On the Biology of a Large Language Model——Claude团队的模型理解文章【论文阅读笔记】其一CLT与LLM知识推理
这个学习笔记,是在精读Anthropic的博客 On the Biology of a Large Language Model 的过程中留下的笔记。
由于原文非常长,我会分2-3 个博客来写。
作者的思路
作者对常用的LLM特征解读工具 SAE/Transcoder 进行了优化,增加了跨层连接的能力和替换主模型的能力,开发出了一个新的解释工具 CLT(cross-layer transcoder),然后用这个解释工具分析Claude模型,在↓
- 知识推理
- 写作规划
- 表征空间
- 数学上的“加法运算”
- 越狱防范
- COT可靠性
- 价值观改变
这些层面上的工作机制。
本篇先介绍 1. CLT模型;2. Claude在知识推理和写作规划上的工作机制。
分析工具 CLT
模型解释的思路
针对<模型隐层特征>的分析解释的工作,大体是围绕着这样一个思路展开的↓:
第一步:提炼特征
不管是最近常用的SAE、Transcoder还是Claude团队的CLT(cross-layer transcoder),核心逻辑都是先用一个超大的码表(codebook)来映射Transformer模型中的特征。
第二步:特征和句子中的token进行关联分析。
在有了码表以后,就要将<码表中的code>与<LLM中的token或语义>进行关联。比如,如果码表中第1257号特征激活的时候,"capital"这个token或者这个概念被LLM生成的概率提高,那说明这个token和capital“牵手成功”。
这个思路中要解的关键问题
1)如何保证提炼的特征有效?——减小还原误差
像一般的AE一样,只要隐层特征有能力还原出<输入>,就说明提炼出了输入中的关键信息。SAE和Transcoder使用的都是和目标输出的还原误差作为自己的训练目标。
2)如何保证特征可解释——强迫稀疏性
