卷积神经网络(二)
1 卷积运算的两个问题:
1.1 图像边缘信息使用少
边缘的像素点可能只会被用一次或者2次,中间的会用的更多。
1.2 图像被压缩
5*5的图像,如果经过3*3的卷积核后,大小变成3*3的。
N*N的图像,果经过F*F的卷积核后,大小变成(N-F+1)*(N-F+1)的。
为了解决这个问题,在边缘会增加像素。像素点增加多少,取决于卷积核的尺寸和滑动的步长。
2 CNN模型:
卷积层,池化层,展开层,全连接层,如何组合成一个有效的模型。这可以参考经典的CNN模型。
一种方法,是参考经典的模型来搭建自己的模型。另外一种方法,可以利用经典模型的部分模块对图像进行预处理,然后用处理完的数据搭建自己的模型。
2.1 LeNet-5
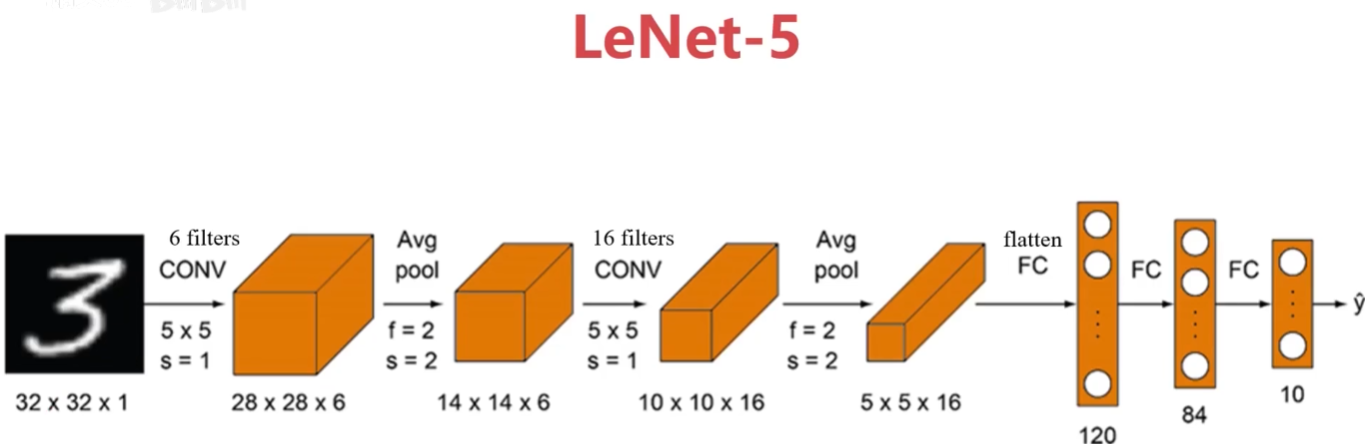
输入图像:32*32灰度图,1个通道
训练参数:约60000个
随着通道越来越深,图像尺寸变小,通道增多;卷积和池化成对出现
2.2 AlexNet-5
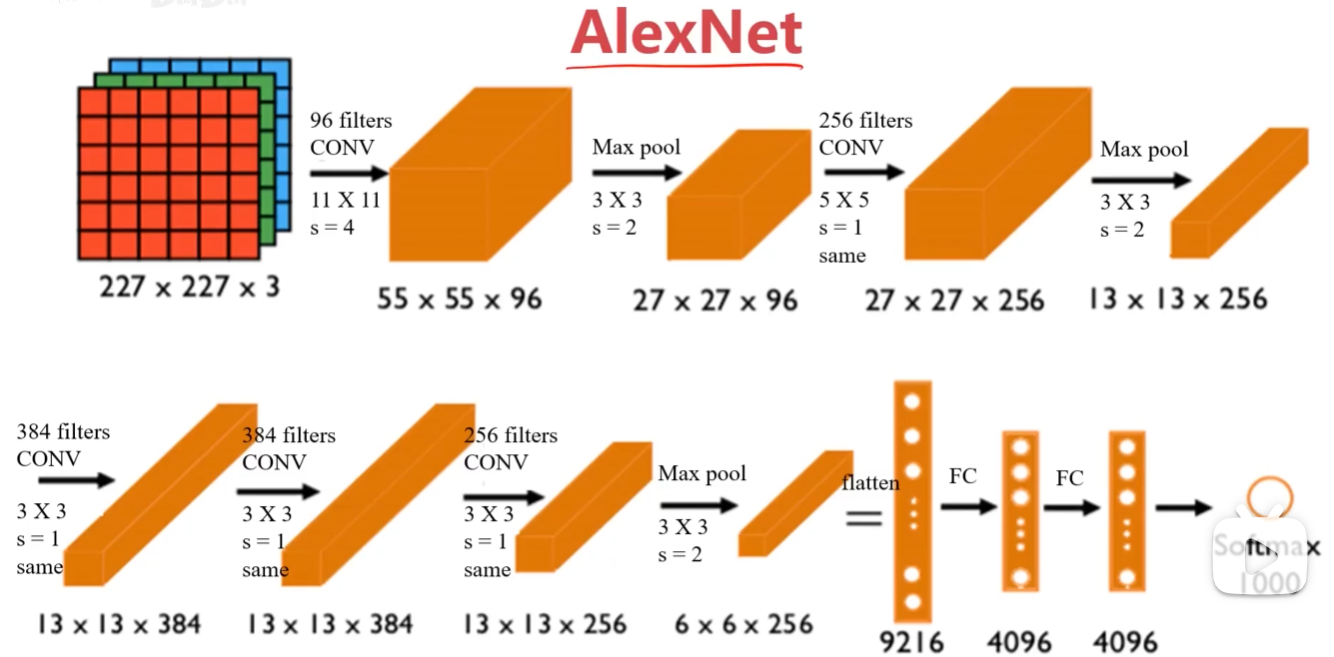
原始图像经过96个11*11的filter,步长为4变换成:(227-11)/4+1=55,图像变化成55*55*96
55x55x96经过3*3步长为2的池化变化成:(55-3)/2+1=27,图像变化成27*27*96
....
输入图像:227*227*3 RGB图,3个通道
训练参数:约60 000 000个
特点:
1 适用于识别较为复杂的彩色图,可识别10000种类别
2 结构比LeNet更为复杂,使用Relu作为激活函数
2.3 VGG16
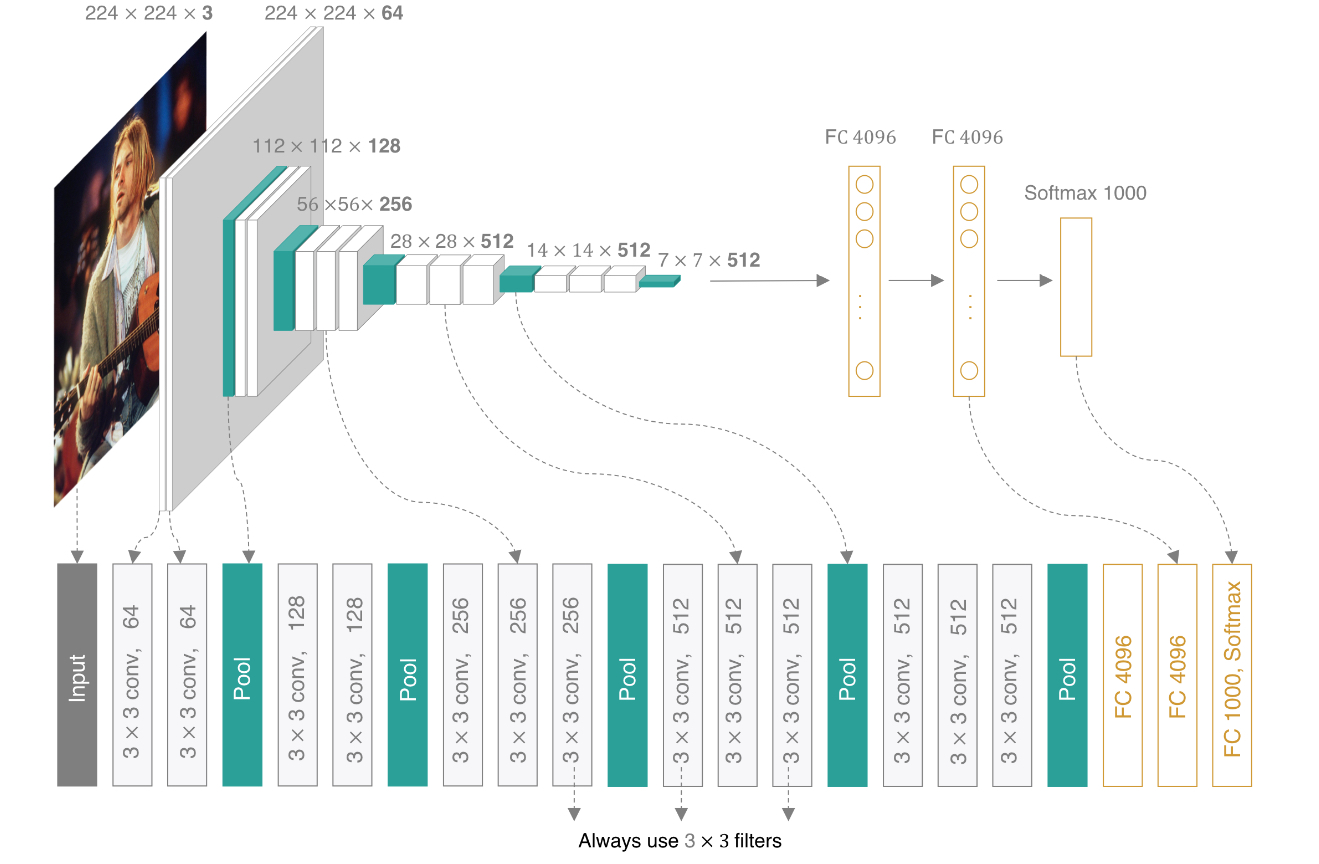
与AlexNet不同的是,在VGG16种卷积核和池化层的大小都是固定的。
输入图像:227*227*3 RGB图,3个通道
训练参数:约138 000 000个
特点:1 所有卷积核的宽和高都是3,步长是1.padding都使用same convolution
2 所有池化层的filter宽和高都是2,步长都是2
3 相比于alexnet,有更多的filter用于提取轮廓信息,具有更高的准确性
3 CNN模型的搭建
一种方法,是参考经典的模型来搭建自己的模型。
另外一种方法,可以利用经典模型的部分模块对图像进行预处理,然后用处理完的数据搭建自己的模型。
比如在VGG16种,可以去除掉FC层,替换成一个MLP层,然后再加一个FC层来复用原理的模型,然后吧7*7*512作为输入给到MLP进行训练。
4 代码示例
4.1 建立CNN模型进行猫狗识别
1 加载数据
#load the data
from keras.preprocessing.image import ImageDataGenerator
#归一化
train_datagen = ImageDataGenerator(rescale=1./255)
#从目录里面导入数据
training_set = train_datagen.flow_from_directory('./cats_and_dogs_filtered/train/', target_size=(50,50), batch_size=32,class_mode='binary')
2 建立模型
#set up the cnn model
from keras.models import Sequential
from keras.layers import Conv2D, MaxPool2D, Flatten, Dense
model = Sequential()
#卷积层
model.add(Conv2D(32,(3,3), input_shape=(50,50,3), activation = 'relu'))
#池化层
model.add(MaxPool2D(pool_size=(2,2)))
#卷积层
model.add(Conv2D(32,(3,3), activation = 'relu'))
