Crawl4AI 部署安装及 n8n 调用,实现自动化工作流(保证好使)
Crawl4AI 部署安装及 n8n 调用,实现自动化工作流(保证好使)
简介
Crawl4AI 的介绍
一、Crawl4AI 的核心功能
二、Crawl4AI vs Firecrawl
Crawl4AI 的本地部署
一、前期准备
二、部署步骤
1、检查系统的网络环境
2、下载 Crawl4AI 源码
3、Crawl4AI 环境变量与配置文件的修改
4、启动 Crawl4AI
5、启动 Crawl4AI(不使用 Docker Compose)
n8n 的调用
1、获取网站的 sitemap.xml
2、在 n8n 中创建一个聊天消息触发器,用于传入对应的 sitemap.xml 的 URL
3、在 n8n 中获取 sitemap.xml 并把 XML 格式转化为 JSON 格式
4、对数据进行分割处理并限制 URL 数量
5、循环处理过滤后的每个 URL 并为每个 URL 生成 task_id
6、执行 task_id 指定的任务
7、对执行结果进行判断并执行不同的动作
8、把输出结果生成文件并映射到宿主机指定目录
备份与加载 Crawl4AI 的镜像
一、备份 Crawl4AI 的镜像
二、加载 Crawl4AI 的镜像
简介
在大语言模型(LLM)和生成式 AI 爆发的今天,数据采集的效率与质量直接决定了 AI 应用的落地效果。传统爬虫工具在动态渲染处理、AI 友好输出和大规模部署上的局限性日益凸显,而专为 AI 设计的 Crawl4AI 框架正成为企业级数据管道的首选方案。
Crawl4AI 的介绍
Crawl4AI 是基于 Python 开发的开源智能爬虫框架,其核心设计理念是“为 AI 应用构建专属数据通道”。架构层面采用分层设计:
- 调度层:基于 asyncio 的自适应并发调度器,支持动态调整爬取并发数(单实例可稳定处理 5000 + 并发请求)
- 渲染层:深度集成 Playwright(默认)/Selenium,支持无头 / 有头模式,内置反反爬机制(UA 随机化、请求间隔动态调整)
- 提取层:创新性引入 LLM 驱动的智能提取引擎,支持通过自然语言指令(如 "提取页面中所有产品价格")生成结构化数据
- 输出层:原生支持 Markdown/JSON/CSV 格式输出,特别适配 LLM 的上下文输入要求
一、Crawl4AI 的核心功能
| 功能模块 | 技术实现 | 应用价值 |
|---|---|---|
| 动态渲染支持 | Playwright 内核,支持 JavaScript 完全执行,页面加载超时智能重试(默认 3 次) | 完美处理 SPA 单页应用、动态加载内容(如电商详情页、瀑布流页面) |
| 智能数据提取 | 支持 JSON Schema/CSS 选择器 / LLM 指令三种提取策略,内置正则表达式增强模块 | 非技术人员可通过自然语言指令完成复杂数据提取,降低开发门槛 50% 以上 |
| 分布式部署 | 原生支持 Docker/Kubernetes,提供 Helm Chart 模板,支持分布式任务队列(Redis/RabbitMQ) | 轻松扩展至数百节点集群,满足日均亿级页面爬取需求 |
| 反爬机制 | 随机 UA 池(内置 500 + 真实 UA)、代理 IP 轮换(支持 HTTP/SOCKS5)、请求间隔抖动算法 | 有效绕过 90% 以上的反爬系统,爬取成功率提升至 98% |
二、Crawl4AI vs Firecrawl
