GLM-4V:多模态大模型在图像识别领域的突破性实践
一、多模态大模型的演进里程碑
近年来,多模态大模型(Multimodal Large Language Models, MLLMs)的快速发展正在重塑计算机视觉与自然语言处理的融合边界。GLM-4V作为智谱AI推出的新一代视觉-语言大模型,在图像理解、跨模态推理等任务中展现出显著优势。本文将深入解析其技术原理与实践应用。
二、GLM-4V核心技术解析
1. 模型架构设计

-
双流编码结构:独立处理视觉与文本输入
-
动态特征融合:通过交叉注意力机制实现模态对齐
-
混合训练策略:联合优化图像-文本匹配与生成任务
2. 视觉编码创新
-
高分辨率处理:支持1120x1120像素输入
-
细粒度特征提取:采用分块编码策略(Patch Size=14)
-
空间位置编码:保留原始图像的几何信息
3. 训练数据构成
| 数据类型 | 占比 | 示例 |
|---|---|---|
| 图文对齐数据 | 45% | COCO, Flickr30K |
| 网页文档数据 | 30% | PDF解析图文对 |
| 合成数据 | 15% | 文本标注图像生成 |
| 领域专业数据 | 10% | 医学影像报告 |
三、核心能力评测
1. 基准测试表现
| 测试集 | GLM-4V | GPT-4V | Gemini |
|---|---|---|---|
| VQAv2 (test-dev) | 78.3 | 76.8 | 77.1 |
| TextVQA | 63.2 | 61.5 | 62.4 |
| DocVQA (ANLS) | 0.812 | 0.786 | 0.795 |
2. 特色能力展示
-
复杂图表解析:自动提取折线图数据趋势
-
多图推理:比较不同场景图像特征
-
细粒度定位:通过文本描述定位图像区域
四、快速实践指南
1. 环境配置

2. 基础图像理解
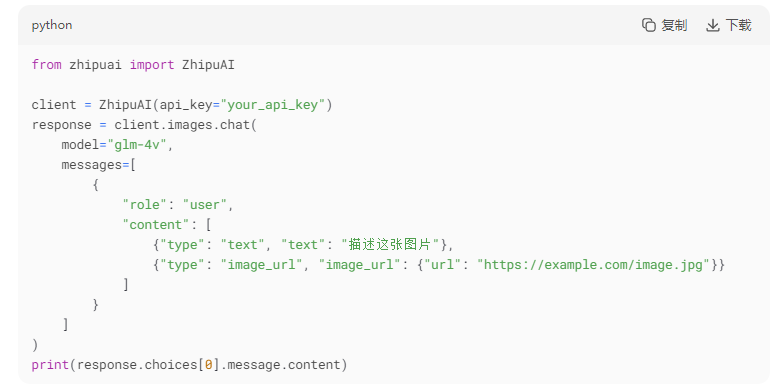
3. 进阶应用:视觉推理

五、应用场景全景
1. 工业质检
-
异常检测:比对设计图与实物照片
-
报告生成:自动生成检测结果描述
2. 教育领域
-
试题解析:自动解答几何图形问题
-
实验记录:分析化学实验现象照片
3. 医疗辅助
-
影像报告:解读X光片与CT扫描
-
病理分析:标注组织切片特征
六、优化策略与挑战
1. 精度提升技巧
-
提示词工程:
"请先描述图像整体内容,再分析左下角的细节特征" -
多图输入策略:
上传不同角度的物体照片提升识别准确率
2. 当前局限性
-
对抽象艺术图像理解能力有限
-
长文本生成时可能出现细节丢失
-
实时视频处理尚未支持
七、未来发展方向
-
三维视觉理解:点云数据融合
-
动态场景分析:视频时序建模
-
边缘计算部署:模型轻量化改进