#池化层
model.add(MaxPool2D(pool_size=(2,2)))
#flattening layer
model.add(Flatten())
#FC layer
model.add(Dense(units=128, activation = 'relu'))
model.add(Dense(units=1, activation='sigmoid'))3 参数配置
#configure the model
model.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics=['accuracy'])4 查看模型结构
model.summary()
Model: "sequential_4" _________________________________________________________________Layer (type) Output Shape Param # =================================================================conv2d_5 (Conv2D) (None, 48, 48, 32) 896 max_pooling2d_4 (MaxPooling (None, 24, 24, 32) 0 2D) conv2d_6 (Conv2D) (None, 22, 22, 32) 9248 max_pooling2d_5 (MaxPooling (None, 11, 11, 32) 0 2D) flatten_2 (Flatten) (None, 3872) 0 dense_4 (Dense) (None, 128) 495744 dense_5 (Dense) (None, 1) 129 ================================================================= Total params: 506,017 Trainable params: 506,017 Non-trainable params: 0
5 训练模型
#train the model
model.fit_generator(training_set, epochs=25)6 计算训练集的准确度
#accuracy on the training data
accuracy_train = model.evaluate(training_set)
print(accuracy_train)7 计算测试集的准确度
#accuracy on the test data
test_set = train_datagen.flow_from_directory('./cats_and_dogs_filtered/validation/', target_size=(50,50), batch_size=32,class_mode='binary')
#accuracy on the training data
accuracy_test = model.evaluate(test_set)
print(accuracy_test)8 网站下载图片的测试
#load signal image
from keras.utils import load_img, img_to_array
#pic_dog = './cats_and_dogs_filtered/test_from_internet.jpg'
pic_dog = './cats_and_dogs_filtered/train/dogs/dog.1.jpg'pic_dog = load_img(pic_dog,target_size=(50,50))
pic_dog = img_to_array(pic_dog)
pic_dog = pic_dog/255
pic_dog = pic_dog.reshape(1,50,50,3)
