数模学习:一,层次分析法
基本定位:
适用于解决评价,选择类问题(数值不确定,需要自己结合资料数据等自己填写)。
引入:
若要解决选择类的问题,打分的方式最为常用——即采用权重表:
| 指标权重 | 选择1 | 选择2 | ........ | |
| 指标1 | ||||
| 指标2 | ||||
| 指标3 | ||||
| ........ |
各指标权重之和为1,各方案在某指标上的打分之和也应为1.
那么我们来看一道例题:
A想去旅游,在查阅网上攻略后,初步选择了苏杭,北戴河,桂林三地之一作为目标景点。
请你确定评价指标,形成评价体系来为小明同学选择最佳的方案:
评价类问题的入手思路:
1,我们评价的目标是什么?
2,我们为了达成这个目标,有哪几种方案?
3,评价的标准或者说指标是什么?
在本题中:
1,为A 找到最佳的景点。
2,三地。
3,答案常常需要根据题目的背景资料,常识,网上搜集的资料进行结合,筛选出最合适的指标
网上资料搜索推荐:
1,知网——引用论文,同时学习分析方法
2,https://search.chongbuluo.com/
那么假设现在已经找到了以下五个指标:
景色,花费,居住,饮食,交通;
列出权重表:
| 指标权重 | 苏杭 | 北戴河 | 桂林 | |
| 景色 | ||||
| 花费 | ||||
| 居住 | ||||
| 饮食 | ||||
| 交通 |
那么剩下的就是找到各指标的权重大小:
问题——当分析多因素对于某一问题的影响大小时,单独分析某一个因素的影响可能会有失偏颇
解决方法:
采用分而治之的思想——要求被分析对象两两指标之间进行比较,根据最终的比较结果来推算权重
——这就是层次分析法的思想。
层次分析法的思想:
| 标度 | 含义 |
| 1 | 表示两个因素相比,同等重要 |
| 3 | 表示两个因素相比,一个因素比另一个稍微重要 |
| 5 | 表示两因素相比,一个因素比另一个明显重要 |
| 7 | 表示两因素相比,一个因素比另一个强烈重要 |
| 9 | 表示两因素相比,一个因素比另一个极端重要 |
| 2,4,6,8 | 表示相邻判断之间的中值 |
| 倒数 | 若A比B标度为3,则B比A标度为1/3 |
| 景色 | 花费 | 居住 | 饮食 | 交通 | |
| 景色 | 1 | 1/2 | 4 | 3 | 3 |
| 花费 | 2 | 1 | 7 | 5 | 5 |
| 居住 | 1/4 | 1/7 | 1 | 1/2 | 1/3 |
| 饮食 | 1/3 | 1/5 | 2 | 1 | 1 |
| 交通 | 1/3 | 1/5 | 3 | 1 | 1 |
总结:
上面的表格为一个5 X 5 的矩阵,即为A,对应元素即为. 具有如下特点:
1,表示的是与指标j相比,指标i的重要程度。
2,满足(称该矩阵为正互反矩阵)
上述矩阵即为层次分析法中的判断矩阵
同样方法也能用判断矩阵得到各个方案对于某一因素的权重大小
PS:一个可能出现矛盾的地方:
例如:
苏杭 = A, 北戴河 = B,桂林 = C;
苏杭比北戴河景色好一点:A > B; 苏杭和桂林景色一样好:A = C;
北戴河比桂林景色好一点:B > C;
此种情况应如何解决?
