新!在 podman-machine-default 中安装 CUDA、cuDNN、Anaconda、PyTorch 等并验证安装
#工作记录
一、前言
在 Windows 系统开发环境中,Podman Desktop 凭借强大的容器管理与 WSL-Linux 子系统集成能力备受开发者关注。
其中,podman-machine-default 是 Podman Desktop 安装后自带的默认 WSL-Fedora 子系统,支持与显卡通信,可用于搭建深度学习环境及部署 AI 项目。
解锁新技能!Windows 11 借助 WSL - Linux 部署 GitHub 项目全攻略_wsl github-CSDN博客
但需注意,该默认子系统仅允许操作用户权限,无 root 权限。
若需 root 权限进行系统级操作,可在 Podman Desktop 图形界面点击 “Create Podman machine”新建 Podman machine 子系统,并在创建时设置授予 root 权限:
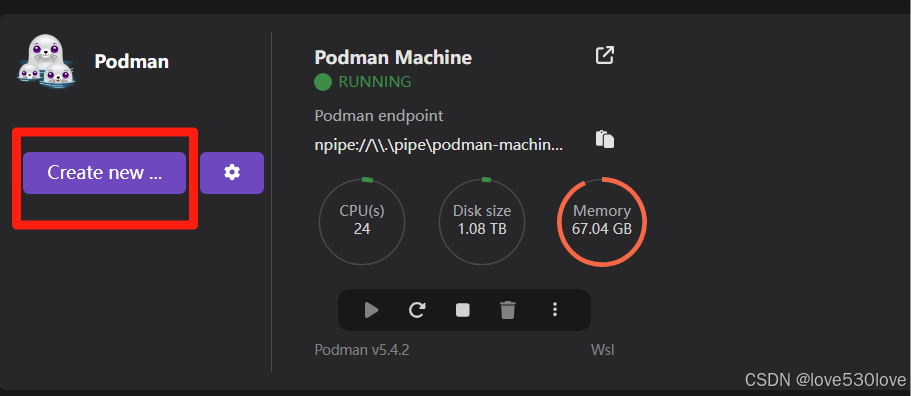
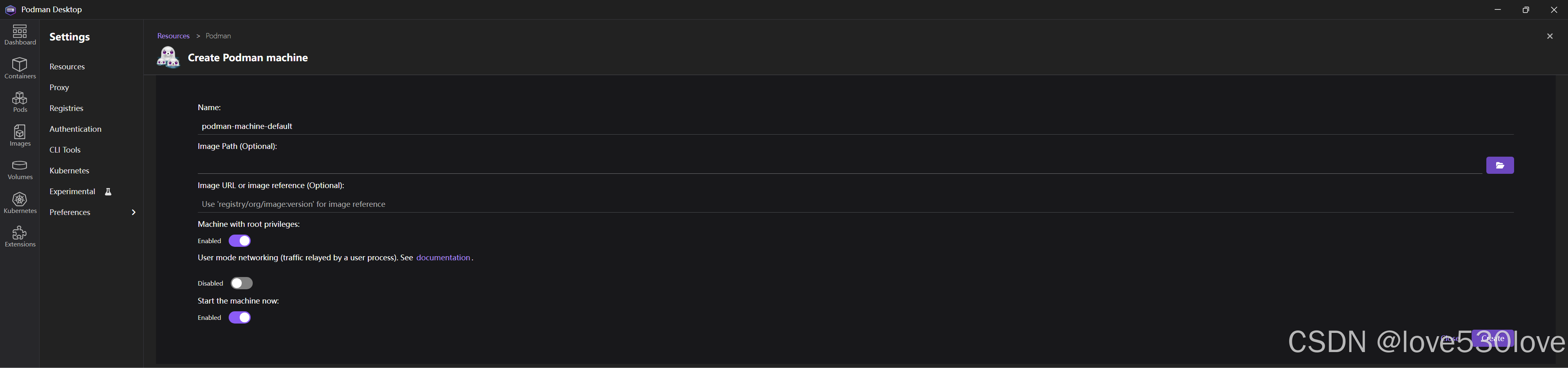
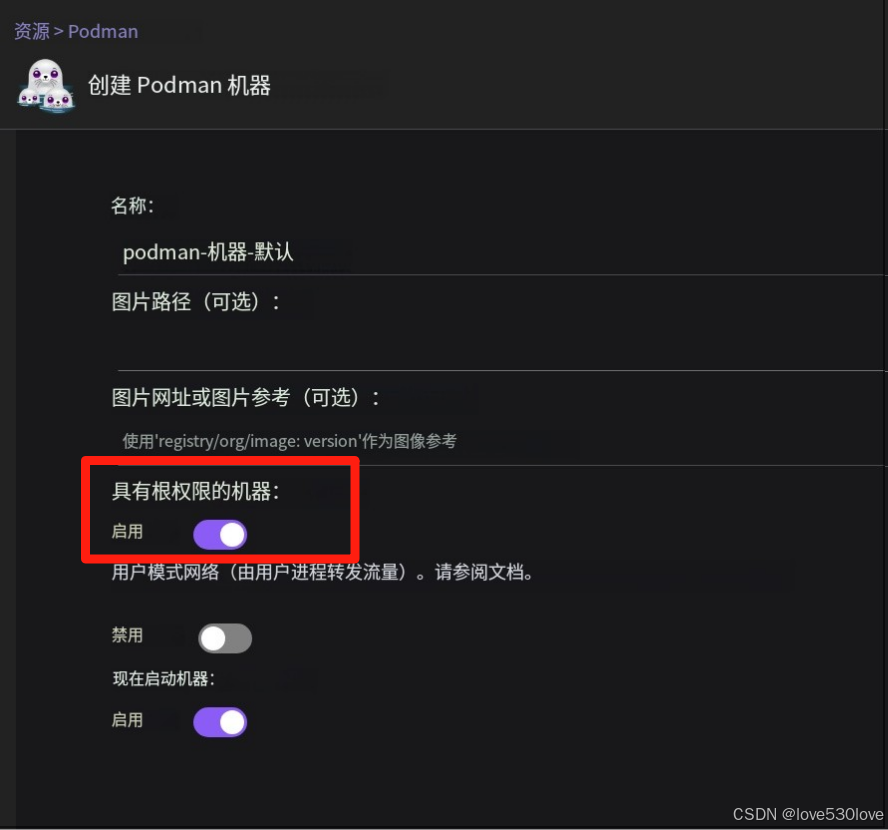
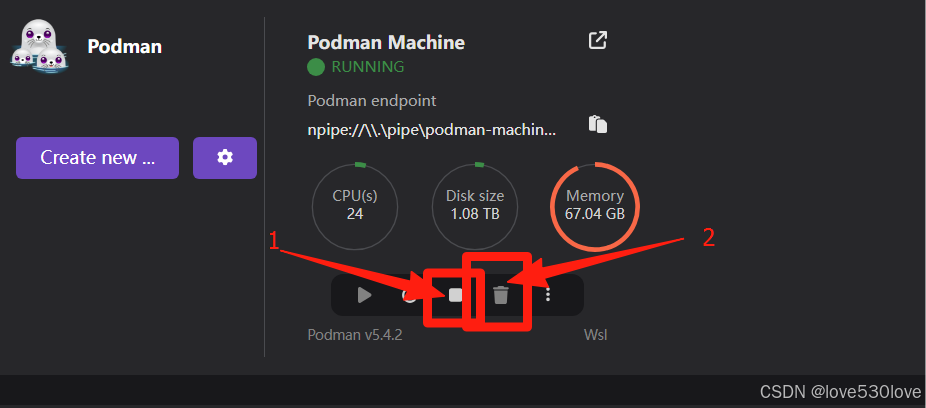
同时,podman-machine-default 作为默认环境,操作时需格外谨慎,一旦出现崩溃,可能影响 Podman Desktop 正常功能。
当崩溃发生,可通过 Podman Desktop 图形界面先停止 podman-machine-default,再执行删除操作,随后点击 “开始并初始化”,即可将其恢复至初始空白状态。
在 Windows Subsystem for Linux(WSL)环境下,CUDA、cuDNN、Anaconda 及 PyTorch 等工具安装流程虽大体相似,但因 Linux 发行版差异,安装命令与软件包细节会有不同,常导致安装受阻。
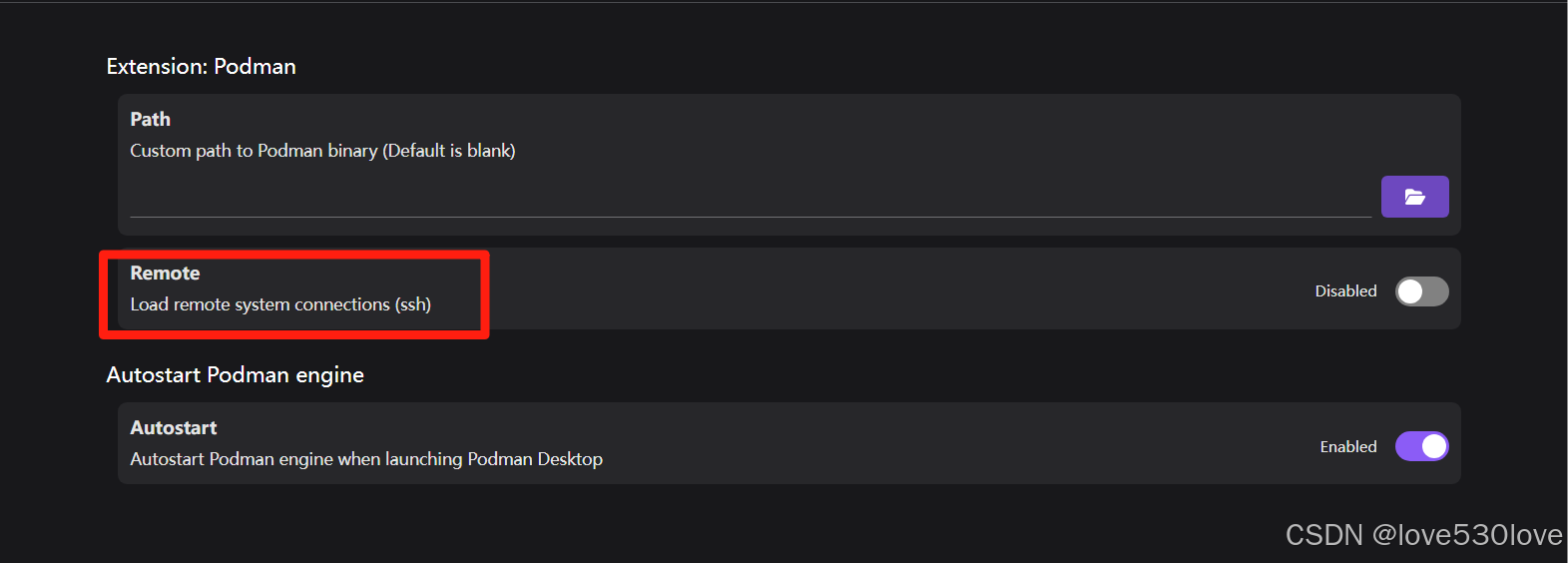
podman-machine-default还能便捷地在Podman Desktop设置中开启ssh远程连接的支持:
本文通过详细回测与重现,记录安装全过程,为开发者提供参考。
借助 Podman Desktop 的容器功能与 WSL-Linux 子系统结合,特别是利用基于 Fedora Linux 41 的开发环境,可高效部署不兼容 Windows 的 AI 项目。
当然,这里只是记述了Podman Desktop的其中一种用法,并非推荐用法,请注意按实际需要调整 WSL-Linux的实现方式。
本文将完整呈现安装配置过程,帮助开发者规避常见错误,顺利搭建podman-machine-default开发环境。
原本只想在安装配置成功后记录一个简洁版本的,后来回测的时候发现出错概率太高了,所以就把podman-machine-default中实现深度学习环境搭建的记录,按回测、排查错误、重现的过程完整记录下来,供大家参考。
Podman Desktop:现代轻量容器管理利器(Podman与Docker)-CSDN博客
PyCharm 链接 Podman Desktop 的 podman-machine-default Linux 虚拟环境-CSDN博客
二、安装前的准备:
(一)类似流程的搭建方法请参考:
在 Windows 11 下的 WSL - Ubuntu 24.04 中安装 CUDA 的记录_cuda-wsl-ubuntu.pin-CSDN博客
Windows 11 系统下,通过 WSL(Windows Subsystem for Linux)里的 Ubuntu 24.04 安装 CUDNN 记录_wsl cudnn-CSDN博客
在 Windows 11 下的 WSL - Ubuntu 24.04 中安装 Anaconda3_wsl2 ubuntu 24.04 anaconda-CSDN博客
在 Windows 11 下的 WSL - Ubuntu 24.04 中安装 Torch 的记录_ubuntu24.04 python3.12 国内源安装 torch-CSDN博客
在WSL2-Ubuntu中安装CUDA12.8、cuDNN、Anaconda、Pytorch并验证安装_cuda 12.8 pytorch版本-CSDN博客
(二)安装前的检查及安装步骤简录:
1、安装前检查(Windows主系统)
Window主系统上应准备好或安装好:
(1)通畅的网络环境
准备好代理网络,稳定通畅的网络环境十分重要。
(2)最新的NVIDIA显卡驱动
下载 NVIDIA 官方驱动 | NVIDIA
(3)指定的Visual Studio版本
可以是社区版(免费)或专业版(试用后需要付费)及以上版本;
版本号要求:17.13以下版本(不包含17.13),因为在官方社区文档中,微软官方已确认17.13该版本与CUDA不兼容,会导致CUDA安装失败,并且经过测试,17.14版本也没有得到修复。
新系统安装CUDA12.8卡在installing Nsight visual studio edtion界面不动的解决方案_cuda12.8安装失败-CSDN博客
(4)最新的CUDA版本
CUDA 工具包 12.8 Update 1 下载 |NVIDIA 开发人员
目前最新的是CUDA12.812.8 Update 1;
Window主系统上已安装的CUDA版本号应大于或等于WSL中要安装的版本;
CUDA从12.6版开始,能自动更新环境变量和管理系统上之前的旧版本,CUDA的.exe安装包在安装时会自动检测并卸载旧版本。
温馨提示:为避免生产环境受影响,请注意对系统上的虚拟环境进行备份!
好消息,最新CUDA和cuDNN安装,俩都可以用exe安装包直装了 CUDA12.6.3和cuDNN9.6.0 Windows系统 省事_cuda最新版本-CSDN博客
(5)最新的cuDNN版本
cuDNN 9.8.0 Downloads | NVIDIA Developer
目前最新的是cuDNN 9.8.0;
从9.7.X版本开始,下载cuDNN已经无需注册登录了,可以直接下载;
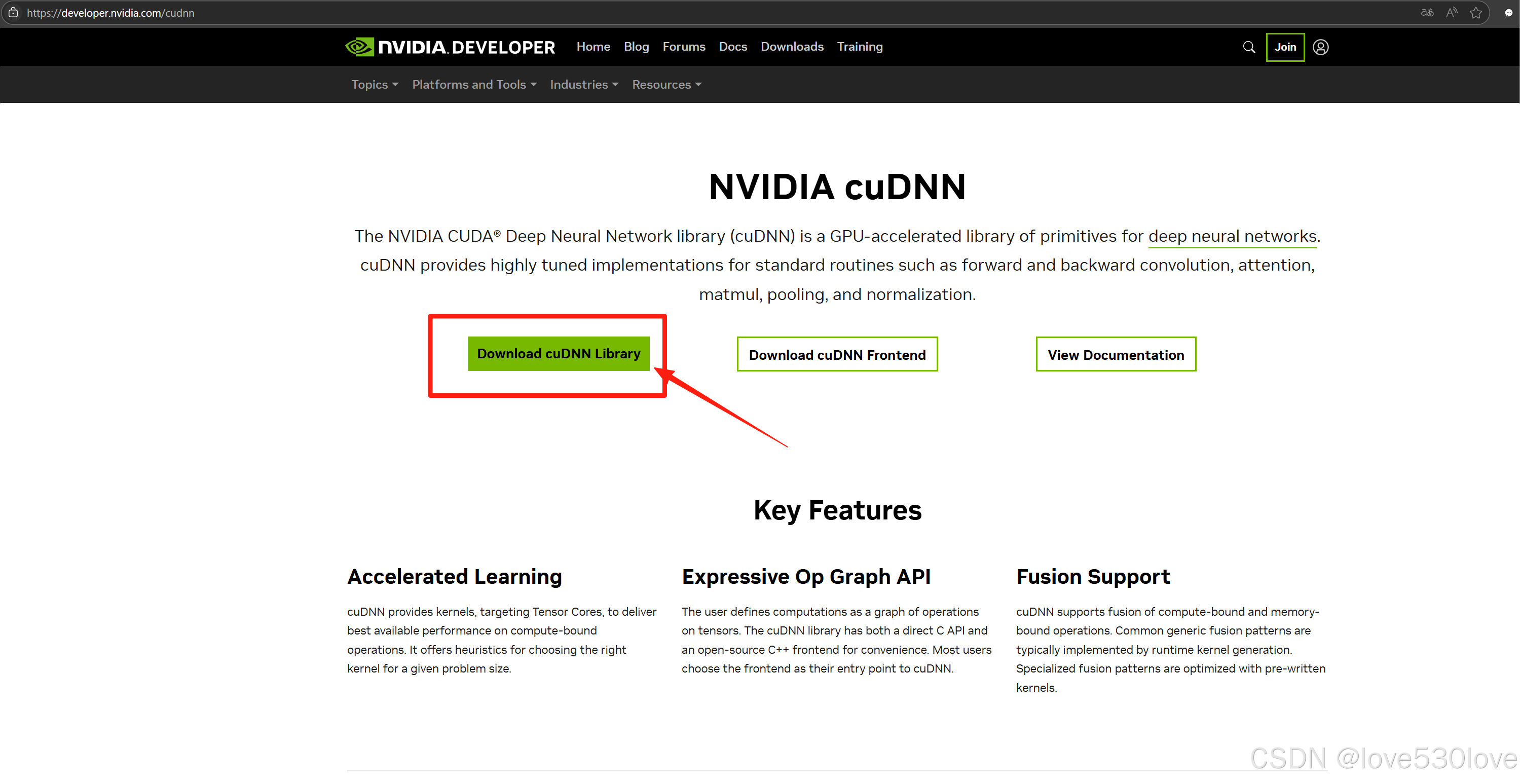
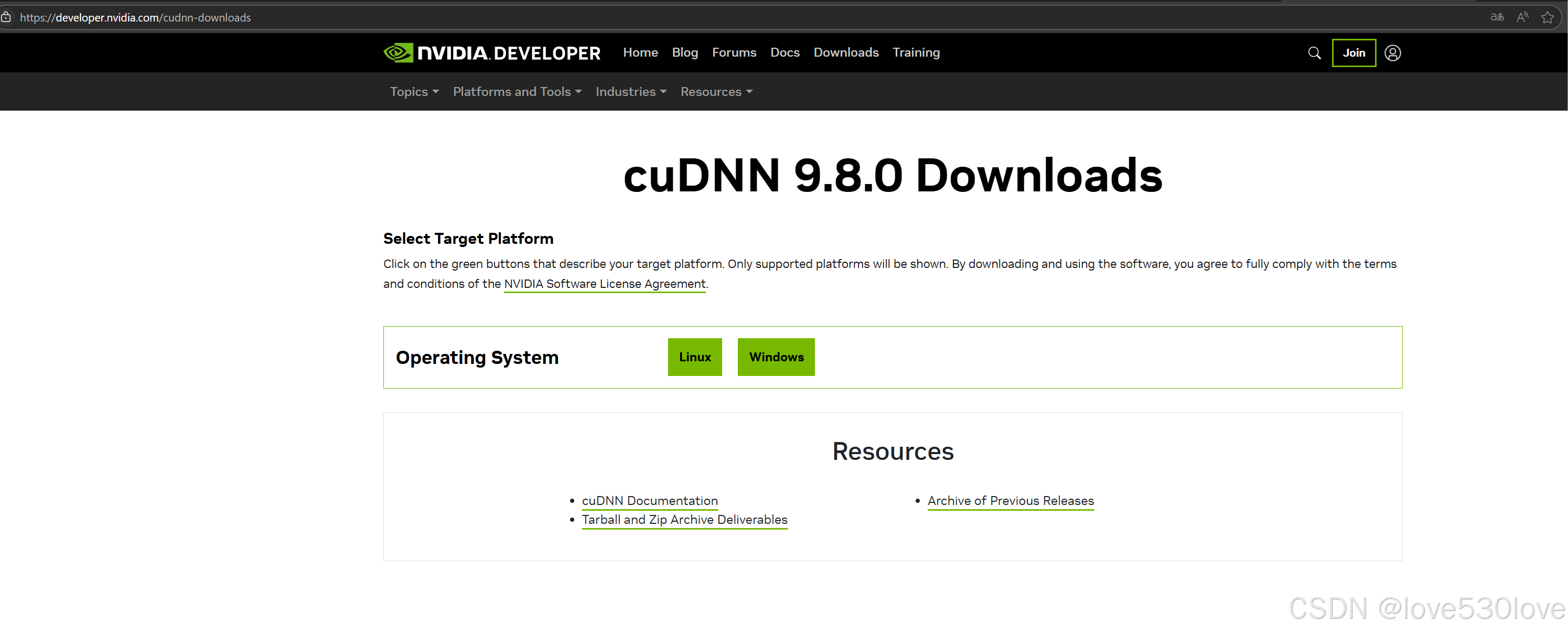
下载最新的cuDNN版本,目前最新的cuDNN可以通过.exe文件来安装,该.exe安装包安装后会自动匹配已安装的CDUA进行安装cuDNN;
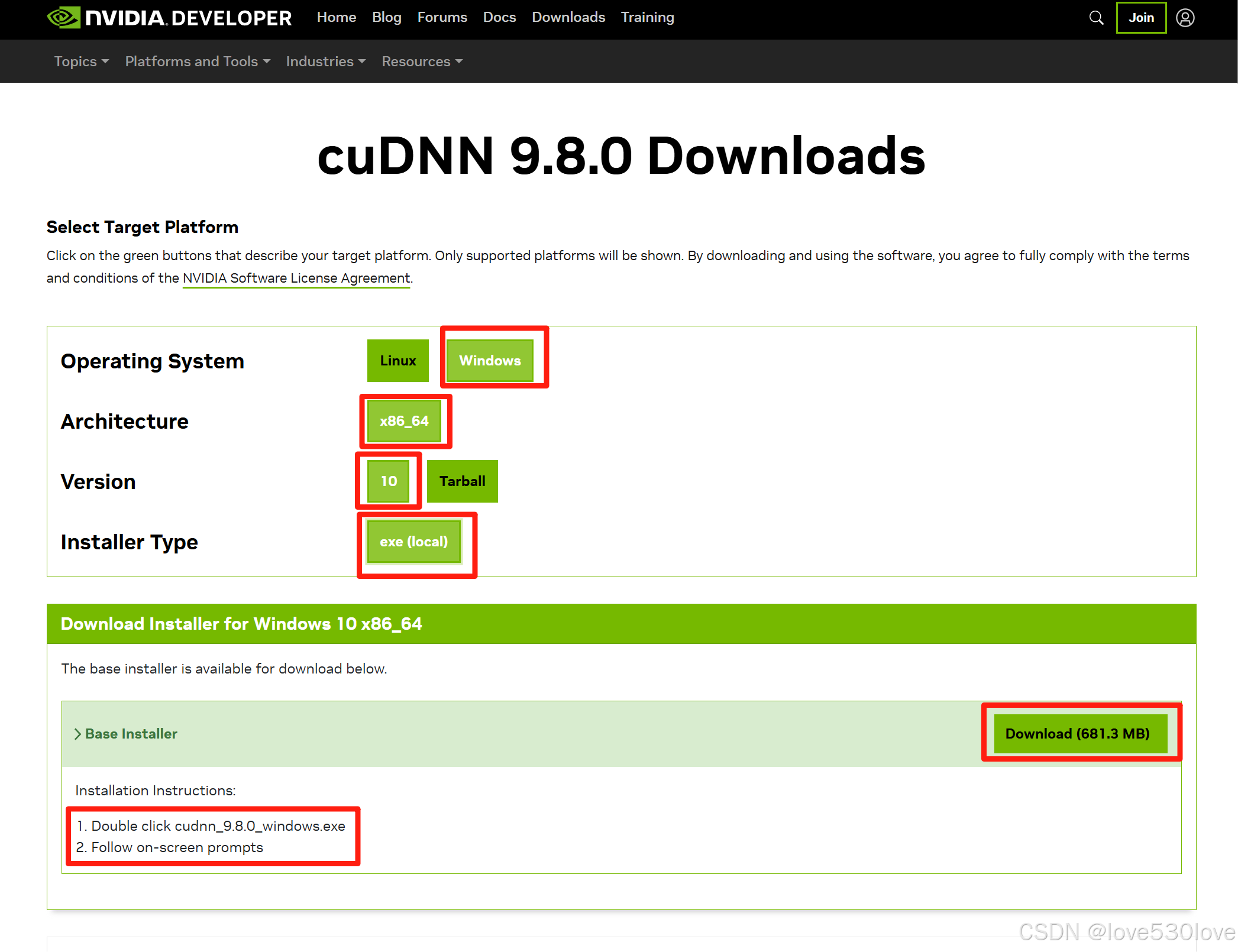
在Linux下通过命令安装,也是会自动匹配CUDA来安装cuDNN版本,这就是为什么明明指定安装的是9.8.0版本的cuDNN,但安装完成后验证时,显示的却是cuDNN其他版本号的原因之一。
验证PyTorch深度学习环境Torch和CUDA还有cuDNN是否正确配置的命令_验证pytorch和cuda的命令-CSDN博客
(6)正确安装并稳定运行的WSL-Linux子系统
Windows Subsystem for Linux - Microsoft Apps 应用商店
安装 WSL | Microsoft Learn 官方文档
关于WSL稳定运行的几点建议:
A、建议C盘空间尽量留大一点;
可以把硬盘留一些未分配的隐藏空间,方便后期用于C盘或其他盘符空间的扩容。
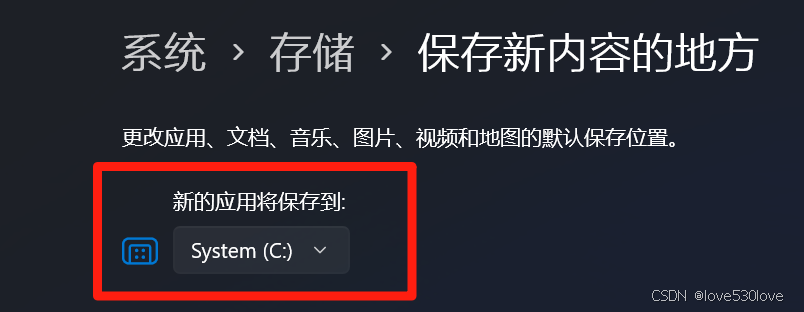
B、建议系统设置里“保存新内容的地方”保持默认的C盘;
设置——系统——储存——高级储存设置——保存新内容的地方——新的应用将保存到:
System (C:)
这里尽量保持默认的C盘,不要改动,因为查阅了大量资料和官方文档,微软官方目前也无法处理改动后的WSL启动错误和运行不稳定问题。
(此前我一直是把这里改到D盘,但后来实在是修复怕了,修复过程相当艰辛,往往需要查阅数百个网页和网友对话,还有一个是修复后的深度学习环境配置过程也比较耗时)
C、设置WSL的网络自动代理
不要直接去碰WSL的配置文件,而是通过下文中记述的用图形界面设置选项进行设置。
WLS2怎么设置网络自动代理_wls 网络模式解析-CSDN博客
WIN11 中已安装 LINUX 子系统出现 WSL 0x80071772 错误的解决方案_wslregisterdistribution failed with error: 0x80071-CSDN博客
排查适用于 Linux 的 Windows 子系统问题 | Microsoft Learn
超详细Windows10/Windows11 子系统(WSL2)安装Ubuntu20.04(带桌面环境)_wsl安装ubuntu20.04-CSDN博客
简单的WSL问题可以查阅相关疑难解答。
(7)正确安装并确定运行的Podman Desktop
Podman Desktop:现代轻量容器管理利器(Podman与Docker)-CSDN博客
Troubleshooting | Podman Desktop 故障排除
(8)Podman Desktop自带的podman-machine-default子系统
