Apache Flink 深度解析:流处理引擎的核心原理与生产实践指南
Apache Flink 深度解析:流处理引擎的核心原理与生产实践指南
引言:实时计算的范式革命
2023年双十一期间,某头部电商平台基于Flink构建的实时风控系统成功拦截了每秒超过120万次的异常交易请求。这背后是Apache Flink作为第四代计算引擎的强大能力体现。本文将深入剖析Flink的架构原理,并通过完整实战案例展示其核心功能实现。
一、核心架构与原理剖析
1.1 流式计算范式演进
各代计算引擎对比:
| Storm | Spark Streaming | Flink | |
|---|---|---|---|
| 延迟 | 毫秒级 | 秒级 | 亚秒级 |
| 吞吐量 | 低(万级/秒) | 高(百万级/秒) | 超高(亿级/秒) |
| 状态管理 | 无原生支持 | 微批处理 | 原生精确状态 |
| 语义保障 | At-least-once | Exactly-once | Exactly-once |
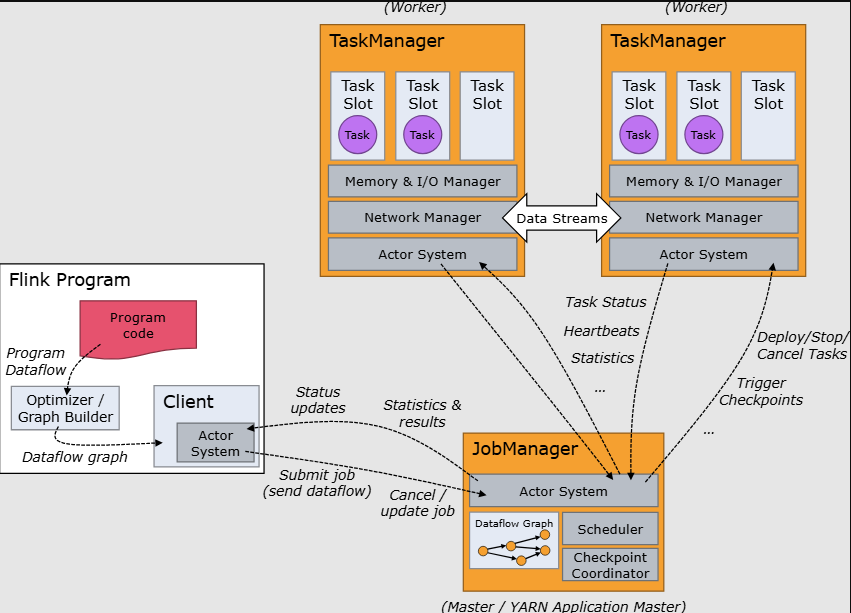
1.2 运行时架构设计
组件交互关系:
[Client] --> [JobManager] <--> [ResourceManager]/|\ /|\| || [CheckpointCoordinator]|\|/
[TaskManager] <--> [TaskManager]
核心模块职责:
- JobManager:作业调度与协调
- TaskManager:任务执行与资源管理
- ResourceManager:集群资源分配
- Dispatcher:REST接口服务
1.3 流处理核心机制
时间语义对比:
// EventTime处理示例
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);dataStream.assignTimestampsAndWatermarks(WatermarkStrategy.<OrderEvent>forBoundedOutOfOrderness(Duration.ofSeconds(5)).keyBy(event -> event.getUserId()).window(TumblingEventTimeWindows.of(Time.minutes(1))).aggregate(new CountAggregate());
状态管理实现:
class FraudDetector extends KeyedProcessFunction[Long, Transaction, Alert] {private var flagState: ValueState[Boolean] = _private var timerState: ValueState[Long] = _override def open(parameters: Configuration): Unit = {flagState = getRuntimeContext.getState(new ValueStateDescriptor[Boolean]("flag", Types.BOOLEAN))timerState = getRuntimeContext.getState(new ValueStateDescriptor[Long]("timer", Types.LONG))}override def processElement(transaction: Transaction,ctx: KeyedProcessFunction[Long, Transaction, Alert]#Context,out: Collector[Alert]): Unit = {// 状态操作逻辑}
}
二、生产环境部署方案
2.1 集群部署模式
部署方式对比:
| 模式 | 适用场景 | 资源管理 | 特点 |
|---|---|---|---|
| Standalone | 开发测试 | 静态分配 | 简单快速 |
| YARN | 企业级生产 | 动态资源 | 资源隔离完善 |
| Kubernetes | 云原生环境 | 弹性伸缩 | 自动化部署 |
| Mesos | 混合集群 | 细粒度调度 | 逐渐淘汰 |
K8s部署示例:
apiVersion: apps/v1
kind: Deployment
metadata:name: flink-taskmanager
spec:replicas: 5selector:matchLabels:app: flinkcomponent: taskmanagertemplate:metadata:labels:app: flinkcomponent: taskmanagerspec:containers:- name: taskmanagerimage: flink:1.16.0args: ["taskmanager"]resources:limits:memory: "4096Mi"cpu: "2"ports:- containerPort: 6122
2.2 关键配置参数
# flink-conf.yaml
taskmanager.numberOfTaskSlots: 4
parallelism.default: 8
state.backend: rocksdb
state.checkpoints.dir: hdfs:///flink/checkpoints
execution.checkpointing.interval: 1min
三、核心API实战解析
3.1 DataStream API
实时ETL处理示例:
DataStream<Event> input = env.addSource(new KafkaSource<>()).name("kafka-source");DataStream<CleanedEvent> processed = input.filter(event -> event.isValid()).map(event -> enrich(event)).keyBy(event -> event.getDeviceId()).window(SlidingEventTimeWindows.of(Time.minutes(5), Time.seconds(30))).aggregate(new CountAggregator()).name("processing-op");processed.addSink(new ElasticsearchSink<>()).name("es-sink");
