群合并为增强集群(K_enhanced < K_pruned < K_init)。
2. 迭代引导:混合权重搜索
- 混合权重搜索作为双层优化问题:给定一组数据集群D={D1, D2,..., Dk}和目标函数ℓ(α,ω)(其中α为混合权重,ω为模型权重),目标是找到最优混合权重α*∈A,以最大化任务性能ℓ(α,ω)。
- 使用预测器近似目标函数:为了降低计算成本,使用预测器fθ(α)来近似目标函数ℓ(α,ω),基于一组(混合权重,性能)对进行训练。
- 迭代引导解决双层优化问题:通过坐标下降方法交替优化配置采样和预测器拟合子程序。在每次迭代中,根据预测性能对配置进行排序,并从顶部配置中随机采样新配置,以平衡利用和探索。然后,使用新采样的配置训练预测器,并用于评估配置和生成预测性能。
3. 实验设置
- 数据集:使用Nemotron-CC和smollm-corpus作为源数据集,通过CLIMB聚类得到21个超级集群,包含约8000亿令牌。评估在PIQA、ARC_C、ARC_E、HellaSwag、WinoGrande和SIQA等推理基准上进行。
- 模型:首先进行第一阶段预训练以建立坚实基础,然后训练62M、350M和1B三种规模的Transformer解码器模型。对于代理模型,使用62M和350M以提高效率。对于目标模型,评估所有三种规模以评估方法在不同尺度上的表现。
- 基线:与随机选择、DoReMi和RegMix等先进的数据混合方法进行比较。
研究结果
1. 与数据混合基线的比较
在350M和1B目标模型上,CLIMB在平均准确率上均优于所有基线数据混合方法。例如,在350M目标模型上,CLIMB的平均准确率为54.83%,高于随机选择的52.17%和最佳基线RegMix的53.78%。在1B目标模型上,CLIMB的平均准确率为60.41%,高于所有基线。
2. 与最先进的语言模型的比较
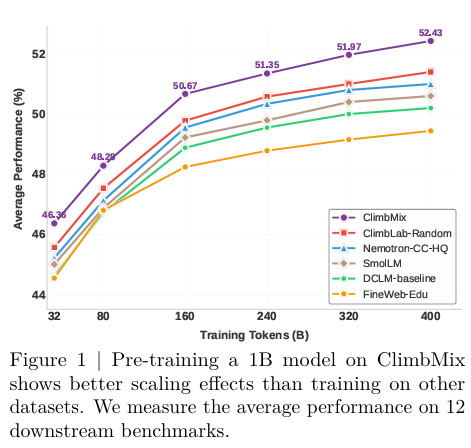
使用CLIMB找到的最优数据混合对400B令牌进行连续训练后,我们的1B模型在多数通用推理基准上均优于Llama-3.2-1B等先进基线,整体平均准确率提高了2.0%。
3. 针对特定领域的优化
除了优化通用推理任务外,CLIMB还能针对特定领域(如社会科学)进行优化。实验结果表明,针对社会科学领域的优化比随机抽样提高了5%的准确率。
4. 消融研究
- 搜索计算预算的影响:增加搜索的总计算量(如从100%增加到150%或200%)可以进一步提高下游准确性。
- 计算分配的影响:在迭代次数和每次迭代的搜索次数之间找到平衡(如4:2:1的分配比例)对于稳健地找到好的混合至关重要。
- 代理模型的影响:使用较大的代理模型(如350M)可以更准确地估计最终(较大)目标模型的性能。
- 集群数量的影响:CLIMB对集群数量不太敏感,表现出鲁棒性。
- 初始化方案的影响:Dirichlet初始化略优于随机初始化,但性能相当,表明数据混合方法对初始化选择不敏感。
研究局限
尽管CLIMB在预训练数据混合方面取得了显著成效,但仍存在一些局限性:
- 计算成本:尽管CLIMB通过迭代引导和使用较小的代理模型降低了计算成本,但在大规模数据集上进行嵌入、聚类和迭代搜索仍然需要相当的计算资源。
- 数据集依赖性:CLIMB的性能可能依赖于所使用的源数据集的质量和多样性。如果源数据集存在偏差或不足,可能会影响最终数据混合的效果。
- 预测器的局限性:预测器用于近似目标函数,但其准确性可能受到训练数据的质量和数量的限制。预测器的偏差可能会影响数据混合的搜索方向。
未来研究方向
- 降低计算成本:探索更高效的嵌入和聚类算法,以及更轻量级的代理模型,以进一步降低CLIMB的计算成本。
- 增强数据集的多样性和质量:研究如何整合更多样化的数据源,并改进数据清洗和过滤技术,以提高源数据集的质量和多样性。
- 改进预测器:研究更先进的预测器模型,以提高其对目标函数的近似准确性,从而更精确地指导数据混合的搜索过程。
- 扩展到更多领域和任务:将CLIMB扩展到更多领域和任务上,以验证其在不同场景下的有效性和通用性。
- 结合其他优化技术:探索将CLIMB与其他数据优化技术(如数据增强、数据选择等)相结合的可能性,以进一步提升预训练模型的性能。
总之,CLIMB为预训练数据混合提供了一种自动化的解决方案,通过迭代引导和预测器实现了对数据混合的有效搜索和优化。未来的研究可以进一步改进CLIMB的性能和效率,并探索其在更多领域和任务上的应用。