spark—kafka
消息队列与Kafka介绍
消息队列模式:
点对点模式和发布订阅模式。Kafka主要使用发布订阅模式。
Kafka角色:
包括broker、topic、分区、生产者、消费者、消费者组、副本、leader和follower
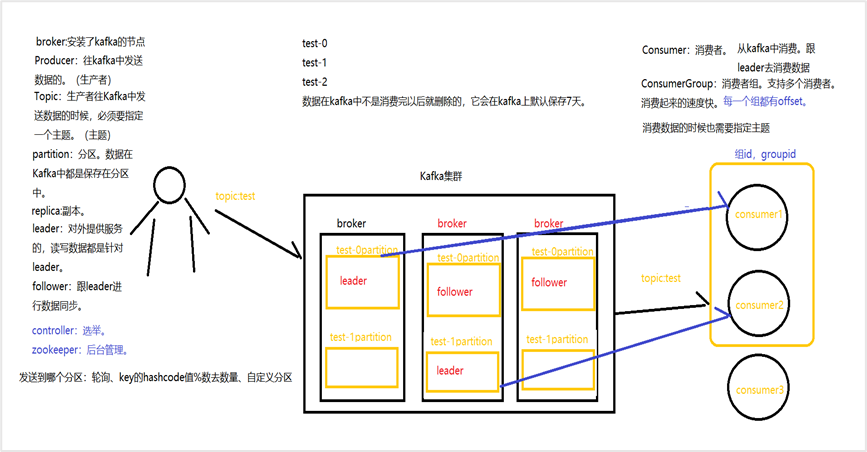
| 术语 | 解释 |
| Broker | 安装了kafka的节点 |
|
|
|
| Topic
| 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处),发送消息必须有主题。 |
| Partition | Partition是物理上的概念,每个Topic包含一个或多个Partition. |
| Producer | 负责发布消息到Kafka broker |
| Consumer | 消息消费者,向Kafka broker读取消息的客户端 |
| Consumer Group | 每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group) 当consumer去消费数据的时候,会有一个偏移量(offset),一个分区的数据,一个consumer只能消费一次。 |
| replica | partition 的副本,保障 partition 的高可用 |
| leader | replica 中的一个角色, producer 和 consumer 只跟 leader 交互 |
| follower | replica 中的一个角色,从 leader 中复制数据,数据备份,如果leader挂掉,顶替leader的工作 |
| controller | Kafka 集群中的其中一个服务器,用来进行 leader election 以及各种 failover |
Kafka特性:
高吞吐量低延迟、可扩展性、持久性和可靠性、容错性、高并发性。
Kafka安装步骤
环境依赖:需要先安装JDK和Zookeeper。
版本一致性:Kafka和Scala版本需要一致。
安装包上传与解压:上传安装包到指定目录并解压。
配置修改:修改配置文件中的ID、主机名、日志路径、分区数量和Zookeeper集群端口号。
分发安装包:将安装包分发到其他节点并修改相应的配置。
启动Kafka集群
启动命令:使用后台守护进程启动Kafka集群。
环境变量配置:添加Kafka的环境变量并修改脚本文件权限。
一键启动脚本:使用脚本文件一键启动和关闭Kafka集群。
Spark与YARN环境安装
解压缩与重命名:对Spark进行解压缩和重命名。
配置文件修改:修改配置文件,添加Java Home和YARN相关变量。
分发与启动:分发配置文件到其他节点,启动HDFS和YARN集群,提交测试应用。
Spark-yarn

修改hadoop配置文件/opt/software/hadoop/hadoop-2.9.2/etc/hadoop/yarn-site.xml,并分发给其他节点。
是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是 true<property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是 true<property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value></property>
返回到spark-yarn目录,修改conf/spark-env.sh,添加 JAVA_HOME 和 YARN_CONF_DIR 配置。
mv spark-env.sh.template spark-env.shvi spark-env.sh

启动HDFS以及Yarn集群提交测试应用bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master yarn \--deploy-mode cluster \./examples/jars/spark-examples_2.12-3.0.0.jar \
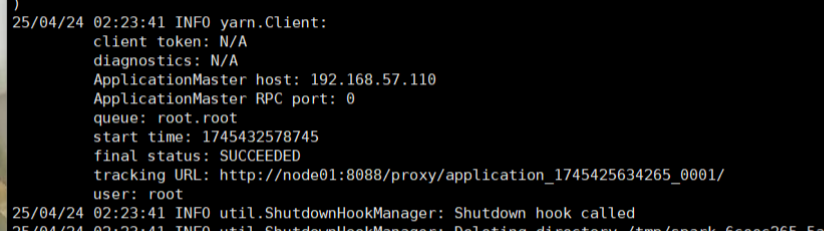
有SUCCEEDED就是成功了