此类方法都用了稀疏化的正则项来保证在训练的过程中,压迫自身码表的稀疏性。这样能够大大压制神经网络模型的特征堆叠现象,避免一个解释code对应多个原模型特征。而且,即便是出现码表中有多个特征对应到了一个Transformer的抽象特征上,只要把这些特征划到一个分组上就行了。
CLT的特殊之处
下图的左侧子图就是CLT的结构–>以LLM每层的attention运算结果项作为输入,FFN层的输出作为输出,逐层向前传递信息。
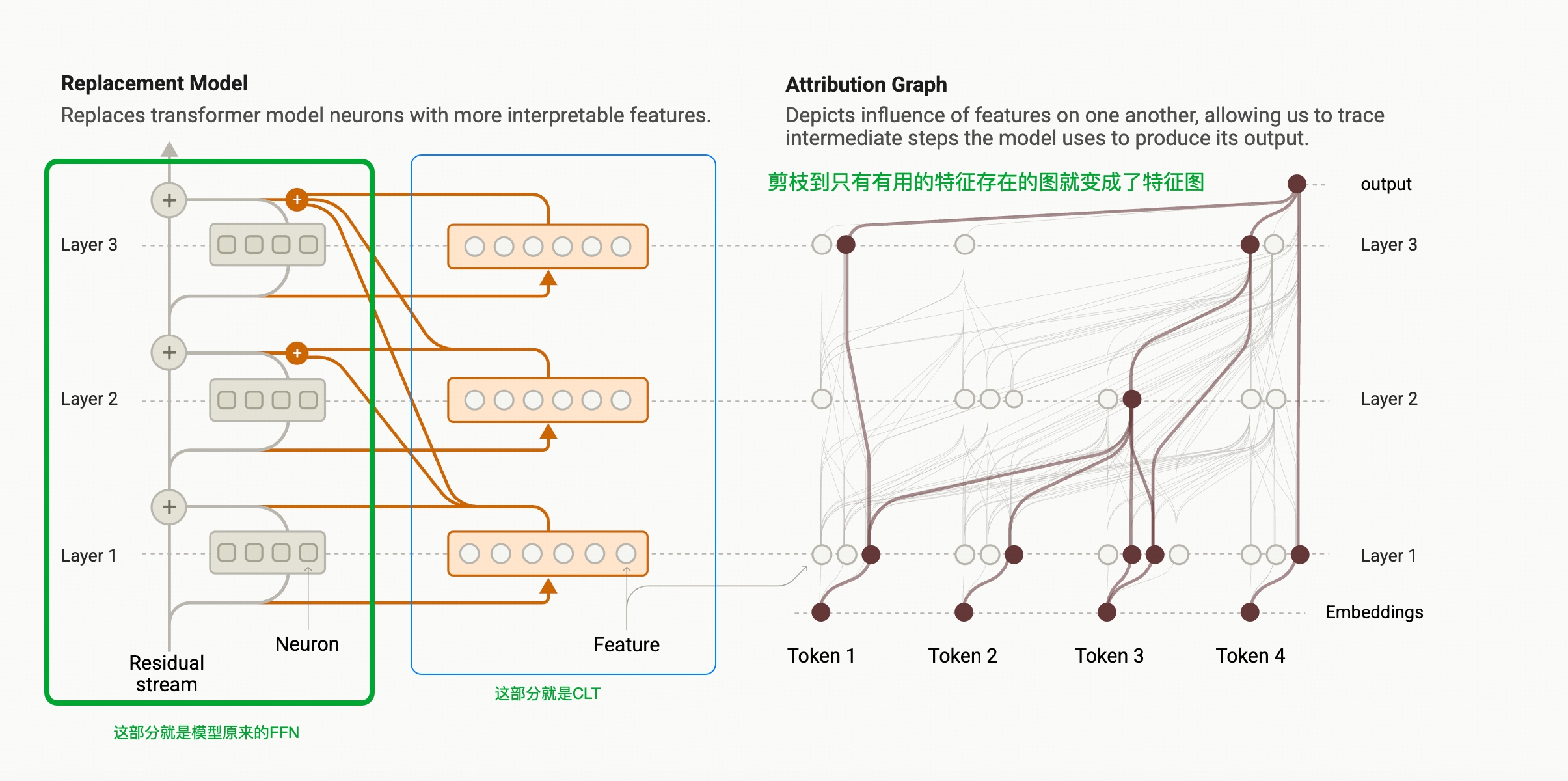
不同于SAE只关心和重建单层的MLP输出,CLT为了分析特征的传递特性,考虑了一种模型解释工作中 <解释模型>的终极形态——直接替换原模型(也就是上图右侧的图像的样子),所以CLT在Transcoder的结构上做了一点点改造,其核心构造见下面公式。

图上的公式中 l l l代表CLT的层数, a a a代表CLT的特征层,即从原模型attention output转化成的稀疏编码向量, W e n c l W^l_{enc} Wencl代表的是CLT encode到稀疏特征 a a a的权重矩阵, W d e c l ′ → l W^{l^{\prime}\to l}_{dec} Wdecl′→l 指的是用来解码–>从 l l l层前面的某一层 l ′ l^{\prime} l′这层 传递过来的 a ′ a^{\prime} a′ 的权重。简而言之, y ^ l \hat{y}^l y^l 是前面所有特征一起解码的结果。
CLT相对于Transcoder的主要改造有两个
- 使用了JumpRelu 这个函数在刺激稀疏表征表达的时候效果更好(具体见:Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders 我下面把那个论文里的核心图贴过来)
- causal decode:所有前面已经算过的层的特征a都会参与下一层的decode(也就是还原的步骤的计算) ,也就是计算 y ^ l \hat{y}^l y^l的公式中展示的那样。
- 正则项:CLT使用的正则项是

