新手村:过拟合(Overfitting)
新手村:过拟合(Overfitting)

什么是过拟合?
过拟合 是指机器学习模型在 训练数据 上表现优异(如高准确率或低误差),但在 新数据(如测试集或验证集)上表现显著下降的现象。
- 核心原因:模型过度学习了训练数据中的 噪声、细节或随机波动,而未能捕捉数据的 本质规律。
- 本质:模型的复杂度远超问题实际所需,导致对训练数据的“死记硬背”而非“理解”。
表现
过拟合的典型特征可以通过以下现象判断:
| 表现 | 具体描述 |
|---|---|
| 训练误差低,测试误差高 | 模型在训练集上误差极小(如准确率接近100%),但在未见过的测试集上误差显著增大。 |
| 模型过于复杂 | 模型包含过多参数(如高阶多项式、深度神经网络)、决策树分支过多或规则过于精细。 |
| 对噪声敏感 | 模型将训练数据中的噪声(如异常值、标签错误)当作重要特征进行学习。 |
| 泛化能力差 | 在新数据上无法稳定预测,甚至出现“离谱”结果(如图像分类中将背景噪声误认为关键特征)。 |
| 学习曲线异常 | 随着训练轮次增加,训练误差持续下降,而验证误差开始上升 |
示例:高阶多项式回归
假设真实数据由二次函数生成,但模型使用 9次多项式 拟合:
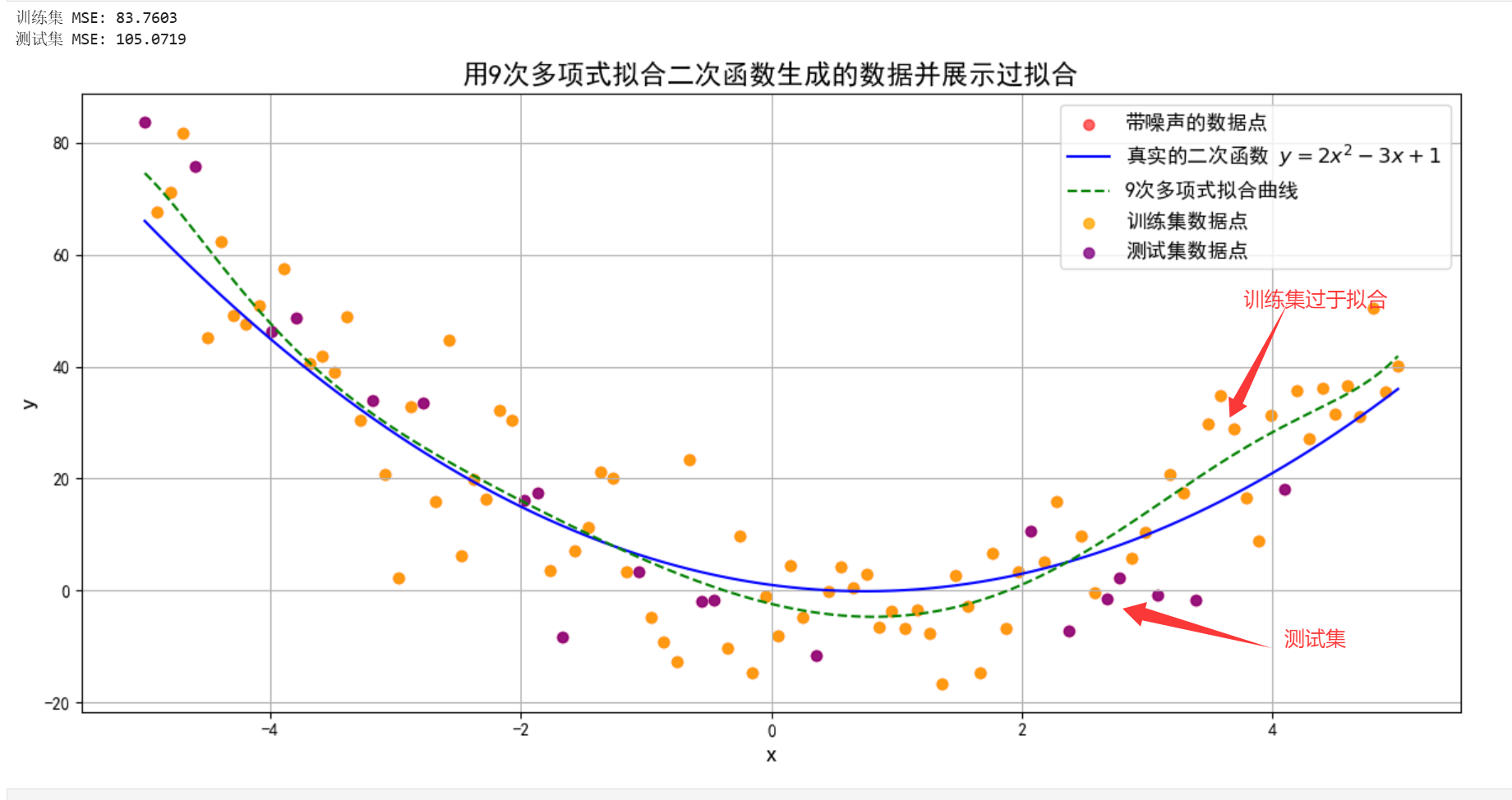
- 训练集:模型过于拟合训练集点的分布,导致在测试集上存在大的误差。
- 测试集:模型因过度拟合噪声,在新数据上剧烈震荡,误差极大
具体来说,二次函数可以表示为:
y = a x 2 + b x + c y = ax^2 + bx + c y=ax2+bx+c
而9次多项式可以表示为:
y = a 9 x 9 + a 8 x 8 + a 7 x 7 + a 6 x 6 + a 5 x 5 + a 4 x 4 + a 3 x 3 + a 2 x 2 + a 1 x + a 0 y = a_9x^9 + a_8x^8 + a_7x^7 + a_6x^6 + a_5x^5 + a_4x^4 + a_3x^3 + a_2x^2 + a_1x + a_0 y=a9x9+a8x8+a7x7+a6x6+a5x5+a4x4+a3x3+a2x2+a1x+a0
由于9次多项式有更多参数,它可以通过调整这些参数来完美地拟合训练数据中的每一个点,包括那些由随机噪声产生的点。
这导致模型在训练数据上表现得非常好,但在新的数据上,由于这些高次项无法泛化到真实的数据生成过程,模型的预测会变得非常不准确。
因此,虽然9次多项式在训练数据上可能有很低的误差,但在实际应用中,它可能无法做出准确的预测。
相比之下,一个二次函数模型虽然在训练数据上可能有更高的误差,但它更有可能在新的数据上做出准确的预测,因为它更接近真实的数据生成过程。
常见原因
过拟合的产生通常由以下因素导致:
(1) 模型复杂度过高
- 参数过多:模型包含大量参数(如深度神经网络、高阶多项式),能“记住”每个训练样本的细节。