Crawl4AI 与 Firecrawl 这两个都是开源的爬虫框架,但是他们之间会存在一些差异,主要体现在核心定位的不同
| 维度 | Crawl4AI | Firecrawl |
|---|---|---|
| 设计目标 | 面向 AI 应用的数据采集管道,深度适配 LLM 输入要求 | 通用型爬虫框架,侧重基础爬取功能 |
| 核心优势 | LLM 智能提取、云原生部署、自适应并发调度 | 轻量级设计、快速原型开发 |
| 技术栈 | Python(asyncio/Playwright) | Python(Scrapy/Selenium) |
| 学习曲线 | 中高(需掌握 AI 提取策略) | 中等(传统爬虫语法) |
Crawl4AI 的本地部署
一、前期准备
环境要求:
| 组件 | 最低配置 | 推荐配置 |
|---|---|---|
| 操作系统 | Windows 10+/macOS 12+/Linux | Ubuntu 22.04+ |
| Python 版本 | 3.9+ | 3.11+ |
| 内存 | 8GB | 16GB+ |
| 存储 | 50GB SSD | 200GB NVMe |
网络环境:
- 本地网络:部署时可以使用 VMware 的 NAT 模式,如果只是本机使用就已经无需调整了,如果是需要内网中为其他设备提供服务,那就需要配置成 bridge(桥接)模式了;如果使用 Docker 部署,可以直接通过使用 Docker Desktop 的默认网络使用即可。
- 外部网络:我们是把 Crawl4AI 部署在 Docker 中,所以构建时需要从网络上拉去镜像,国内虽然有镜像源,但是并没有外面的全,而且通常 github 上的 Dockerfile 都是使用 docker.io 这个官方源去拉取的,所以可能会导致超时导致构建失败,所以提前准备一个靠谱的代理(科学上网)是非常必要的。
docke r 的安装:
关于 Linux 中 do cker 的安装在这里就不进行细说了,可以跟着这篇博客来操作:Ubuntu使用国内源安装Docker,Mysql,Redis_ubuntu docker 国内源-CSDN博客
二、部署步骤
Crawl4AI 可以使用 Python 和 Docker 来部署,推荐使用 Docker 来进行部署,本篇也会基于 Docker 部署的方式来介绍部署步骤。
Python 部署的方式可以看这个链接:Crawl4AI 的 Python 部署方法。
本次演示将会在 Windows 环境下进行安装,Windows 和 Linux 除了 docker 的安装不太一样之外,后面的一系列命令都是一样的。
1、检查系统的网络环境
在装好 Docker Desktop 后开始检查的及时网络问题了,首先我们要把之前提到的“科学上网”打开,并调节到全局模式(拉取镜像的成败关键)

同时即使开了“科学上网”有的还是会失败,这是由于运营商的问题,因为每个运营商对于不同 IP 访问的路由设置都不一样,目前在广东测试发现电信是最好使的。可以根据下面的命令进行 ping 测一下:
ping www.docker.com
ping www.github.com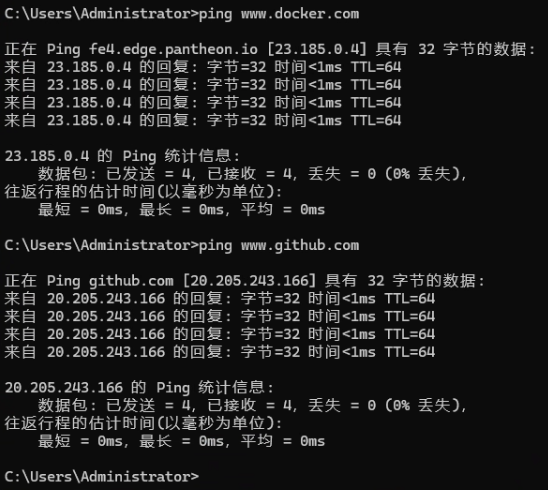
如果到最后实在是没办法了,可以拿我提前安装好的镜像直接导入到 docker 当中来使用,这样就可以避免网络问题了,链接在“备份与加载 Crawl4AI 的镜像”的部分
2、下载 Crawl4AI 源码