使用了 t a n h ( c ∗ x ) tanh(c*x) tanh(c∗x)的意思就是希望把这里的 x x x压到 [ − 1 c , 1 c ] [-\frac{1}{c},\frac{1}{c}] [−c1,c1]之间。
CLT的其他实现细节
JumpReLU
↓ 这个图是Google团队JumpReLU SAE论文里的图,意思是这样的:通常,我们用ReLU激活函数来过滤掉大部分负值(从左一图到左二图),但是还是有一些正值虽然是正的,但并不高(左二图中的蓝色柱子)被放过了。虽然我们可以通过调整偏置(bias)来把这些不高的正值拉回到负值,但这样一来,原本我们想保留的那些高的正值(左二中的红色柱子)也会被降低成左三那样。最理想的做法是,在ReLU函数的基础上再加一个阈值,不到这个阈值的值全部变成0,达到阈值的值保持原样。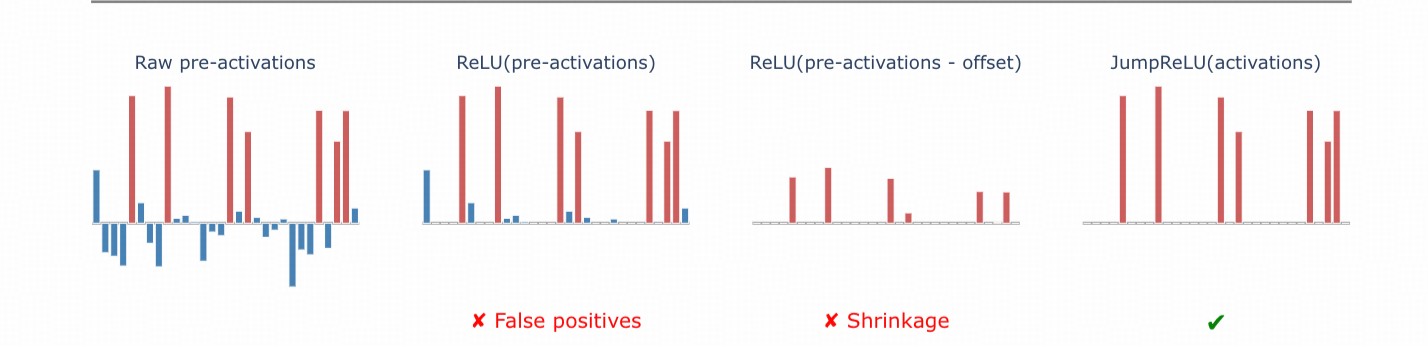
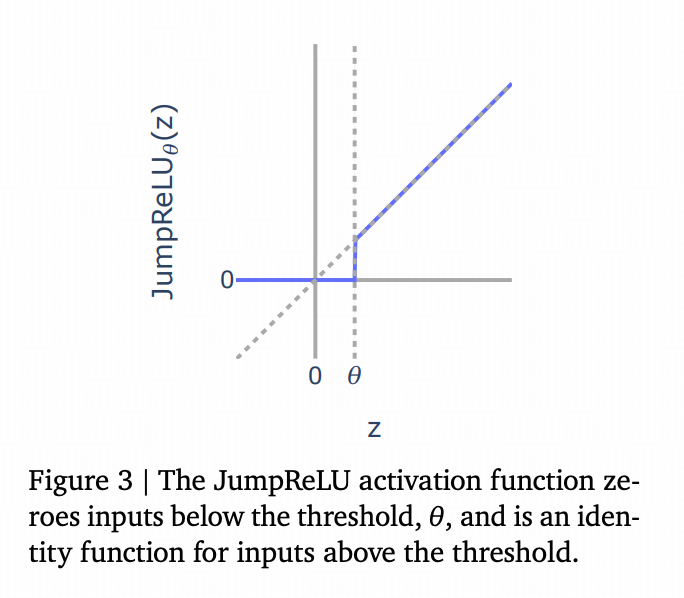
所以JumpReLU的函数图就长↓下面这样↓(需要复现Claude这个CLT的老哥得看一下他的附录,他这里再训练的时候用的初始,bandwidth等等参数都跟Google的原作有一点差别)
为了减少误差累积,引入了误差修正项
所谓的误差修正项,就是每一层的CLT解码出来的 y ^ \hat{y} y^和原模型中真实的 y y y(也就是原始大语言模型这一层的真实输出)之间的差值。因为稀疏模型本身舍弃了MLP自带的特征堆叠能力,同时无论是SAE、Transcoder还是Claude团队使用的CLT,其实研究的都是transformer的残差的前向路径,这里并没有对Attention机制和Transformer的FFN层的激活函数进行等效建模,所以不可避免地会带来一些误差。作者直接把自己复原的 y ^ \hat{y} y^和误差修正项加起来传递给CLT的下一层解码,以减少这种误差累积的影响。
CLT特征和<语义>关联
知道每层CLT的<哪些>特征会在<什么>上下文中激活就等于有了解释工具了吗?
