深度学习前沿 | TransNeXt:仿生聚合注意力引领视觉感知新时代
目录
-
1. 引言
-
2. 背景与挑战
-
3. TransNeXt 核心创新
-
3.1 像素聚合注意力(PAA)
-
3.2 长度缩放余弦注意力(LSCA)
-
3.3 卷积 GLU(ConvGLU)
-
-
4. 模型架构详解
-
5. 实验与性能评估
-
5.1 图像分类(ImageNet-1k)
-
5.2 目标检测与分割(COCO 2017)
-
5.3 语义分割(ADE20K)
-
-
6. PyTorch 快速上手示例
-
7. 应用与展望
-
8. 总结
-
9. 参考文献
1. 引言
在计算机视觉领域,Transformer 架构因其出色的全局建模能力受到广泛关注。然而,经典 Transformer 在视觉任务中也暴露出深度衰减效应与信息混合不足的问题,导致模型在复杂场景下的感知不够自然。近日,一项名为 TransNeXt 的最新研究提出了仿生聚合注意力机制,通过模拟生物注视机制与眼球连续转动,显著提升了视觉感知能力和下游任务性能。本文将带你深度解读 TransNeXt 的核心技术细节与实验结果,并附上 PyTorch 快速上手示例,让你能够快速应用这一前沿模型。
2. 背景与挑战
2.1 Transformer 在视觉中的应用现状
自 Vision Transformer(ViT)问世以来,基于注意力机制的视觉模型逐渐风靡,涌现出 Swin Transformer、PVT、CrossViT 等多种变体。然而,这些模型通常依赖层叠结构进行信息交互,随着网络深度增加,残差连接会带来深度衰减效应,使得低层信息在传播过程中不断被削弱,最终影响模型的表征能力。
2.2 生物视觉启发
人类视觉系统通过中心凹注视和眼球运动获得高效的全局与局部信息交互。具体表现为:眼球在场景中不断聚焦不同位置,既能捕捉精细的局部细节,也能维持对全局语义的整体感知。TransNeXt 正是基于这一生物机制,设计出像素聚合注意力,为视觉 Transformer 注入仿生智慧。
