论文笔记-arXiv2025-FilterLLM
论文笔记-arXiv2025-FilterLLM: Text-To-Distribution LLM for Billion-Scale Cold-Start Recommendation
- FilterLLM:面向十亿级冷启动推荐的文本到分布大语言模型
- 摘要
- 1.引言
- 2.前言
- 2.1符号说明
- 2.2文本到判断
- 2.2.1候选生成(从数十亿到数百)
- 2.2.2交互模拟(从数百到数十)
- 3.方法
- 3.1总体框架
- 3.1.1文本到分布任务
- 3.1.2利用分布增强冷嵌入
- 3.2FilterLLM结构
- 3.2.1用户词汇扩展
- 3.2.2内容提示编码器
- 3.2.3分布预测
- 3.3FilterLLM训练
- 3.3.1用户词汇的初始化
- 3.3.2分布学习
- 3.3.3行为指导
- 4.实验
- 4.1设置
- 4.2离线评估
- 4.3泛化研究
- 4.4效率
- 4.5在线评估
- 5.总结
FilterLLM:面向十亿级冷启动推荐的文本到分布大语言模型
论文: FilterLLM: Text-To-Distribution LLM for Billion-Scale Cold-Start Recommendation
代码: 无
摘要
基于大模型的冷启动推荐遵循“文本到判断”的范式,即将用户-物品内容对作为输入,并逐步评估每对。为了保证效率,现有方法选择预筛选用户-物品对,但是这严重限制了LLM的推理能力。
为了克服这种限制,本文提出了一种“文本到分布”的范式,即在一次推理中预测整个用户集的物品交互概率分布。具体而言,本文提出了FilterLLM。首先,引入一个定制的分布预测和冷启动框架。然后,结合高效的用户词汇结构,以训练和存储亿级用户的嵌入。最后,详细说明分布预测和用户词汇构建的训练目标。
1.引言
“文本到推断”的范式一次只能推断一对用户-物品对,在实际应用中会导致线性增强的计算负担。这种推断范式存在以下局限性:
-
有限的用户表示:用户的表示是基于该用户交互的所有项目,但由于LLM的提示长度限制,用户的表示可能只包含部分交互。
-
