从代码学习深度学习 - 微调 PyTorch 版
文章目录
- 前言
- 一、迁移学习与微调概念
- 二、微调步骤解析
- 三、实战案例:热狗识别
- 3.1 数据集准备
- 3.2 图像增强处理
- 3.3 加载预训练模型
- 3.4 模型重构
- 3.5 差异化学习率训练
- 3.6 对比实验分析
- 总结
前言
深度学习模型训练通常需要大量数据,但在实际应用中,我们往往难以获得足够的标记数据。例如,如果我们想构建一个识别不同类型椅子的系统,收集和标记数千甚至数万张椅子图像将耗费大量时间和资金。这种情况下,迁移学习特别是微调(fine-tuning)技术便显示出其强大优势。本文将通过一个热狗识别的实际案例,详细讲解如何在PyTorch中实现微调,帮助读者掌握这一重要技术。注意,本博客只列出了与微调相关的代码,完整代码在下方链接中给出,其中包含了详细的注释。
完整代码:下载链接
一、迁移学习与微调概念
迁移学习是指将从一个任务中学到的知识应用到另一个相关任务中。在计算机视觉领域,我们常常利用在大规模数据集(如ImageNet)上预训练的模型,将其"迁移"到我们的特定任务中。
微调是迁移学习的一种常见方法,它不仅复用预训练模型的架构,还复用其参数,然后通过在目标数据集上继续训练来调整这些参数,使模型适应新任务。这种方法的核心假设是:预训练模型已经学到了通用的特征提取能力,只需要针对新任务做适度调整。
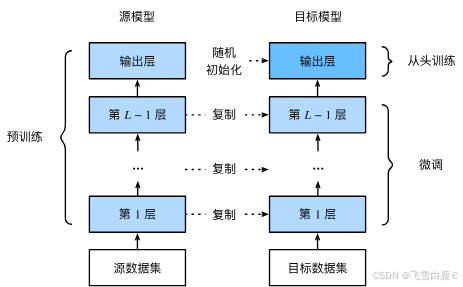
二、微调步骤解析
微调通常包含以下四个关键步骤:
- 预训练模型选择:在源数据集(如ImageNet)上训练一个基础模型
- 模型结构调整:复制预训练模型的架构和参数(除输出层外)
- 输出层替换:添加适合目标任务的新输出层,并随机初始化其参数
- 差异化训练:在目标数据集上训练模型,通常对预训练层使用较小学习率,对新添加层使用较大学习率
三、实战案例:热狗识别
3.1 数据集准备
首先,我们加载并查看热狗识别的数据集:
# 设置matplotlib在Jupyter Notebook中内嵌显示图表
%matplotlib inline
# 导入必要的库
import os # 用于处理文件路径
import torch # PyTorch深度学习框架
import torchvision # PyTorch视觉库,用于处理图像数据
from torch import nn # PyTorch神经网络模块
# 导入自定义工具函数,用于显示图像
import utils_for_huitu
# 设置数据目录路径
data_dir = 'hotdog' # 数据根目录
# 加载训练集图像
# ImageFolder假设数据按类别存放在不同文件夹中
# 文件结构应为:hotdog/train/[类别1]/, hotdog/train/[类别2]/ 等
train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'))
# 加载测试集图像
test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'))
# 获取训练集中的热狗图像样本
# 从训练集的前8张图像中获取图像数据
# train_imgs[i][0]表示第i个样本的图像数据,train_imgs[i][1]是对应的标签
hotdogs = [train_imgs[i][0] for i in range(8)]
# 获取训练集中的非热狗图像样本
# 从训练集的末尾8张图像中获取图像数据
not_hotdogs = [train_imgs[-i - 1][0] for i in range(8)]
# 显示图像
# 将热狗和非热狗图像合并为一个列表,并显示在2行8列的网格中
# scale参数用于调整图像显示的大小
utils_for_huitu.show_images(hotdogs + not_hotdogs, 2, 8, scale=1.4)