一般情况下这个不用手动安装,正常是安装Podman Desktop过程中,选中WSL和Hyper-V后自动生成的。

(9)安装Windows主系统上的其他必要程序或组件
这个范围比较广,包括但不限于上边提到的:NVIDIA显卡驱动程序、适用于Linux的Windows子系统(组件)、虚拟机平台(组件)、虚拟机监控平台(组件)、Hyper-V等(组件)、Visual Studio Community、CUDA、cuDNN、PyCharm Community、Git、GitHub Desktop、Podman Desktop、CMake、Visual Studio 生成工具、Microsoft C++ 生成工具、IncrediBuild等等程序或组件。
请根据实际情况有针对性地进行安装调试和配置。
2、安装步骤简记
A、先处理Window主系统里的必要程序或组件;
B、再处理WSL中的安装和相关问题:
(1)查询并确认系统版本和相关信息<podman-machine-default(WSL-Linux)>
cat /etc/os-release(2)确认或处理系统GPU的支持情况<podman-machine-default(WSL-Linux)>
nvidia-smi如果nvidia-smi输出失败,则需要另外的处理,将在下一章节中详细记录。
(3)安装对应系统的必要包和组件<podman-machine-default(WSL-Linux)>
如wget、curl、bash、nano等
(4)安装CUDA(使用官网命令在线安装)
试了官方提供的三种方法,其中在线安装(network)比较容易成功配置。
(5)配置CUDA的系统环境变量<podman-machine-default(WSL-Linux)>
打开系统环境变量编辑器;
粘贴添加变量内容(变量值);
关闭系统环境变量编辑器;
用命令使系统环境变量生效;
(6)验证CUDA的安装
nvcc -Vnvidia-smi(7)确认安装 或 不安装NVIDIA 的开源驱动程序
如果上一步的命令执行后输出都没问题,则不要安装NVIDIA CUDA官网提供的开源驱动;
如果上一步的命令执行后输出有问题,则安装NVIDIA CUDA官网提供的开源驱动进行调试;
(8)安装cuDNN(使用官网命令本地安装)
试了官方提供的两种方法,其中本地安装(local)比较容易成功配置。
(9)验证cuDNN的系统环境变量
一般不用手动配置cuDNN的系统环境变量,因为cuDNN是安装到CUDA的目录中,在前边配置CUDA系统环境变量时,已经包含这些目录;
这一步是暂时性的检验cuDNN是否已被正确包含在系统环境变量中。
(10)暂时性地验证cuDNN的安装
通过简单的命令,暂时性的验证cuDNN的安装结果,后续会用专门的命令统一进行验证,因为python和有些库还没安装,所以统一验证的命令暂时还不能运用。
(11)安装Anaconda或Miniconda
用来管理python版本和conda虚拟环境
(12)安装PyTorch
通过安装PyTorch来检验podman-machine-default(WSL-Linux)对PyTorch GPU的支持。
(13)通过命令全面验证CUDA、cuDNN、Anaconda、PyTorch 等是否安装成功
全面验证podman-machine-default(WSL-Linux)的深度学习环境搭建情况
(14)安装Git
(15)验证Git的安装
(16)配置Git
(17)其他安装和配置(自定义/可选)…
如果顺利的话,流程至此,WSL-podman-machine-default的深度学习环境将基本搭建完毕!
三、详细的安装和配置步骤:
在本章中,我们将详细讲解如何在 podman-machine-default(WSL 环境中的 Fedora Linux 41)中安装 CUDA、cuDNN、Anaconda、PyTorch 等深度学习所需的软件包,并完成必要的环境配置。通过这些步骤,我们将能够在 Windows 系统下的容器化 Linux 环境中运行深度学习任务。
(一)查询并确认系统版本和相关信息<podman-machine-default(WSL-Linux)>
可以通过以下命令查询系统版本和相关信息:
打开系统里的podman-machine-default图标,进入podman-machine-default系统

运行以下命令查询系统相关信息:
cat /etc/os-release(因为是回测重现,所以我截图中的终端显示是(base)虚拟环境,仅作展示,不影响后续操作)