predictions = model.predict(pic_dog)
print(predictions)# 对于二分类问题
if predictions.shape[1] == 1:result = (predictions > 0.5).astype(int)
# 对于多分类问题
else:result = np.argmax(predictions, axis=1)print(result)
4.2 改造VGG16进行识别
1 加载和预处理图片格式,利用VGG16处理图片
from keras.utils import load_img, img_to_array
from keras.applications.vgg16 import VGG16
from keras.applications.vgg16 import preprocess_input
import numpy as np
model_vgg = VGG16(weights='imagenet', include_top=False)
def modelProcess(img_path, model):img = load_img(img_path,target_size=(224,224))img = img_to_array(img)x = np.expand_dims(img, axis = 0)x = preprocess_input(x)x_vgg = model_vgg.predict(x)x_vgg = x_vgg.reshape(1,25088)return x_vgg
import os
folder = "./cats_and_dogs_filtered/train/cats"
dirs = os.listdir(folder)#generate path for the images
img_path = []
for i in dirs:if os.path.splitext(i)[1] == ".jpg":img_path.append(i)
img_path = [folder+"//"+i for i in img_path]#preprocess multiple images
features1 = np.zeros([len(img_path), 25088])
for i in range(len(img_path)):feature_i = modelProcess(img_path[i], model_vgg)print('preprocessed: ', img_path[i])features1[i] = feature_ifolder = "./cats_and_dogs_filtered/train/dogs"
dirs = os.listdir(folder)#generate path for the images
img_path = []
for i in dirs:if os.path.splitext(i)[1] == ".jpg":img_path.append(i)
img_path = [folder+"//"+i for i in img_path]#preprocess multiple images
features2 = np.zeros([len(img_path), 25088])
for i in range(len(img_path)):feature_i = modelProcess(img_path[i], model_vgg)print('preprocessed: ', img_path[i])features2[i] = feature_i#label the result
print(features1.shape, features2.shape)
y1 = np.zeros(1000)
y2 = np.ones(1000)X = np.concatenate((features1,features2),axis=0)
