多模态知识图谱:重构大模型RAG效能新边界

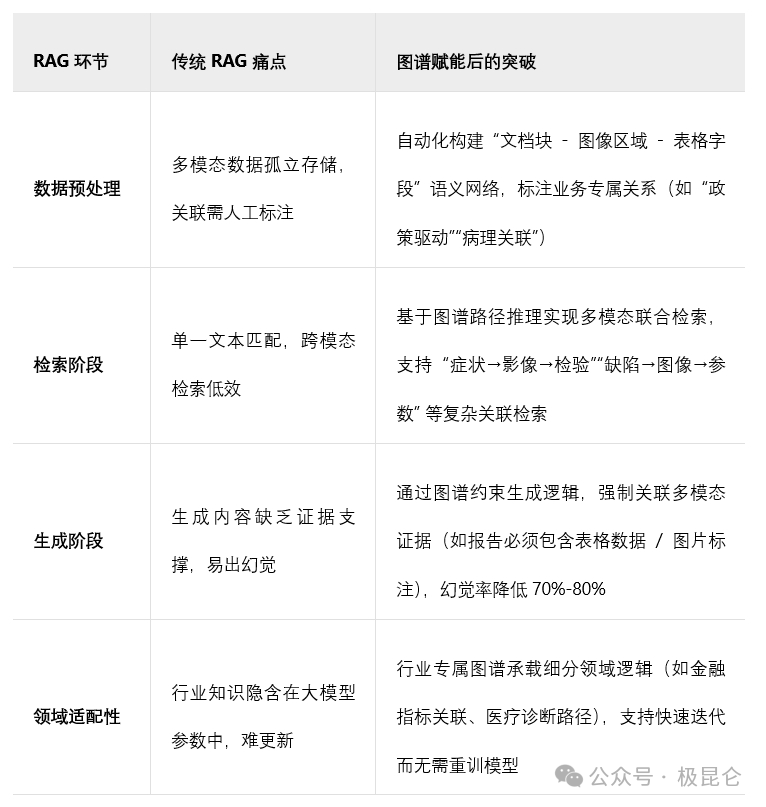
当前企业级RAG(Retrieval-Augmented Generation)系统在非结构化数据处理中面临四大核心问题:
-
数据孤岛效应:异构数据源(文档/表格/图像/视频)独立存储,缺乏跨模态语义关联,导致知识检索呈现碎片化。例如合同文本中的设备型号无法关联操作手册中的技术参数,质检报告中的缺陷描述无法匹配生产线监控视频。
-
语义鸿沟:传统向量检索依赖局部关键词匹配,难以捕捉跨文档的隐含逻辑关系(如报告中的图表引用意图)。
-
复杂推理失效:面对多层级查询(如"分析原材料涨价对下游产业链的影响"),系统无法构建跨文档、跨模态的推理链条,导致生成内容逻辑断裂。
-
动态知识滞后:业务数据持续更新时,静态知识库无法实时融合新数据,导致生成内容时效性不足。
多模态知识图谱构建
1.多模态数据解析与实体萃取
-
文档级解构:通过大模型将文档拆分为章节、段落(块),提取关键实体(如合同中的 “甲方”“标的金额”);利用 OCR 技术解析图片 / 表格,转化为结构化元数据(如财报表格中的 “营收指标”“时间维度”)。
-
跨模态对齐:采用 CLIP 模型实现视觉 - 文本联合嵌入,例如将产品图片中的零部件与技术文档中的参数描述映射至统一向量空间,支持 “以图搜文”“以表引文” 的跨模态检索。案例:某汽车厂商整合 20 万份设计图纸与工艺文档,通过实体萃取建立 “零部件图片 - 材料参数表 - 加工工艺段落” 的关联,检索效率提升 60%。
2.语义关系建模与图谱构建
-
微观层:通过图神经网络(GNN)构建段落级关联,识别文档块之间的逻辑关系(如 “因果”“并列”“引用”),例如法律文档中 “违约条款” 与 “赔偿公式” 的推导关系。
-
宏观层:构建文档级知识图谱,通过共现分析、时序关联等算法连接不同文档,如将 “年度财报” 与 “季度市场分析报告” 通过 “时间 - 指标” 维度关联。
-
动态更新机制:引入增量学习算法,实时捕获新数据的实体与关系,自动更新图谱(如新闻事件触发 “企业 - 产品 - 市场反应” 的关联更新),确保知识库与业务动态同步。
3.检索生成增强:图谱驱动的智能交互
-
检索环节:基于知识图谱的路径推理优化检索策略,例如用户查询 “某药物副作用” 时,系统不仅检索文本描述,还关联该药物临床试验图片中的副作用标注区域、剂量表格中的安全阈值,返回包含多模态证据的结果。
-