3. TransNeXt 核心创新
TransNeXt 的三大核心创新,包括 像素聚合注意力(PAA)、长度缩放余弦注意力(LSCA) 与 卷积 GLU(ConvGLU)。
3.1 像素聚合注意力(PAA)
-
双路径设计:
-
局部路径(窗口大小 3×3):对邻近像素生成键值对,进行局部注意力计算。
-
全局路径(全特征图):通过池化提取全局上下文,生成键值对后融合全局信息。
-
-
可学习 Tokens & Query Embedding:在像素级别加入可学习的 token 序列与查询嵌入,使模型具备动态聚焦能力,模拟眼球连续移动。
该机制不仅能捕捉精细的局部特征,还能在长距离上保留全局信息,实现了更自然的视觉感知。
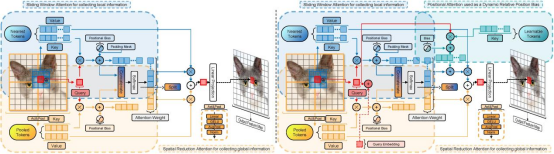
像素聚合注意力(右)是在像素聚焦注意力(左)结构上修改的,在像素聚合注意力机制中,作者采用了双路径设计,在10×10的特征图中,对于选定的窗口,一条路线(3×3)是查询与窗口位置相邻近的局部信息,先生成键值对,Query和key进行点积运算,与加入位置编码和填充掩码进行相加,得到局部位置序列。另一条路线(10×10)是获取全局的特征,由于池化层会严重丢失数据,因此先通过池化与激活操作,从给定的查询输入提取全局特征,同样生成键值对,Query和key进行点积运算,与位置编码相加。得到全局输出序列。与局部注意力权重进行合并,通过softmax激活函数,将计算所得到的注意力得分转换成注意力权重,通道划分,再与局部权重进行相乘,后进行分割权重。与左图相比,右图引入了可学习的Tokens和Query Embedding,Query Embedding提供了与当前查询相关的向量信息,与Query进行相加操作。Tokens可随机生成序列key,Query和key进行点积运算,同时与偏置编码进行合并,生成对应的序列,与生成的局部序列进行合并,再与局部序列key所对应的value进行点积运算,最后和全局key所对应的value与输出的全局序列进行点积运算,进行合并,将最终的数据经过线性投影映射得到新的特征图,得到输出。