Crawl4AI 是一个开源软件,我们可以直接上 Github 上搜索并下载其源码,链接为:https://github.com/unclecode/crawl4ai,可以直接下载 ZIP 压缩或通过 git 命令下载(需要提前安装 git)。
2.1 本次我们使用 git 命令来克隆代码。git 命令安装过程如下:
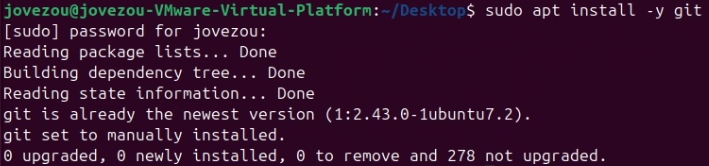
Ubuntu:
sudo apt-get install -y git如果已经安装过会如下图所示
Windows:
直接打开该链接下载:Git - Downloads
下载完成后双击安装,安装选项默认即可。
2.2 然后我们去 Github 上获取克隆链接,如下图所示
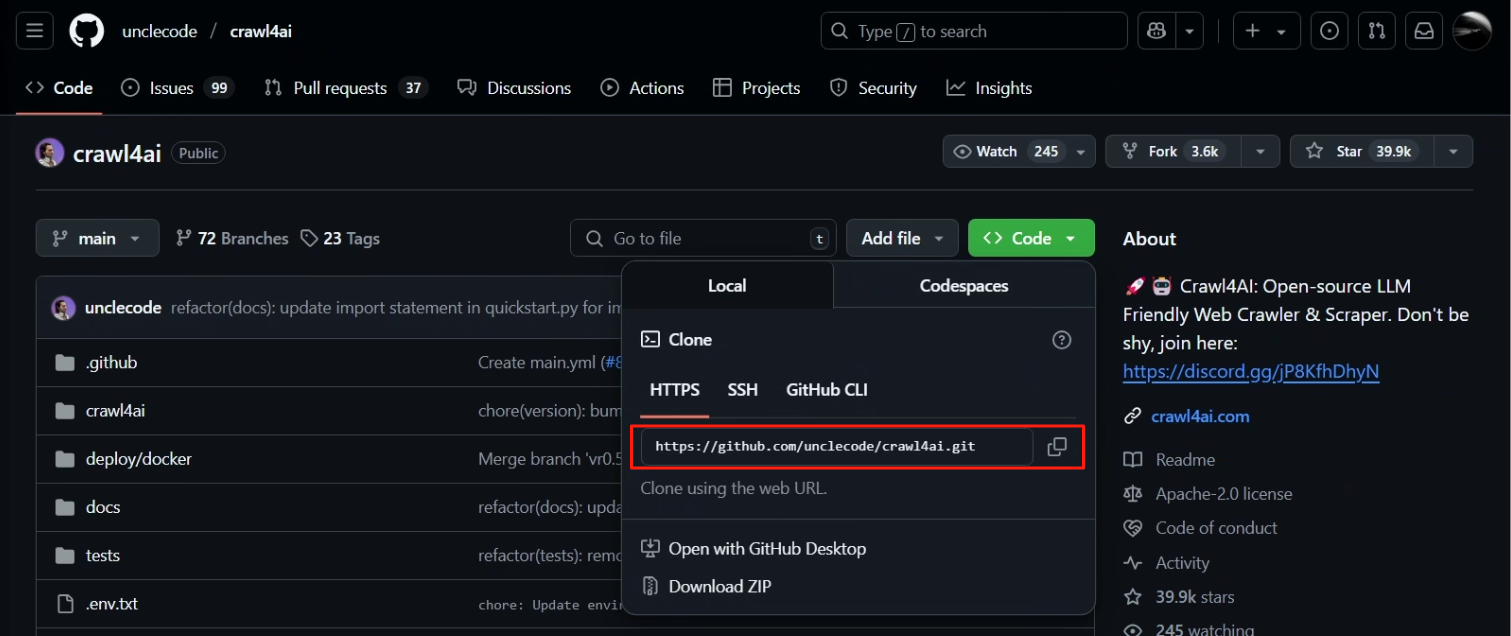
打开目标目录,在地址栏输入 cmd 根据当前目录打开终端,并输入以下命令(该命令会下载到当前所在目录下)
git clone https://github.com/unclecode/crawl4ai.git3、Crawl4AI 环境变量与配置文件的修改
Crawl4AI 源码当中并没有预先准备好的 .env 文件和 docker-compose.yml 文件,如果我们想要使用 Docker Compose 来管理的话那就要自己编写一份了,不过型号官方文档当中有一份参考的可以参考一下:https://docs.crawl4ai.com/core/docker-deployment,我在这里也提供一下经过我改造的 .env 文件和 docker-compose.yml 文件:
.env 文件:
# API Security (optional)
CRAWL4AI_API_TOKEN=12345 # Crawl4AI的API Key# LLM Provider Keys
GROQ_API_KEY = "YOUR_GROQ_API" # GROQ的API Key
OPENAI_API_KEY = "YOUR_OPENAI_API" # OpenAI的API Key
ANTHROPIC_API_KEY = "YOUR_ANTHROPIC_API" # ANTHROPIC的API Key# Other Configuration
MAX_CONCURRENT_TASKS=5 # 最大并发任务数量docker-compose.yml 文件:
name: crawl4ai
version: '3.8'services:crawl4ai:image: unclecode/crawl4ai:all-amd64ports:- "11235:11235"environment:- CRAWL4AI_API_TOKEN=${CRAWL4AI_API_TOKEN:-} # Optional API security- MAX_CONCURRENT_TASKS=${MAX_CONCURRENT_TASKS:-}# LLM Provider Keys- OPENAI_API_KEY=${OPENAI_API_KEY:-}- ANTHROPIC_API_KEY=${ANTHROPIC_API_KEY:-}volumes:- /dev/shm:/dev/shmdeploy:resources:limits:memory: 4Greservations:memory: 1Gnetworks:- backendnetworks:backend:driver: bridgeipam:config:- subnet: 169.254.60.0/24gateway: 169.254.60.14、启动 Crawl4AI