是也不是。是的原因是,“解释”的意思在这个场景下确实是:
CLT的<哪些>特征会在<什么>语义下激活
不是的原因是,这个语义解释其实并不是基于单个样本的结论,而是基于大量样本的归因分析之后的结论。大部分同类工作到这一步, 都会启用<人>,而不是机器。因为这类工作的归因分析一般要做两件事,一个是要记录触发规律,另一个是要做扰动实验来固化影响传递路径。Claude的团队其实也差不多,他们虽然也启用了LLM但是让LLM来梳理规律并没有他们希望的那么顺。最后还是用了人来做这件事。
正片开始
第一个结论:证实了LLM的内部像一个条件概率图一样的知识推理结构
但要先声明一点,知识推理,指的是原先在知识图谱上常用的基于知识关联的推理↓
即“售卖苹果手机的公司的CEO是蒂姆库克”这种,先从知识图谱上查找到“出售卖苹果手机的公司”是苹果公司—>再查找到“苹果公司的CEO是蒂姆库克”
而不是我们最近一年内常探讨的数学推理。(当然,如果深究这两种推理是否本质是一个,那就是另外一个话题了。)
而作者举的例子跟我这个差不多↓↓
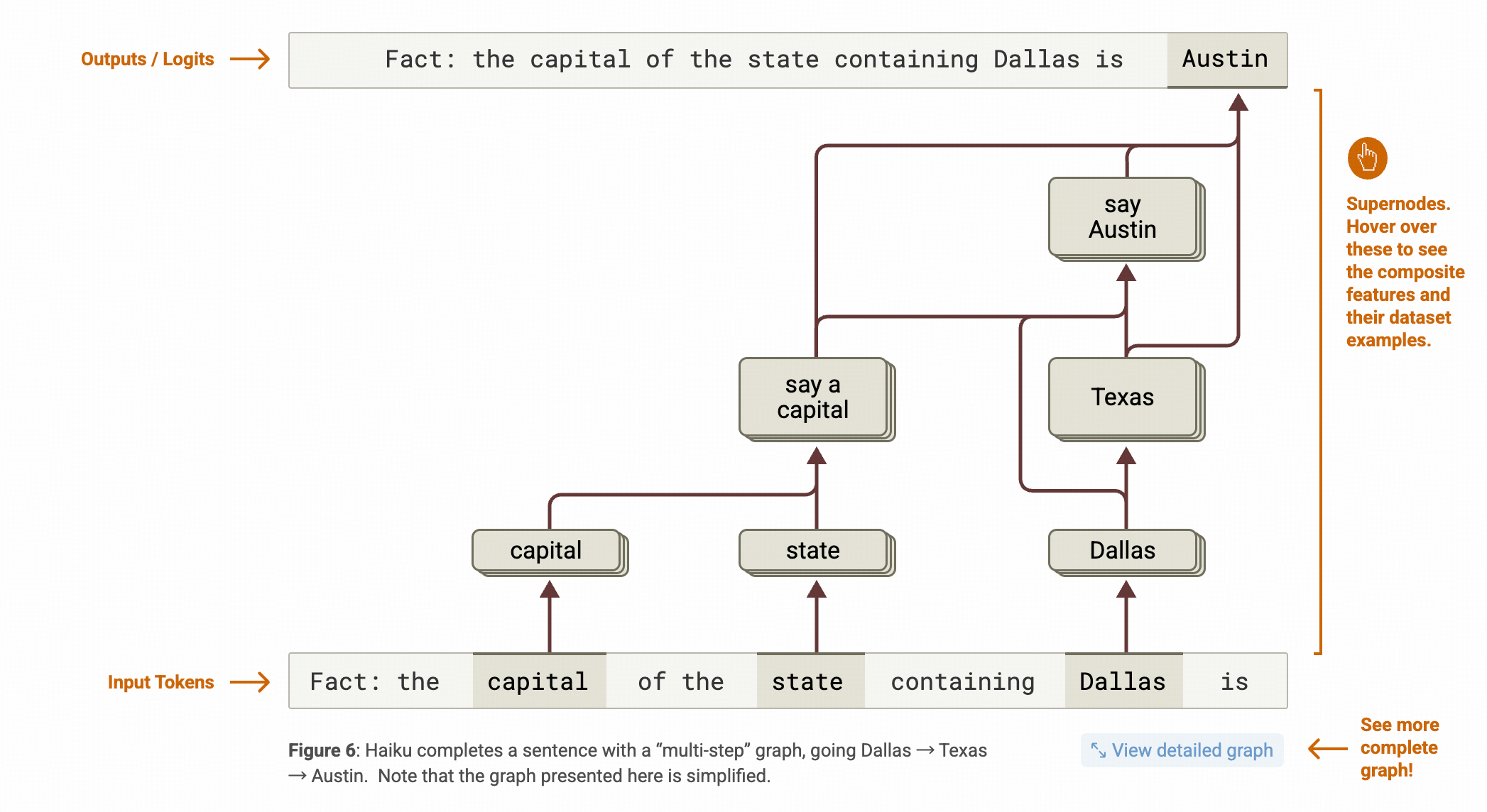
作者拿来举例子的是这样一个句子:
“达拉斯”所在的“州”的“首府”是
然后观察is这个词在运算的过程中,CLT的哪些特征被点亮,而这些特征又分别对应着哪些提前分析过已知的语义。
作者得到了以下结论
- 达拉斯这个token会点亮很多跟德州相关的特征
这个情况其实在Physics of LLM这篇文章中也有提及,很多实体的关系和实体的属性特征都是储存在实体token上的,通过FFN层就会被拉起来,像KV对一样。
- capital 和 state 两个词的中间融合特征会让模型有欲望吐出大量不同首都的名称
这里强烈建议点进原文看一眼,他say a captial这个feature组对应了若干会吐出不同地区capital的feature。
- Austin的生成就是由Dallas把Texas拉起来,capital and state 把capital这个概念拉起来,最后被模型找到的概率最高的token。
如果把作者的这张图上下颠倒 ,就非常像一个条件概率图了。不知道和国内一些研究神经符号推理的团队思路像不像?