或者是在pycharm终端中打开podman-machine-default虚拟机也是一样的效果:
这将显示系统的详细信息,例如:
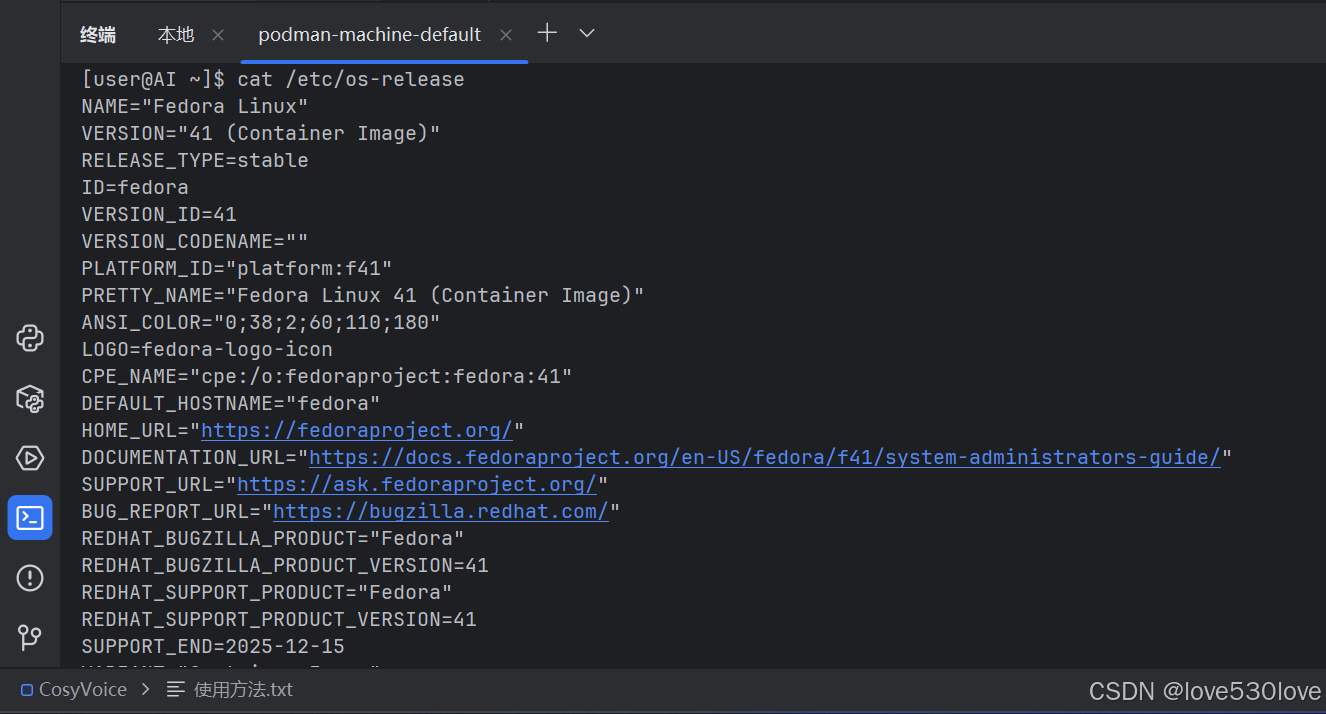
输出内容摘录如下:
[user@AI ~]$ cat /etc/os-release
NAME="Fedora Linux"
VERSION="41 (Container Image)"
RELEASE_TYPE=stable
ID=fedora
VERSION_ID=41
VERSION_CODENAME=""
PLATFORM_ID="platform:f41"
PRETTY_NAME="Fedora Linux 41 (Container Image)"
ANSI_COLOR="0;38;2;60;110;180"
LOGO=fedora-logo-icon
CPE_NAME="cpe:/o:fedoraproject:fedora:41"
DEFAULT_HOSTNAME="fedora"
HOME_URL="https://fedoraproject.org/"
DOCUMENTATION_URL="https://docs.fedoraproject.org/en-US/fedora/f41/system-administrators-guide/"
SUPPORT_URL="https://ask.fedoraproject.org/"
BUG_REPORT_URL="https://bugzilla.redhat.com/"
REDHAT_BUGZILLA_PRODUCT="Fedora"
REDHAT_BUGZILLA_PRODUCT_VERSION=41
REDHAT_SUPPORT_PRODUCT="Fedora"
REDHAT_SUPPORT_PRODUCT_VERSION=41
SUPPORT_END=2025-12-15
VARIANT="Container Image"
VARIANT_ID=container
[user@AI ~]$ 从输出的 /etc/os-release 文件内容来看,我的系统是 Fedora Linux 41 (Container Image)。
这意味着我正在使用的是一个基于 Fedora Linux 41 的容器镜像版本。
以下是一些关键信息的总结:
1、系统版本信息
-
名称:Fedora Linux
-
版本:41 (Container Image)
-
发行版类型:Stable
-
ID:fedora
-
版本号:41
-
平台 ID:platform:f41
-
完整名称:Fedora Linux 41 (Container Image)
-
支持结束日期:2025-12-15
2、官方资源链接
-
主页:Fedora Linux | The Fedora Project
-
文档:https://docs.fedoraproject.org/en-US/fedora/f41/system-administrators-guide/
-
支持论坛:Ask Fedora - Fedora Discussion
-
Bug 报告:Red Hat Bugzilla Main Page
确认我们在 podman-machine-default 中运行的是 Fedora Linux 41,确保后续安装的包和驱动与系统版本兼容。
(二)确认或处理系统GPU的支持情况<podman-machine-default(WSL-Linux)>
在上一步中,我们确认了当前运行的podman-machine-default系统版本是 Fedora Linux 41。
然后需要确认一下podman-machine-default对系统GPU的支持情况。
在podman-machine-default中输入以下命令查询:
nvidia-smi1、 状态一:输出正常
如果输出如下:
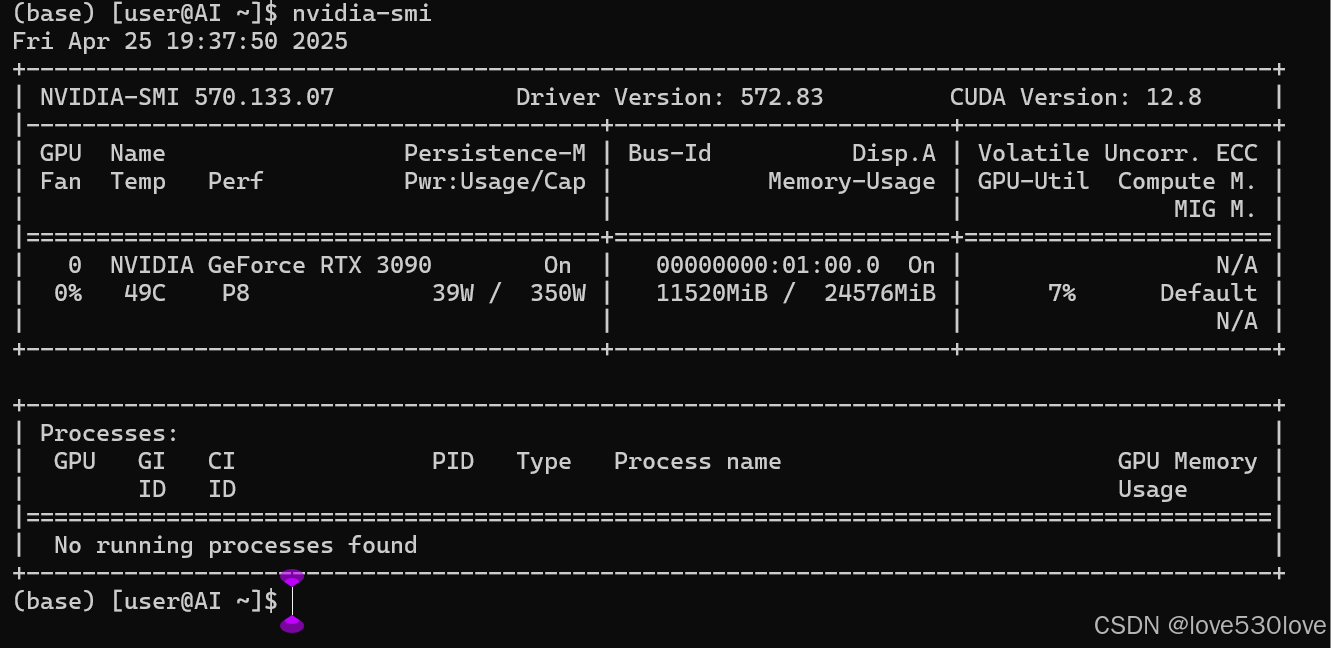
则表明此时podman-machine-default与Windows主系统的GPU通信是正常的,因为后边有些操作会导致掉驱动,所以我们在下边的文中会时不时再次使用该命令来确认podman-machine-default系统的GPU支持状态。
2、状态二:输出异常
如果输出是:
[user@AI ~]$ nvidia-smi
-bash: nvidia-smi: command not found
[user@AI ~]$ nvcc -V
-bash: nvcc: command not found