高推理时间和资源成本:“文本到判断”方法的顺序性质要求LLM检查每一个用户项目对,从而导致大量的推理时间和资源消耗。
-
小型候选集:基于LLM的冷启动模型需要从数十亿用户选择小型候选人集,限制了LLM的推断能力。
采用“文本到分布”范式使得在单次推理中预测特定项目的亿级用户交互分布成为可能,从而直接解决了线性计算负担。然而,这种范式转变引入了三个关键挑战:
-
用户建模:现有的方法受到同时建模的用户数量的限制。设计一种能够并行建模数百万用户的解决方案是一个重大挑战。
-
分布预测:虽然LLMs在预测下一个词的分布方面表现出色,但在亿级用户中预测分布则是一项独特且复杂的挑战。
-
LLM训练:LLMs可以利用现有的语料库和监督微调进行训练。然而,将这一训练范式调整到推荐领域,尤其是关注用户意图分布的场景,仍然是一个未解决的问题。
为了解决以上问题,本文提出了FilterLLM,主要贡献如下:
-
提出了一种单次推理的“文本到分布”范式,用于基于LLM的冷启动推荐,从根本上解决了“文本到判断”方法的迭代推理负担。
-
设计并实现了FilterLLM框架,展示了如何有效预测用户交互分布以及如何训练FilterLLM的各个组件。
2.前言
2.1符号说明
U U U、 I I I 和 H H H 表示用户集、项目集和交互集。项目集 I I I 可以分为温项目集 I w I_w Iw(有交互历史的项目)和冷项目集 I c I_c Ic(没有交互历史的项目)。对于每个热项目 i ∈ I w i \in I_w i∈Iw,与项目 i i i 交互的用户集合用 U i U_i Ui 表示。此外,令 C C C 表示所有项目的内容集,其中每个项目 i i i 关联有特定的内容特征 c i \mathbf{c}_i ci。
2.2文本到判断
基于 LLM 的“文本到判断”冷启动方法利用大语言模型为冷启动项目生成交互,生成过程可以分为两个步骤。
2.2.1候选生成(从数十亿到数百)
构建候选集,减少 LLM 需要处理的对数。这个过程可以定义为:
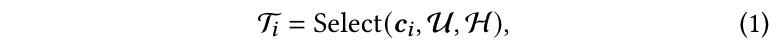