3.2 Table API & SQL
-- 实时TopN分析
SELECT *
FROM (SELECT *,ROW_NUMBER() OVER (PARTITION BY window_start, category ORDER BY sales DESC) AS row_numFROM (SELECT TUMBLE_START(event_time, INTERVAL '1' HOUR) AS window_start,category,SUM(amount) AS salesFROM ordersGROUP BY TUMBLE(event_time, INTERVAL '1' HOUR),category)
)
WHERE row_num <= 5;
3.3 状态后端选型
| 后端类型 | 特点 | 适用场景 |
|---|---|---|
| MemoryState | 全内存操作,速度快 | 小状态本地测试 |
| FsState | 文件系统持久化 | 中等规模状态 |
| RocksDB | 磁盘存储,支持超大状态 | 生产环境通用方案 |
| 自定义实现 | 对接外部存储系统 | 特殊存储需求 |
四、生产环境调优策略
4.1 性能调优矩阵
| 优化方向 | 具体措施 | 预期收益 |
|---|---|---|
| 并行度 | 设置合理的Task Slot数量 | 提升20-40%吞吐量 |
| 序列化 | 使用Flink Native序列化 | 减少30%CPU消耗 |
| 状态管理 | 配置RocksDB参数优化 | 降低50%IO延迟 |
| 网络优化 | 调整buffer超时和数量 | 减少20%网络开销 |
| Checkpoint | 调整间隔和并行存储 | 提升10倍恢复速度 |
RocksDB配置示例:
RocksDBStateBackend backend = new RocksDBStateBackend("hdfs://checkpoints");
backend.setPredefinedOptions(PredefinedOptions.SPINNING_DISK_OPTIMIZED);
backend.setNumberOfTransferThreads(4);
env.setStateBackend(backend);
4.2 容错与恢复
Checkpoint机制:
端到端精确一次保障:
[Kafka Source] -- Exactly-once --> [Flink Processing] -- Exactly-once --> [HBase Sink]
五、典型应用场景实践
5.1 实时数仓建设
-- 流表Join维度表
CREATE TABLE orders (order_id STRING,product_id INT,order_time TIMESTAMP(3),WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (...);CREATE TABLE products (product_id INT,category STRING,price DECIMAL(10,2)
) WITH (...);SELECT o.order_id,p.category,SUM(p.price) AS total
FROM orders o
JOIN products FOR SYSTEM_TIME AS OF o.order_time AS p
ON o.product_id = p.product_id
GROUP BY p.category;
5.2 复杂事件处理
Pattern<Event, ?> pattern = Pattern.<Event>begin("start").where(new SimpleCondition<Event>() {@Overridepublic boolean filter(Event event) {return event.getType().equals("login");}}).next("failure").where(new SimpleCondition<Event>() {@Overridepublic boolean filter(Event event) {return event.getType().equals("error");}}).times(3).within(Time.minutes(5));CEP.pattern(input, pattern).select(new PatternSelectFunction<Event, Alert>() {@Overridepublic Alert select(Map<String, List<Event>> pattern) {return new Alert("连续三次登录失败");}});
六、运维监控体系
6.1 监控指标看板
关键监控维度:
- 吞吐量:recordsIn/recordsOut
- 延迟:checkpointDuration/processLatency
- 资源:CPU/Memory/Network
- 背压:isBackPressured指标
- Watermark:事件时间延迟
6.2 常见故障排查
任务反压诊断流程:
- 检查Web UI的反压监控
- 分析各个算子的处理延迟
- 查看线程堆栈定位瓶颈点
- 调整并行度或优化代码逻辑
- 验证网络带宽和反压配置
结语:流处理新纪元
某国际支付平台通过Flink实现全球交易的实时风控,将欺诈识别响应时间从分钟级压缩到毫秒级。生产环境建议:
- 使用Savepoint实现版本热切换
- 配置State TTL自动清理过期状态
- 采用Kerberos进行安全认证
- 定期执行State Compaction优化存储
Flink正在向流批一体2.0架构演进,新增的自适应批处理和混合执行模式将进一步提升处理效率。建议关注:
- Unified Scheduler:统一流批调度
- Dynamic Scaling:实时弹性扩缩容
- Machine Learning:原生算法库集成
掌握Flink的核心原理与实践技能,将为企业构建实时智能系统提供坚实基础。建议通过Flink Web Dashboard持续观察作业运行状态,结合Prometheus+Grafana构建完整的监控告警体系。