[user@AI ~]$
2.1、 输出异常command not found的解决方案:
-bash: nvidia-smi: command not found
-bash: nvcc: command not found
2.1.1分析可能的原因:
如果podman-machine-default(WSL-Linux)提示 `nvidia-smi` 和 `nvcc` 命令未找到,这可能是因为以下原因之一:
1、Windows主系统中NVIDIA 驱动问题;
2、Windows主系统中CUDA 工具包问题;
3、Windows主系统中环境变量问题;
4、WSL-Linux的安装问题;
5、WSL 的 NVIDIA 驱动支持问题。
……
在1、2、3、4确认没问题之后,其中第5才是最常见也是最易发生的问题。
2.1.2 解决方法:
第5点 WSL 的 NVIDIA 驱动支持问题 的解决方法:
配置 WSL 以支持 NVIDIA 驱动
在 Windows 端,确保NVIDIA 驱动和CUDA工具包等正常后,可以通过以下方式修复在 WSL 中使用 nvidia-smi命令输出异常的问题:
-
安装 WSL 2 的 NVIDIA 驱动:
运行以下命令,将 NVIDIA 驱动的路径添加到 WSL 的 PATH 中
echo 'export PATH=$PATH:/usr/lib/wsl/lib' >> ~/.bashrc
source ~/.bashrc-
验证
nvidia-smi是否可用:
nvidia-smi如果配置正确,应该可以看到 GPU 的状态信息。
(三)安装对应podman-machine-default(WSL-Linux)系统的必要包和组件
如wget、curl、bash、nano等
sudo dnf update
sudo dnf install wget
sudo dnf install curl
sudo dnf install bash
sudo dnf install nano这些命令都是基于 DNF(Dandified Yum)的 Linux 包管理操作,主要用于在 Fedora、CentOS Stream 或其他基于 RPM 的系统中管理软件包。
以下是每个命令的具体作用:
1. sudo dnf update
- 作用:更新系统中所有已安装的软件包到最新版本。
- 细节:
sudo:以管理员权限运行命令。dnf update:检查仓库中的新版本,并升级所有软件包(包括安全补丁和功能更新)。
- 使用场景:保持系统安全和稳定性,修复漏洞,获取最新功能。
2. sudo dnf install wget
- 作用:安装
wget工具。 - 细节:
wget是一个命令行下载工具,支持 HTTP/HTTPS/FTP 协议,常用于从网络下载文件。- 示例用途:
wget https://example.com/file.zip直接下载文件到当前目录。
- 使用场景:需要从终端下载文件时使用。
3. sudo dnf install curl
- 作用:安装
curl工具。 - 细节:
curl是一个多功能命令行工具,支持 HTTP/HTTPS/FTP/SMTP 等协议,常用于传输数据或与 API 交互。- 示例用途:
curl https://example.com显示网页内容,或curl -O https://example.com/file.zip下载文件。
- 使用场景:需要更灵活的网络请求(如调试 API、上传下载)时使用。
4. sudo dnf install bash
- 作用:安装或更新
Bash(Bourne Again Shell)。 - 细节:
Bash是大多数 Linux 系统的默认命令行解释器(Shell),用于执行命令和编写脚本。- 通常系统已预装,此命令可能用于修复损坏的安装或升级到新版本。
- 使用场景:需要自定义 Shell 环境或修复 Shell 相关问题时使用。
5. sudo dnf install nano
- 作用:安装
nano文本编辑器。 - 细节:
nano是一个简单易用的终端文本编辑器,适合新手快速编辑配置文件(如/etc/hosts)。- 功能比
vim更简单,自带快捷键提示(如Ctrl+O保存,Ctrl+X退出)。
- 使用场景:需要编辑文本文件但没有图形界面时使用。
小结
- 系统维护:
dnf update保持系统最新。 - 网络工具:
wget和curl用于下载和网络交互。 - 基础工具:
bash和nano是日常命令行操作的核心工具。
如果有具体使用场景(如开发、服务器管理),可以进一步优化安装的软件包列表!