y = np.concatenate((y1,y2), axis=0)2 分离测试和训练数据
#split the traing and test data
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3,random_state=50)
print(X_train.shape, X_test.shape, X.shape)3 建立模型
#set up the mlp model
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(units=10, activation='relu',input_dim=25088))
model.add(Dense(units=1, activation='sigmoid'))
model.summary()Layer (type) Output Shape Param # =================================================================dense_12 (Dense) (None, 10) 250890 dense_13 (Dense) (None, 1) 11 ================================================================= Total params: 250,901 Trainable params: 250,901 Non-trainable params: 0
4 配置和训练模型
#confg the model
model.compile(optimizer='adam', loss = 'binary_crossentropy', metrics=['accuracy'])
#train the model
model.fit(X_train, y_train, epochs=50)5 训练集测试
from sklearn.metrics import accuracy_score
y_train_predict_probs= model.predict(X_train)
y_train_predict = (y_train_predict_probs > 0.5).astype(int)
accuracy_train = accuracy_score(y_train,y_train_predict)
print(accuracy_train)6 测试集测试
from sklearn.metrics import accuracy_score
y_test_predict_probs= model.predict(X_test)
y_test_predict = (y_test_predict_probs > 0.5).astype(int)
accuracy_test = accuracy_score(y_test,y_test_predict)
print(accuracy_test)7 下载图片测试
#load the data cat
from keras.utils import load_img, img_to_array
pic_path = './cats_and_dogs_filtered/test_from_ie_cat.jpeg'
pic_cat = load_img(pic_path,target_size=(224,224))
img = img_to_array(pic_cat)
x = np.expand_dims(img, axis = 0)
x = preprocess_input(x)
features = model_vgg.predict(x)
features = features.reshape(1,7*7*512)
result_tmp = model.predict(features)
result = (result_tmp > 0.5).astype(int)
print(result)