和很多知识编辑的研究思路类似,Claude团队验证CLT特征可靠性(其实也顺带验证了非常像因果图这点)的终极扰动实验就是把中间对应某个语义的特征人为的替换成另外一个语义对应的CLT特征,来观察模型的生成是否收到影响。而这个实验的结果就如下图:
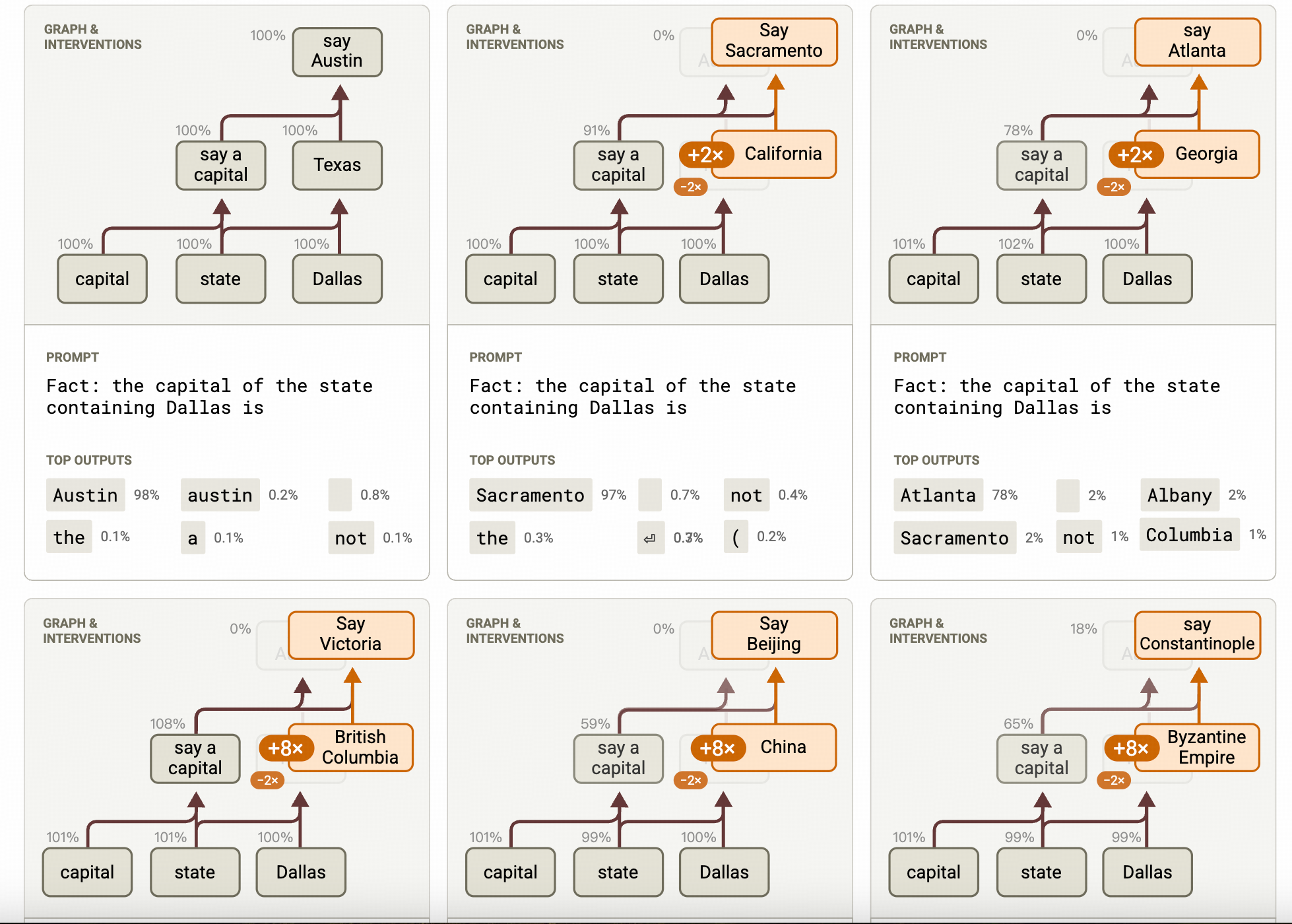
即,把中间层中代表的Texas的特征替换成已经知道的代表<中国>的特征,模型就会生成跟北京最为相关的中间层特征,模型也就会生成北京。