其中 T i ⊂ U T_i \subset U Ti⊂U 表示由 LLM 处理的项目 i i i 的候选用户集,而 Select ( ⋅ ) \text{Select}(\cdot) Select(⋅) 表示预定义的选择规则,例如传统的冷启动模型或随机选择。
2.2.2交互模拟(从数百到数十)
获得候选用户集后,每个用户与冷项目 i i i 配对,并将该对输入 LLM,预测其是否代表真实的交互。这个过程可以表述为:
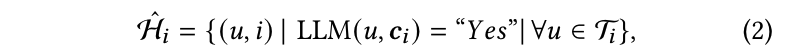
其中 H ^ i \hat{H}_i H^i 是冷项目 i i i 的模拟交互集,而 LLM ( u , i ) = “Yes” \text{LLM}(u, i) = “\text{Yes}” LLM(u,i)=“Yes” 表示大模型模拟了用户 u u u 与项目 i i i 之间的交互。
3.方法
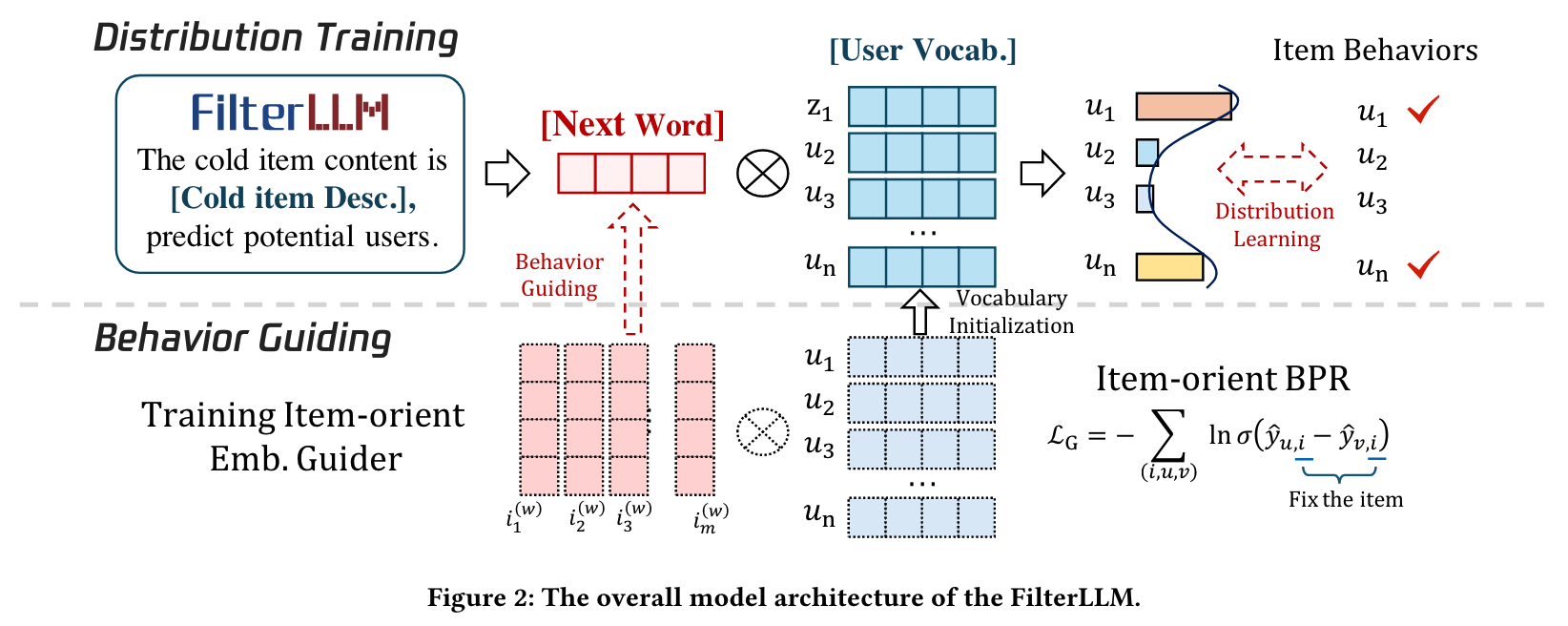
整体框架如图2所示。
3.1总体框架
3.1.1文本到分布任务
该任务的目标是利用大模型将冷项目的内容(以文本形式表示)映射到用户分布。该分布通过考虑所有历史用户行为以及用户、项目和上下文信息来学习。这个过程可以表述为:
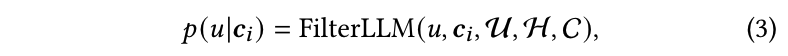
其中 FilterLLM ( ⋅ ) \text{FilterLLM}(\cdot) FilterLLM(⋅) 表示一个函数,用于在一次传递中生成给定项目的用户分布。
3.1.2利用分布增强冷嵌入
使用生成的用户分布为每个冷项目抽样一个交互集 H ^ i \hat{H}_i H^i 来更新其嵌入,公式如下:
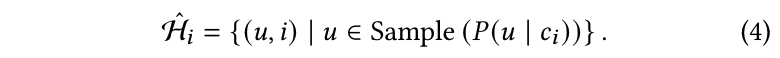
这里, Sample ( ⋅ ) \text{Sample}(\cdot) Sample(⋅) 表示一种抽样策略,从项目 i i i 的用户分布 P ( u ∣ c i ) P(u | \mathbf{c}_i) P(u∣ci) 中生成一组用户 u u u。一旦为冷项目抽样了交互,这些冷项目就可以利用这些交互进行更新。通过利用抽样的交互,最终用于下游任务的冷嵌入可以表示为:
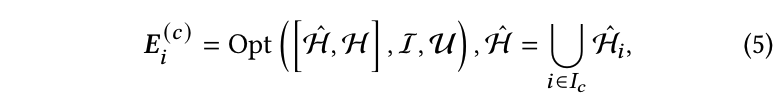