在使用 Docker Compose 启动 Crawl4AI 的容器前,我们需要到 docker-compose.yml 文件所在的目录下打开终端来执行以下第一条命令才行,顺带的我们一起把停止容器和删除容器一起介绍一下
# 通过当前目录下的 docker-compose.yml 文件启动容器,-d 为后台执行的意思
docker compose up -d# 停止当前目录下的 docker-compose.yml 文件管理的容器
docker compose stop# 停止并删除当前目录下的 docker-compose.yml 文件管理的容器,会把相应的容器网络也一并删除掉,但 volume 并不会删除
docker compose down启动时如下图所示

启动完成如下图所示
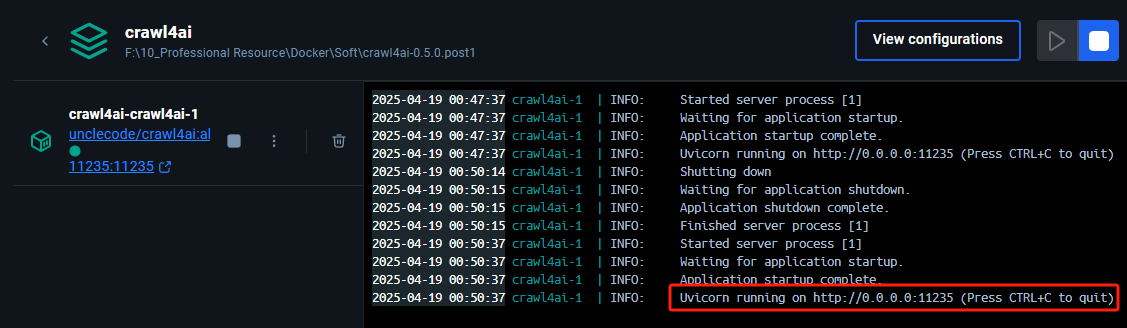
出现 http://0.0.0.0:11235 代表启动成功,但是需要把 0.0.0.0 替换为本机 IP 或 127.0.0.1 才能访问成功。访问成功后会出现 Crawl4AI 的文档,如下图所示
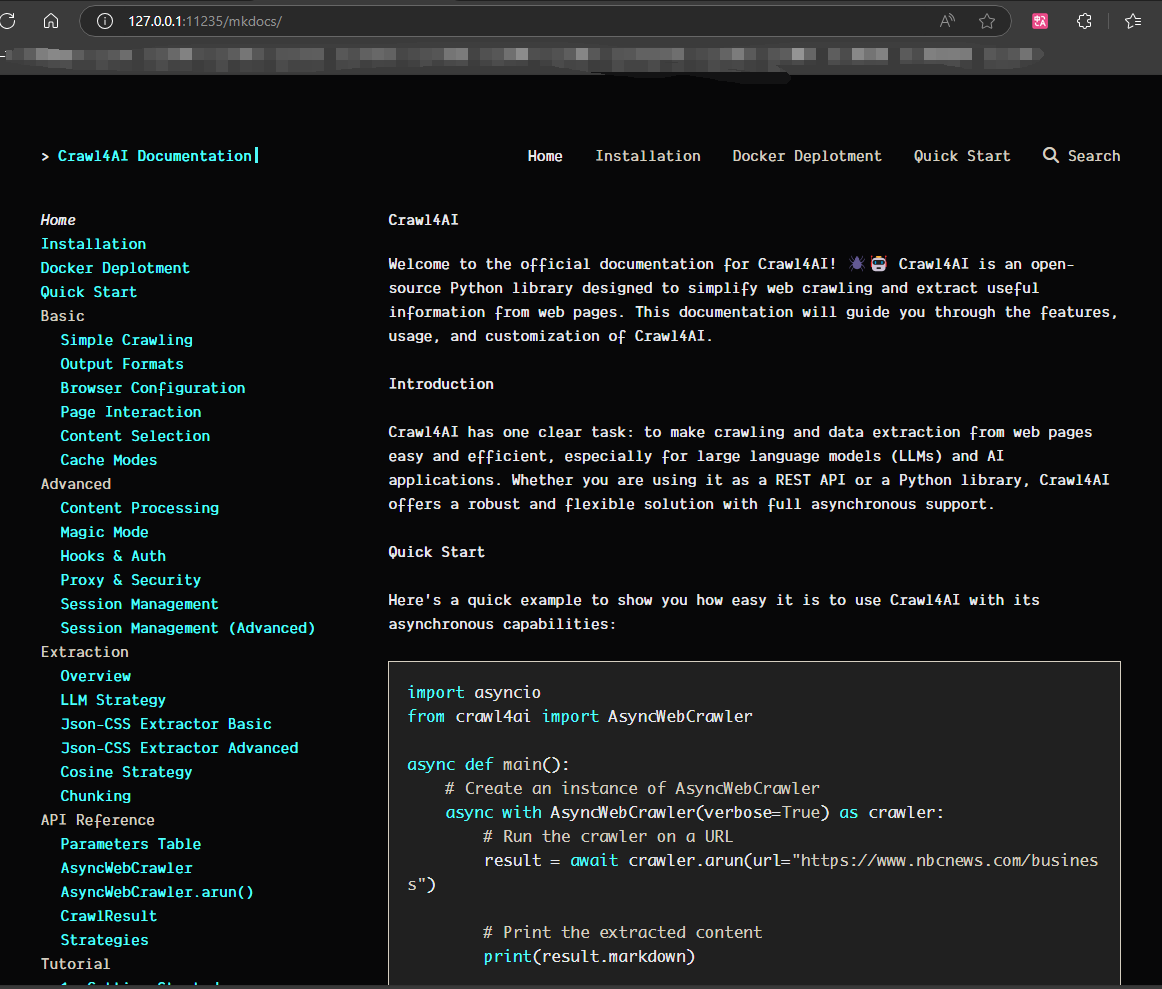
到此 Crawl4AI 就使用 Docker 部署完毕了。
5、启动 Crawl4AI(不使用 Docker Compose)
当然,Crawl4AI 由于只整合成了一个容器,所以并不存在对其他容器的依赖,也就是说它对比起 Firecrawl 来说是比较轻便的,所以我们也可以不使用 Docker Compose 来启动,而是直接使用 docker run 来启动容器也是可以的,只需要执行以下的命令即可
# 拉取镜像,如果前面已经使用 Docker Compose 拉取过了,就不需要执行该命令了
docker pull unclecode/crawl4ai:all-amd64# 直接运行容器,-p 为端口参数(映射到宿主机:容器内部网络),-e 为环境变量 CRAWL4AI_API_TOKEN 是使用 Crawl4AI 的 API Key,最后是镜像名及版本号 unclecode/crawl4ai:all-amd64(版本为 all-amd64)
docker run -p 11235:11235 -e CRAWL4AI_API_TOKEN=12345 unclecode/crawl4ai:all-amd64但是使用 docker run 启动有一个缺点,那就是不能进行统一的管理,例如当你达到“docker compose down”时,需要执行以下一系列的命令
# unclecode/crawl4ai:all-amd64 容器停止运行
docker stop unclecode/crawl4ai:all-amd64
# 删除容器 unclecode/crawl4ai:all-amd64
docker rm unclecode/crawl4ai:all-amd64
# 删除 Crawl4AI 的容器网络,crawl4ai_backend 为网络名,也能使用“网络 ID”来删除
docker network rm crawl4ai_backendn8n 的调用
在使用 n8n 调用 Crawl4AI 前要先确保 n8n 已经成功部署了,具体的部署教程请查看:https://blog.csdn.net/zjw529507929/article/details/147164342
