RSUniVLM论文精读
一些收获:
1. 发现这篇文章的table1中,有CDChat ChangeChat Change-Agent等模型,也许用得上。等会看看有没有源代码。
摘要:RSVLMs在遥感图像理解任务中取得了很大的进展。尽管在多模态推理和多轮对话中表现良好,现有模型在像素级理解上存在不足,在处理多图像输入时也面临困难。RSUniVLM有变化检测和变化描述任务。为了增强模型在不同层次捕获视觉信息的能力,同时不增加模型体积,我们设计了一种名为“粒度导向的专家混合”(Granularity-oriented Mixture of Experts)的新架构,模型参数大约10亿。我们还构建了一个大规模的遥感指令跟随数据集,该数据集基于遥感和通用领域的多种现有数据集,涵盖了目标定位、视觉问答和语义分割等多种任务。
引言:随着llms的出现,很多领域显著发展,通过配备视觉编码模块,lvlms(large vlm)将llm的能力扩展到了通用视觉和语言理解,一个突破性的工作是llava,它在多模态对话数据上微调,展示了出色的视觉聊天能力。为了支持广泛的视觉任务,随后的研究工作尝试通过各种方式开发lvlm的潜力,包括利用更大规模的和更高质量的指令微调数据,设计更高效的微调方法(qa-lora),以及采用新的llm架构(moe)。此外,一些研究试图将多模态感知和生成任务统一起来,采用任务特定的头部进行处理。「感知任务:检测 分割 分类定位 问答等。生成任务:图像生成文本(描述) 图生图 文生图。把这两类任务统一起来意味着一个模型。底层共享同一个视觉语言backbone,针对不同的任务(分类 分割 问答)最后加上不同的结构进行任务输出。比如分类的head是softmax分类器,分割head是卷积结构输出pixel-wise label,文本生成是一个语言模型头用来生成文字。」通用lvlm在常规领域表现好,但是在rs领域不行,因为rs图像和自然场景图像差异大。为了弥合这差距,提出了几种大规模rs图像-文本对数据集和指令微调数据集。然而现有的rs领域的lvlm,还是仅限于图像级和区域级,缺乏像素级理解,无法处理语义分割这样的任务。为了解决上述问题,本文提出了一个统一的框架RSUniVLM,是首个支持图像级、区域级和像素级理解与推理任务的rs专用视觉-语言模型,并且具有多图像分析能力。
RSUniVLM在像素级理解和多图像分析方面扩展了RS领域的视觉-语言模型。采用Text4Seg方法,把语义分割的mask结果转成一句描述性的文字,让语言模型可以“说出”分割的结果,从而统一所有任务为“文本生成任务”。「语言的形式表示mask: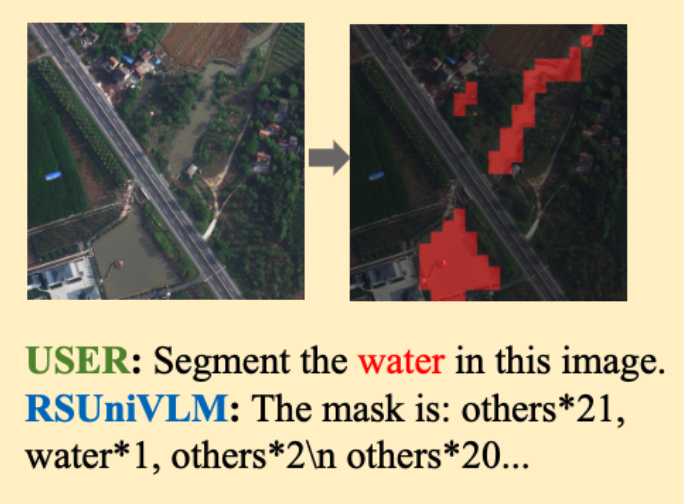 」
」
相关工作
通用vlm就不说了
RS vlms有很多,包括rsgpt geochat lhrs-bot skyeyeGPT change-agent和changechat等。rsUniVLM是对个统一的遥感视觉-语言模型,能处理 图像级 区域级和像素级 且是端到端的。