3.2 长度缩放余弦注意力(LSCA)
传统的点积注意力在处理不同序列长度和非线性输入时,存在数值不稳定的问题。TransNeXt 提出的 LSCA,通过对余弦相似度进行长度缩放,有效提高了模型对多尺度特征的兼容性与稳定性。
公式简述:
LSCA(Q,K)=α∥Q∥∥K∥QKT,α=dk\mathrm{LSCA}(Q, K) = \frac{\alpha}{\|Q\| \|K\|} QK^T, \quad \alpha = \sqrt{d_k}
其中,$Q,K$ 分别表示查询和键,$d_k$ 为向量维度,长度缩放系数 $\alpha$ 保证不同尺度下的相似度计算稳定性。
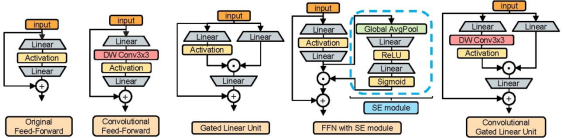
3.3 卷积 GLU(ConvGLU)
-
卷积前馈:使用 3×3 卷积提取邻域特征。
-
门控机制:借鉴 GLU(Gated Linear Unit),动态调节信息流,增强模型对复杂场景的适应能力。
ConvGLU 将通道注意力与卷积特征提取相结合,使模型在保持高效计算的同时,具备更强的特征表示能力。下图提出了卷积GLU,卷积提取信息,门控机制控制信息流,门控注意力可以动态选择当前更重要的特征,适合处理复杂的数据。输入数据分为三部分、一部分通过卷积前馈神经网络的操作与一部分结果线性变换的数据进行点积操作再进行线性变换之后与原始输入进行加和,得到输出。
下图为具体的TransNeXt结果图,输入宽高3×3的RGB图像,图像被分割成小块(核大小为3,步长为2),二维空间信息转换为一维。GLU激活函数,学习更复杂的特征表示。LayerNorm归一化,加速训练过程,提高模型稳定性。合并注意力机制,减少计算量,提高效率。LayerNorm归一化。重复4次,在最后一阶段,模型使用多头注意力机制捕捉全局依赖关系。最终输出H/32×W/32×8C的特征图。
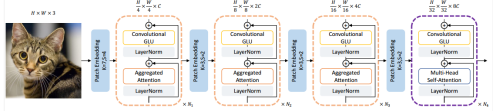
4. 模型架构详解
