JVM(Java虚拟机)详解
目录
1 JVM执行流程
2 JVM运行时数据区(内存布局)
2.1 堆
2.2 栈
2.3 方法区
2.4 程序计数器
2.5 Java和运行时数据区相关的异常
3 JVM类加载(Class Loading)
3.1 加载Loading
3.2 连接Linking
3.2.1 验证Verification
3.2.2 准备Preparation
3.2.3 解析Resolution
3.3 初始化Initialization
3.4 双亲委派模型
4 JVM垃圾回收机制(GC)
4.1 回收的目标
4.2 判断对象是否死亡算法
4.2.1 引用计数
4.2.2 可达性分析
4.3 垃圾回收算法
4.3.1 标记-清除法
4.3.2 复制算法
4.3.3 标记-整理法
4.3.4 分代回收算法
5 JVM内存模型(JMM)
1 JVM执行流程
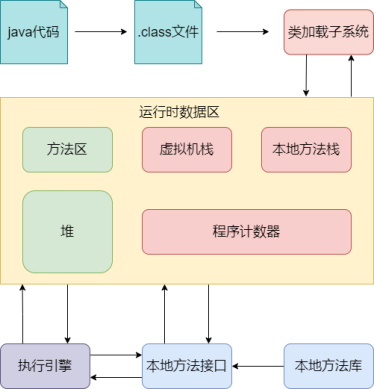
在IDEA点击运行,首先把java代码编译(javac)成字节码(.class文件),JVM通过类加载器(ClassLoader)把字节码文件加载到内存中运行时数据区(Runtime Data Area),在该区域进行变量、对象、方法、执行指令的构造。
字节码文件是JVM的一套指令集规范,并不能直接交个操作系统去执行,因此需要特定的命令解析器执行引擎(Execution Engine)将字节码翻译成底层系统指令再交由CPU去执行,而这个过程中需要调用其他语言(C++)的接口,即本地库接口(Native Interface)来实现整个程序的功能。
2 JVM运行时数据区(内存布局)
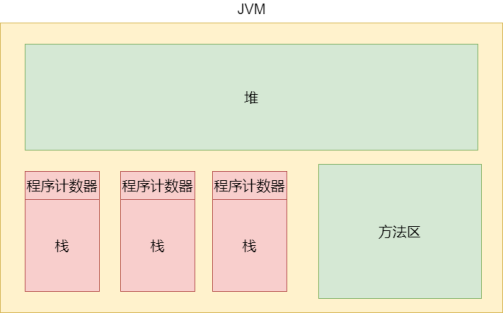
运行时数据区主要包含4个部分:堆、栈、方法区和程序计数器。
2.1 堆
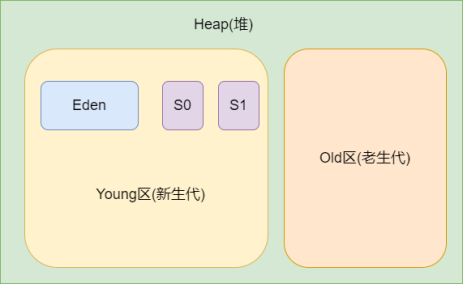
堆是存放对象的区域,线程共享堆区域。
堆分为两个区域:新生代和老生代,新生代放新建的对象,当经过一定GC(垃圾回收)次数之后还存活的对象会放入老生代。新生代还有3个区域:一个Eden+两个Survivor(S0和S1)。
垃圾回收的时候会将Eden中存活的对象放到一个未使用的Survivor中,并把当前的Eden和正在使用的Survivor清除掉。
2.2 栈
JVM的栈原来是有两个区域:Java虚拟机栈和本地方法栈。Java虚拟机栈是给Java代码使用的;本地方法栈是给本地方法使用的。在Java1.8后,JVM把这两个栈合并。
栈中存放局部变量和方法之间的调用关系(不存储方法内容),属于线程私有区域(一个线程对应一个栈)。
注意:局部变量和成员变量的区分。局部变量是方法中创建的变量,存储在栈中。成员变量是对象的属性表示的变量,存储在堆中(属于对象的一部分)。
2.3 方法区
方法区用来存储被虚拟机加载的类对象、常量、静态变量,线程共享该区域。
类对象包含类的信息,即编译后的代码,包含类名、继承关系、实现关系、属性(类型、名称、访问权限)、方法(名称、访问权限、参数、返回值、方法内容(也就是转换后的指令)。
在HotSpot虚拟机(默认实现JVM的定义的版本)的实现中,在JDK 7时此区域叫做永久代(PermGen),JDK 8中叫做元空间(Metaspace)。
注意:区分局部变量、成员变量和静态变量。
比如:
class A{int num;static int count;}int main(){A a = new A();}在这个代码中,成员变量num存储在堆。a属于局部变量,存储在栈。a引用所指向的对象A存储在堆。而count是静态变量,属于类对象,存储在方法区。
2.4 程序计数器
程序计数器用来记录当前线程执行到代码的行号,属于线程私有区域。和线程调度上下文(环境)的记录和恢复相关。