其中 E i ( c ) E^{(c)}_i Ei(c) 表示更新后的冷项目嵌入矩阵,由优化函数 Opt ( ⋅ ) \text{Opt}(\cdot) Opt(⋅) 生成。 [ H ^ , H ] [\hat{H},H] [H^,H] 是一个交互集,包含原始交互 H H H 和所有抽样的交互 H ^ \hat{H} H^。
3.2FilterLLM结构
基于上述思路,核心挑战是如何有效地完成“文本到分布”的任务。本文通过引入用户特定的词汇来扩展 LLM 的原始词汇。这一扩展使 LLM 能够在一次前向传递中将数十亿用户建模为一个分布,利用扩展用户词汇中预存的用户表示。
3.2.1用户词汇扩展
为了支持用户分布预测,本文通过引入专门的用户词汇将用户特征融入到LLM中,其中每个用户 ID 被表示为模型中的一个唯一标记。用户词汇定义为:
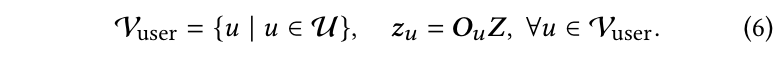
其中 Z ∈ R ∣ U ∣ × d \mathbf{Z} \in \mathbb{R}^{|U|\times d} Z∈R∣U∣×d 表示在 LLM 中学习到的用户标记嵌入, z u ∈ R d \mathbf{z}_u \in \mathbb{R}^d zu∈Rd 表示用户 u u u 的嵌入,而 O u ∈ R ∣ U ∣ \mathbf{O}_u \in \mathbb{R}^{|U|} Ou∈R∣U∣ 是对应于用户 u u u 的独热向量。这些用户标记仅在 LLM 的输出空间中使用,使得模型能够预测用户分布,而无需在输入中显式描述用户。
3.2.2内容提示编码器
输入提示的结构如下:“假设您是推荐专家。一个项目的内容如下 Text,请预测该项目的潜在用户。”然后,这个提示将通过一系列堆叠的自注意力和前馈模块映射到隐空间,表达式如下:
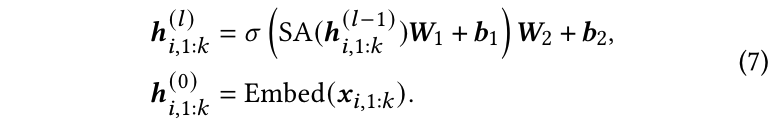