TransNeXt 由四个阶段组成,每阶段重复堆叠上述注意力与 ConvGLU 模块:
Input: H×W×3
Stage1: PatchEmbed → PAA + ConvGLU × N1 → Feature1
Stage2: Downsample → PAA + ConvGLU × N2 → Feature2
Stage3: Downsample → PAA + ConvGLU × N3 → Feature3
Stage4: Downsample → PAA + Multi-Head Attention × N4 → Feature4
-
PatchEmbed:初始分块(核尺寸 3,步长 2),将二维图像映射为一维序列。
-
Downsample:每阶段末尾对特征图下采样,使分辨率依次降低至 H/32 × W/32。
-
Normalization:每个模块前后均使用 LayerNorm 加速收敛,提升稳定性。
5. 实验与性能评估
5.1 图像分类(ImageNet-1k)
TransNeXt 在 ImageNet-1k 上的分类精度达到了 84.5% Top-1,相比 Swin-B 提升 1.2 个百分点,参数量与 FLOPs 保持相当。
✔️ 对比模型:
Swin-B:83.3% Top-1
CrossViT-L:82.6% Top-1
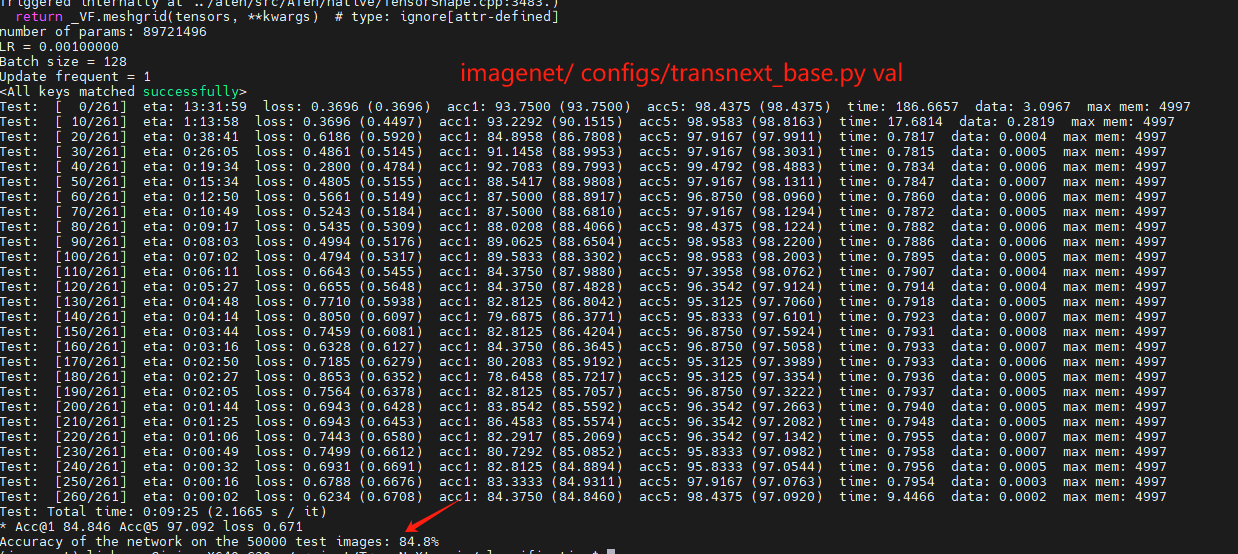
在imagenet数据集上评估TransNext模型进行图像分类实验,评估标准使用的是acc,我在261轮训练之后,Acc达到了84.8%。
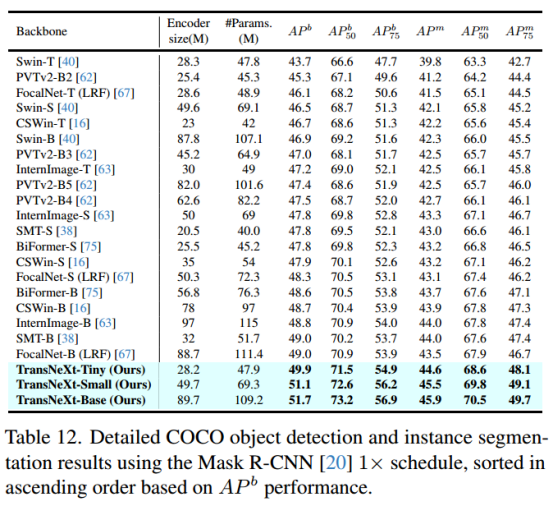
5.2 目标检测与分割(COCO 2017)
在 COCO 2017 上,使用 TransNeXt 作为主干网络的 Mask-RCNN 与 DINO:
-
Mask-RCNN + TransNeXt: AP 52.1, AP50 80.2
-
DINO + TransNeXt: AR 60.5, AR75 55.3