注意:推荐使用 Docker Compose 运行,在 docker-compose.yml 中有对宿主机进行映射的配置
该示例是自动把网页内容生成为 FAQ 格式(RAGFlow 对这种格式支持比较好),并保存文件到宿主机指定目录当中。
1、获取网站的 sitemap.xml
sitemap.xml 是网站地图文件,它是一种遵循特定格式的 XML 文件,用于向搜索引擎等 web 爬虫程序提供有关网站上所有页面的信息,以便它们能够更有效地抓取和索引网站内容。现在很多网站为了能更好的传播自己的网站都会提供 sitemap.xml,例如:
- DeepSeek 的中文 api 文档:https://api-docs.deepseek.com/zh-cn/
- Crawl4AI 的官方文档:https://docs.crawl4ai.com/
当遇到某些网站没有 sitemap.xml 时,我们可以通过一些 sitemap.xml 生成网站来生成,例如:
- 在线生成 sitemap.xml:https://www.xml-sitemaps.com/(免费最多生成500个网站页面链接)
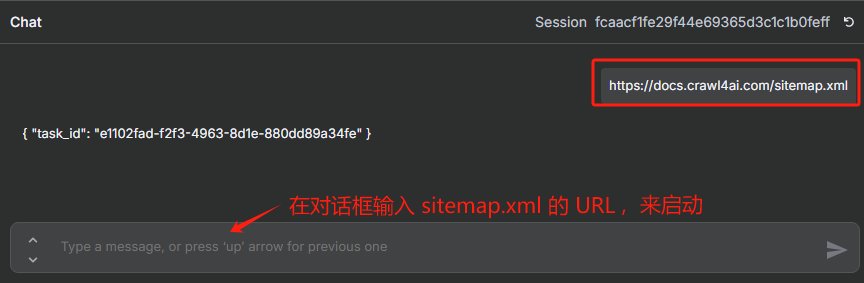
假设我现在要对这个网站:https://www.fsonline.com.cn/(该网站没有自己的 sitemap.xml),在线生成 sitemap.xml,我们打开在线生成 sitemap.xml 的网站,只要直接输入对应的 URL,然后点击 START 就可以开始生成 sitemap.xml 了。
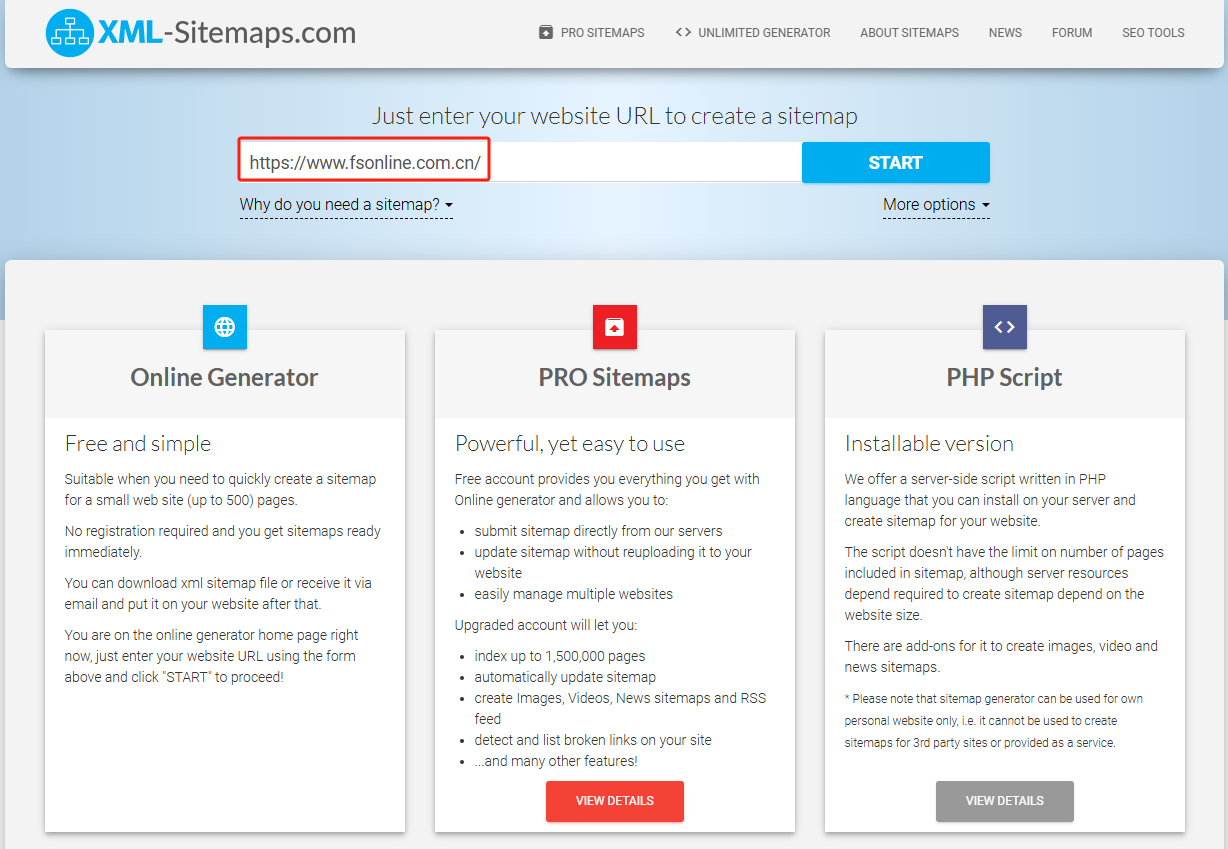
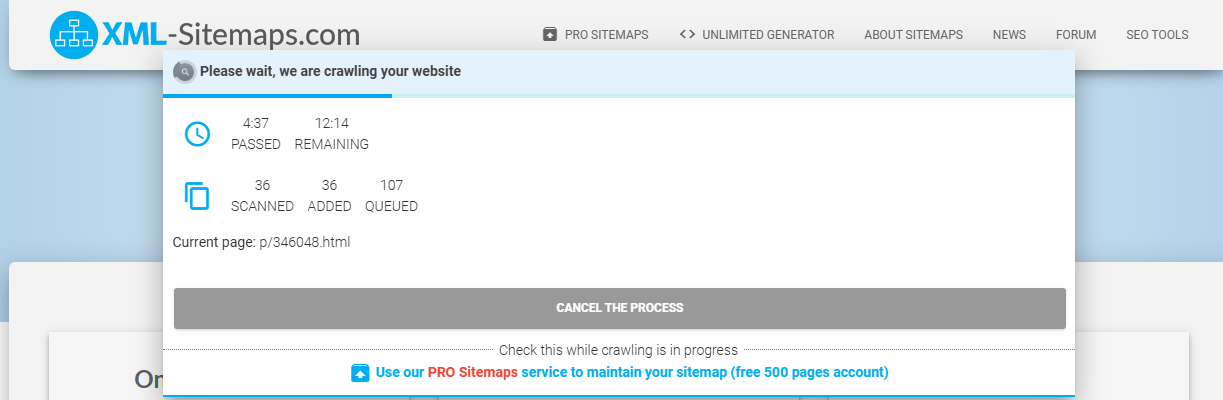

生成完毕后会生成一个 sitemap.xml 的 URL,那我们就能访问这个 URL 来获取我们需要抓取网站的 sitemap.xml 了
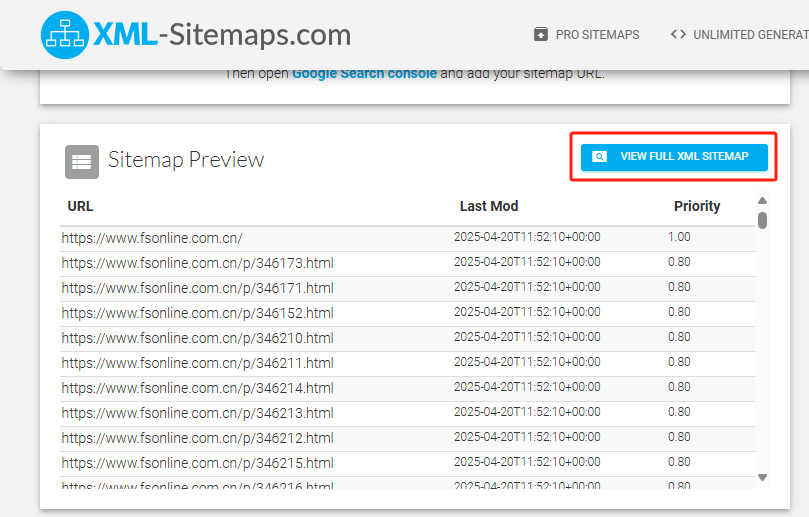
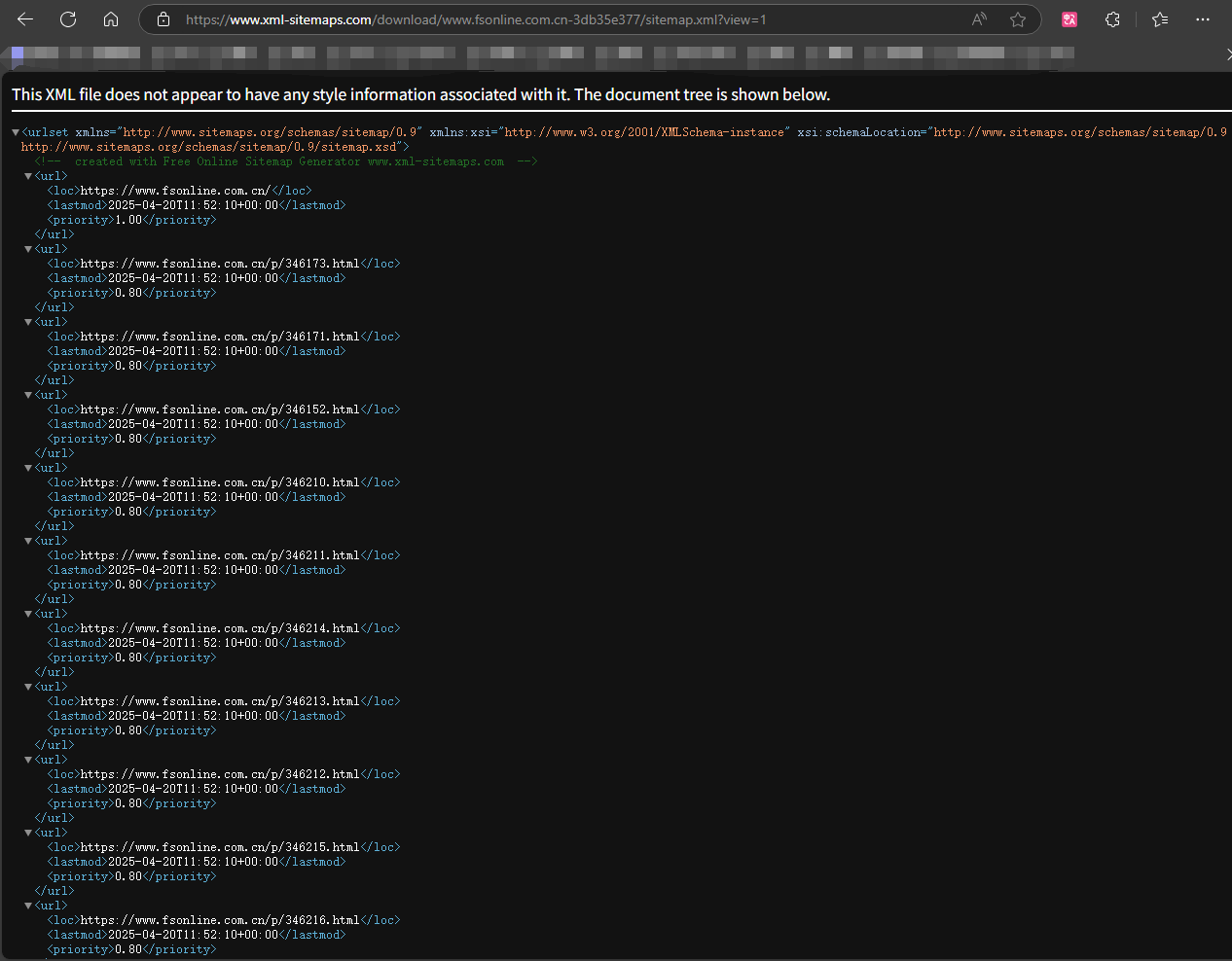
2、在 n8n 中创建一个聊天消息触发器,用于传入对应的 sitemap.xml 的 URL
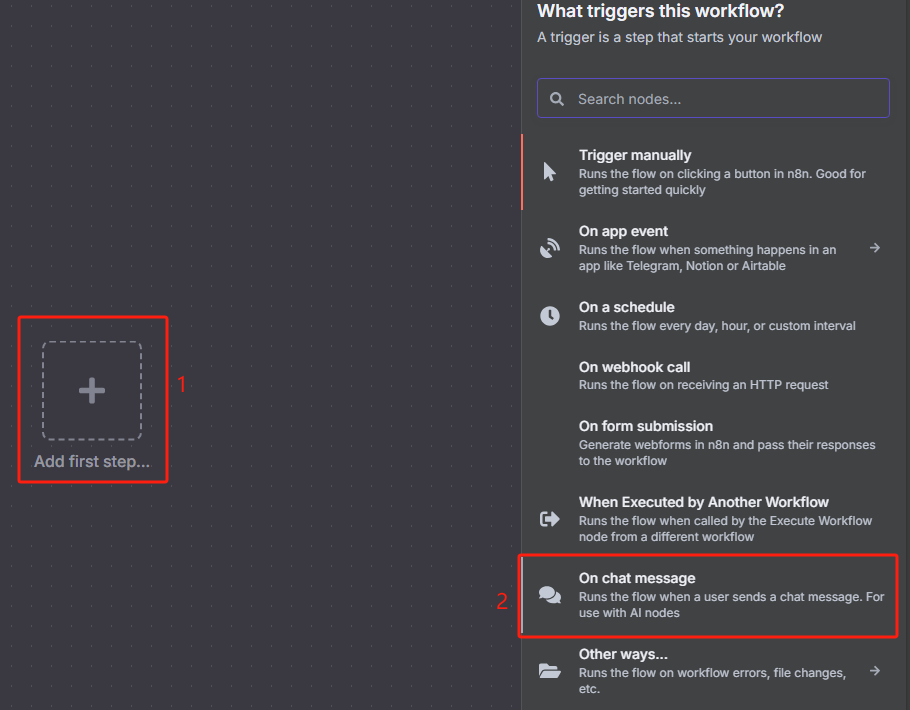
该聊天消息触发器保持默认设置就可以了。
3、在 n8n 中获取 sitemap.xml 并把 XML 格式转化为 JSON 格式
添加一个 HTTP 请求节点,用于获取 sitemap.xml
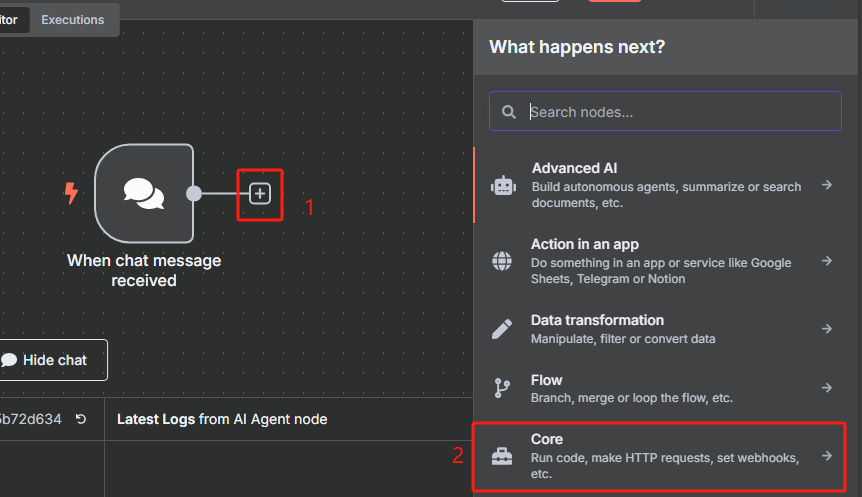
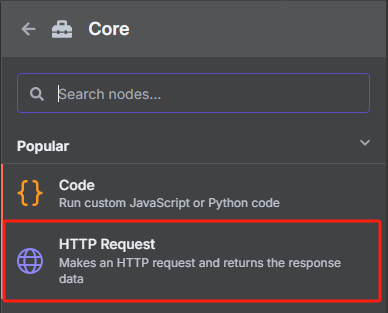
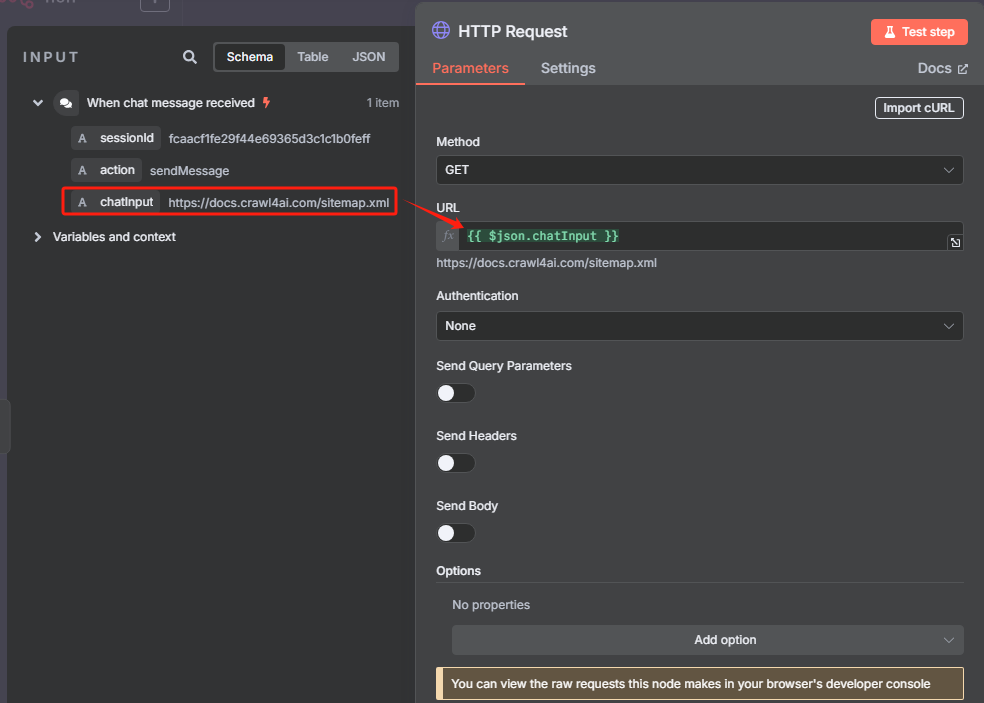
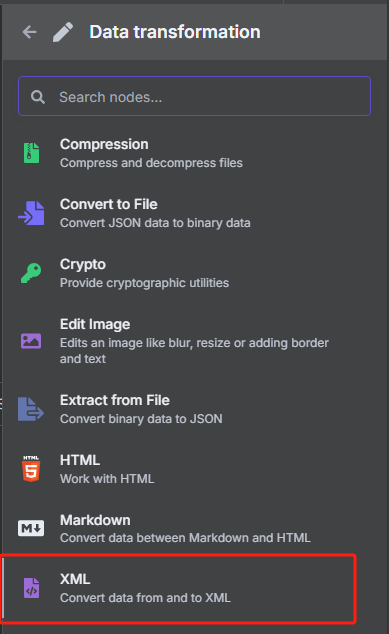
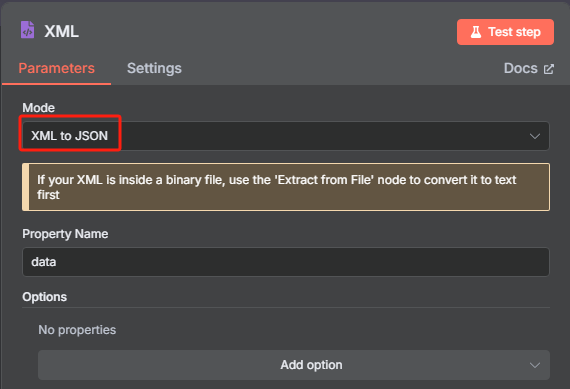
这时候获取到的是一个 XML 格式的文件,并不能很好的进行识别,我们需要使用 XML 工具节点转换为 JSON 格式

4、对数据进行分割处理并限制 URL 数量
由于我们前面转换后的 JSON 格式数据当中包含了很多 URL,但是我们并不是所有时候都需要对所有 URL 进行抓取,所以接下来我们需要对数据中的每一条 URL 进行分割,并使用限制节点来控制抓取数量。