2.5 Java和运行时数据区相关的异常
(1)OutOfMemoryError:Java heap space:堆溢出。解决时关注对象是否实例化的次数过多。
(2)StackOverflowError:栈溢出。解决时关注是否函数出现多次调用,比如循环递归。
3 JVM类加载(Class Loading)
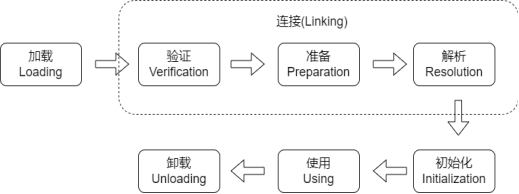
JVM类加载过程大致分为加载、连接和初始化三个阶段。
3.1 加载Loading
编译后的class文件存储在磁盘上,加载就是找到class文件、读取文件内容、在内存构造类对象、再把数据填入类对象中一系列过程。
3.2 连接Linking
3.2.1 验证Verification
验证阶段确保Class文件的字节流中包含的信息符合《Java虚拟机规范》的全部约束要求,保证这些信息被当作代码运行后不会危害虚拟机自身的安全。
验证的选项:文件格式验证、字节码验证、符号引用验证。
3.2.2 准备Preparation
准备阶段是正式为类中定义的变量(即静态变量,static修饰的变量)分配内存并设置类变量初始值(int类型赋值为0,自己定义的变量时赋的值不在这个阶段,而是在初始化阶段)的阶段。
3.2.3 解析Resolution
解析阶段是JVM将常量池内的符号引用替换为直接引用(编译时只知道某个地方应该用常量池的某个常量,用一个符号占用该位置表示。解析时,把这个符号引用替换成常量池某个常量的真实的内存地址)的过程,也就是初始化常量的过程。
3.3 初始化Initialization
初始化阶段,JVM真正开始执行类中编写的Java程序代码,将主导权移交给应用程序。初始化阶段就是执行类的构造器方法的过程,针对静态变量实现初始化(初始化为开发人员给变量赋的值),执行静态代码块,同时如果某个类的父类没有加载,就要去加载父类。
3.4 双亲委派模型
双亲委派模型描述了一个类加载器收到类加载请求时由哪个类加载器负责的问题。
JVM一共存在4种类加载器,分别是BootStrapClassLoader、ExtensionClassLoader、ApplicationClassLoader和自定义的类加载器,这里不讨论自定义的类加载器(如果有就位于ApplicationClassLoader的下一级)。
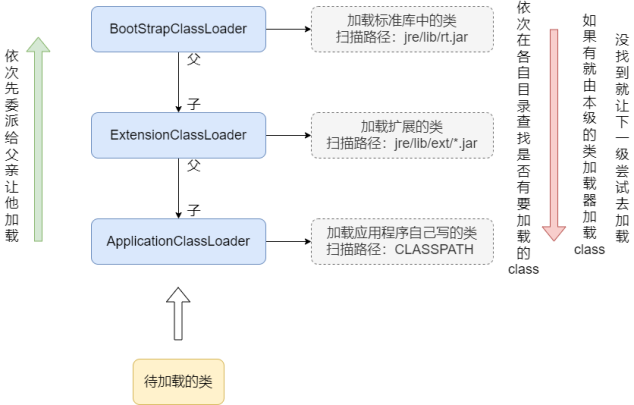
当有待加载的类时,类加载器开始运行,从ApplicationClassLoader开始,每个类加载器首先不进行类加载,而是把任务委派给父亲让他先尝试加载,最终会把类加载请求发给BootStrapClassLoader。
BootStrapClassLoader首先会从标准库中扫描是否有待加载的class文件,如果有就由其负责类加载。如果没有就由其孩子来尝试进行类加载。如果所有的类加载器都没有找到class文件,就会抛出ClassNotFoundException的异常。
注意:双亲委派模型的好处。最大的好处是可以让程序员自定义的类不会把Java标准库中的类给覆盖了,因为即使写了一个类名为String,根据双亲委派模型,该类被加载首先会在rt.jar中查找,就找到了由BootStrapClassLoader来进行类加载,也就是仍然优先加载标准库的类而不是自己写的类。
是否自定义的类加载器一定要遵循双亲委派模型?不一定,可以遵循也可以不遵循。比如Tomcat加载webapps的一些类的时候自定义了类加载器,并没有遵循双亲委派模型。
4 JVM垃圾回收机制(GC)
当申请的内存空间不进行释放,就有可能出现内存泄露问题,即内存越用越少,最终没有内存空间可用。而开发人员手动释放难免保证不出纰漏,因此据需要垃圾回收机制定时自动回收。
4.1 回收的目标
垃圾回收的目标主要是堆区域,即回收不在使用的对象(死亡状态)。为什么不回收其他区域的内存呢?