SA ( ⋅ ) \text{SA}(\cdot) SA(⋅) 和 Embed ( ⋅ ) \text{Embed}(\cdot) Embed(⋅) 分别是自注意力和嵌入函数。此外, x i , 1 : k = Prompt ( c i ) \mathbf{x}_{i,1:k} = \text{Prompt}(\mathbf{c}_i) xi,1:k=Prompt(ci) 表示从项目内容 c i \mathbf{c}_i ci 派生的提示标记序列。 h i , 1 : k ( l ) ∈ R k × d \mathbf{h}^{(l)}_{i,1:k} \in \mathbb{R}^{k \times d} hi,1:k(l)∈Rk×d 指的是 LLM 第 l l l 层输出的隐藏向量, k k k 是 x i , 1 : k \mathbf{x}_{i,1:k} xi,1:k 的长度。使用最后一层的最终隐藏状态向量 h i , k ( N ) ∈ R d \mathbf{h}^{(N)}_{i,k} \in \mathbb{R}^d hi,k(N)∈Rd 来表示项目内容提示。
3.2.3分布预测
在对项目提示进行编码后,进一步将其转化为用户概率分布,依赖于用户词汇。具体而言,在 LLM 的输出上添加一个概率分布预测头 f l : R d → P ( J ) f_l : \mathbb{R}^d \to P(J) fl:Rd→P(J),该头将项目内容表示 h i , k ( N ) \mathbf{h}^{(N)}_{i,k} hi,k(N) 映射到概率空间 P ( J ) P(J) P(J)。函数 f l f_l fl 的权重与扩展用户词汇的嵌入密切相关,可以写成如下形式:
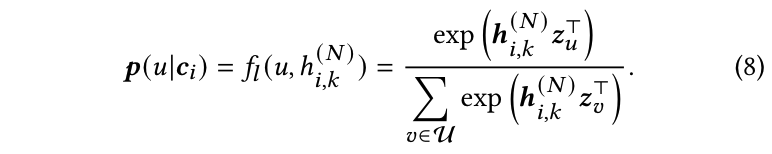
用户分布可以表示为 u ∼ p ( u ∣ c i ) u \sim p(u | \mathbf{c}_i) u∼p(u∣ci),这意味着基于项目内容 c i \mathbf{c}_i ci 生成用户 u u u。
3.3FilterLLM训练
3.3.1用户词汇的初始化
本文提出一种协作驱动的方法来初始化用户标记嵌入。具体而言,引入了一种面向项目的 BPR 损失,用于初始化用户标记嵌入,具体公式如下:
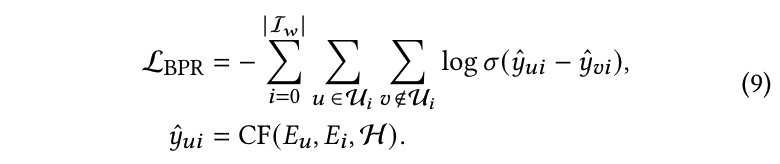