(四)安装CUDA(使用官网命令在线安装)
CUDA 是 NVIDIA 提供的并行计算平台和编程模型,它支持 GPU 加速。在 podman-machine-default 上安装 CUDA 时,我们将使用 NVIDIA 官方的安装脚本。
试了官方提供的三种方法,其中在线安装(network)比较容易成功配置。
以下是官网的一组自动执行安装命令示例:
sudo dnf config-manager addrepo --from-repofile https://developer.download.nvidia.com/compute/cuda/repos/fedora41/x86_64/cuda-fedora41.repo
sudo dnf clean all
sudo dnf -y install cuda-toolkit-12-8此命令会自动安装 CUDA 以及相关的工具包和示例。
详细操作:
1、打开CUDA官网
CUDA Toolkit 12.8 Update 1 Downloads | NVIDIA Developer
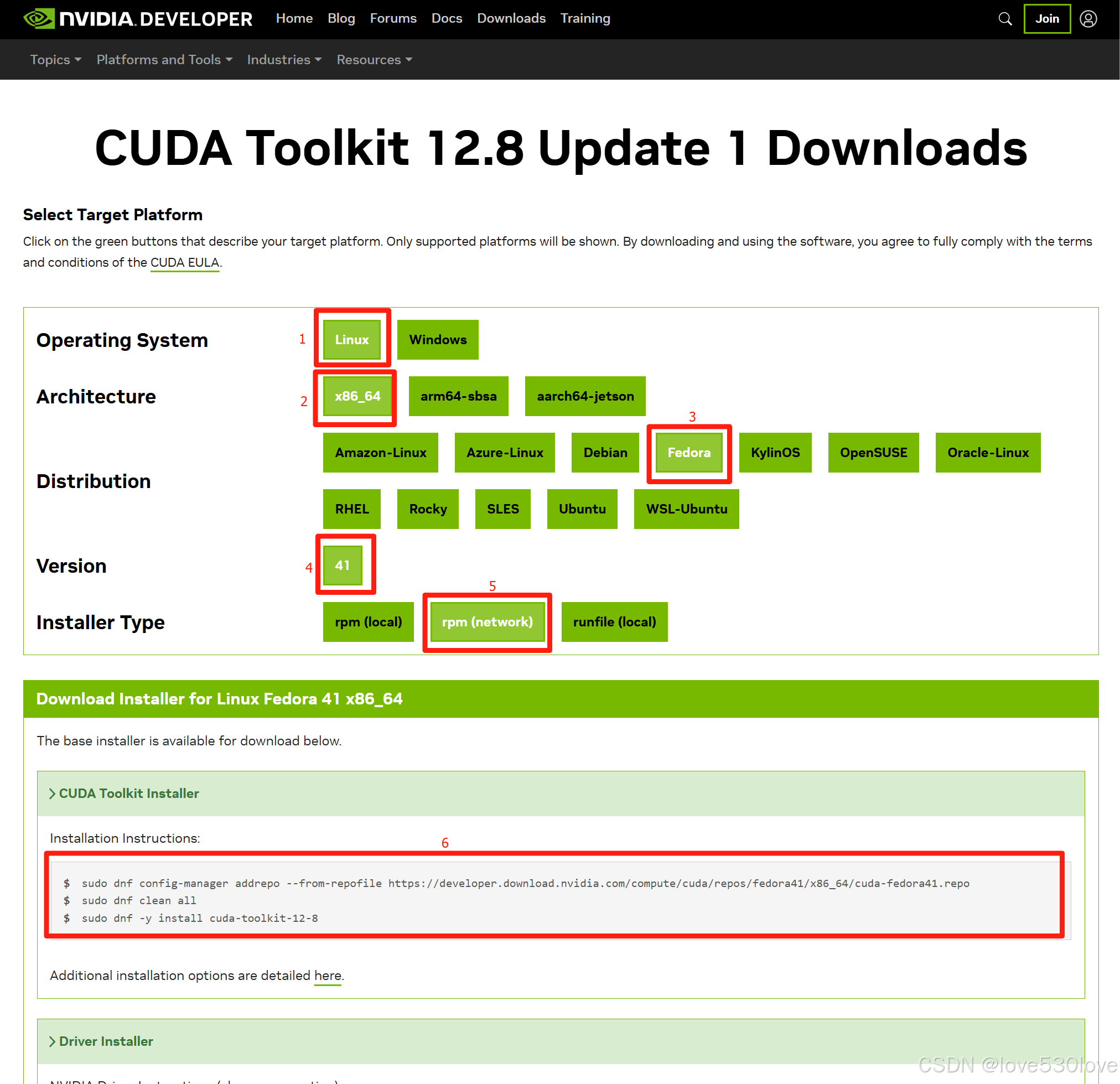
2、选择系统和安装方式:
这里要选对:
2.1、系统类型(Linux);
2.2、架构(x86_64);
2.3、对应的Linux操作系统(Fedora);
2.4、对应的Linux操作系统版本号(41);
2.5、安装或部署工具中的安装方法选项,每个选项都代表不同的安装方式:
-
rpm (local):
-
这个选项表示使用 RPM 包管理器从本地文件系统安装软件包。
-
用户需要先下载 RPM 包到本地,然后通过包管理器进行安装。
-
-
rpm (network):
-
这个选项表示通过网络使用 RPM 包管理器安装软件包。
-
这通常意味着包管理器会从远程仓库或服务器下载 RPM 包并进行安装,适用于需要从网络获取软件包的情况。
-
-
runfile (local):
-
这个选项表示使用本地的可执行文件(runfile)来安装或运行软件。
-
用户需要先下载可执行文件到本地,然后直接运行该文件进行安装或启动软件。
-
这些选项提供了不同的安装和部署方法,我们可以根据自己的网络环境和需求选择合适的方式。
例如,在没有网络连接的环境中,可能会选择本地安装方式;而在需要快速部署或更新时,可能会选择网络安装方式。
3、复制官网中的命令粘贴到podman-machine-default终端中:
比如上图中我选择的rpm (network)网络安装方式:
sudo dnf config-manager addrepo --from-repofile https://developer.download.nvidia.com/compute/cuda/repos/fedora41/x86_64/cuda-fedora41.repo
sudo dnf clean all
sudo dnf -y install cuda-toolkit-12-8过程会比较漫长,请提前保持网络通畅





4、如果一种方式安装失败,可以更换网络环境重复尝试,或者自由选择更换安装方式。
如果链接有效,但命令执行失败,多数情况下可能是网络问题。请尝试重新运行命令。
或者更换安装方式<rpm (local) / rpm (network) / runfile (local)>
(五)配置CUDA的系统环境变量<podman-machine-default(WSL-Linux)>
安装完 CUDA 后,需要配置系统环境变量,使其生效。我们可以通过以下步骤进行配置:
1、查找CUDA的安装路径:
find /usr/local -name nvcc 2>/dev/nullfind /usr/local -name nvcc 2>/dev/null
[user@AI ~]$ find /usr/local -name nvcc 2>/dev/null
/usr/local/cuda-12.8/bin/nvcc
[user@AI ~]$
我们已经找到了 nvcc 的安装路径,它位于 /usr/local/cuda-12.8/bin/nvcc。
现在,我们可以设置 CUDA 环境变量来确保系统能够正确地找到 CUDA Toolkit。
2、设置环境变量
打开我们的 shell 配置文件,例如 ~/.bashrc:
vi ~/.bashrc或:
nano ~/.bashrc打开之后,在文件的末尾添加以下行:
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH保存并关闭文件。
3、重新加载配置文件:
source ~/.bashrc这样,系统环境变量配置成功。
4、用vi 编辑器设置环境变量详细流程示例
以下是在 ~/.bashrc 文件中添加 CUDA 环境变量的步骤:
-
打开终端。
-
使用文本编辑器打开
~/.bashrc文件。如果我们的系统中没有nano,我们可以尝试使用vi或vim:vi ~/.bashrc -
使用
vi或vim编辑文件,按i键进入插入模式。 -
在文件的末尾添加以下行(确保替换
<cuda-version>为实际的版本号,例如12.8):export CUDA_HOME=/usr/local/cuda-12.8 export PATH=$PATH:$CUDA_HOME/bin export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$CUDA_HOME/lib64 -
按
Esc键退出插入模式。 -
输入
:wq然后按Enter键保存并退出vi或vim。
-
重新加载配置文件,使更改生效:

source ~/.bashrc -
验证环境变量是否设置正确:
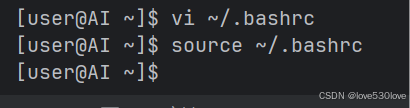
echo $CUDA_HOME echo $PATH echo $LD_LIBRARY_PATH
确保这些环境变量的值正确指向了我们的 CUDA Toolkit 安装路径。
(六)验证CUDA的安装
nvidia-smi1、 测试 CUDA Toolkit
为了验证 CUDA Toolkit 是否正确安装和配置,我们可以尝试运行以下命令检查版本:
在podman-machine-default终端中运行以下命令:
nvcc -V或使用:
nvcc --version
如果安装成功,我们应该能看到类似以下输出,显示 CUDA 版本信息:
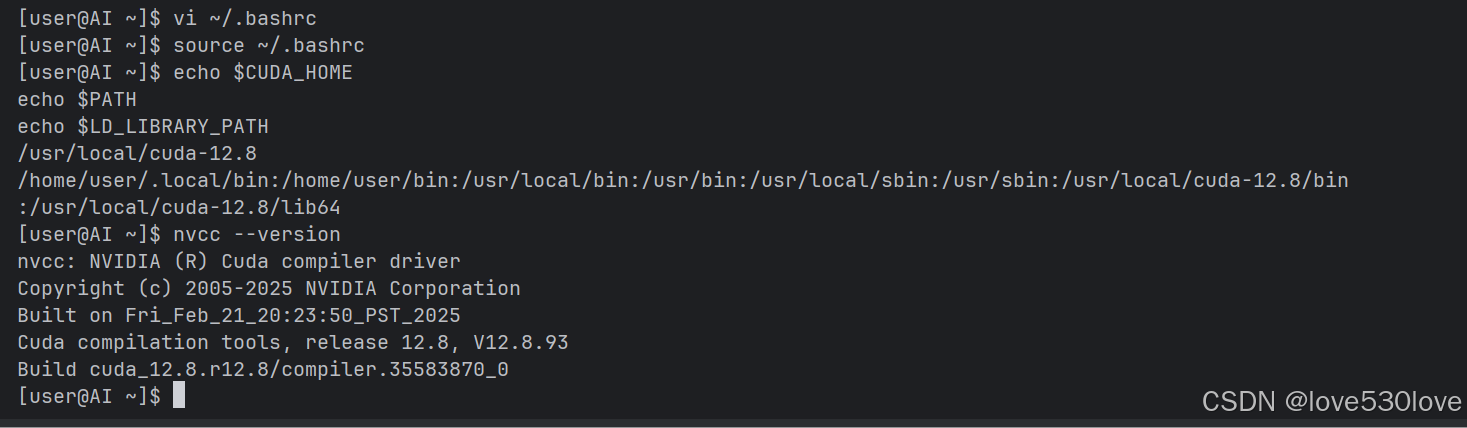
[user@AI ~]$ nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2025 NVIDIA Corporation
Built on Fri_Feb_21_20:23:50_PST_2025
Cuda compilation tools, release 12.8, V12.8.93
Build cuda_12.8.r12.8/compiler.35583870_0
[user@AI ~]$
如果 nvcc 命令可用并且显示了版本信息,则说明 CUDA Toolkit 安装和环境变量设置成功。
2、再次确认podman-machine-default(WSL-Linux)的NVIDIA支持
另外,为了确保podman-machine-default的NVIDIA显卡驱动在安装CUDA后仍保持正常状态,此时可用以下命令再次确认:
nvidia-smi3、注意事项
-
确保在添加环境变量时没有拼写错误,特别是路径和变量名。
-
如果我们使用的是其他 shell(如 zsh 或 fish),我们需要编辑相应的配置文件(如
~/.zshrc或~/.config/fish/config.fish)。 -
如果我们在系统中没有找到
nvcc,可能需要重新安装 CUDA Toolkit 或者查找安装日志来确定其安装位置。
通过以上步骤,我们应该能够正确设置 CUDA 环境变量,并确保我们的系统能够使用 CUDA Toolkit。
在 Windows 11 下的 WSL - Ubuntu 24.04 中安装 CUDA 的记录_cuda-wsl-ubuntu.pin-CSDN博客
4、安装异常的处理
Complete!