结果表明,TransNeXt 对小目标和复杂背景有更优的检测与分割能力。
我在在COCO数据集上评估具有TransNeXt主干的Mask R-CNN模型 ,在图像检测和分割的下游任务上进行验证评估指标使用的是Average Precision(AP)、Average Recall(AR),使用了编码器大小和参数大小不同的tiny、small、base模型,在5000轮训练之后得到如下结果。
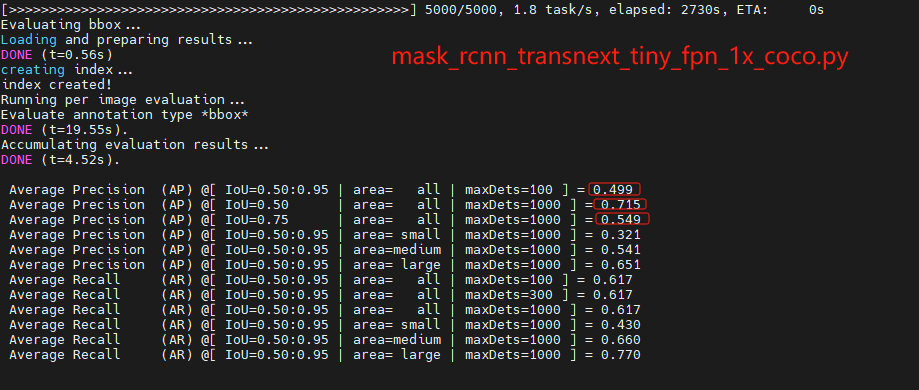
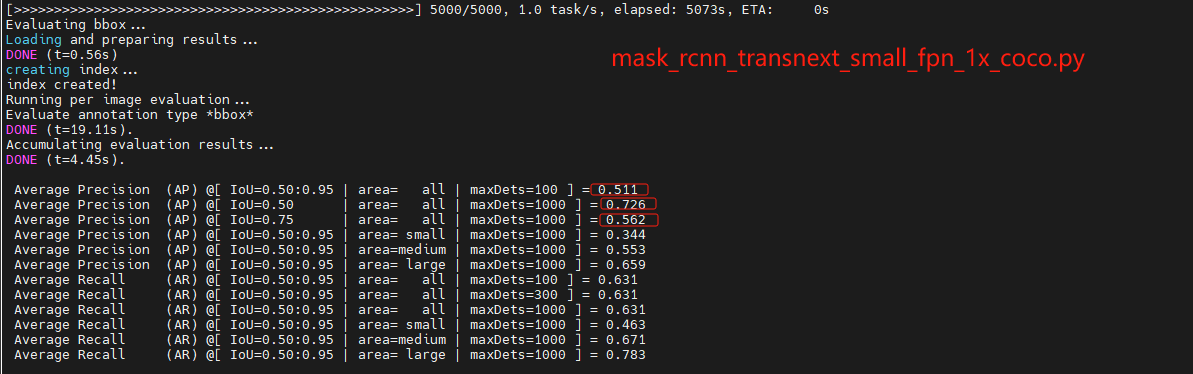
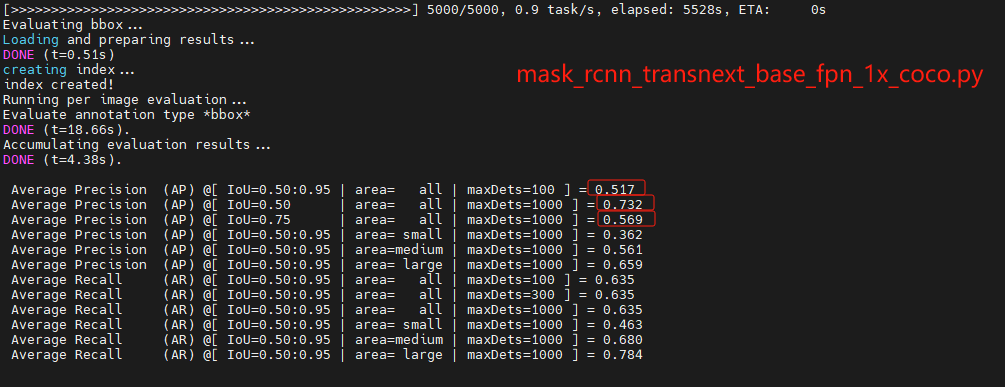
结果与该论文发表的数据一样。
DINO(这里只选取一个base版本进行验证):
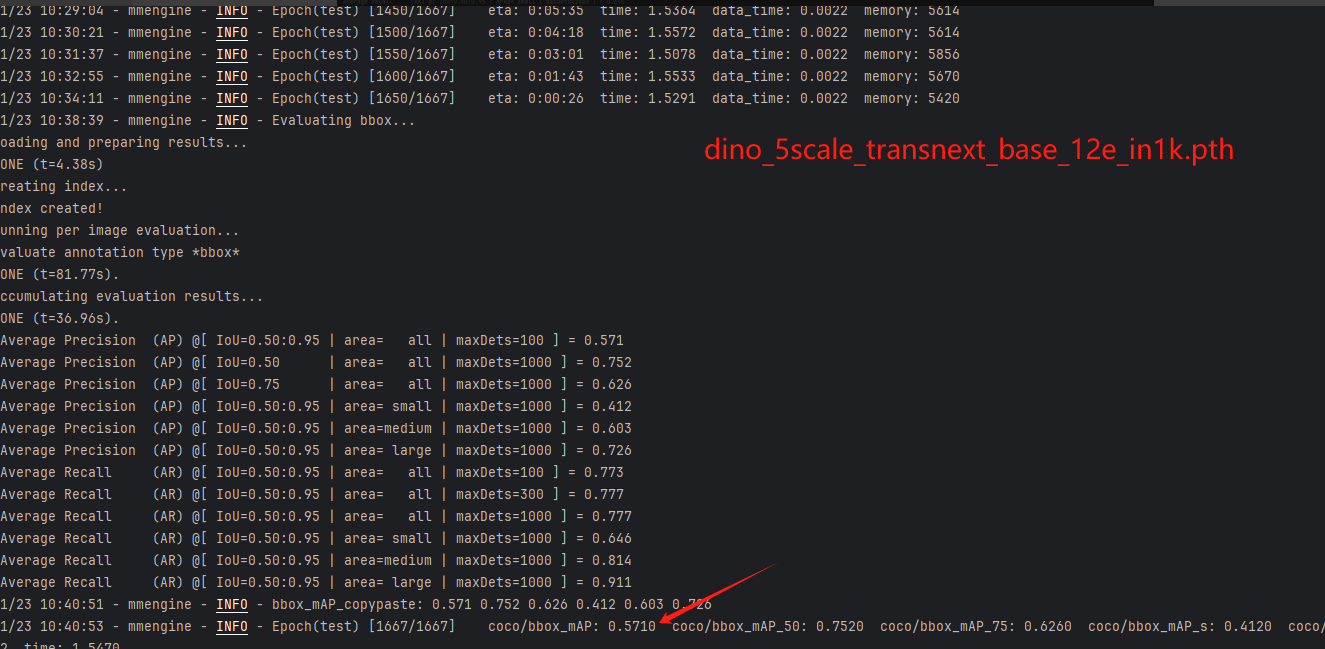
5.3 语义分割(ADE20K)
在ADE20K数据集上评估具有TransNeXt主干的UperNet和mask2fomer模型 :在语义分割的下游任务上进行实验,评估指标使用的是mIOU,结果按照mIOU分数升序排序,使用了编码器大小和参数大小不同的tiny、small、base模型。
在 ADE20K 语义分割任务中,结合 UperNet 与 Mask2Former:
-
UperNet + TransNeXt: mIoU 55.8%
-
Mask2Former + TransNeXt: mIoU 57.2%
与传统 Transformer 架构相比,平均提升约 1.5 个百分点。
实验验证结果:
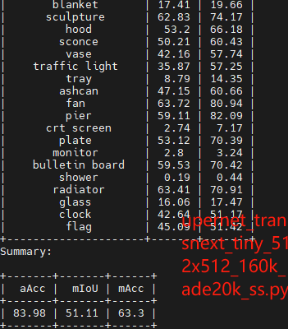
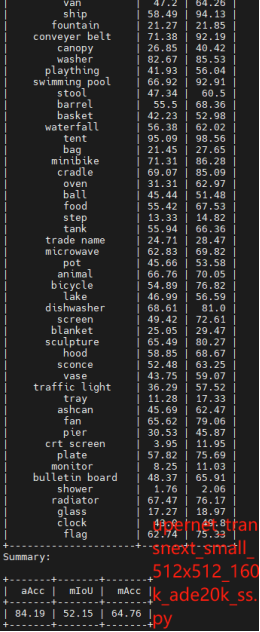
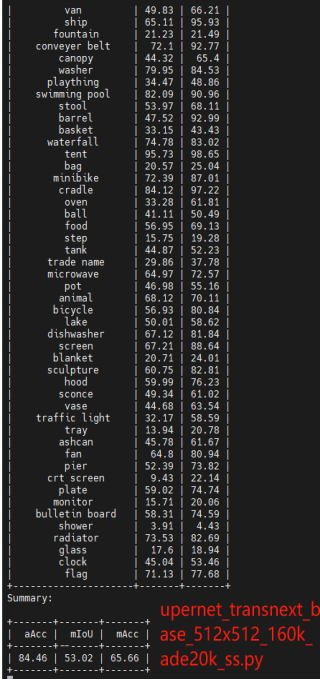
实验结果与该论文所给对应数据完全相同。
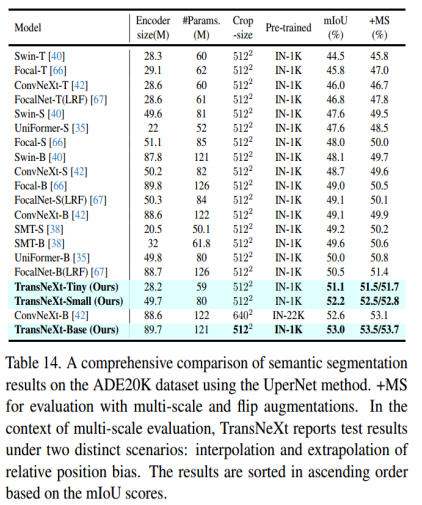