生成环节:通过图谱约束生成逻辑,确保回答覆盖关联数据,如生成投资报告时,自动关联同行业财报表格中的财务指标对比、市场趋势图中的数据拐点,提升内容的逻辑性与丰富度。
多模态图谱重构RAG能力
行业实践
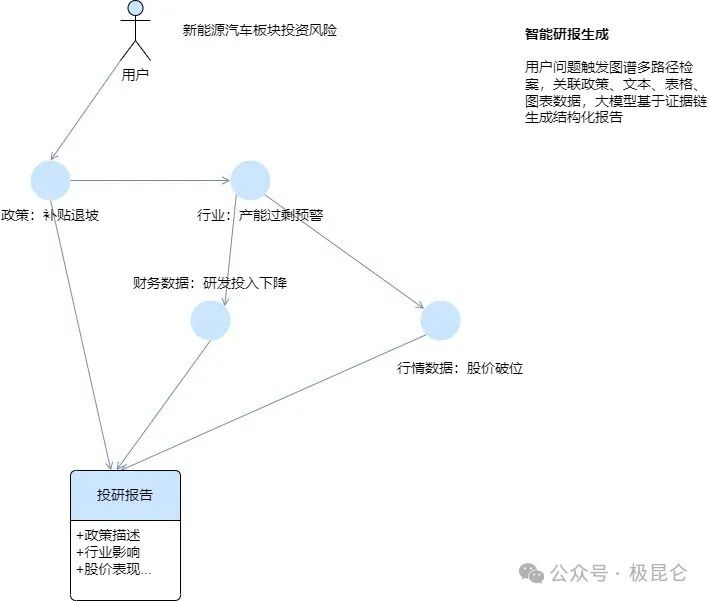
1.金融领域:大模型 RAG 驱动的智能研报生成
1)数据预处理阶段:
将研报拆分为 “行业分析”“风险提示” 等文档块,通过 OCR 提取财报表格字段(如 “研发投入占比”“毛利率”),用 CLIP 模型生成图表区域的视觉嵌入,构建 “文档块 - 表格字段 - 图表区域” 的关联图谱,标注 “政策影响”“指标波动” 等业务关系。
2)检索阶段:
当用户提问 “新能源汽车板块投资风险” 时,RAG 系统不再局限于文本检索,而是通过图谱路径推理:
政策文档块(补贴退坡)→行业分析块(产能过剩预警)→财报表格字段(研发投入下降)→K线图关键点位(股价破位),一次性召回多模态关联数据,检索覆盖度提升 60%。
3)生成阶段:
大模型基于图谱关联的证据链生成报告,自动引用 “补贴退坡条款原文”“研发投入同比下降 15% 的表格数据”“近 3 个月股价波动图拐点标注”,并通过图谱约束避免生成无依据的结论,幻觉率从 8% 降至 1.5%。。
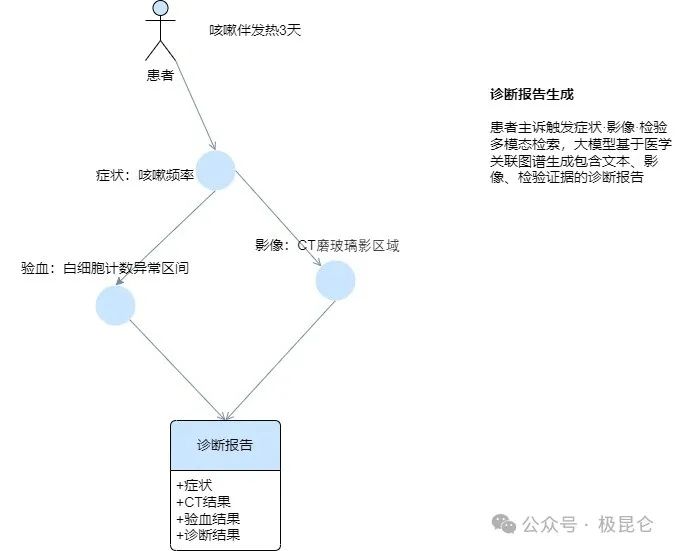
2. 医疗领域:多模态 RAG 辅助诊断系统
某三甲医院部署大模型 RAG 用于肺炎辅助诊断,整合 20 万份电子病历(含症状描述段落)、10 万张 CT 影像(标注 20 + 肺部特征区域)、5 万份检验报告(含 30 + 血液指标),目标是提升诊断效率并减少误诊。
1)数据预处理阶段:
将病历拆分为 “主诉”“现病史” 等段落,用 NLP 提取 “咳嗽频率”“发热天数” 等症状实体;通过视觉模型标注 CT 影像中的 “磨玻璃影区域”“实变区”;结构化检验报告中的 “白细胞计数”“C 反应蛋白” 等指标,构建 “症状段落 - 影像区域 - 检验指标” 的诊断关联图谱,标注 “症状 - 影像映射”“指标阈值关联” 等医学关系。
2)检索阶段:
当输入患者主诉 “咳嗽伴发热 3 天”,RAG 系统通过图谱检索:
咳嗽频率段落→CT磨玻璃影区域→白细胞计数异常区间,同步召回文本症状描述、影像特征标注、检验数据异常值,相比传统 RAG 仅检索文本,证据丰富度提升 300%。
3)生成阶段:
大模型基于图谱证据链生成诊断报告,自动关联 “咳嗽频率≥10 次 / 小时的病历段落”“左肺下叶磨玻璃影的 CT 标注”“白细胞计数 15×10^9/L的检验结果”,并通过图谱验证指标逻辑(如 “白细胞升高→细菌感染可能性”),诊断建议准确率从 82% 提升至 94%。
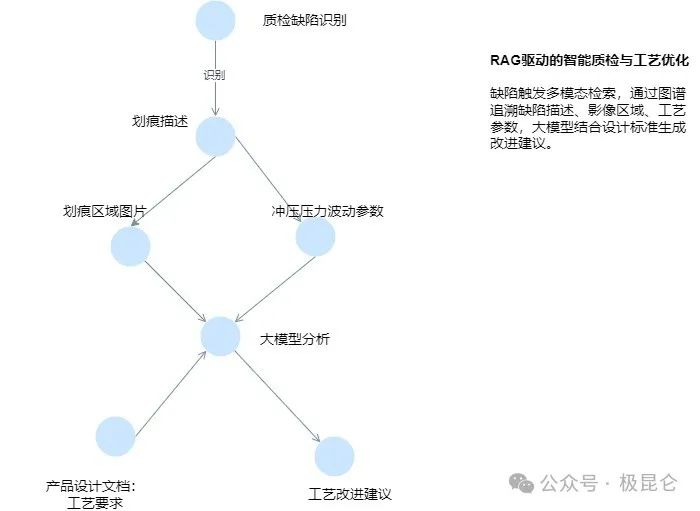
3. 制造业:RAG 驱动的智能质检与工艺优化
某汽车零部件厂商部署大模型 RAG 系统,整合 5 万份设计文档(含材料 / 工艺要求段落)、10 万张质检图片(标注 10 + 缺陷类型区域)、3 万份工艺参数表(含 20 + 关键参数),目标是通过 RAG 快速定位生产缺陷根源并生成改进建议。
1)数据预处理阶段:
将设计文档拆分为 “材料硬度要求”“表面粗糙度标准” 等段落,用 OCR 识别质检图片中的 “划痕区域”“凹陷区域” 坐标,结构化工艺参数表中的 “冲压压力”“温度波动” 等字段,构建 “缺陷描述 - 影像区域 - 工艺参数” 的追溯图谱,标注 “缺陷 - 参数关联”“标准 - 实测对比” 等制造关系。
2)检索阶段:
当质检系统识别到 “产品表面划痕”,RAG 系统通过图谱推理:
划痕描述段落→质检图片划痕区域→冲压压力波动参数→设计文档硬度标准,同步召回缺陷文本描述、影像定位、异常参数、设计标准,相比传统 RAG 仅检索文本,问题定位效率提升 500%。
3)生成阶段:
大模型基于图谱追溯链生成改进建议,自动关联 “表面粗糙度≥1.6μm 的设计要求”“冲压压力超出阈值 20% 的参数表”“划痕区域分布热力图”,并通过图谱验证参数逻辑(如 “压力过高→材料表面损伤”),建议准确率从 60% 提升至 85%。
结语
在企业数字化转型中,非结构化数据不再是低效利用的 “暗数据”,而是通过关联图谱转化为可检索、可推理、可生成的 “智能资产”。极昆仑以 “全模态知识图谱引擎” 重构 RAG 技术框架,让每一份文档、每一张图片、每一个表格都成为智能决策的基石。
更多内容请点击:
极昆仑![]() http://kingkunlun.com/
http://kingkunlun.com/
北京极昆仑智慧科技有限公司(简称 “极昆仑智慧”),是一支深耕 NLP 技术长达 10 年的专业人工智能团队。极昆仑以成熟的NLP能力平台为技术基座,融合自训练昆仑墟大语言模型(LLM),打造kunlun-core智能体能力平台及kunlun-x综合应用平台。针对垂直领域需求,依托混合模型(大模型+小模型)方案,结合具体业务场景特征,为用户提供高效智能服务落地解决方案。