[user@AI ~]$ nvcc --version
-bash: nvcc: command not found
[user@AI ~]$ echo $PATH /home/user/.local/bin:/home/user/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/usr/lib/wsl/lib [user@AI ~]$ echo $LD_LIBRARY_PATH
[user@AI ~]$
如果遇到nvcc: command not found的情况,请查看以下方案:
从输出来看,nvcc 命令未找到,这表明 CUDA 的路径可能未正确添加到我的环境变量中,或者 CUDA 未正确安装。
同时,$LD_LIBRARY_PATH 也是空的,这意味着 CUDA 的库路径也未配置。
我们需要重新检查并配置这些环境变量。
4.1、检查 CUDA 安装路径
首先,确认 CUDA 是否已经安装在 /usr/local/cuda 目录下。运行以下命令:
ls /usr/local/cuda如果 CUDA 安装成功,你应该会看到类似以下的目录结构:

bin doc include lib64 libnsight nsight samples share version.txt
如果没有看到这些目录,说明 CUDA 可能未正确安装,或者安装路径与默认路径不同。
4.2配置环境变量
根据你的输出,$PATH 中没有包含 /usr/local/cuda/bin,而 $LD_LIBRARY_PATH 是空的。我们需要将 CUDA 的路径添加到这些环境变量中。
编辑 ~/.bashrc 文件,添加以下内容:
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH然后运行以下命令使环境变量生效:
source ~/.bashrc
4.3、验证环境变量配置
运行以下命令验证环境变量是否已正确配置:
echo $PATH输出中应该包含 /usr/local/cuda/bin。
运行以下命令:
echo $LD_LIBRARY_PATH输出中应该包含 /usr/local/cuda/lib64。
4.4、验证 CUDA 安装
重新运行以下命令验证 nvcc 是否可用:
nvcc --version如果配置正确,你应该会看到类似以下的输出:
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2025 NVIDIA Corporation
Built on Fri_Apr__5_16:00:00_PDT_2025
Cuda compilation tools, release 12.8, V12.8.0
4.5、如果仍然无法找到 nvcc
如果 nvcc 仍然无法找到,可能是因为 CUDA 未正确安装,或者安装路径与默认路径不同。你可以尝试以下步骤:
4.5.1、 检查 CUDA 安装路径
运行以下命令,查找 CUDA 的安装路径:
find / -type d -name "cuda" 2>/dev/null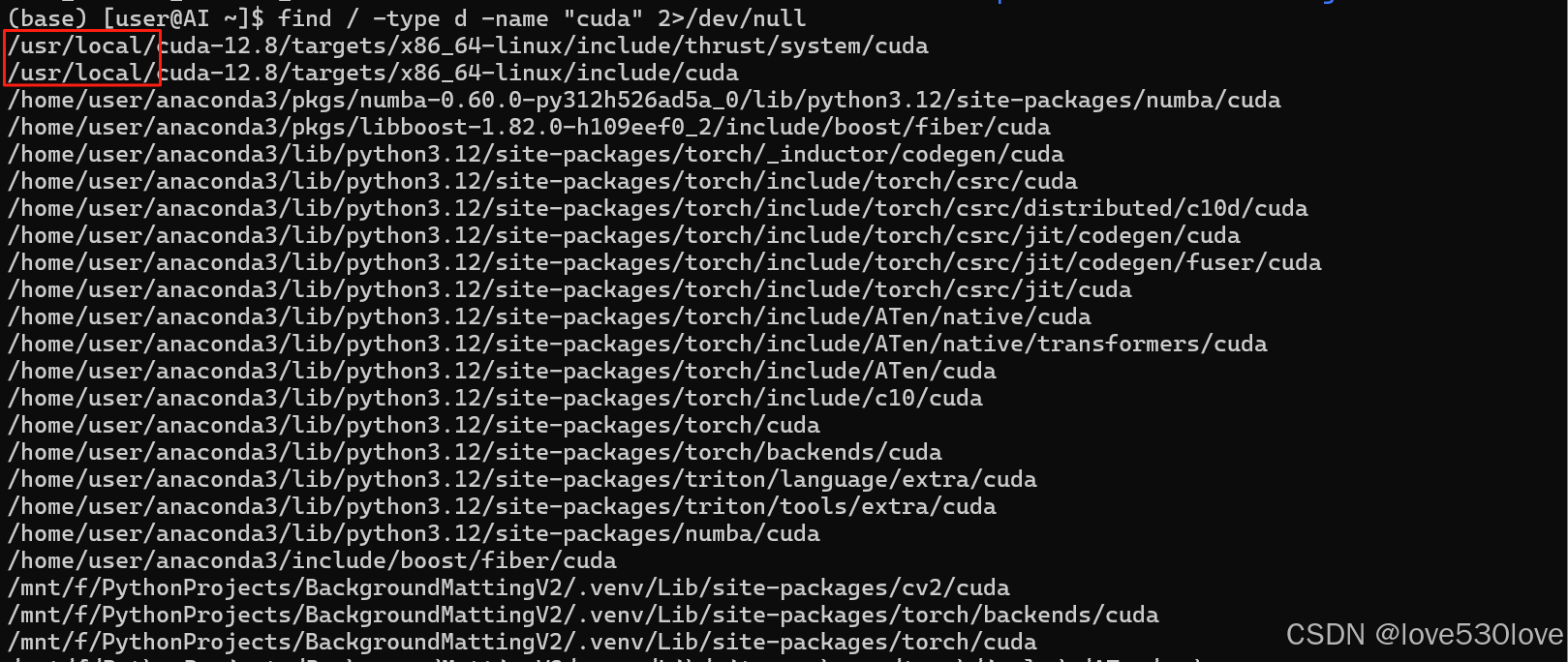
如果找到了其他路径(例如 /opt/cuda 或其他自定义路径),请将该路径替换为 /usr/local/cuda,并重新配置环境变量。
4.5.2、 重新安装 CUDA
如果 CUDA 未正确安装,可以尝试重新安装。运行以下命令:
sudo dnf clean all
sudo dnf makecache fast
sudo dnf -y install cuda-toolkit-12-8
5、 小结
通过以上步骤,匀应该能够成功配置 CUDA 的环境变量并验证 nvcc 是否可用。
如果仍然遇到问题,请记录下更多详细信息,例如:
-
CUDA 的安装路径(如果找到)。
-
安装过程中是否有任何错误信息。
然后认真地编写提示词然后发送给专业的AI以解决问题。
(七)确认 安装 或 不安装 NVIDIA 的开源驱动程序
如果上一步的命令执行后输出都没问题,则不要安装NVIDIA CUDA官网提供的开源驱动;
如果上一步的命令执行后输出有问题,则可尝试安装NVIDIA CUDA官网提供的开源驱动进行调试;
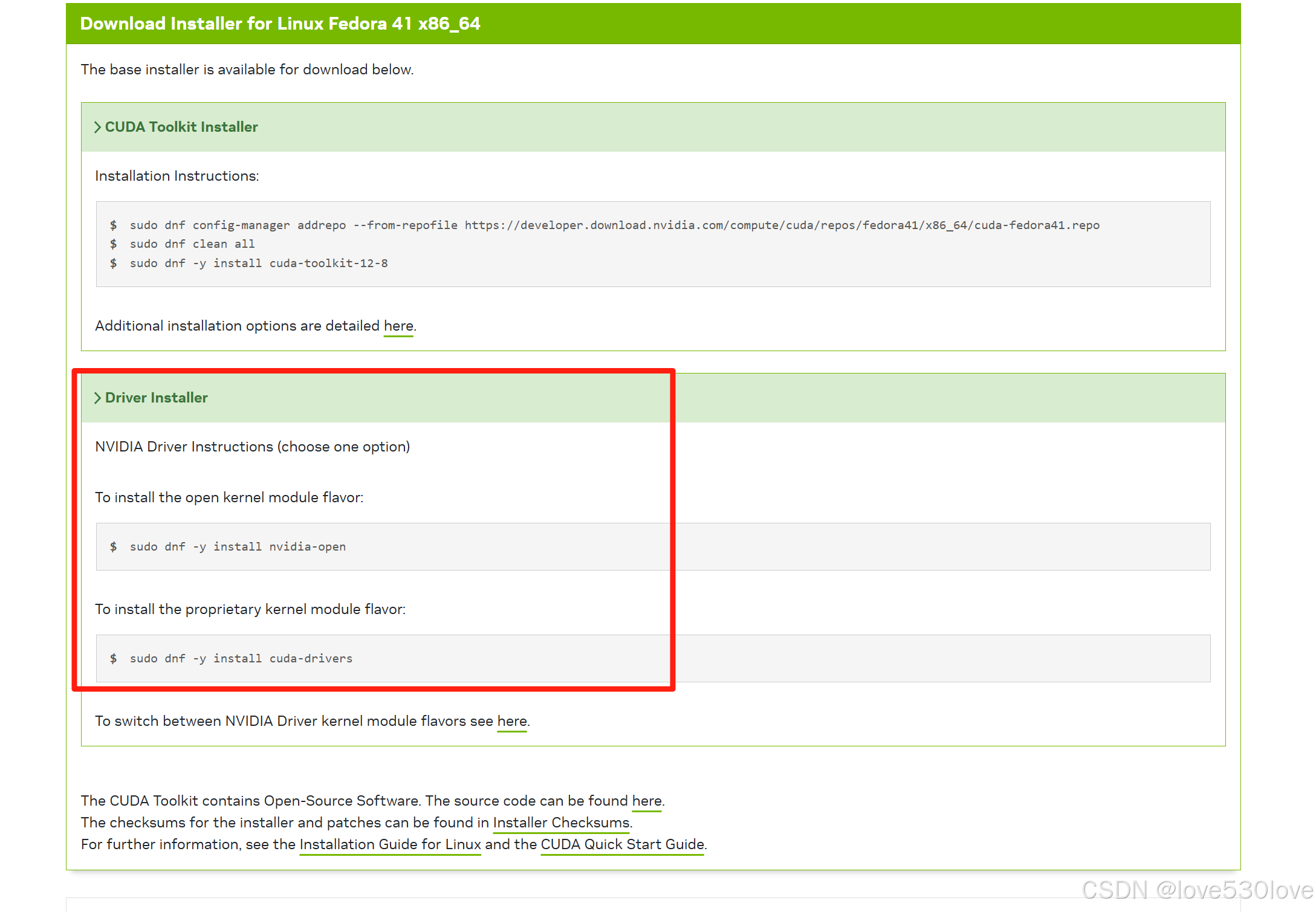