在这一刻 Transformer中常用的causal才能和我们中文认知中的因果对应上。
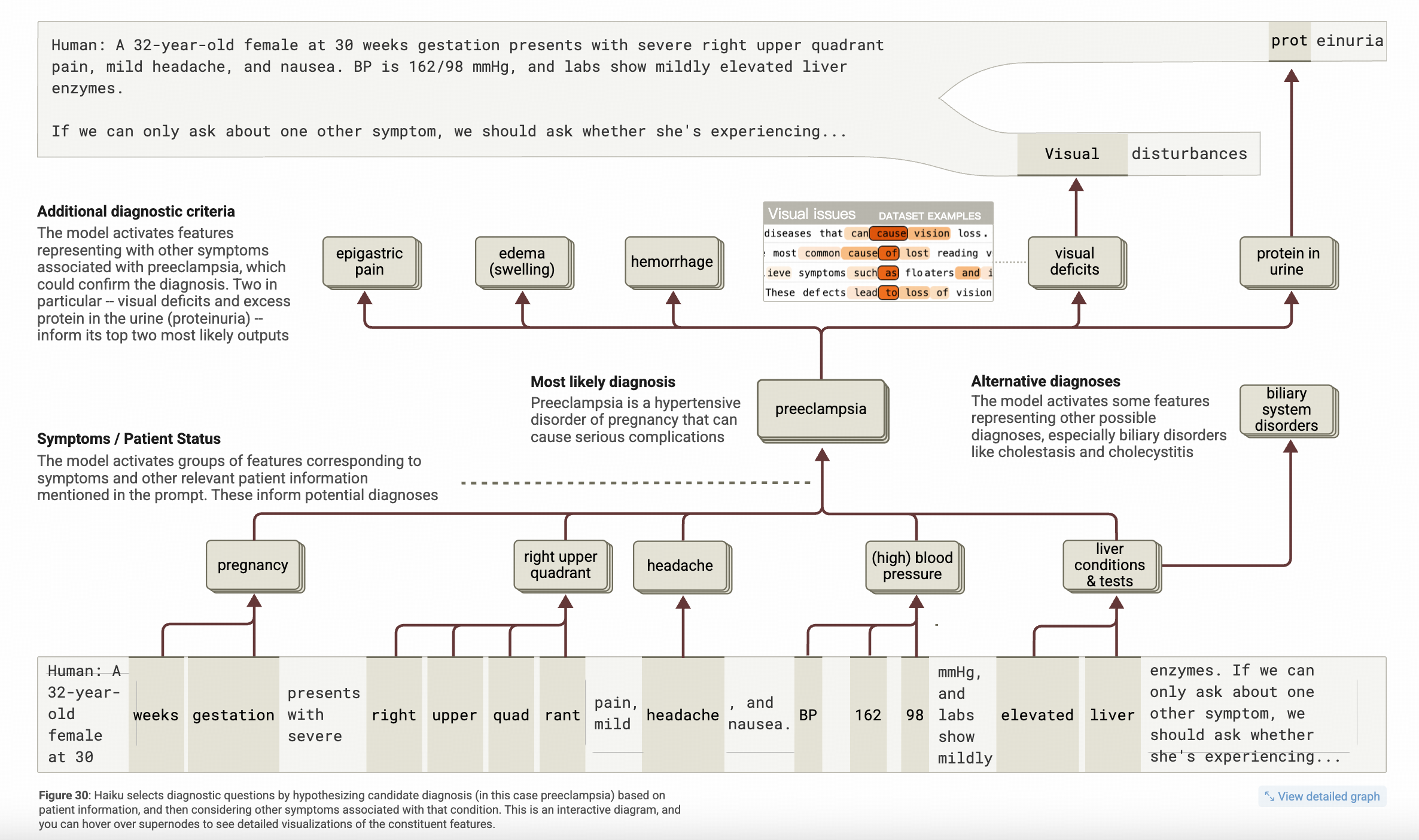
拓展:模型在医疗的case上呈现的模式也呈现了条件概率图的模式
第二个结论: 模型会在生成第一个词之前对要生成的一句做规划
作者研究这个内容的方法是让模型写诗。这确实还是挺巧的一个思路,因为如果使用常规的提问,又会落到知识存储相关的问题上,很难剥离这方面能力的影响。
如↓下图↓所示,作者让模型接着一个已经写好的诗的开头“He saw a carrot and