- 决策树过度生长:决策树未限制深度或节点分裂条件,导致节点仅包含少数样本(如纯事件或非事件数据)。
- 神经网络训练过长:训练次数过多(Overtraining),模型过度拟合训练数据中的噪声。
(2) 数据问题
- 数据量不足:训练数据太少,无法代表真实分布,模型被迫学习噪声。
- 噪声或异常值干扰:数据中存在标签错误、测量误差或无关特征,模型误将其当作规律。
- 特征冗余:输入特征过多且相关性高(多重共线性),导致模型依赖无关特征。
(3) 训练过程不当
- 未使用正则化:缺乏L1/L2正则化、Dropout等约束,模型参数无限制增长。
- 未划分验证集:仅用训练集评估模型,无法及时发现过拟合。
- 交叉验证缺失:未通过K折交叉验证评估模型的泛化能力。
(4) 特征工程问题
- 特征选择不当:保留了与目标无关的特征,干扰模型学习。
- 特征构造过度:通过多项式扩展或复杂变换生成过多特征,增加模型复杂度。
典型案例场景
-
案例1:高阶多项式回归
- 场景:用9次多项式拟合二次函数生成的数据。
- 现象:
- 训练集误差极低,但测试集误差极高。
- 模型曲线剧烈波动,试图穿过每个训练点(如图2)。
-
案例2:决策树过拟合
- 场景:未限制深度的决策树分类。
- 现象:
- 树的叶子节点仅包含少量样本(如纯类别)。
- 新数据若与训练样本稍有差异,预测结果即出错。
-
案例3:神经网络过拟合
- 场景:用小型数据集训练大型神经网络(如CIFAR-10的子集)。
- 现象:
- 在训练集上准确率100%,但测试集仅50%。
- 模型对输入的微小扰动(如噪声)极度敏感。
总结
| 维度 | 过拟合 |
|---|---|
| 定义 | 模型在训练集表现好,新数据表现差,因过度学习噪声和细节。 |
| 核心原因 | 1 模型复杂度过高 2 数据不足/噪声 3 训练过程不当。 |
| 关键表现 | 训练误差低、测试误差高,模型复杂度远超问题需求。 |
6. 延伸思考
- 如何区分过拟合与欠拟合:
- 过拟合:训练误差低,测试误差高(模型太复杂)。
- 欠拟合:训练和测试误差均高(模型太简单)。
- 过拟合的解决方法:
正则化(L1/L2、Dropout)、简化模型、增加数据、交叉验证等
参考
9次多项式代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split# 生成二次函数数据
np.random.seed(0) # 设置随机种子以保证结果可重复
a, b, c = 2, -3, 1 # 二次函数的系数
x = np.linspace(-5, 5, 100).reshape(-1, 1) # x值范围从-5到5,共100个点
y_true = a * x**2 + b * x + c # 真实的二次函数值
noise = np.random.normal(0, 10, size=y_true.shape) # 添加噪声
