注意力机制(np计算示例)单头和多头
为了更好理解注意力机制里面的qkv矩阵,使用np来演示。
单头注意力
import numpy as np
import math# 初始化输入 X
X = np.array([[[1, 2, 3], [4, 5, 6]]])# 初始化权重矩阵 WQ、WK、WV
WQ = np.array([[1, 0], [0, 1], [0, 0]])WK = np.array([[1, 0], [0, 1], [0, 0]])WV = np.array([[1, 0], [0, 1], [0, 0]])# 计算 Q、K、V
# 使用np.matmul是高维矩阵运算的方法,np.dot是1维或2维的方法
Q = np.matmul(X, WQ)
K = np.matmul(X, WK)
V = np.matmul(X, WV)# 计算注意力分数
# d_k的维度 (1, 2, 2)
# 轴 0 对应 batch_size,表示批次大小,即一次处理的样本数量。
# 轴 1 对应 seq_length,表示序列长度,即每个样本中的元素数量。
# 轴 2 对应 hidden_dim,表示每个元素的特征维度。
d_k = K.shape[-1] # 这里使用qkv任意一个都可以,我们只是需要# 在论文中提到,除根号dk的意义,是为了缓解梯度小或梯度消失的问题
# 产生的原因:Q与K矩阵进行运算时,结果有可能小或者大,经过Softmax时,会使大的更大,小的更小。大的更接近1,小的更接近0.
# 这种两级分化的情况,容易让模型在反向传播时,使梯度变小,而模型无法收敛。
# 解决的方法:Q与K矩阵进行运算后除上根号dk,dk是元素的特征维度
# 在输入的特征向量长度,如果短,则除dk的意义不大,如果长,则依然可以使模型继续收敛,不会因为梯度小
# 而让模型收敛过于缓慢或者是不收敛。
# dk是论文公式里的,d_k是此代码中的变量scores = np.matmul(Q, K.transpose(0, 2, 1)) / math.sqrt(d_k)# 若想不以科学计数显示:
np.set_printoptions(suppress = True)
# 定义 Softmax 函数
def softmax(x):e_x = np.exp(x - np.max(x, axis=-1, keepdims=True))return e_x / np.sum(e_x, axis=-1, keepdims=True)# 计算注意力权重
weights = softmax(scores)# 计算注意力输出
output = np.matmul(weights, V)print("Q:", Q)
print()
print("K:", K)
print()
print("V:", V)
print()
print("scores:", scores)
print()
print("weights:", weights)
print()
print("output:", output)
print()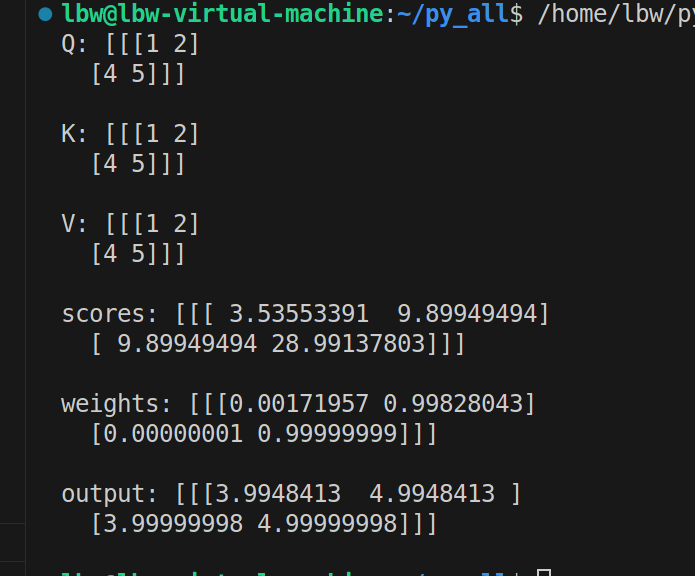
多头注意力机制
在此处的transpose本质是矩阵转置,用来便于并行计算。
import numpy as npdef scaled_dot_product_attention(Q, K, V, mask=None):"""计算缩放点积注意力:param Q: 查询矩阵,形状为 (batch_size, num_heads, seq_length, d_k):param K: 键矩阵,形状为 (batch_size, num_heads, seq_length, d_k):param V: 值矩阵,形状为 (batch_size, num_heads, seq_length, d_k):param mask: 掩码矩阵,可选,形状为 (batch_size, 1, 1, seq_length):return: 注意力输出,形状为 (batch_size, num_heads, seq_length, d_k);注意力权重,形状为 (batch_size, num_heads, seq_length, seq_length)"""# 获取 d_k 的值,用于缩放点积d_k = Q.shape[-1]# 计算 Q 和 K 的转置的点积,并除以根号 d_k 进行缩放scores = np.matmul(Q, K.transpose(0, 1, 3, 2)) / np.sqrt(d_k)# 如果提供了掩码,将掩码应用到分数上,将掩码位置的值设为负无穷大if mask is not None:scores = scores + (mask * -1e9)# 对分数应用 softmax 函数,得到注意力权重attention_weights = softmax(scores)# 将注意力权重与值矩阵 V 相乘,得到注意力输出output = np.matmul(attention_weights, V)return output, attention_weightsdef softmax(x):"""实现 softmax 函数,将输入转换为概率分布:param x: 输入数组:return: 经过 softmax 处理后的数组"""# 为了数值稳定性,减去每行的最大值e_x = np.exp(x - np.max(x, axis=-1, keepdims=True))# 计算 softmax 值return e_x / np.sum(e_x, axis=-1, keepdims=True)def multi_head_attention(X, num_heads, mask=None):"""实现多头注意力机制:param X: 输入矩阵,形状为 (batch_size, seq_length, d_model):param num_heads: 头的数量:param mask: 掩码矩阵,可选,形状为 (batch_size, 1, seq_length):return: 多头注意力输出,形状为 (batch_size, seq_length, d_model);注意力权重,形状为 (batch_size, num_heads, seq_length, seq_length)"""# 获取批次大小、序列长度和模型维度batch_size, seq_length, d_model = X.shape# 计算每个头的维度d_k = d_model // num_headsprint(d_k)# 初始化线性变换矩阵 W_Q、W_K、W_V# 这里使用固定值进行初始化,方便调试和理解W_Q = np.ones((d_model, d_model))W_K = np.ones((d_model, d_model))W_V = np.ones((d_model, d_model))# 对 X 进行线性变换得到 Q、K、VQ = np.matmul(X, W_Q)K = np.matmul(X, W_K)V = np.matmul(X, W_V)# 将 Q、K、V 分割成多个头# 先调整形状为 (batch_size, seq_length, num_heads, d_k)# 再交换轴 1 和 2,得到 (batch_size, num_heads, seq_length, d_k)Q = Q.reshape(batch_size, seq_length, num_heads, d_k).transpose(0, 2, 1, 3)K = K.reshape(batch_size, seq_length, num_heads, d_k).transpose(0, 2, 1, 3)V = V.reshape(batch_size, seq_length, num_heads, d_k).transpose(0, 2, 1, 3)# 如果有掩码,调整掩码形状以适应多头注意力计算if mask is not None:mask = mask[:, np.newaxis, np.newaxis, :]# 计算每个头的注意力output, attention_weights = scaled_dot_product_attention(Q, K, V, mask)# 合并头# 先交换轴 1 和 2,得到 (batch_size, seq_length, num_heads, d_k)# 再将最后两维合并,得到 (batch_size, seq_length, d_model)output = output.transpose(0, 2, 1, 3).reshape(batch_size, seq_length, d_model)# 最终的线性变换# 初始化线性变换矩阵 W_OW_O = np.ones((d_model, d_model))# 对合并后的输出进行线性变换output = np.matmul(output, W_O)return output, attention_weights# 示例使用
# batch_size = 2
# seq_length = 3
# d_model = 4
num_heads = 2# 使用固定输入矩阵 X
X = np.array([[[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]],[[13, 14, 15, 16], [17, 18, 19, 20], [21, 22, 23, 24]],]
)# 调用多头注意力函数
output, attention_weights = multi_head_attention(X, num_heads)
print("输入特在矩阵形状: ", X.shape)
print()
print("多头注意力输出形状:", output.shape)
print("注意力权重形状:", attention_weights.shape)