σ \sigma σ表示 sigmoid 函数, CF ( ⋅ ) \text{CF}(\cdot) CF(⋅) 指代一种协同过滤方法。本工作采用一种基于图的方法来捕捉用户与项目之间的高阶关系。 E u ∈ R ∣ U ∣ × d \mathbf{E}_u \in \mathbb{R}^{|U| \times d} Eu∈R∣U∣×d 和 E i ∈ R ∣ I w ∣ × d \mathbf{E}_i \in \mathbb{R}^{|I_w| \times d} Ei∈R∣Iw∣×d 分别是用户和项目的行为嵌入矩阵,这些矩阵在训练过程中学习得到。 E i \mathbf{E}_i Ei 将作为后续 FilterLLM 训练中的项目嵌入引导。
在获得嵌入矩阵后,用户标记嵌入可以初始化为:
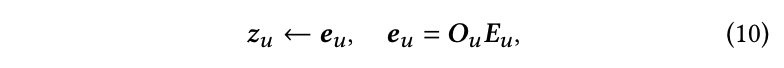
3.3.2分布学习
为了优化用户概率分布,目标是确保与该项目交互的正用户的概率尽可能高,而与未交互的负用户的概率尽可能低。此外,需要将概率计算方法与下一个标记预测对齐,以保持与 LLM 的一致性。因此,本文采用 logsoftmax 损失来优化用户预测分布。具体而言,损失可以表示为:
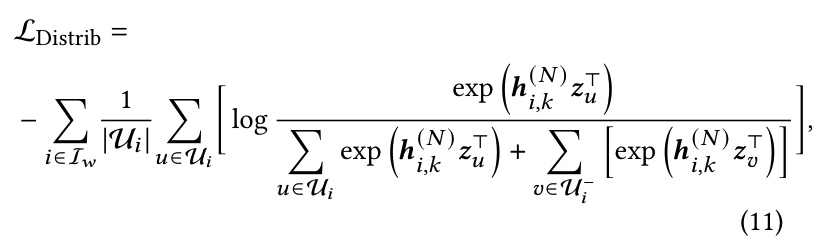
3.3.3行为指导
在训练的早期阶段,主要用于自然语言处理任务的 LLM 通常难以有效解释带有协作信息的用户词汇。为了解决这个问题,本文引导 LLM 从嵌入的角度模仿用户与项目交互中观察到的行为模式,使其能够捕捉 LLM 通常遗漏的高阶用户-项目关系。这种方法有助于模型克服其自然语言关注点与协作数据之间的初始不一致。
具体而言,行为指导损失可以计算如下:
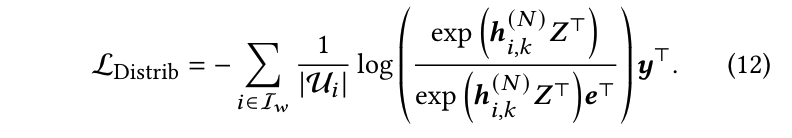
4.实验
4.1设置
数据集:CiteULike和ML-10M
基线:
-
基于 dropout 的嵌入模拟模型:DropoutNet、MTPR、Heater 和 CLCRec
-
基于生成的嵌入模拟模型:DeepMusic、MetaEmb、GAR 和 ALDI
-
交互模拟模型:USIM、MI-GNN、Wang 等 和 ColdLLM
评估指标:Recall@20 and NDCG@20