y_noisy = y_true + noise # 带噪声的数据# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y_noisy, test_size=0.2, random_state=42)# 使用9次多项式拟合数据
poly_features = PolynomialFeatures(degree=9, include_bias=False)
X_train_poly = poly_features.fit_transform(x_train)
X_test_poly = poly_features.transform(x_test)model = LinearRegression()
model.fit(X_train_poly, y_train)# 生成拟合曲线的y值
x_fit = np.linspace(-5, 5, 400).reshape(-1, 1) # 更细密的x值范围用于平滑曲线
X_fit_poly = poly_features.transform(x_fit)
y_fit = model.predict(X_fit_poly)# 计算训练集和测试集上的均方误差(MSE)
train_mse = np.mean((model.predict(X_train_poly) - y_train)**2)
test_mse = np.mean((model.predict(X_test_poly) - y_test)**2)print(f"训练集 MSE: {train_mse:.4f}")
print(f"测试集 MSE: {test_mse:.4f}")# 绘制原始数据和拟合曲线
plt.figure(figsize=(12, 6))# 绘制带噪声的数据点
plt.scatter(x, y_noisy, label='带噪声的数据点', color='red', alpha=0.6)# 绘制真实的二次函数曲线
plt.plot(x, y_true, label='真实的二次函数 $y = 2x^2 - 3x + 1$', color='blue')# 绘制9次多项式拟合曲线
plt.plot(x_fit, y_fit, label='9次多项式拟合曲线', color='green', linestyle='--')# 绘制训练集数据点
plt.scatter(x_train, y_train, label='训练集数据点', color='orange', alpha=0.8)# 绘制测试集数据点
plt.scatter(x_test, y_test, label='测试集数据点', color='purple', alpha=0.8)plt.title('用9次多项式拟合二次函数生成的数据并展示过拟合', fontsize=16)
plt.xlabel('x', fontsize=14)
plt.ylabel('y', fontsize=14)
plt.legend(fontsize=12)
plt.grid(True)
plt.tight_layout()
plt.show()