程序计数器每个线程有一个独立的空间,线程销毁时一起跟着就被销毁了,因此不需要垃圾回收。
栈区域主要就是局部变量,当局部变量出了作用域,也就可以被回收了,因此它的回收时间明确,也不需要回收。
方法区主要存储类对象,类对象被类加载一次就不再加载了,且几乎不会被类卸载,因此需要回收的时机并不多,因此也没有那么需求垃圾回收机制。
注意:垃圾回收的单位是对象而不是字节。在堆的区域划分中,有3类:正在使用的内存、使用过不再使用的内存和从未被使用的内存。因此即使一个对象只有其中一个成员变量仍被使用,其他成员使用过不再使用,此时也不是回收的目标,只有整个对象都不再使用,才会被垃圾回收。
4.2 判断对象是否死亡算法
4.2.1 引用计数
引用计数就是给每个对象增加一个引用计数器,每有一个引用变量引用对象,计数器就+1,每有一个引用对象的引用被销毁,计数器就-1。当计数器为0时,对象就会被垃圾回收。
但是引用计数有一些弊端:
1.多线程环境下,对象被多个线程引用,就会存在线程安全问题。
2.对于空间占用小的对象,如果数量很多,就会引来不小的内存开销(1kb(大对象)+2字节(引用计数器) VS 2字节(小对象)+2字节(引用计数器))。
3.存在循环引用问题(最大的缺点)。假设存在类:
class Test{Test t = null;}int main(){Test a = new Test();Test b = new Test();a.t = b;b.t = a;a = null;b = null;// 销毁a和b}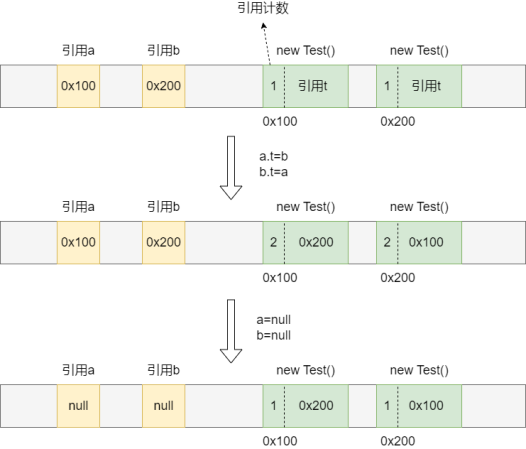
刚创建引用a和b并实例化Test对象时,a引用的Test对象地址是0x100,引用计数1;b引用的Test对象地址是0x200,引用计数1。当执行a.t = b和b.t = a后,两个对象的引用计数变为2。但是当销毁引用a和b后,两个Test对象引用计数都-1,此时没有引用变量再指向两个Test对象,但两个对象其中的成员属性都互相引用,造成循环引用,此时引用计数器无法变成0,也就无法被垃圾回收。
注意:引用计数在Python中被使用,但是在JVM中,由于以上弊端没有使用该算法。
4.2.2 可达性分析
特殊变量作为起点(GCRoot),从起点出发,沿引用链访问对象,如果可以访问到,则该对象是可达的(表示仍被引用,是存活的)。如果不可以被访问到,则该对象是不可达的(表示没有被引用,应该被回收)。
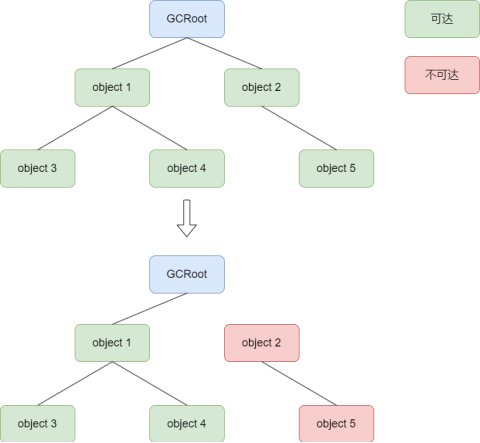
可以作为起点(GCRoot)的对象:
1.局部变量表中的引用(栈中的局部变量)。
2.常量池中的对象(方法区)。
3.静态引用类型的成员(方法区)。
可达性分析的优点:1.没有使用额外的空间(引用计数器)2.没有循环引用问题,因为如果没有引用能访问到循环引用的对象,即不可达,也会被垃圾回收。
4.3 垃圾回收算法
4.3.1 标记-清除法
经过可达性分析,把要回收的对象标记,垃圾回收时把所有带标记的对象回收。
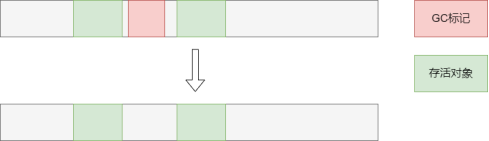
