CIFAR-10图像分类学习笔记(一)
pytorch
解决视觉分类
图像分类网络模型
微观方面
分类网络基本结构:
01数据加载模块(对训练的数据进行加载【读取训练数据的过程】)
02数据预处理(数据增强)->将处理好的数据丢到CNN卷积神经网络中(提取卷积特征)->将提取出来的卷积特征转化为N维向量(N维向量就是要表示的图像分类的N个类别)->LOSS函数计算当前的损失,利用当前损失进行反向传播,对网络参数进行调整->利用N维向量的概率分布计算出当前的训练集的准确率
03定义网络的优化器:梯度下降算法(对网络参数进行迭代)->多维迭代模型会收敛到LOSS非常小或者不再变化->拿到一组最优的神经网络参数解->根据构建的神经网络对实际的输入数据进行推理
训练过程vs推理过程
训练的过程:对神经网络中的参数进行求解
推理的过程:已知网络结构,并通过训练过程计算得到网络参数->输入x利用神经网络结构及已知参数计算出网络的结果
01数据加载模块
使用pytorch中的torchvision.datasets中的数据集(封装好的公开的数据集)
torch.utils.data下的Dataset,detaLoader这俩类完成自定义数据集的训练
首先要知道数据的排列方式是RGB(三个维度上的数据)还是BGR
若是JPEG编码的数据需要用解码的方式获取RGB这三个通道
02数据增强
原因背景;
神经网络中网络的参数十分庞大,但是样本数量有限,可能因为样本数量不够导致过拟合的现象出现),模型的泛化能力不强(训练结果在训练集上效果非常好,但是在测试集效果不好)
措施:
对已有的数据进行数据扩充,例如:随机翻转、旋转、修改图像的亮度、对比度、饱和度,不同颜色属性完成对数据的扩充