使用数据分割节点的操作如下
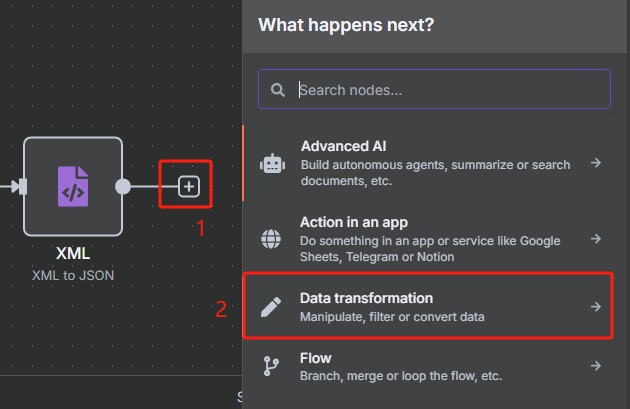
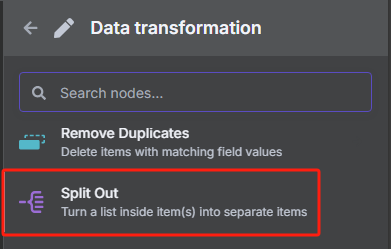
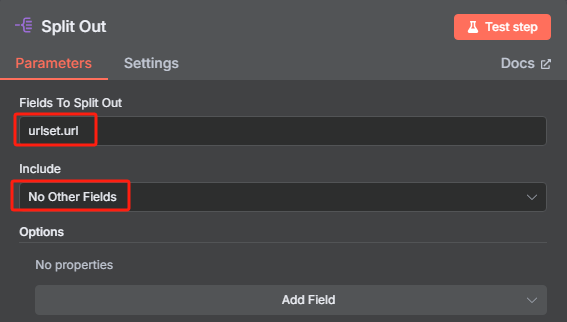
使用限制节点来控制抓取数量的操作如下
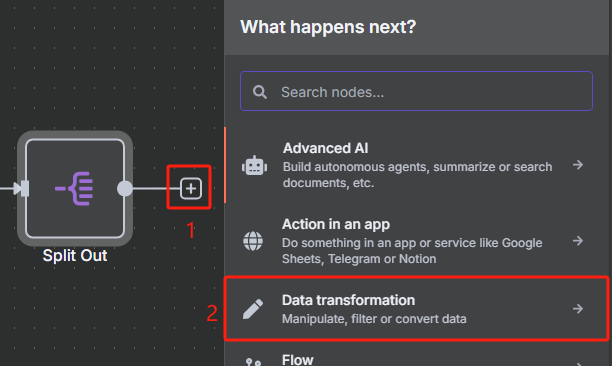
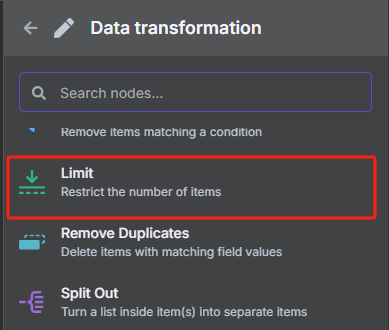
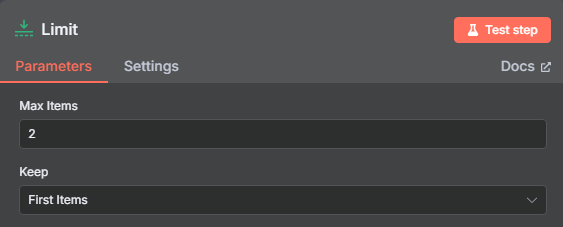
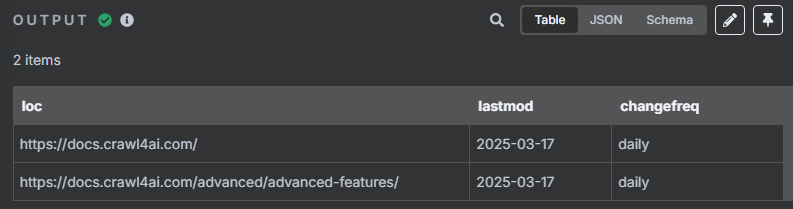
限制一次只获取前两个 URL
5、循环处理过滤后的每个 URL 并为每个 URL 生成 task_id
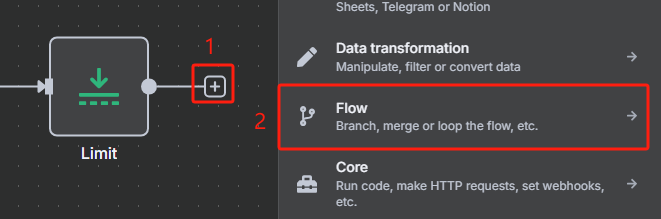
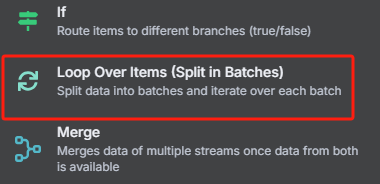
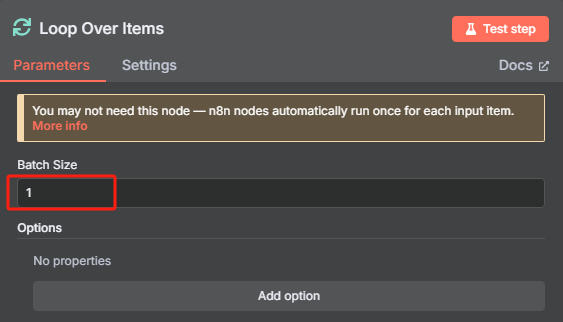
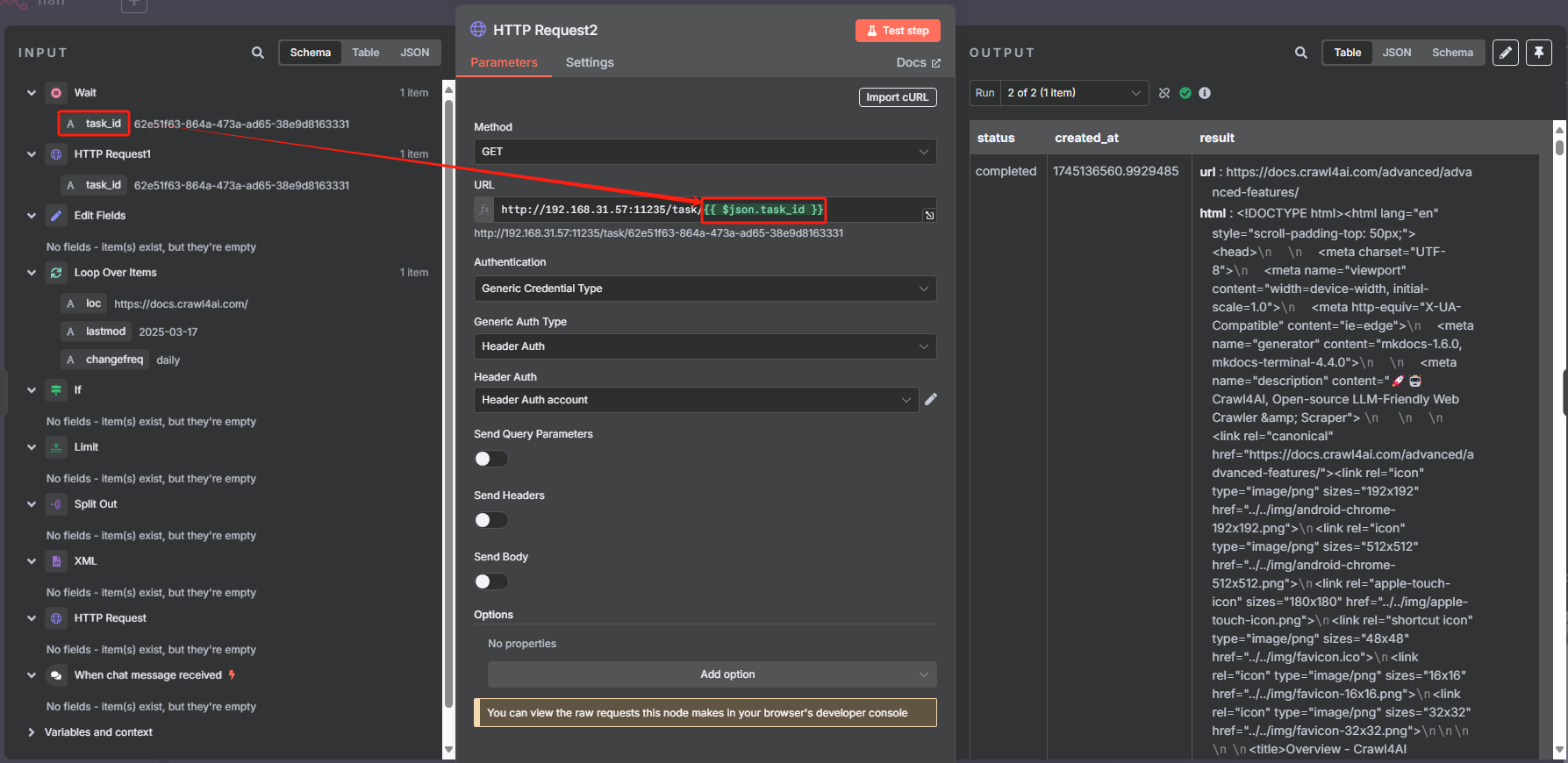
然后每次循环都是使用 HTTP 请求 Crawl4AI 的 crawl 接口来添加抓取任务,返回的是一个 task_id,这个就相当于是一个任务代码,后面需要把这个 task_id 给 task 接口才能执行该任务,获取 task_id 的具体操作如下
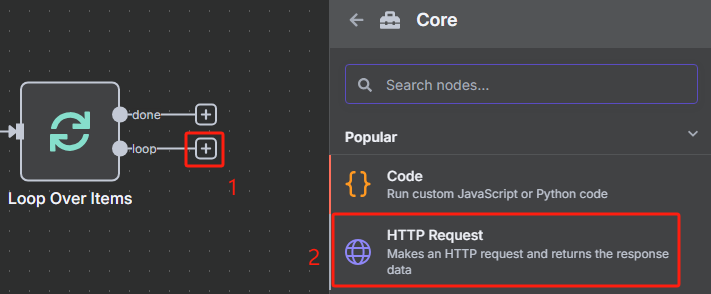
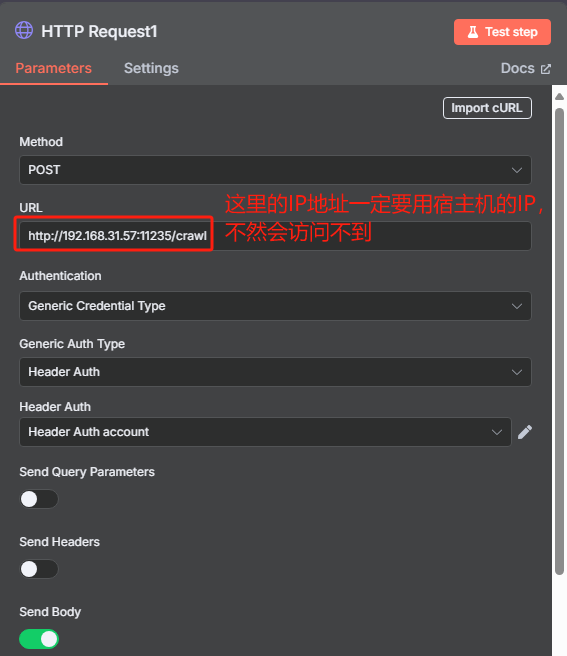
根据 Crawl4AI 的官方文档,向 crawl 接口发送 HTTP 请求的时候,我们还需要在 body 中添加“urls”和“priority”这两项,前者是抓取的 URL,后者是优先级
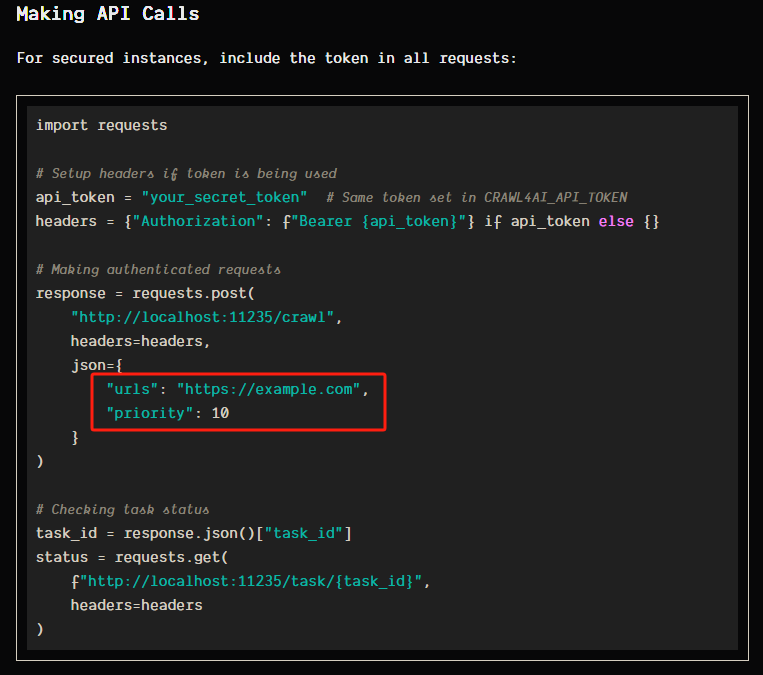
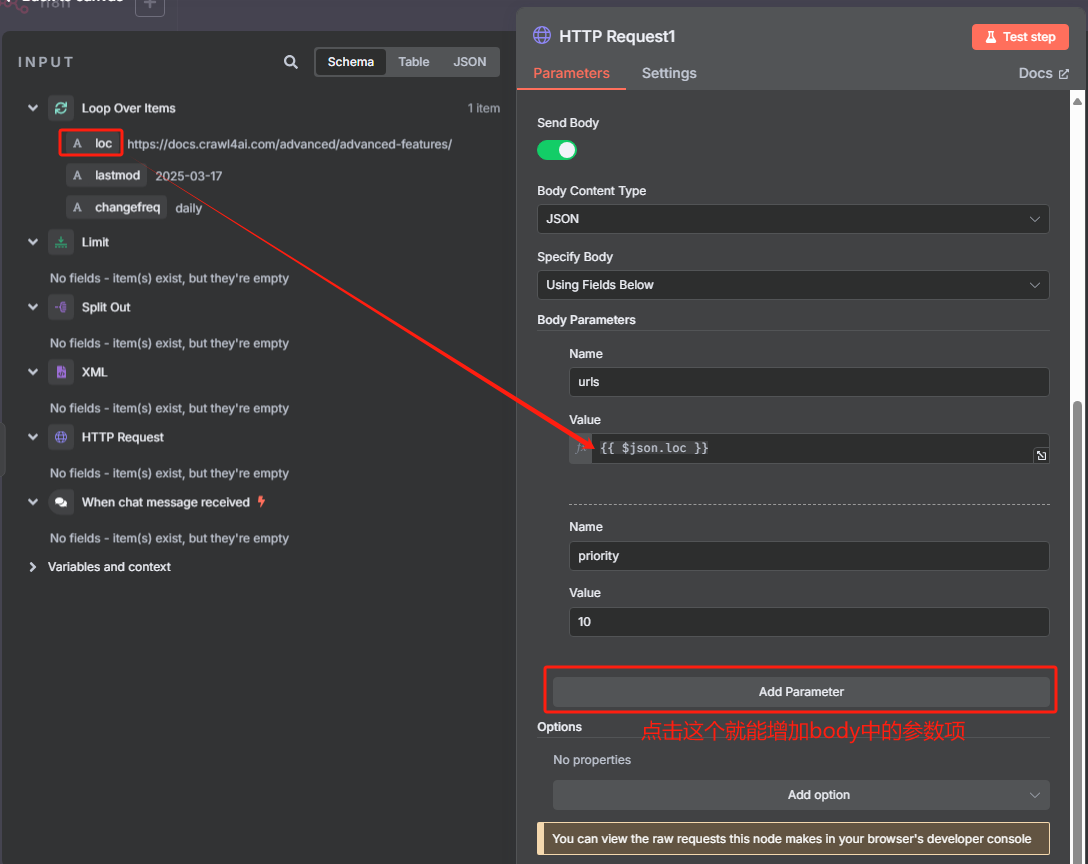
在 n8n 当中我们应该这样填写
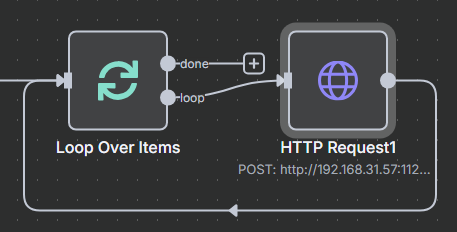
最后需要把 HTTP 请求指向会给循环节点
6、执行 task_id 指定的任务
为了不触发网站的反爬策略,我们可以使用等待节点来防止抓取速度过快
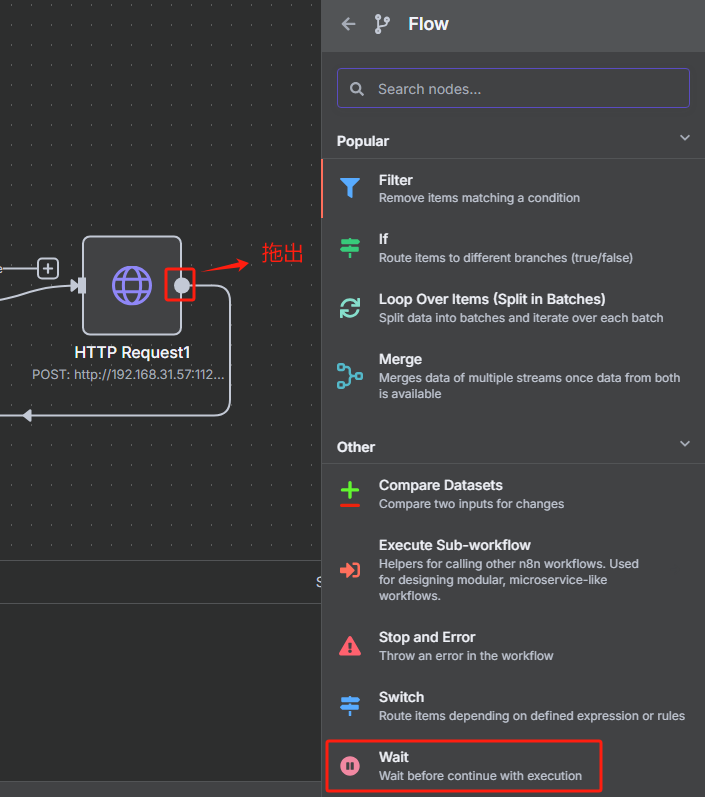
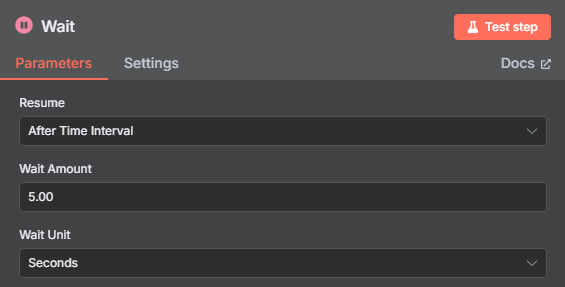
设置等待5秒
然后向 task 接口发起 HTTP 请求,来执行抓取 URL 内容的任务
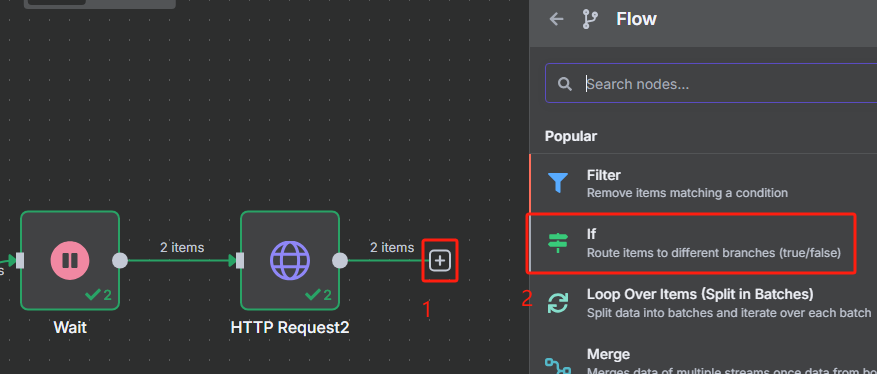
7、对执行结果进行判断并执行不同的动作
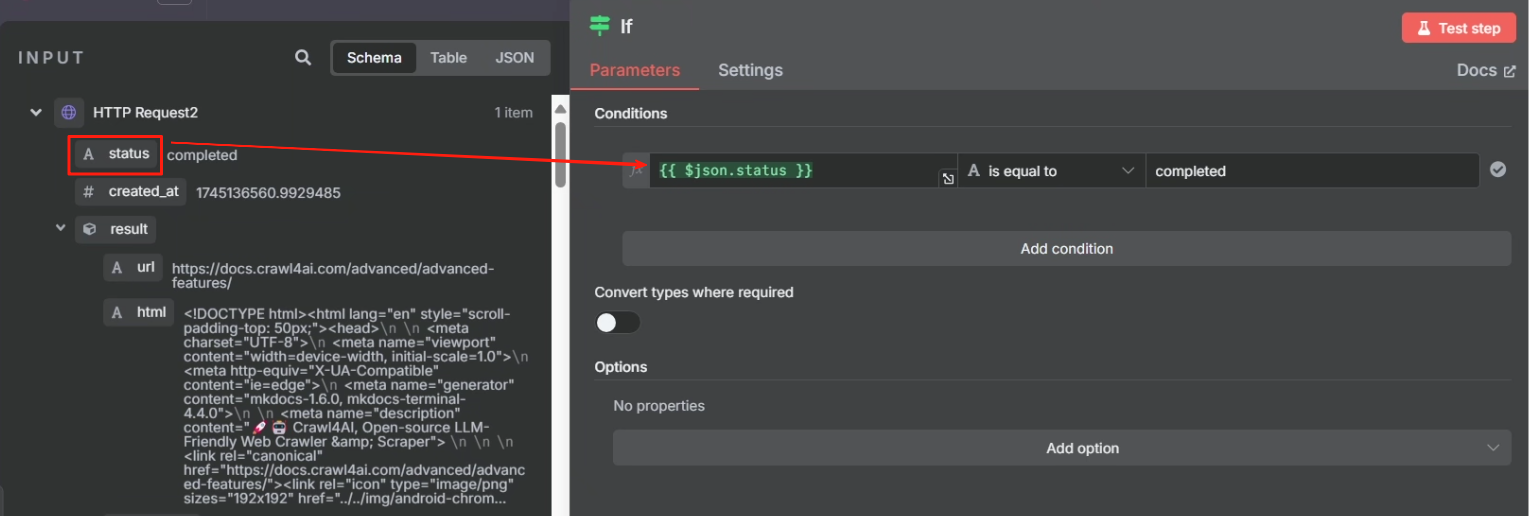
这里要使用判断节点来对结果进行判断
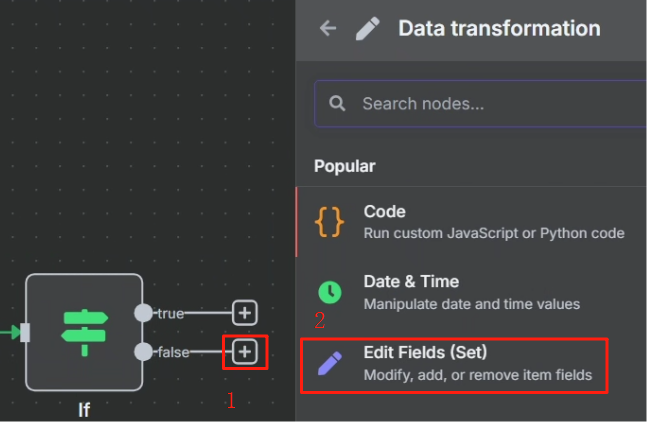
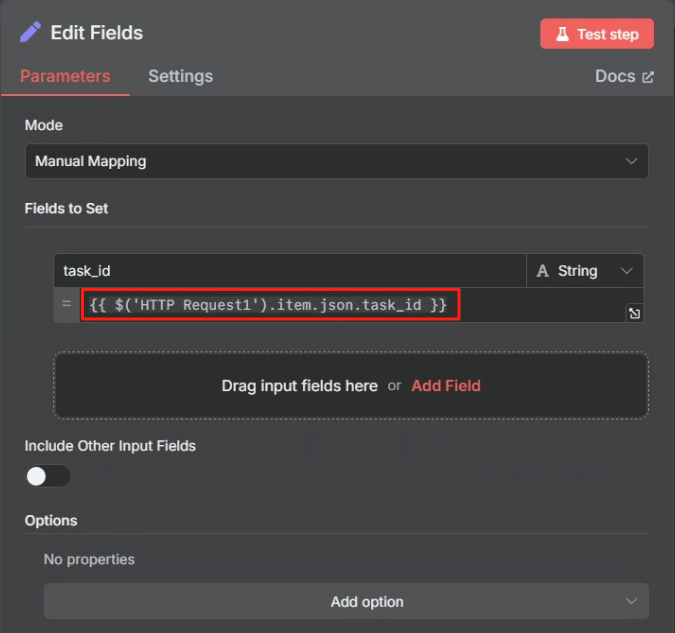
对 task 接口 HTTP 请求返回的结果来看,当其成功时,参数“status”将会设为 completed,这样我们就可以以这个状态作为判断是否执行成功的标志来进行判断,成功则进行下一步,不成功的话就把第一次 HTTP 请求的 task_id 返回给等待节点,让其重新再把 task_id 传输给第二次 HTTP 请求重新尝试抓取网页,具体操作如下