had to grab it” 然后观察到,在下一行的起始token“换行符”这里,rabbit和habbit这两个与上文相关且韵脚“it”一致的词相关的feature在CLT内部被点亮了。
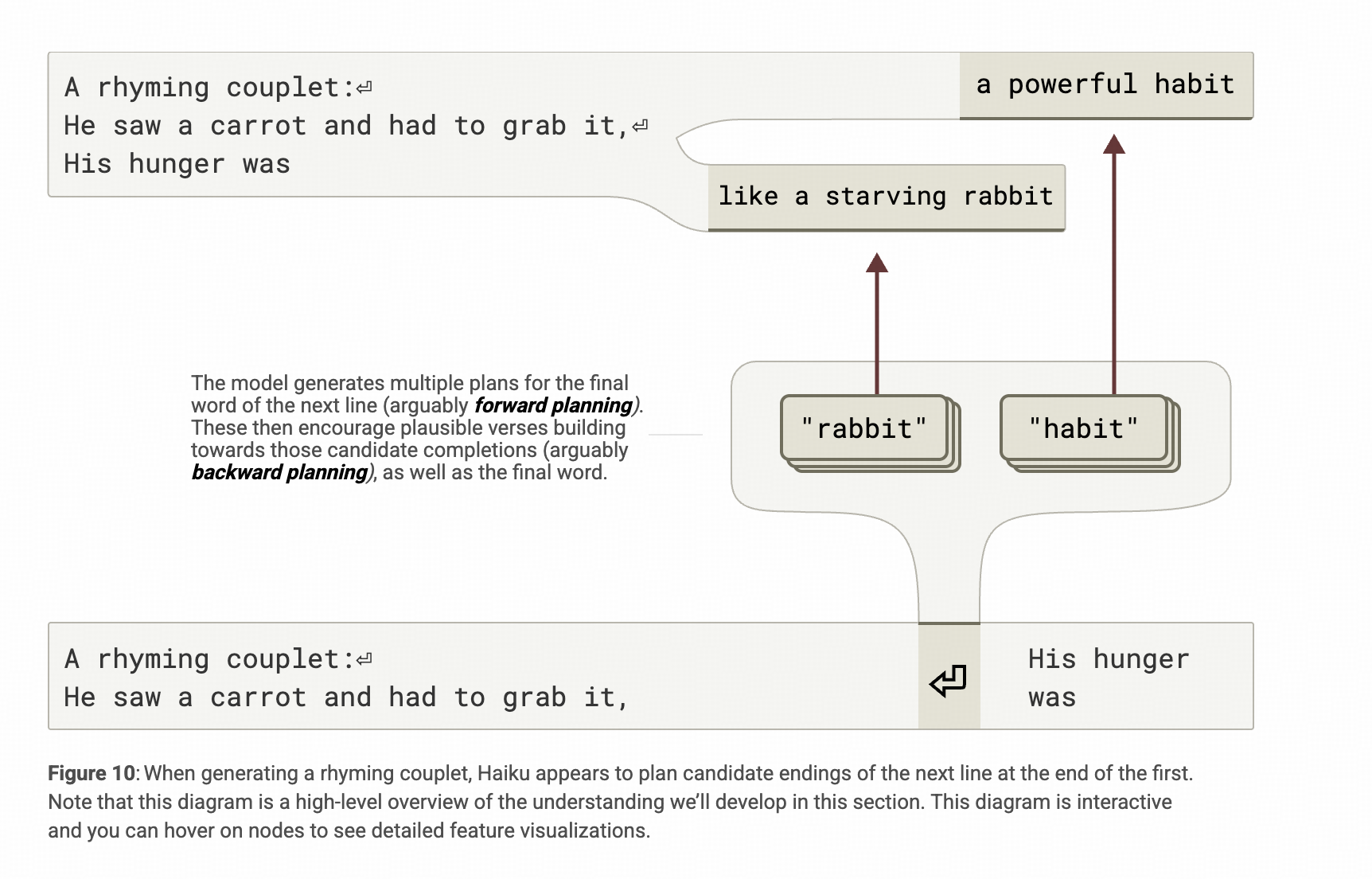
具体而言,模型先是激活了和‘it/et/eet’读音相关的feature,这个feature又找到最接近的rabbit和habit这两个词相关的feature。
而且,经过分析,这个规划是仅在生成前的这一个token上完成的。