什么是过拟合?简单说就是为了得到一致的结果而使得假设过于的严格,使得有限的样本数据全部落在人为干预拟定曲线上,但实际上非样本数据(即在训练集外的数据)有可能根本不在这个曲线上
实现:
pytorch下的torchvision的transforms类进行数据增强的实现
03网络结构
搭建卷积神经网络
利用四个结构分别搭建四种网络模型来实现
04类别概率分布
将N为向量转换为对应的N个类别的方法
1)FC
2)conv卷积
3)pool
3分类
[1,0,0] [0,1,0] [0,0,1]这种从标签转换成向量的方式叫one-hot编码(独热码)
有的图片既可能属于类别1也可能属于类别2,但这种三分类很hard要不是1要不就是0,因此采用label smoothing定义:[0.9,0.05,0.05]
05分类任务中的评价指标
正确率、错误率、灵敏度、特效度、精度、召回率、PR曲线(x-recall召回率,y-precision)、ROC曲线、AUC曲线(对应ROC曲线的面积)
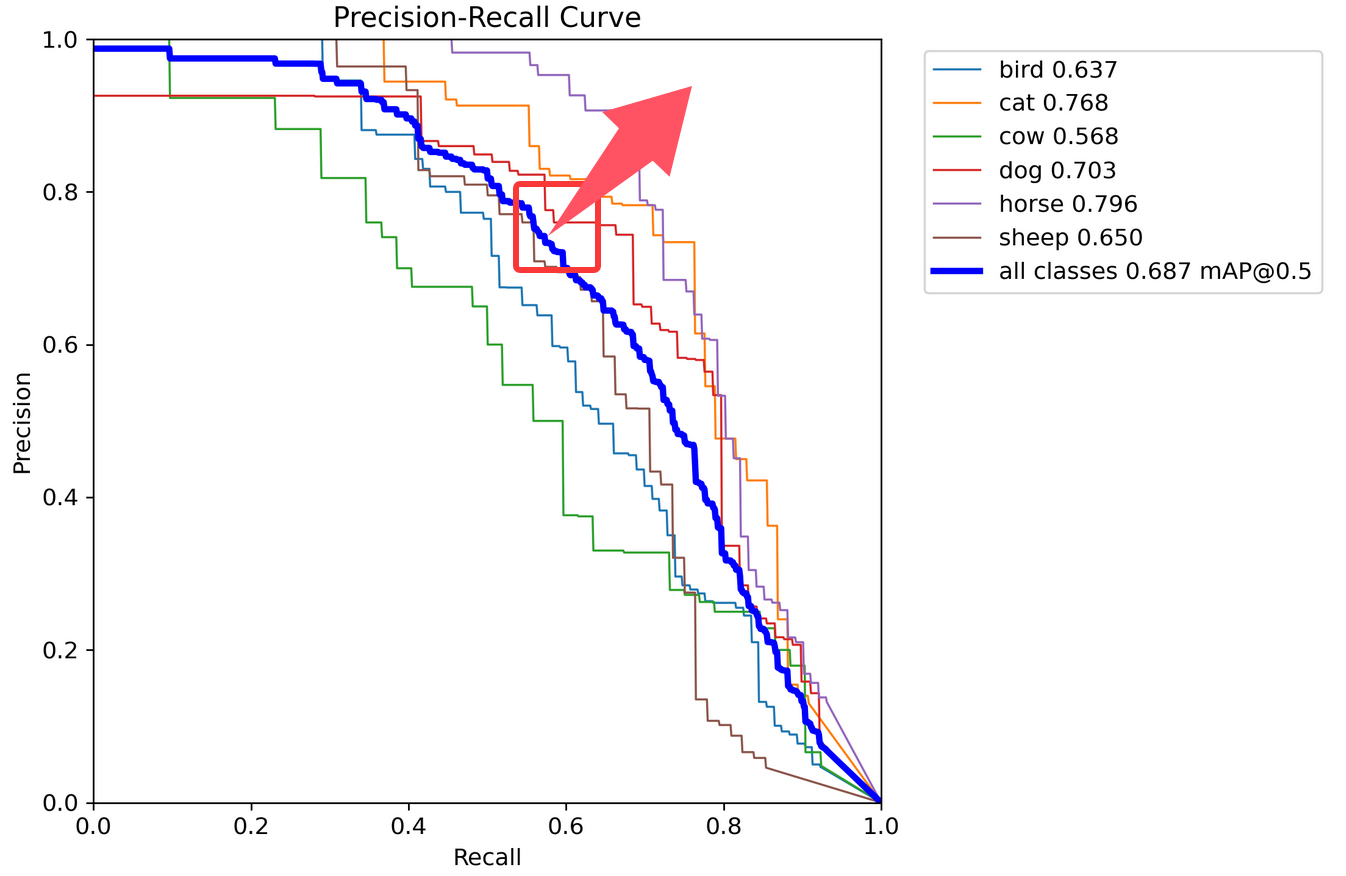
PR曲线:
要做到的就是从上到下的弯曲点尽可能的在俩坐标轴方向值都大如下图箭头所示,保证在高召回率的情况下精度依然高
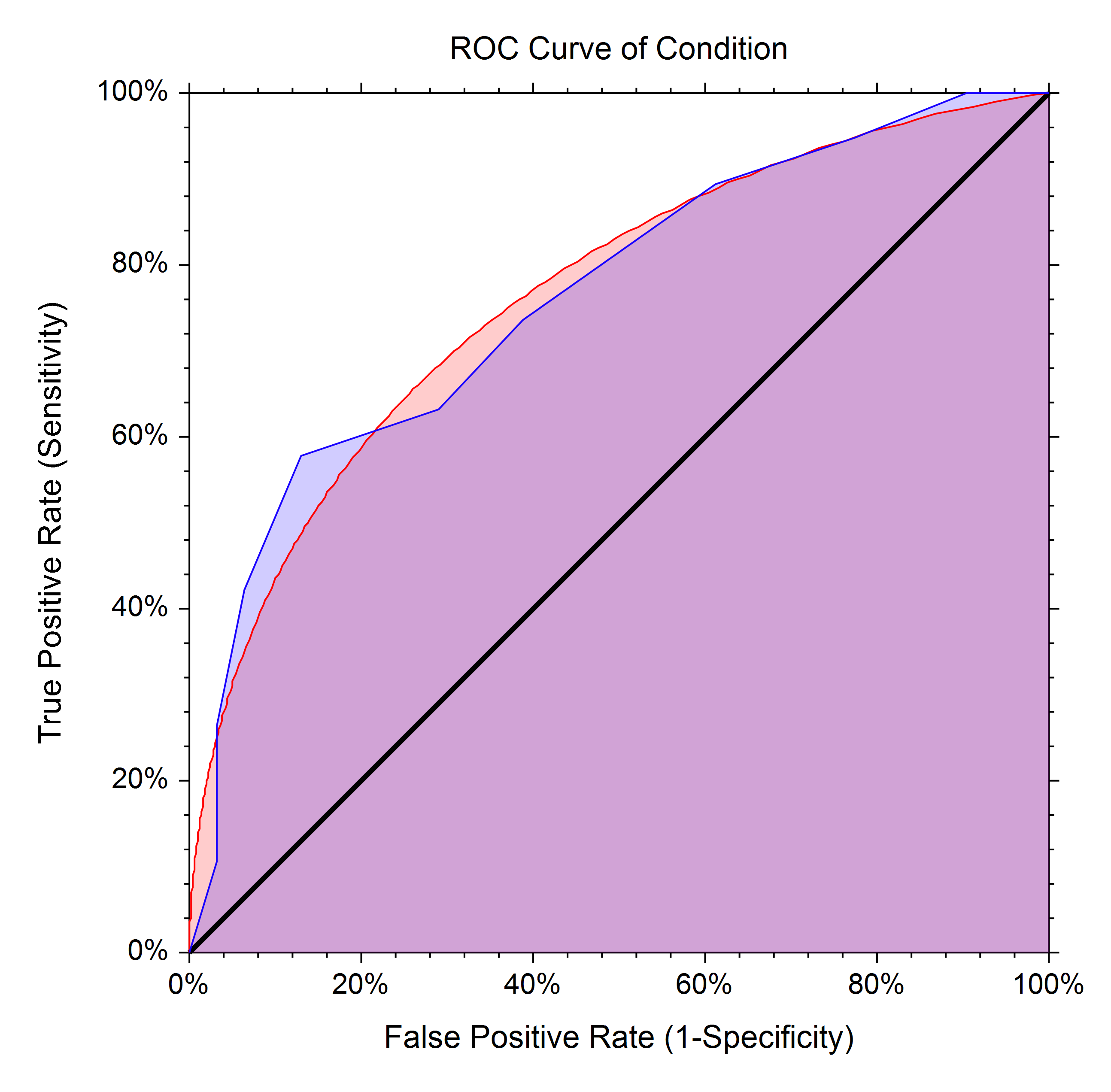
ROC曲线:
ROC曲线凸的地方越靠近1,模型的效果就越好,即下面图阴影部分面积越大越好,右上角线越靠近100%则模型效果越好
06优化器选择torch.optim.Adam
学习率初始值:lr=0.001
学习率衰减的方法采用指数衰减:torch.optim.lr_scheduler.ExponentialLR