首先引入一致矩阵的概念:
一致矩阵:
若所构造的判断矩阵满足,则称其为一致矩阵。
满足——各行(列)之间成倍数关系
我们在使用判断矩阵求权重之前,就必须对其进行一致性检验。
进行一致性检验的意义:
可能存在的问题:
例如:
设定苏杭 = A,北戴河 = B,桂林 = C;
苏杭比北戴河景色好一点:A > B; 苏杭和桂林景色一样好: A = C;
北戴河比桂林景色好一点: B > C;
此类题中出现了前后相矛盾的情况
故一致性检验的目的:为了检验我们构造的判断矩阵和一致矩阵是否有太大的区别
引理基础:
1,A为n阶矩阵,且r(A) = 1,则A有一个特征值tr(A),其余特征值均为0;
因为一致矩阵的各行成比例,故矩阵的秩一定为1,有一个特征值为n,其余特征值均为0;
2,n阶正互反矩阵A为一致矩阵时,当且仅当最大特征值 = n;
当n阶正互反矩阵A非一致时,一定满足最大特征值 > n;
判断矩阵越不一致,最大特征值与n相差越大;
一致性检验的步骤:
1,计算一致性指标CI;
2,查找对应的平均随机一致性指标RI:
用随机方法构造500个样本矩阵,并随机地从1~9及其倒数中抽取数字构造正互反矩阵,求得最大特征根的平均值D,并定义:
3,计算一致性比例CR:
若CR < 0.1,则可认为判断矩阵的一致性可以接受;否则需要对判断矩阵进行修正
判断矩阵怎么计算权重:
若我们所构造的判断矩阵已通过一致性检验。
法1(算术平均法):
| 景色 | 苏杭 | 北戴河 | 桂林 |
| 苏杭 | 1 | 2 | 4 |
| 北戴河 | 1/2 | 1 | 2 |
| 桂林 | 1/4 | 1/2 | 1 |
注意:权重最终值一定要进行归一化处理。
苏杭 = 1 / (1 / 2 + 1 + 1/ 4)
北戴河 = 1/2 / ( 1 + 1 / 2 + 1 / 4)
桂林 = 1 / 4 / (1 +1 / 2 +1 / 4 )
形似的,对于存在着误差的判断矩阵,
进行相同处理,对于每一列的计算结果,其答案有可能均不相同,那么判断矩阵的计算结果即为n列结果的平均值。(算数平均法)
故按算术平均法计算权重步骤如下:
1,将判断矩阵进行归一化(每一个元素除以所在列的的和)
2,将归一化的各列相加(按行求和)
3,将相加后得到的向量中每一个指标除以总列数后,即可得到权重向量;
法二,特征值法求权重:(最常用)
一致矩阵有一个特征值n,其余特征值均为0,。另外,特征值为n时,对应的特征向量刚好为
又因为对于一致矩阵,1 / a1n = an1;,即特征向量即是一致矩阵的第一列。
若判断矩阵的一致性检验结果可以接受,那么就可以仿照一致矩阵的计算方法。
第一步:求出矩阵A的最大特征值及其对应的特征向量。
第二步:对求出的特征向量进行归一化处理后即可得到权重
对于最终结果的处理:
推荐使用EXCEL表格快速计算表格结果。
要点:通过F4锁定单元格进行相同运算。
层次分析法:
一,画出层次分析图
分析系统中个元素之间的关系,建立系统的递阶层次结构
(注意:若使用了层次分析法,那么层次分析图要放在建模论文中)
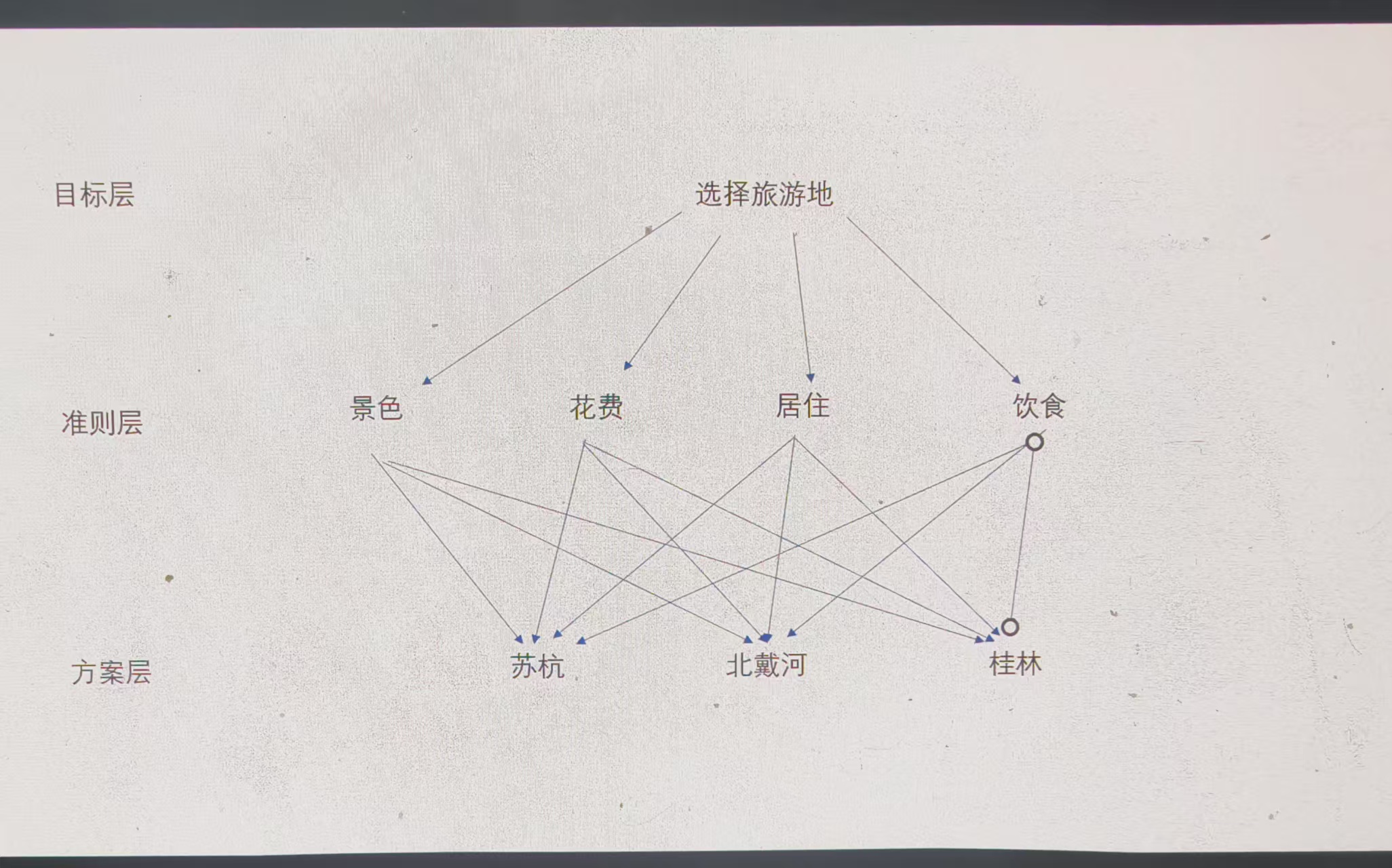
二,构造判断矩阵:
三,由判断矩阵计算被比较元素的相对权重,并进行一致性判断(检验通过才能使用权重):
三种方法:
1,算术平均法; 2,几何平均法; 3,特征值法;
推荐比赛时,三种方法都使用。
在结论时便可加上——“为了保证结果的稳健性,本文采用了三种方法计算权重。再根据得到的权重矩阵计算各方案的得分,并进行排序和综合分析。这样避免了采用单一方法产生的偏差,得到的结论更全面,更有效”
若一致性检验结果 > 0.1:尽量往一致性矩阵方向靠拢(各行各列均成倍数)
四,运用EXCEL 表格对计算数值,并将结果进行排序
层次分析法的局限性:
一,评价的决策层不能太多:
一是判断矩阵会与一致矩阵的差异很大;
二是平均随机一致性指标RI的表格中n最多是15;
二,若决策层中指标的数值已知,那么我们若再使用自己填写的判断矩阵,则会加大误差,所以此情况不能使用层次分析法。
模型拓展:
(1)决策层可以有多层,如子决策层,子子决策层.......
(2)一个决策可以只对应部分的方案,只需要在判断矩阵中将相应的方案权重设为0即可