BBRv2,v3 吞吐为什么不如 BBRv1
为什么 BBRv2/3 测试下来吞吐远不如 2016 年底的 BBRv1,这个事曾经提到过很多次,今天分析一下原理。注意三个事实:
- BBR 是一种拥塞控制算法;
- BBR 已经迭代到了 v3 版本;
- BBRv3 的 “性能” 远不如 BBRv1.
第二点有点不可思议,一般而言,不存在版本越新性能越差的,如果有,一定是 bug,但对于 BBR 却是不争的事实。到底发生了什么?
如果你不知道拥塞控制算法的性能意味着什么,建议先去了解,这里不赘述。从一篇有趣的论文开始本文:BBR vs. BBRv2: A Performance Evaluation.
摘要部分最后几句:
Our results suggest that BBRv2 trades performance for better fairness under losses. To bridge this gap, we investigate the workings of BBRv2 and find that BBRv2 employs a long-term upper bound on sending rate that is not robust to losses. This upper bound is continually decremented in the presence of persistent losses, thereby depressing goodput. We show that by aligning BBRv2’s upper bound with its maximum bandwidth estimation, BBRv2’s performance can be greatly improved while maintaining its fairness.
好家伙,还好只 aligning 了 upper bound,要是连 lower bound 也给 aligning 了,差一点就回退到 BBRv1 了。后面会分析到,upper bound 越大,吞吐越高,但必然以公平性为代价,若将 upper/lower bound 全取消,吞吐达到最优,公平性全无,因此这篇论文其实什么都没说,就是滑动了一下滑杆,展示了这个交易。
BBRv2/3 增加这两个 bound 的目标就是解决公平性问题,细节还得看 BBR Congestion Control(IETF-Draft):
BBR.inflight_hi(upper bound): The long-term maximum volume of in-flight data that the algorithm estimates will produce acceptable queue pressure, based on signals in the current or previous bandwidth probing cycle, as measured by loss. That is, if a flow is probing for bandwidth, and observes that sending a particular volume of in-flight data causes a loss rate higher than the loss rate objective, it sets inflight_hi to that volume of data. (Part of the long-term model.)