缺点是会产生许多内存碎片,即被释放的区域如果想要存储一个更大的对象,就无法利用该空间(有空闲空间却无法用)。
4.3.2 复制算法
把内存空间分为两份连续的空间,每次只使用其中一份,当垃圾回收时,把存活的对象复制到另一份未使用的区域,然后清空当前使用区域的所有对象。
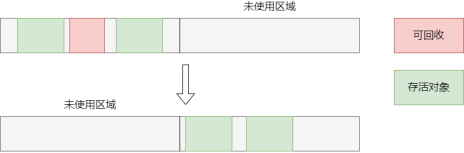
解决了标记-清除法的内存碎片问题,但是引入新的问题:空间利用率太低。
4.3.3 标记-整理法
类似顺序表一样,每次垃圾回收后,会把所有还存活的对象进行整理,即把所有存活对象全移动到一起。
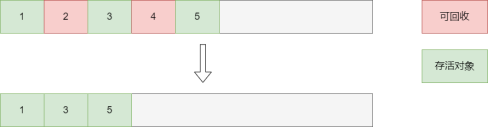
解决了复制算法空间利用率低的问题,但是缺点是移动操作开销很大。
4.3.4 分代回收算法
引入概念对象的年龄:对象经过垃圾回收算法扫描的轮次。比如当对象经过3轮GC算法,仍然没有被回收,对象年龄就为3。
把堆区域划分新生代区域和老年代区域,对象的年龄小的在新生代区存储,年龄大的在老年代区存储。
新生代区域具体分为:一个Eden(伊甸区)+两个Survivor(幸存者区S0和S1)。由于新生代区每次垃圾回收绝大部分对象都会死去,只有少部分对象存活,因此使用复制算法,并且幸存区不会很大。老年代区对象年龄大,经常被使用,且满足条件的对象少,因此使用标记-整理法不会有很大的开销。
分代回收算法执行流程如下:
1.新创建的对象在伊甸区,绝大部分对象会在一轮GC后被回收,存活的对象复制到幸存区1。
2.幸存区1和伊甸区再经过一轮GC后,仍然存活的对象复制到幸存区2。
3.此后,如果对象的年龄仍未达到设定的轮次,就在幸存区1和幸存区2之间反复复制(总有一个幸存区是空的)。
4.如果对象的年龄到达设定的轮次,就存储在老年代区,此后使用标记-整理法进行GC(频率就比较低了)。
5.如果创建的对象很大,来回复制开销也很大,因此会在创建之初就被存储在老年代区。
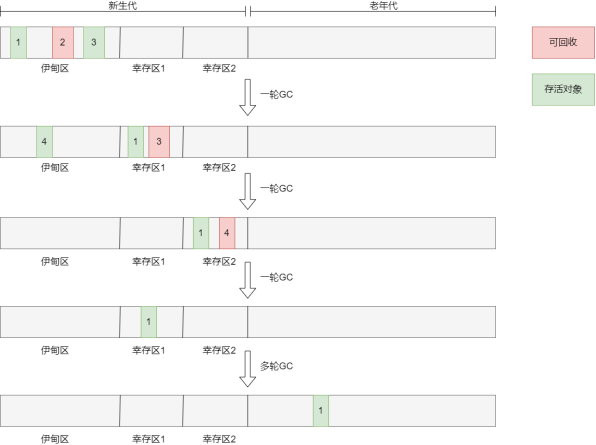
分代回收算法就是对不同的区域使用不同的算法,充分利用各种算法的优点,避免缺点,从而具有较好的性能,因此分代回收算法是JVM使用的GC算法。
5 JVM内存模型(JMM)
这部分内容在多线程就已经讲过了:
多线程—线程安全原理![]() https://blog.csdn.net/sniper_fandc/article/details/146420990?fromshare=blogdetail&sharetype=blogdetail&sharerId=146420990&sharerefer=PC&sharesource=sniper_fandc&sharefrom=from_link
https://blog.csdn.net/sniper_fandc/article/details/146420990?fromshare=blogdetail&sharetype=blogdetail&sharerId=146420990&sharerefer=PC&sharesource=sniper_fandc&sharefrom=from_link