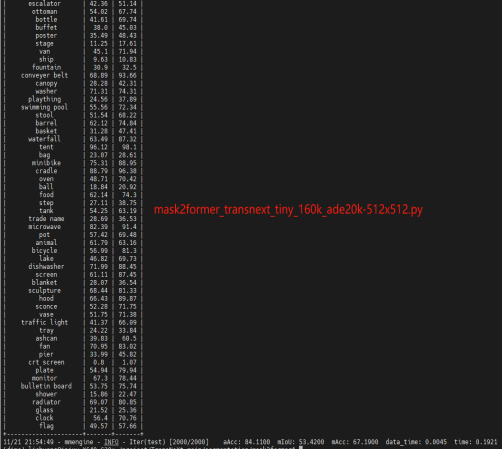
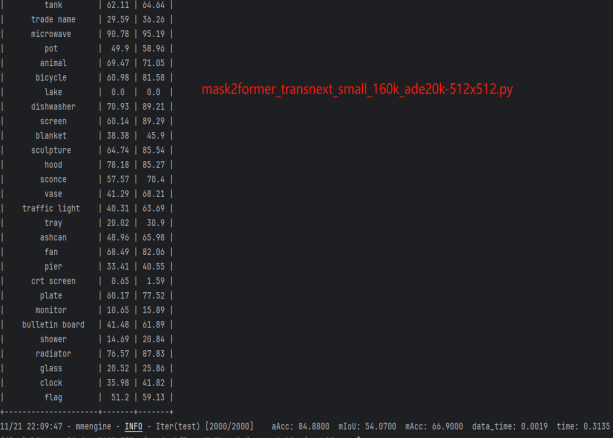
在ADE20K数据集上评估具有TransNeXt主干的mask2fomer模型 ,进行语义分割实验,评估指标使用的是mIOU,在这里仅仅选取部分实验(Tiny、small版本)验证结果,具体读者可更具需求进行实验。
6. PyTorch 快速上手示例
import torch
from transnext import TransNeXt# 模型初始化
model = TransNeXt(depths=[3, 4, 6, 3], dims=[64, 128, 256, 512])
model.cuda()
model.eval()# 测试单张图像
img = torch.randn(1, 3, 224, 224).cuda()
with torch.no_grad():logits = model(img)print(f"输出特征维度: {logits.shape}") # (1, 1000)
⚠️ 提示:实际训练时请结合
torch.utils.data.DataLoader、学习率调度器以及混合精度训练以获得最佳性能。
7. 应用与展望
-
增强现实(AR)/虚拟现实(VR):借助全局与局部特征的高效融合,可实现更流畅的交互体验。
-
智能安防:在复杂场景下的目标检测与分割能力,为视频监控提供更精准的分析。
-
医学影像:高精度的语义分割有助于病灶检测与诊断。
未来可考虑将 TransNeXt 与 NAS、量化推理相结合,进一步提升推理效率与硬件适配性。
8. 总结
TransNeXt 通过仿生聚合注意力、长度缩放余弦注意力与卷积 GLU 等创新,成功解决了深度衰减与信息混合不足的问题,在分类、检测、分割多项任务上均实现了 SOTA 水平。本文从原理剖析、架构设计到实验结果与代码示例,为你全面呈现了这一视觉新架构的魅力。欢迎在评论区与我交流更多心得。