BBR.inflight_lo(lower bound): Analogous to BBR.bw_lo, the short-term maximum volume of in-flight data that the algorithm estimates is safe for matching the current network path delivery process, based on any loss signals in the current bandwidth probing cycle. This is generally lower than max_inflight or inflight_hi (thus the name). (Part of the short-term model.)
BBRv2/3 遵循下列逻辑来调整 upper bound 和 lower bound:
// upper bound 在 ProbeUP & Refill phase 调整
loss_too_high_in_ProbeUP & Refill:inflight_hi = max_t(in_flight, bdp * (1 - beta);// lower bound 在 ProbeUP & Refill phase 之外调整
any_loss_except_ProbeUP & Refill:inflight_lo = max_t(max_inflight_latest, inflight_lo * (1 - beta);
用 (1 - beta) 兜底是为了 “ ensure that BBR does not react more dramatically than CUBIC’s 0.7x multiplicative decrease factor.”
long-term upper bound 维持 AIMD 周期间与 reno/cubic 的公平性,short-term lower bound 维持 AIMD 周期内与 reno/cubic 的公平性,如下图所示:
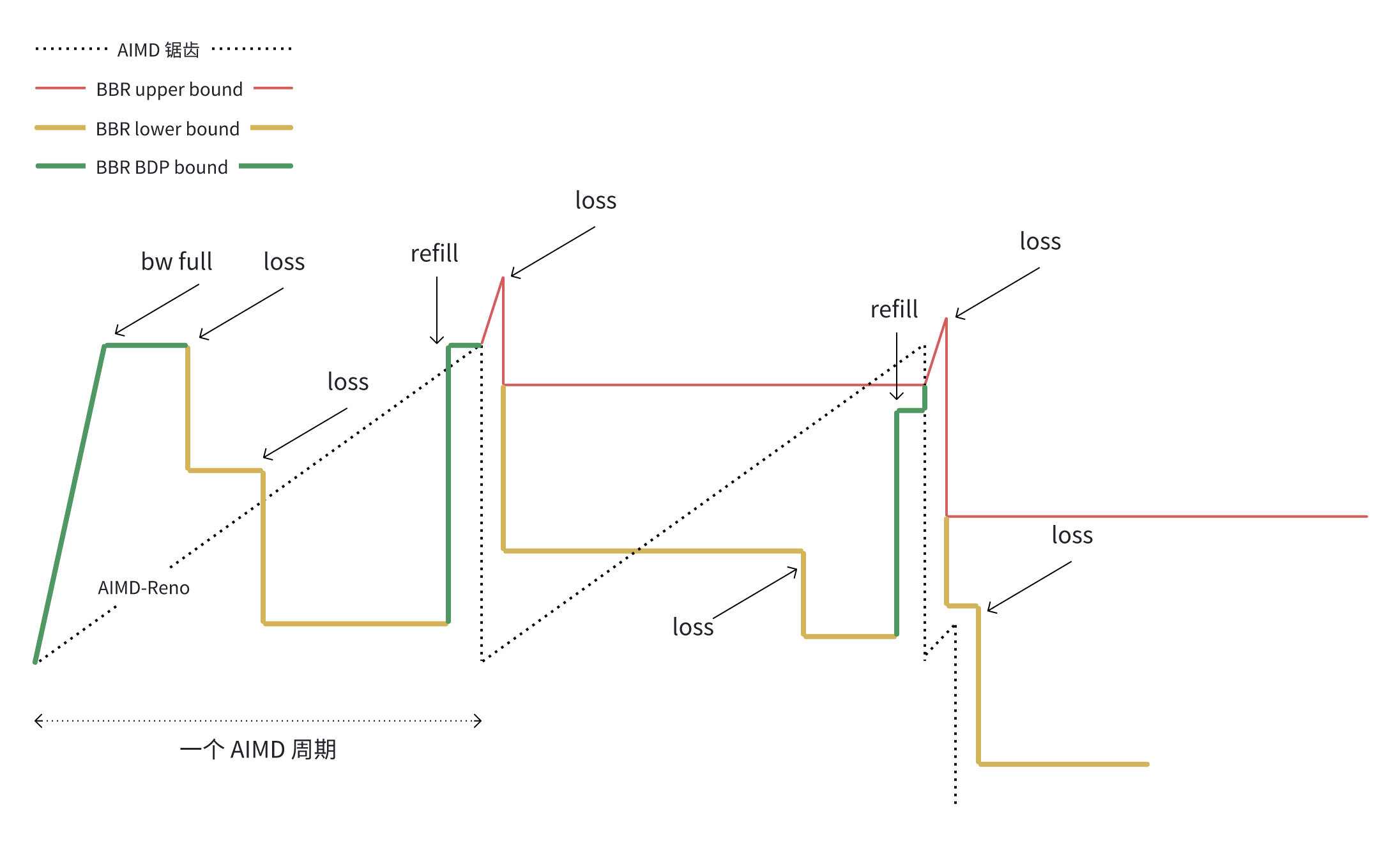
就解释一句,红绿黄线下的面积是一个 cycle 内 BBRv2/3 的传输总量,它对应一个 AIMD 周期内虚线下面的面积,肉眼可见,大差不差,这就是所谓 “对 reno/cubic 的公平性”。
ProbeUP phase 是个受 loss_thresh 约束的指数增加 upper bound 的逻辑,期间,任何丢包率越过 loss_thresh 均将对 upper bound 进行 mutiplicatively decrease,整个 cycle 中只要发现比 upper bound 更大的实际 inflight,都会更新 inflight_hi,比如 ProbeUP 时的随机丢包导致 loss_thresh 越界而 upper bound 被削减,后续的 cwnd_gain 将可能填充更大的 inflight。
注意,loss_thresh 越界时,只在 refill,ProbeUP phase 才更新 upper bound,因为 cruise 默认已在 drain phase 后完成适配 maxbw,minrtt 这个操作点了。
可见,BBRv2/3 除却 BBR 状态机就是一个 cwnd-based reno/cubic,因此有两个结论:
- 在丢包率高于 loss_thresh 场景,BBRv2/3 维持与 reno/cubic 之公平性,吞吐跌落至与之持平;
- 在丢包率低于 loss_thresh 场景,BBRv2/3 获得比 reno/cubic 更大的吞吐,提高了带宽利用率。
虽说 BBRv2/3 采用了指数增加 upper bound 的方式,但为了和 reno/cubic 一致,BBR 确保在一个和 reno/cubic AIMD 周期一致的 cycle 内维持 upper bound 稳定(前面提到取实际 inflight 更新 inflight_hi 以对抗随机丢包的技巧不在此约束内)而不再 ProbeUP,和 AIMD 零存整取不同,BBRv2/3 相当于整存整取。