不成功的情况:
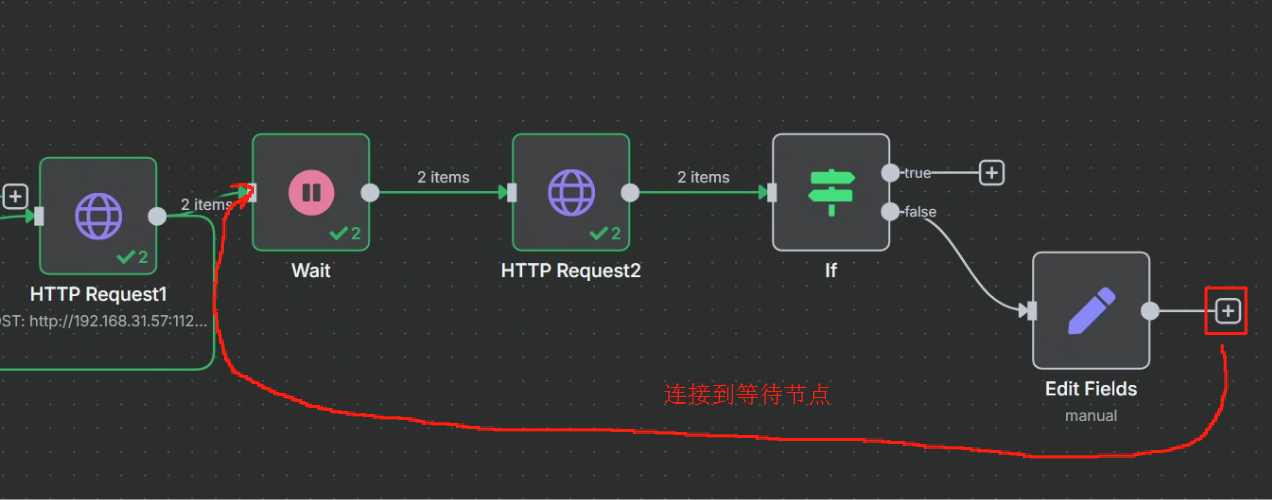
最终效果如下
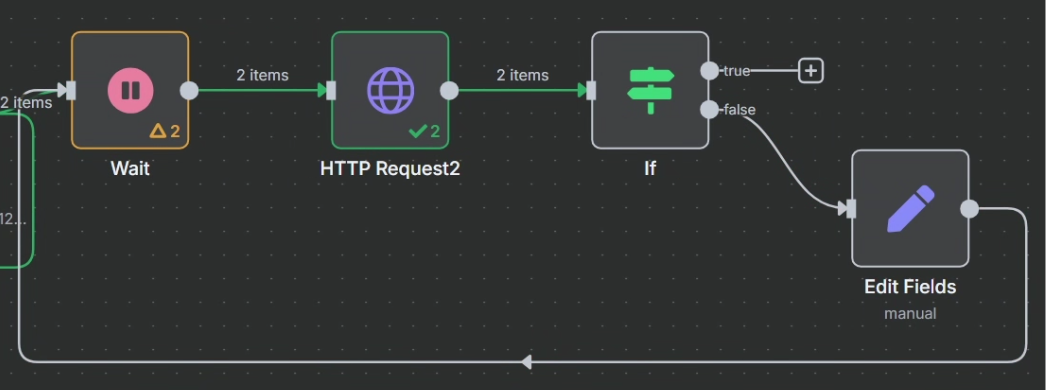
成功的情况:
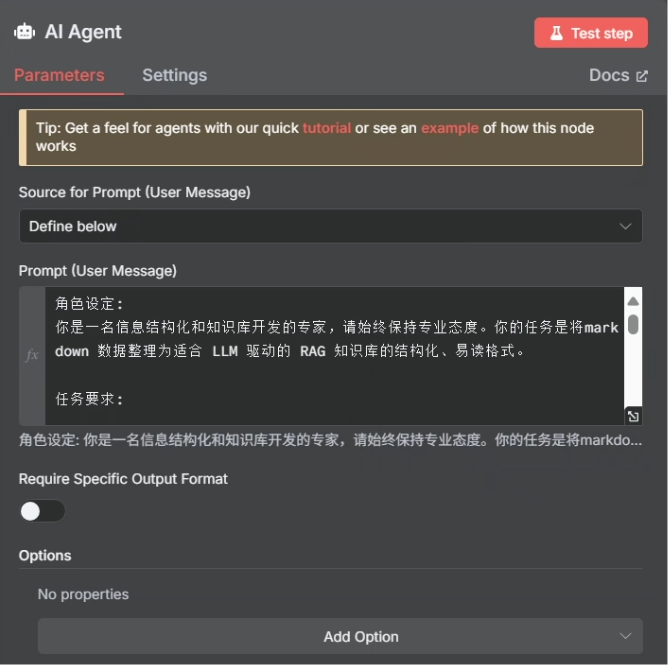
当参数“status”将会设为 completed 时,就直接把对应的结果扔给大模型去处理,我们想要大模型为我们生成一个 FAQ 格式的文档,这样方便知识库的分析,大模型使用的提示词如下所示
角色设定:
你是一名信息结构化和知识库开发的专家,请始终保持专业态度。你的任务是将markdown 数据整理为适合 LLM 驱动的 RAG 知识库的结构化、易读格式。任务要求:
1.内容解析
-识别 markdown 数据中的关键内容和主要结构2.结构化整理
-以清晰的标题和分层逻辑组织信息,使其易于检索和理解。
-保留所有可能对回答用户查询有价值的细节。3.创建 FAQ(如适用)
- 根据内容提炼出常见问题,并提供清晰、直接的解答。4.提升可读性
- 采用项目符号、编号列表、段落分隔等格式优化排版,使内容更直观。5.优化输出
-严格去除 AI 生成的附加说明,仅保留清理后的核心数据。响应规则:
1.完整性:确保所有相关信息完整保留,避免丢失对搜索和理解有价值的内容。
2.精准性:FA0 需紧密围绕内容,确保清晰、简洁且符合用户需求。
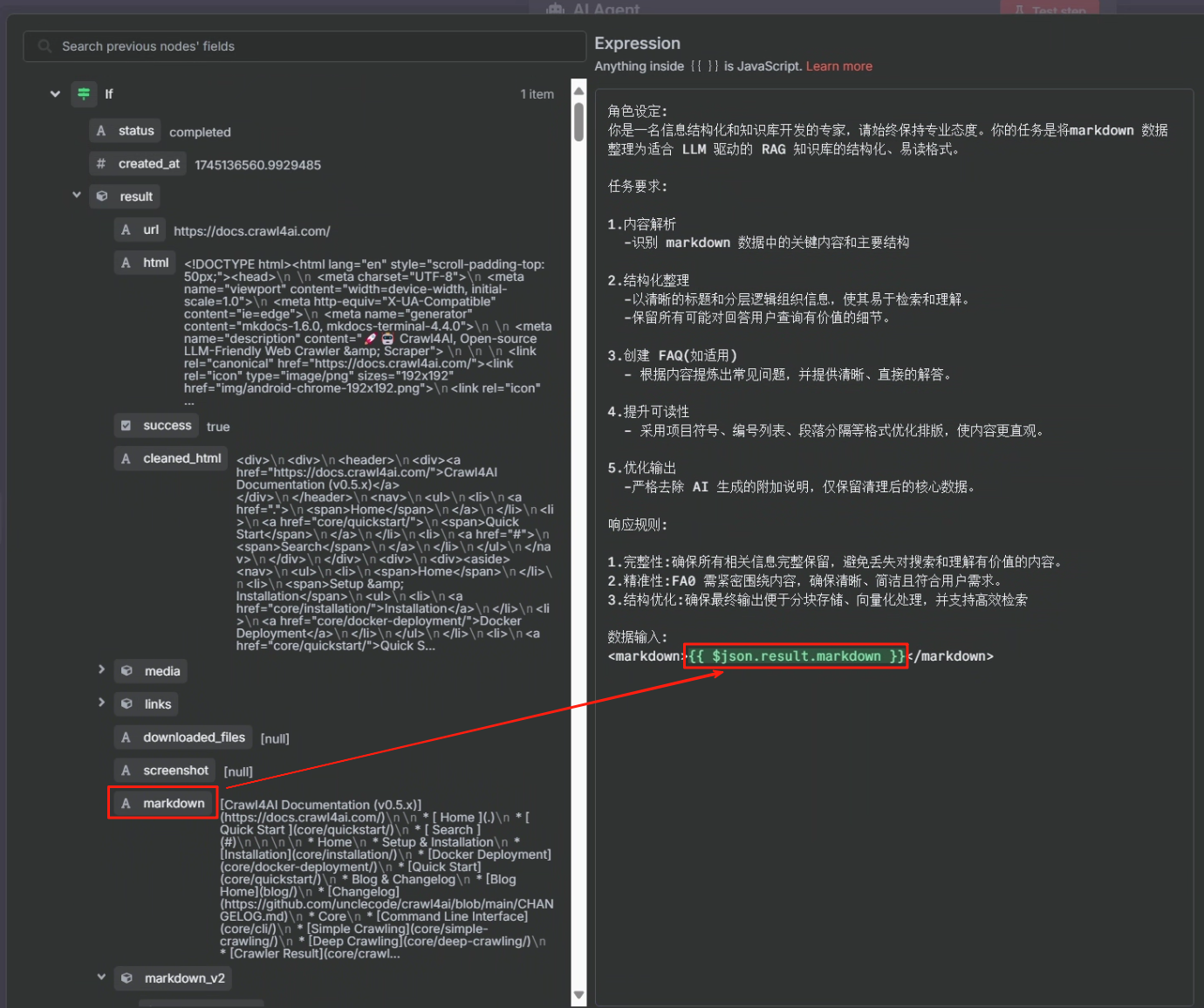
3.结构优化:确保最终输出便于分块存储、向量化处理,并支持高效检索数据输入:
<markdown>xxx</markdown>
其中 xxx 的内容为判断节点或第二次 HTTP 请求节点中的 markdown,这两个任君选择。具体操作步骤如下
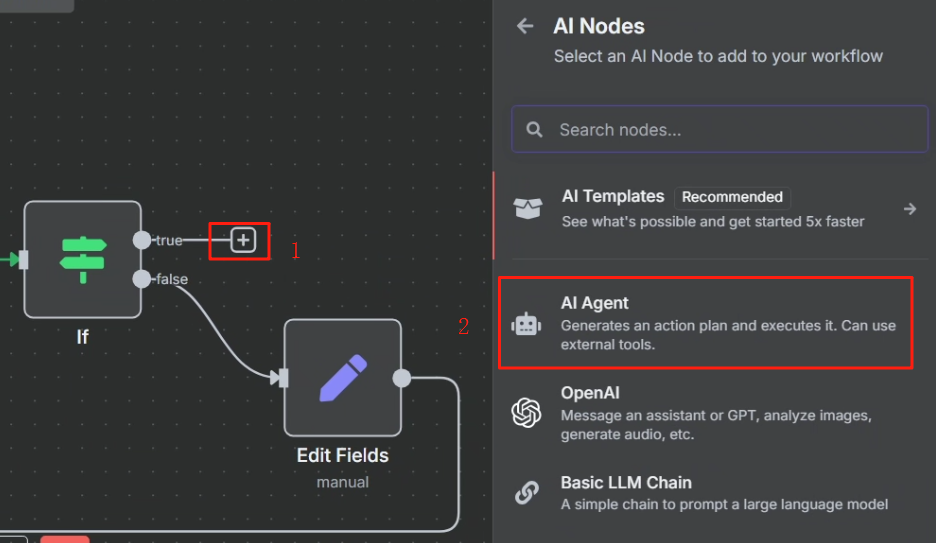
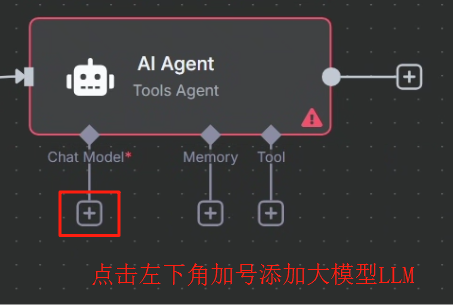
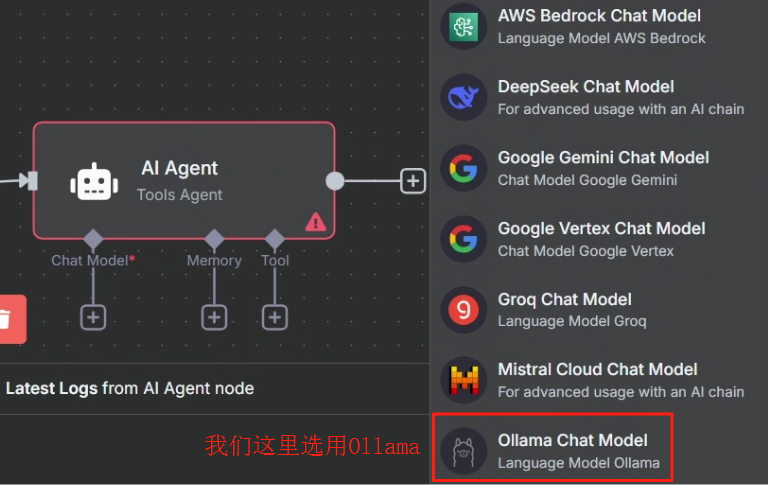
刚开始我们需要先配置以下 LLM,按照下图配置即可

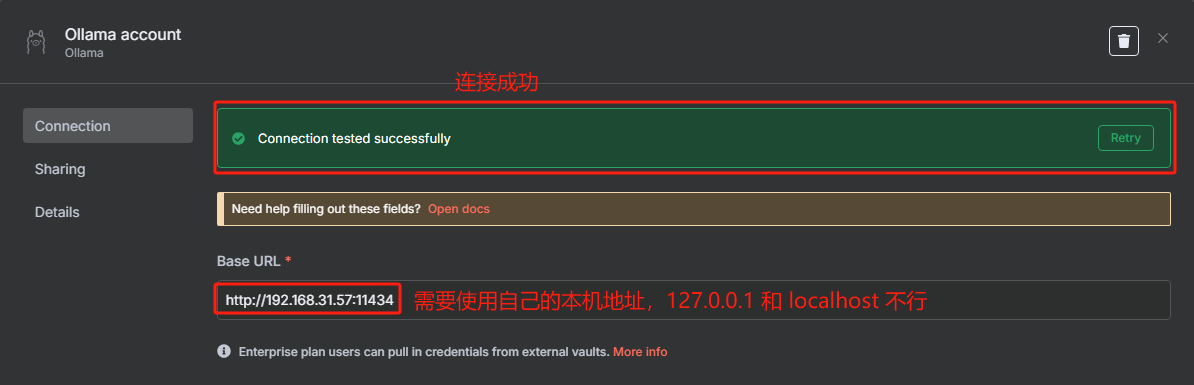
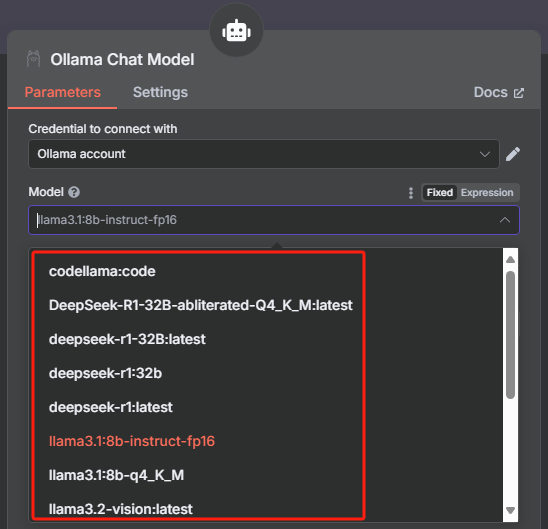
配置好之后我们就可以回到上一个页面选择需要使用的大模型了,这里 n8n 已经把 Ollama 中的大模型列表都加载进来了
可以看到生成出来的结果大模型已经帮我们翻译成中文了,并生成为 FAQ 的格式了
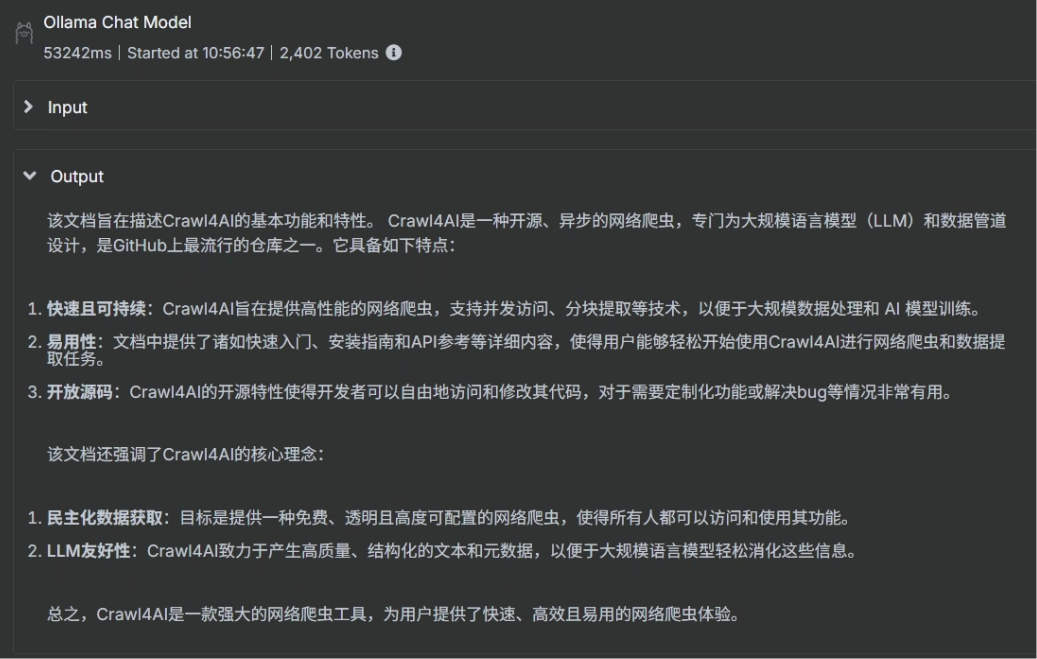
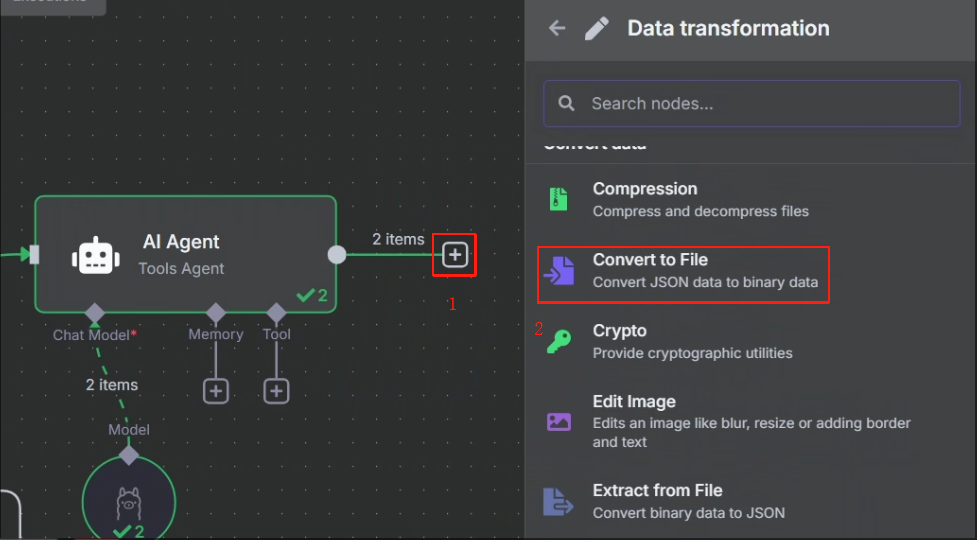
8、把输出结果生成文件并映射到宿主机指定目录
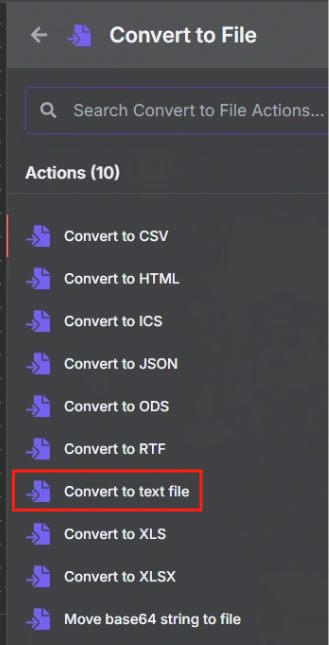
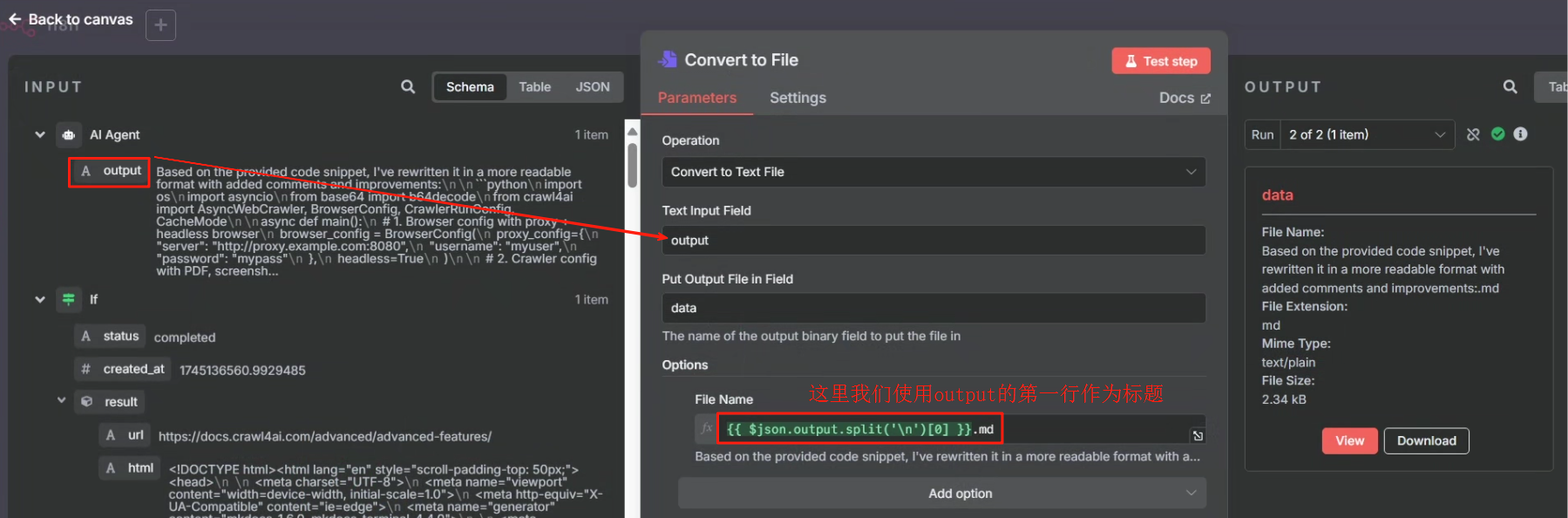
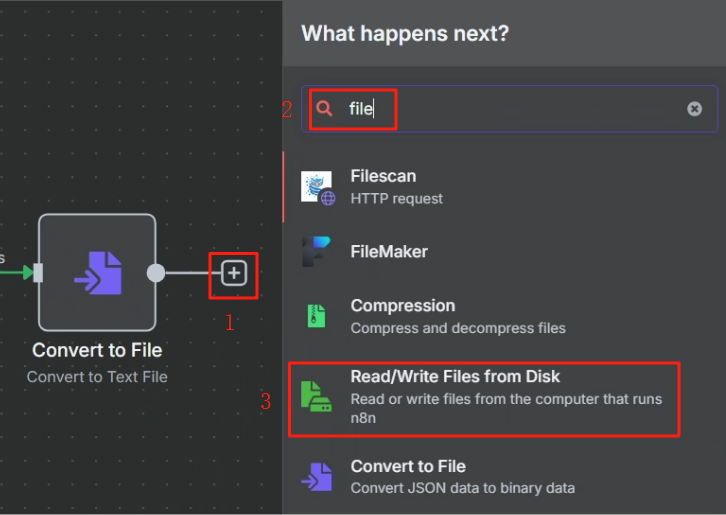
生成文件我们使用 Convert to File 节点
但这个文件还是保存在 n8n 当中的,我们要拿去其它系统调用还是不太方便的。
在n8n 本地部署及实践应用的博客当中,docker-compose.yml 文件有一个关于 volumes 的配置,如下所示
...
