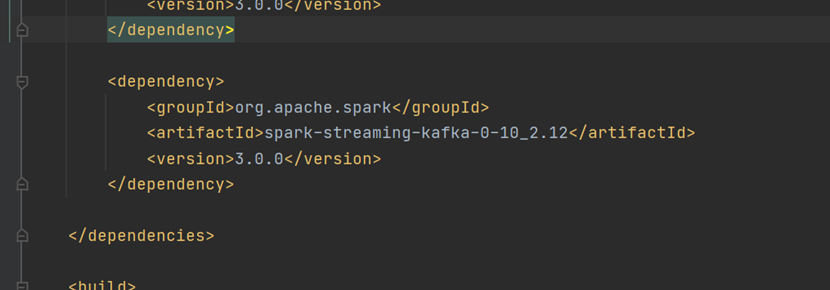
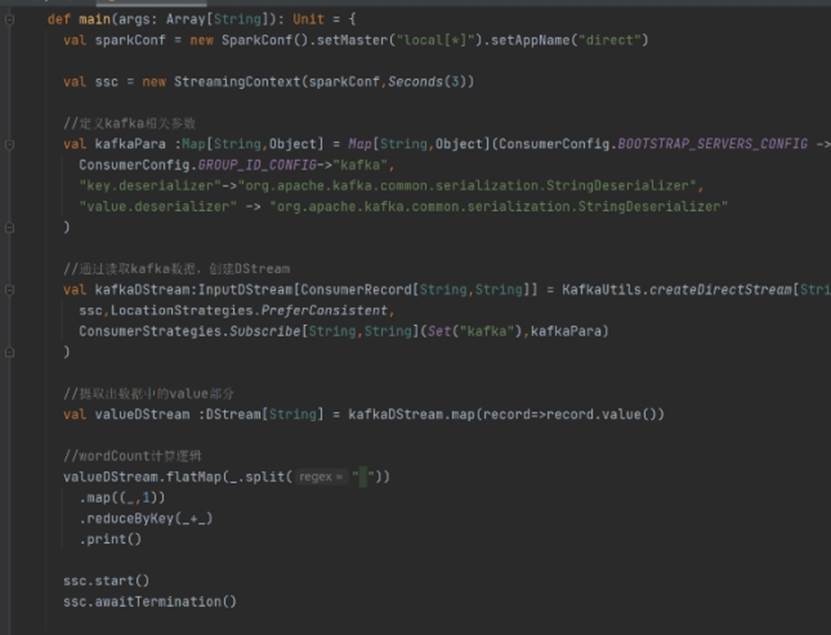
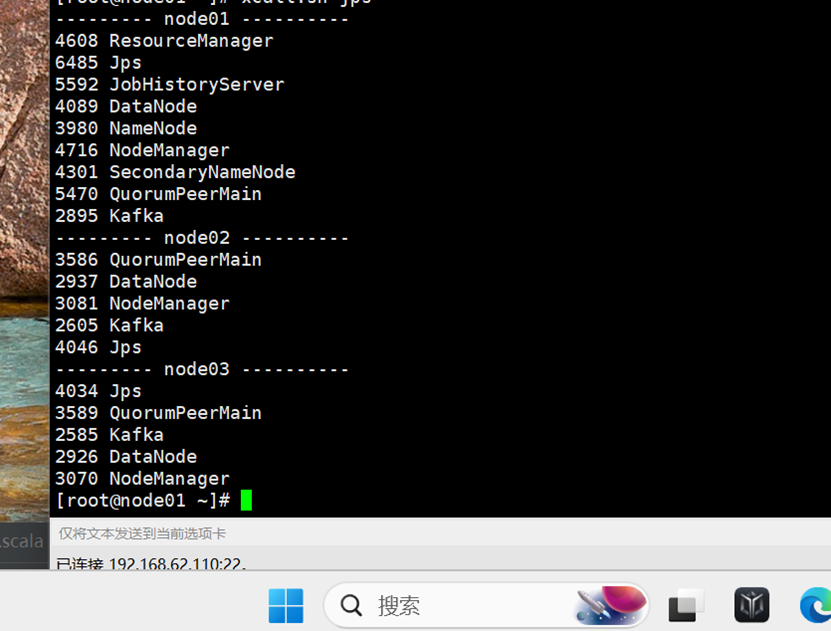
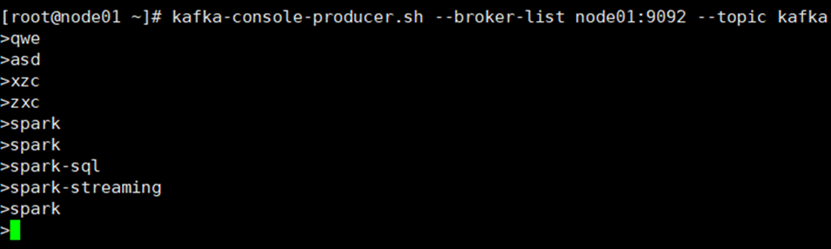
当前位置: 首页 > news >正文 Spark-Streaming核心编程 news 来源:原创 2025/4/25 9:43:32 Kafka数据源 需求:通过 SparkStreaming 从 Kafka 读取数据,并将读取过来的数据做简单计算,最终打印到控制台 2. 导入依赖 编写代码 5.开启Kafka集群 6.开启Kafka生产者,产生数据 相关文章: Java集成【邮箱验证找回密码】功能 聊聊Spring AI Alibaba的OneNoteDocumentReader 实现Variant AI赋能Python长时序植被遥感动态分析、物候提取、时空变异归因及RSEI生态评估 系统高性能设计核心机制图解:缓存优化、链表调度与时间轮原理 白鲸开源WhaleStudio与崖山数据库管理系统YashanDB完成产品兼容互认证 麒麟系统离线安装软件方法(kazam录屏软件为例) SEO的关键词研究与优化 第一章 AI | 最近比较火的几个生成式对话 AI YOLO训练时到底需不需要使用权重 【AI提示词】私人教练 昆仑万维开源SkyReels-V2,解锁无限时长电影级创作,总分83.9%登顶V-Bench榜单 使用正确的 JVM 功能加速现有部署 Kaamel视角下的MCP安全最佳实践 python-69-基于graphviz可视化软件生成流程图 文件操作、流对象示例 用 Python 实现基于 Open CASCADE 的 CAD 绘图工具 碰一碰发视频源码文案功能,支持OEM VulnHub-DC-2靶机渗透教程 编译型语言、解释型语言与混合型语言:原理、区别与应用场景详解 今年地质灾害防治形势严峻,哪些风险区被自然资源部点名? 拖车10公里收1900元?货车司机质疑收费过高,潮州饶平县市监局已介入 广东省发展改革委原副主任、省能源局原局长吴道闻被开除公职 张文宏团队公布广谱抗猴痘药物研发进展,将进入临床审批阶段 最高法:家长以监督为名虚构事实诋毁学校的,应承担侵权责任 护航民营企业出海,上海设37家维权工作站、建立近百人专家团队
Kafka数据源 需求:通过 SparkStreaming 从 Kafka 读取数据,并将读取过来的数据做简单计算,最终打印到控制台 2. 导入依赖 编写代码 5.开启Kafka集群 6.开启Kafka生产者,产生数据