BBRv2/3 PROBE_BW 的一个 cycle 确定为一个典型的 reno/cubic 流的 AIMD 周期,约 2s,或者动态设置为 BDP 个 round,因为一个 AIMD 周期就是 cwnd_max 个 round。
看这篇论文中展示 BBRv2 在丢包率 2% 下吞吐陡降的图示:
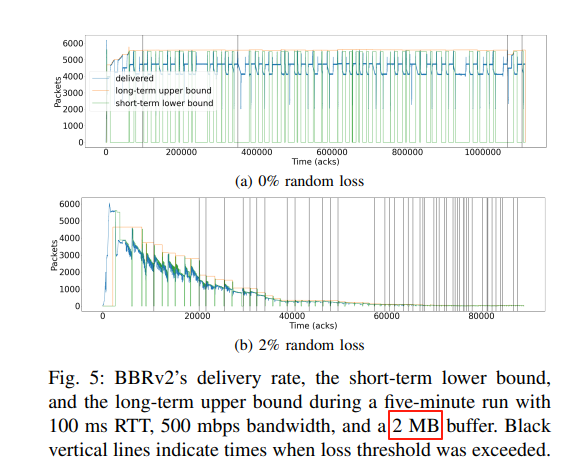
2MB buffer,以 1KB mss 算,一共就是 2000 个段,按照 AIMD 理论,丢包率即 1/2000,相比 2% 的丢包率要低 40 倍,由 reno 吞吐公式可知其吞吐要高 根号 √40 倍,约等于 6.3,从图上可见,inflight 理论上跌落到 5500*0.85/6.3 = 742,从图上看,大差不差。
再看 BBRv1 论文中抗丢包的广告图(BBR 可容忍 20% 丢包,相比之下,cubic 连 1% 都容忍不了),若 long-term/short-term bound 均不受限(BBRv1 无 upper bound 约束),BBR 可支撑 20%+ 丢包率(解方程求出 gain = 1.25 时的最大丢包率),单独 short-time bound 限制在均匀丢包的 reno/cubic 共存场景亦碾压 reno/cubic,因此 BBRv2/3 的实际吞吐低的原因是其 long-term bound 即 upper bound 不断被丢包压制却鲜有上升导致。
因此,想提高吞吐的方案就摆在眼前了:
- 要么升高 inflight_hi;
- 要么升高 loss_thresh。
但如论文所示,如此做法肯定损害了对 reno/cubic 的公平性,它的结论很明显,如此修改对原生 BBRv2/3 而言提高了吞吐,而对 BBRv1 而言提高了公平性,好一个田忌赛马。这个结论意味着,BBRv2/3 基本锁死了吞吐和公平性的权衡,顾此失彼,不可兼得。
值得再次强调,当丢包率低于 loss_thresh = 2% 时,Probe_UP 不受阻碍,BBRv2/3 相对 reno/cubic 还是有很大吞吐优势。BBRv2/3 与 reno/cubic 共存的宗旨就是,有难同当,有福独享。
因此,BBRv2/3 吞吐不如 BBRv1 并非问题,而是特性,它并非论文指数的那样,long-term bound inflight_hi 无法涨回去,虽然 short-term bound 确实会传递给 long-term bound,但正如其名字所表达,影响也只是 short-term,一旦丢包消除,long-term bound 下一个 cycle ProbeUP 时有自己的增长逻辑,即使在当前 cycle,由于 short-term bound inflight_lo 在 ProbeUP 和 Refill phase 不起作用,这两个 phase 的 loss_thresh 越界虽 cut 了 inflight_hi,但若真的只是随机丢包越界,在 cruise phase 靠 cwnd_gain 造成 inflight 超过 upper bound,仍可递增 long-term bound。论文所下的结论,仅在其假设丢包率 2% 均匀分布(而不是随机突发丢包)的场景有效。
若真要用通用方法提高吞吐,更好的做法是在 Cruise phase 只要不丢包就 additive increase upper bound,这最终就类似 BBR 旁路 cugas(cubic + vegas) 或 vebic(vegas + cubic) 了(or hybla?)。
如果想在模拟仿真环境(特别是 tc netem,mininet 这些玩意儿模拟一个固定的均匀丢包率)忽悠经理,让经理看到吞吐碾压原生算法的效果而获得加薪晋升机会,我的方法就非常有用。因为绝大多数干这行的,证明给经理看或者写论文的环境都是这类仿真环境,模拟均匀丢包,连 4-state 都不会(参见 揭露 BBR 的真相 最后部分)。
浙江温州皮鞋湿,下雨进水不会胖。