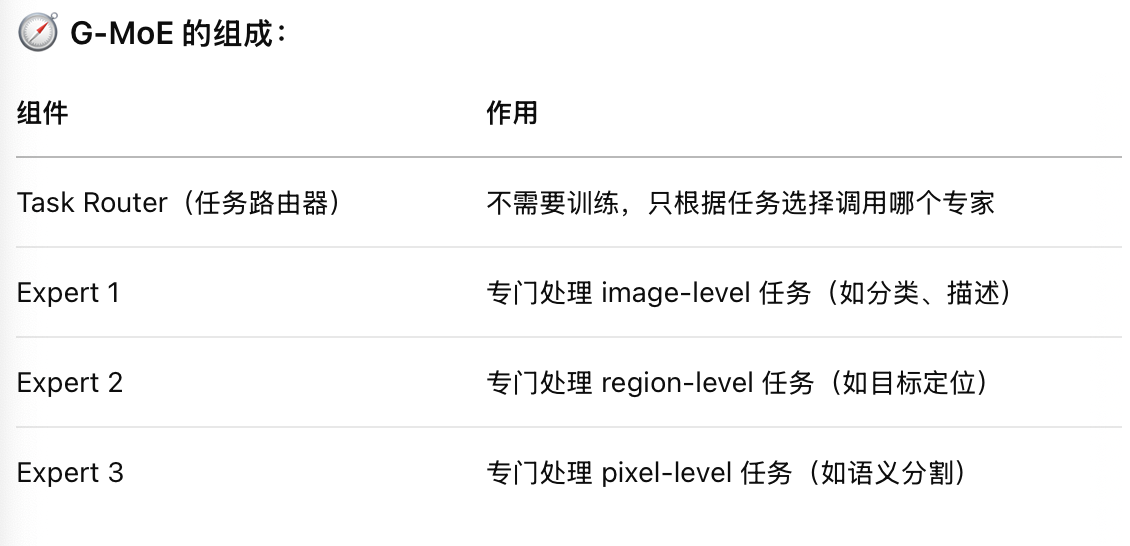
moe(mixture of experts) 主要由两个组件组成 专家层和路由器,输入的计算不会全部由一个固定的模型处理,而是通过路由器来选择不同的专家处理不同的输入。在这项工作中,作者提出了一种新的稀疏 Granularity-oriented MoE 架构,旨在 提升多模态理解能力。这种架构在 MoE 基础上进一步创新,专注于不同粒度的任务(例如 图像级、区域级 和 像素级):
-
粒度导向(Granularity-oriented): MoE 专家不再仅仅根据输入类型来分配,而是根据任务的粒度(例如,高层次的图像分类和低层次的像素分割)来选择相应的专家进行处理。
-
稀疏(Sparse): 这种新架构是稀疏的,即 并非所有专家都参与计算,只有最相关的专家会被激活,从而减少计算量。
方法描述
模型设计:该模型遵循常见的llava风格框架的设计范式,主要包含四个关键组件 图像编码器、文本嵌入层、多层投影器(mlp)、大语言模型llm。对于具有多张图像的输入,我们使用共享权重的图像编码器分别提取每张图像的特征,然后直接在嵌入维度上将它们拼接。「就是说 输入多张图像的时候 用同一个image encoder来提取特征,这个图像编码器的权重是共享的。在提取完每张图像的特征向量后,将它们连接在一起,拼成一个大向量。当输入图像数量不同导致拼接后的向量维度不同时,模型会通过填充或池化,将不同向量维度变成相同的。」
统一表示:我们将所有任务都转化为 仅文本生成任务,包括对象定位和分割。视觉定位和指代表示生成的边界框都是标准化为0-100之间的整数,并以文本格式表示[x1, y1, x2, y2]。对于mask生成的任务,用Text4seg方法。
基于粒度的专家混合(g-moe):三个粒度,图像级、区域级、像素级。为了有效整合这些专家,采用了一个无训练的门控机制(gating mechanism)。该机制根据输入数据的特点将输入提示分配给特定的专家,确保模型响应既能考虑上下文又能高效执行。
训练策略:两阶段的从粗到细训练策略:首先进行多任务的预训练阶段,然后通过精细调优阶段进一步提高模型。第一阶段:全参数微调,将遥感领域的知识注入预训练的视觉语言模型中。为了创建一个强大的指令跟随数据集,我们整合了十五个不同的公共数据集,涵盖遥感领域的五个不同任务,并将其转换为结构化的指令跟随集合,使用手工编写的模版。还引入了部分来自rs和通用领域的高质量指令集。这一阶段,g-moe层还没引入到llm中,因此模型重点集中在基础的对齐任务上。第二阶段:我们通过重复三次ffn层(前馈网络feed-forward network 通常是个全连接层)来初始化专门针对不同类型遥感任务的专家。我们根据任务的粒度和多样性,从阶段1的训练集中选取了一小部分遥感特定的指令数据,用于进一步微调g-moe层。 这两个训练阶段的目标是相同的:通过逐步细化模型,增强其对不同任务的理解能力。
实验


局限性:
多轮对话能力较弱(可以更多更高质量多轮对话数据来改进)、无法执行生成任务如超分辨率和去雾。