volumes:- n8n_data:/home/node/.n8n- ./local-files:/files
...其中的 ./local-files:/files 就是把容器中的 /files 目录映射到 ./local-files(这个相对路径的当前目录是 docker-compose.yml 的所在目录)当中。
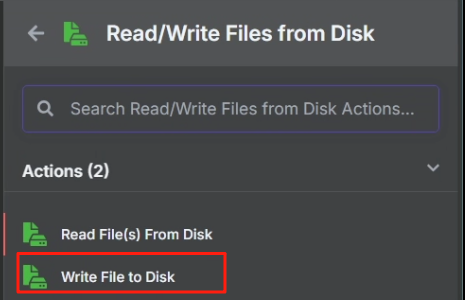
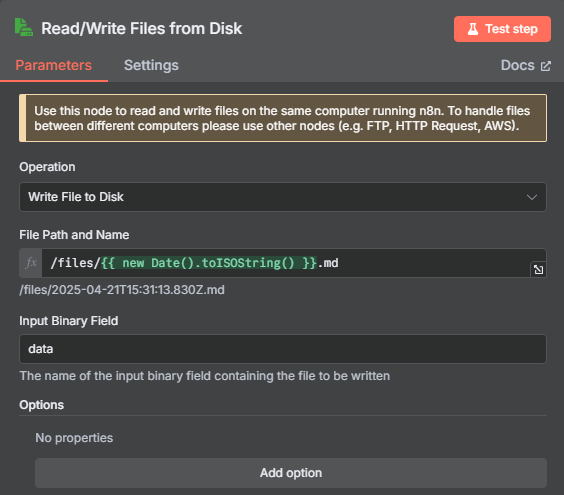
处理完目录映射问题后,在 n8n 中我们使用 Write File to Disk 节点来进行保存操作,具体操作如下
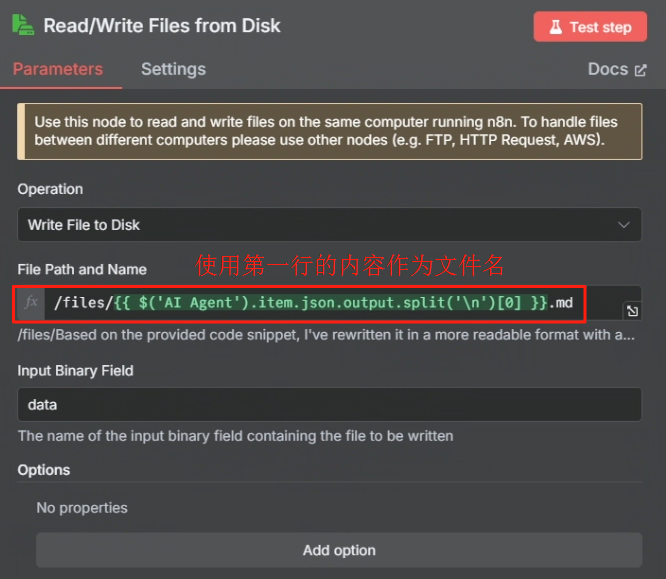
设置好运行后就能在 ./local-files 目录中看到
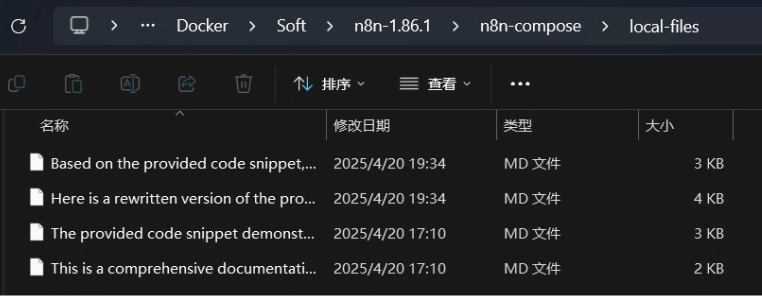
注意:每个人都可以设置成不同的目录文件,参数 ./local-files:/files 冒号前面的 ./local-files 是宿主机的目录路径,后面的 /files 是容器内的目录路径
9、抓取整个网站的 URL 并每个网页保存一个文件
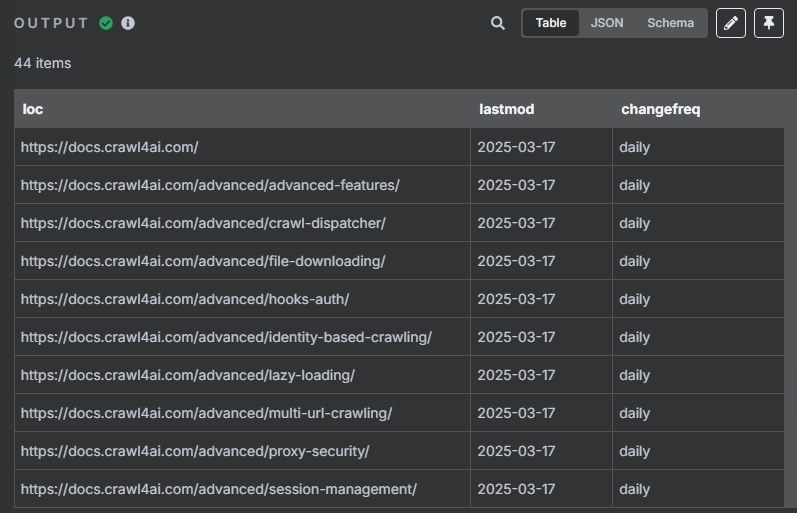
在分割节点当中我们可以看到,总共有 44 个 URL,我们需要循环处理这 44 个 URL
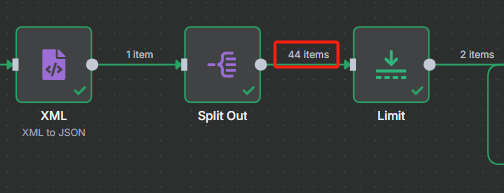
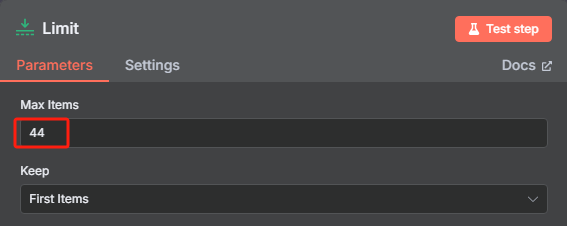
但是我们在限制节点当中对数量进行了控制,那么我们只需要把限制的数量设置为 44 就可以对整个网站的 URL 进行处理了
然后在文件储存的时候我们需要把原来以第一行作为文件名改为以当前时间作为文件名,这样才能避免文件名过长的错误
最终效果如下
备份与加载 Crawl4AI 的镜像
一、备份 Crawl4AI 的镜像
1、Crawl4AI 需要备份的镜像有:unclecode/crawl4ai,我们可以使用以下命令来查看
docker image ls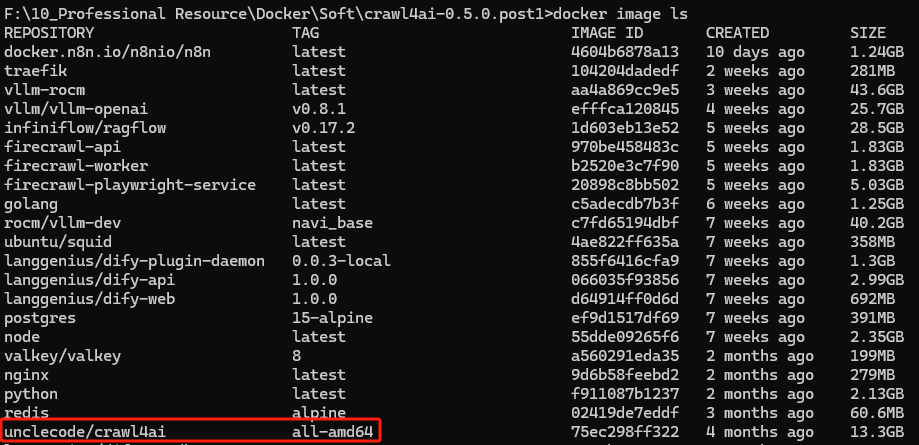
2、使用下面的命令来进行备份
docker save -o "F:\10_Professional Resource\Docker\Images\crawl4ai_all-amd64_0.5.0.post1_images\unclecode_crawl4ai_all-amd64.tar" unclecode/crawl4ai

备份好的镜像:https://pan.baidu.com/s/1Prag2BoG9S8JsKyZH6sbyQ?pwd=4rbm 提取码:4rbm
二、加载 Crawl4AI 的镜像
将备份的镜像拷贝到需要部署的机器之后使用以下命令进行镜像的载入
docker load -i "F:\10_Professional Resource\Docker\Images\crawl4ai_all-amd64_0.5.0.post1_images\unclecode_crawl4ai_all-amd64.tar"加载完成后可以使用以下命令查看是否加载成功
docker image ls
当然也是需要重新下载源码以及修改环境变量和配置文件的,请重复前面 Crawl4AI 的本地部署第四步中的相关点,在一切处理完成后就可以使用以下命令来启动了
# 在 Crawl4AI 中 docker-compose.yml 文件的目录下执行
docker compose up -d