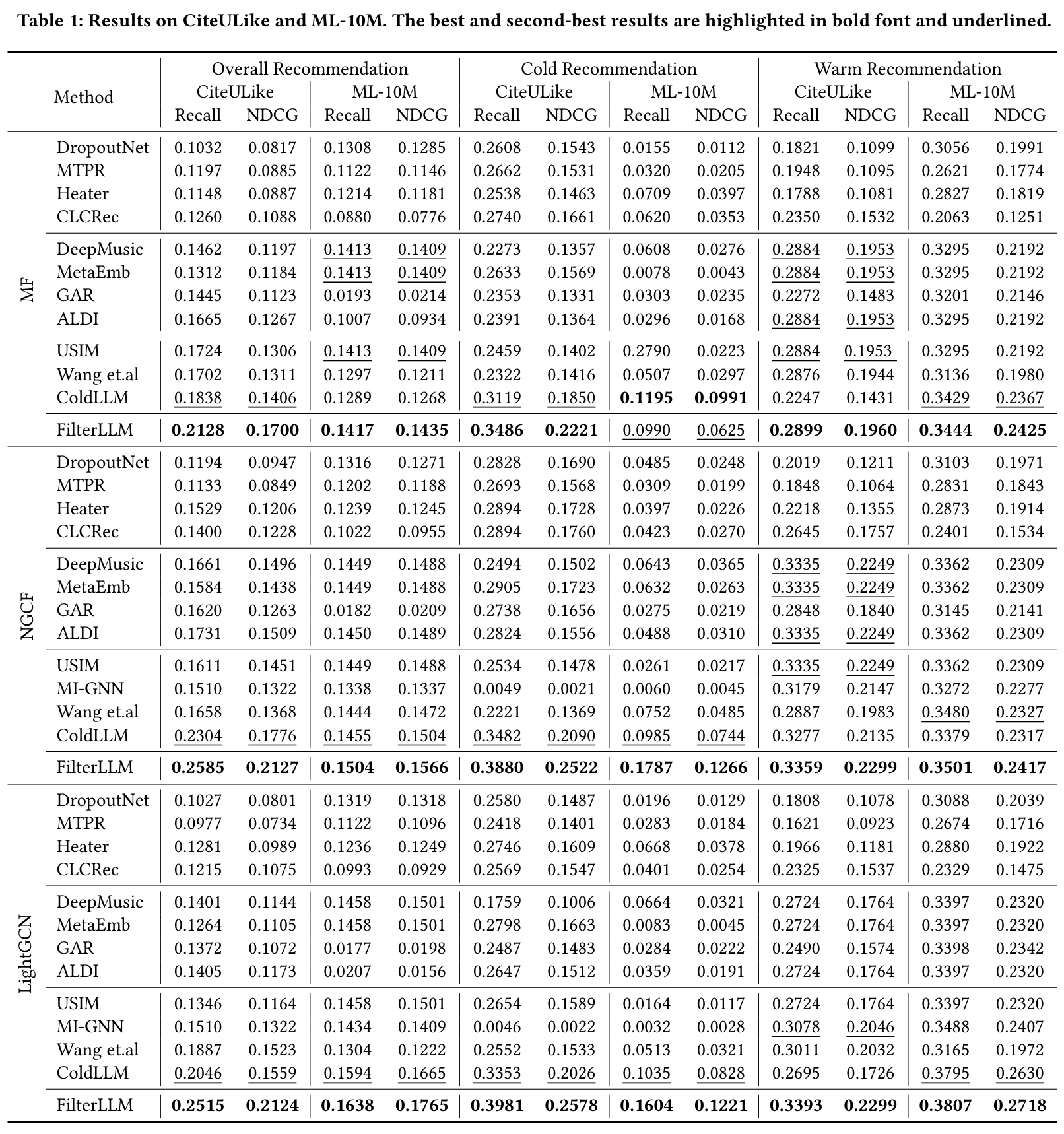
4.2离线评估
结论:
-
FilterLLM 在各个基线模型中表现出显著优势。
-
基于 LLM 的基线 ColdLLM 在其他基线中表现最佳。
-
基于 Dropout 的嵌入模拟器在整体和温暖推荐场景中的表现不如其他两种方法。
4.3泛化研究
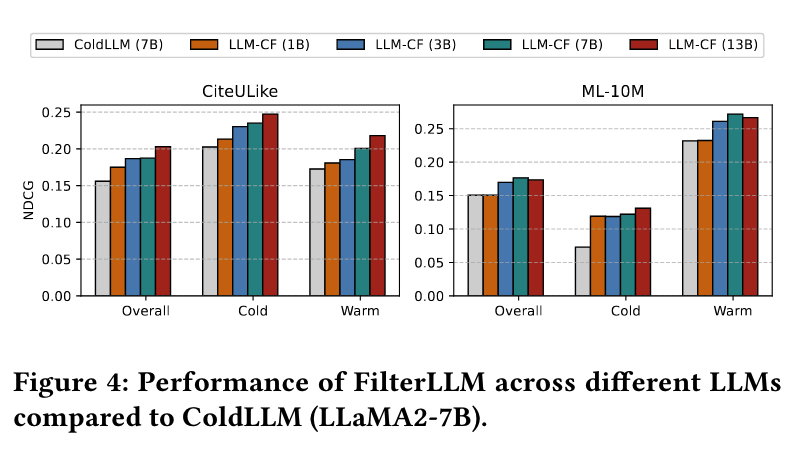
为了评估 FilterLLM 在不同 LLM 基础架构上的泛化能力,本文对四个具有不同参数规模的基础 LLM 进行了实验:LLaMA3-1B、LLaMA3-3B、LLaMA2-7B 和 LLaMA2-13B,并与 ColdLLM (LLaMA2-7B) 进行了比较。结果如图 4 所示:
结论:
-
FilterLLM 在所有 LLM 基础架构上表现出色。
-
随着 LLM 参数规模的增加,FilterLLM 的性能呈现出改善的趋势。
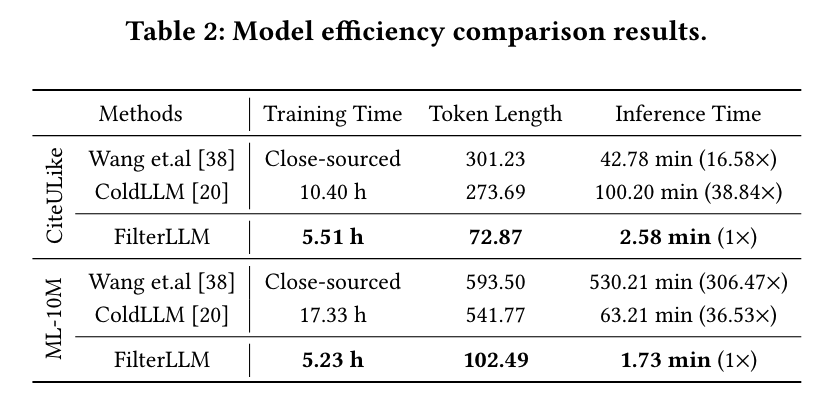
4.4效率
结论:
-
FilterLLM 的模型训练时间显著短于 ColdLLM。
-
FilterLLM 的推理时间显著快于其他基于 LLM 的模型。
4.5在线评估
为了在工业环境中评估 FilterLLM,本文在阿里巴巴的平台上进行了为期两个月的在线 A/B 测试,该平台每天有 3 亿用户,新增 100 万个项目。用户被随机分为两个相等的组进行 A/B 测试,FilterLLM 与 ALDI 和 ColdLLM 进行比较。
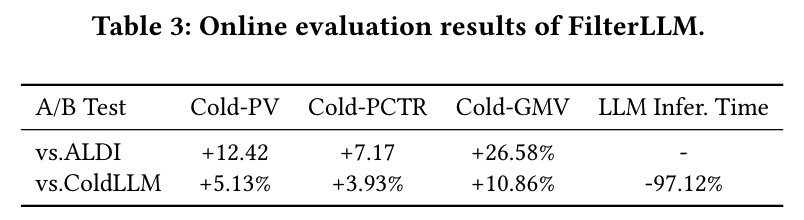
结论:
-
FilterLLM 在冷启动推荐场景中在多个指标上表现出显著改善。
-
与 ColdLLM 相比,FilterLLM 显著提升了 LLM 推理效率。
5.总结
本文提出了一种新颖的“文本到分布”范式,使 LLM 能够在一次推理中预测用户与项目的交互分布。在此基础上,本文引入了 FilterLLM,一个旨在扩大 LLM 推理能力以支持大规模冷启动推荐的框架。FilterLLM 在阿里巴巴的平台上部署了两个月,成为冷启动推荐的核心。大量实验验证了其在离线和在线评估中的有效性和效率。