截图中提到的“驱动程序安装程序”是用于安装或更新 NVIDIA GPU 驱动的。
不需要安装的情况:
当执行完上一步的命令后,若输出结果一切正常,这就表明 CUDA Toolkit 已成功安装。与此同时,如果 nvidia-smi 命令也能够顺利运行,那就说明 NVIDIA 驱动程序已经正确安装在系统之中了。
一般而言,在使用官方提供的安装命令来安装 CUDA Toolkit 时,安装程序会自动处理驱动程序的安装事宜。
此外,如果 nvidia-smi 命令能够正常显示 GPU 的详细信息,并且在系统的使用过程中,没有遭遇任何与驱动相关的异常状况,比如图形界面显示异常、GPU 性能明显下降等问题,那么从常规角度来讲,确实没有必要再去进行驱动程序的重新安装或更新操作。
在这种驱动程序已正常安装且运行良好的情况下,切记不要安装 NVIDIA CUDA 官网所提供的开源驱动,以免引发不必要的系统冲突或其他问题。
需要安装的情况:
倘若我们希望确保所使用的 NVIDIA 驱动程序是最新版本,以便获得更出色的性能优化以及新功能支持,又或者在系统运行过程中遇到了诸如图形界面显示异常、GPU 性能不佳等与驱动相关的问题时,那么就应当考虑对驱动程序进行安装或更新操作。
在这些有必要安装或更新驱动的情形下,我们可以尝试安装 NVIDIA CUDA 官网提供的开源驱动,以此来对系统进行调试,从而解决可能存在的驱动相关问题。
可以通过以下命令来安装对cuda兼容性较好的驱动程序:
sudo dnf install cuda-drivers或者,如果你想要安装特定版本的驱动程序,可以使用 dkms 来安装:
sudo dnf install cuda-driversdkms在安装新的驱动程序之前,建议先查阅相关的文档或指南,以确保兼容性和正确的安装步骤。
小结:
总的来说,如果我们的系统已经能够正常识别和使用 GPU,并且没有遇到任何问题,那么通常没有必要再次安装驱动程序。
如果我们想要更新到最新版本或遇到了问题,那么可以考虑安装或更新驱动程序。
(八)安装cuDNN(使用官网命令本地安装)
cuDNN 是 NVIDIA 提供的 GPU 加速库,专门用于深度学习模型的训练和推理。
试了官方提供的两种方法,其中本地安装(local)比较容易成功配置。
要安装 cuDNN,可以使用以下步骤:
1、 安装 cuDNN 库(可选/非必须)
通常,在Fedora Linux 41上,我们需要安装以下两个包:
-
libcudnn:运行时库,用于运行依赖 cuDNN 的程序。 -
libcudnn-devel:开发库,用于编译依赖 cuDNN 的程序。
运行以下命令安装这些包:
sudo dnf install libcudnn9 libcudnn9-devel如果提示找不到这些包,可以先运行以下命令查看可用的 cuDNN 包:
dnf list available | grep libcudnn根据输出结果,选择正确的包名进行安装。
但一般情况下,使用官网的安装命令会省去一些手动处理依赖的步骤,请接着往下看。
2、用官网的命令进行安装
进入cuDNN官网:
建议使用rpm(local)进行安装。
cuDNN 9.8.0 Downloads | NVIDIA Developer
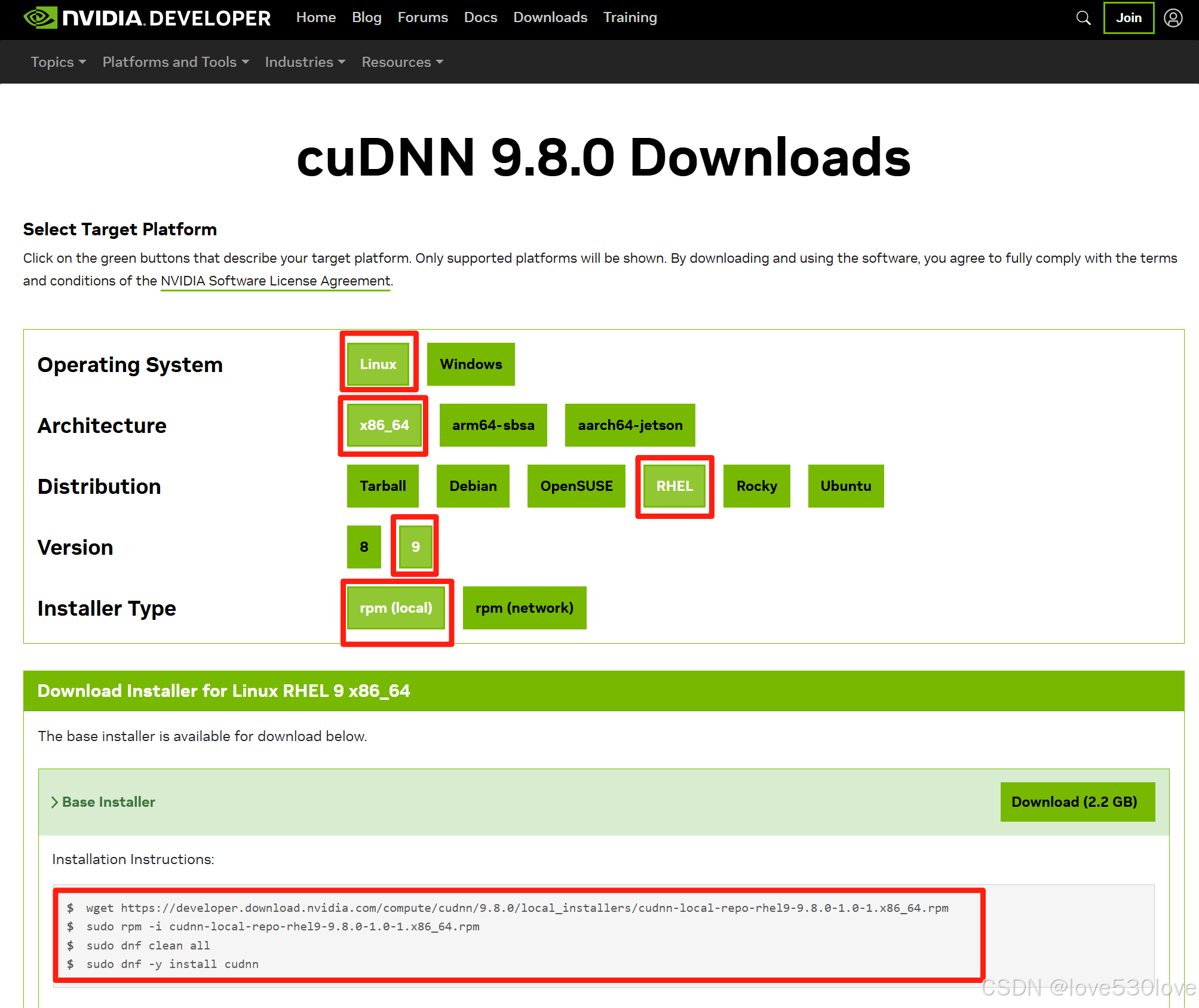
3、用rpm(local)安装命令:
wget https://developer.download.nvidia.com/compute/cudnn/9.8.0/local_installers/cudnn-local-repo-rhel9-9.8.0-1.0-1.x86_64.rpm
sudo rpm -i cudnn-local-repo-rhel9-9.8.0-1.0-1.x86_64.rpm
sudo dnf clean all
sudo dnf -y install cudnn4、手动下载安装:
如果网络不好,我们可以尝试下载安装包到本地安装:
点击“Download(2.2GB)”下载到Windows本地,比如我下载“cudnn-local-repo-rhel9-9.8.0-1.0-1.x86_64.rpm”安装包到E:/Downloads目录,则:
对应 WSL-podman-machine-default的目录就是“/mnt/e/Downloads”
cd /mnt/e/Downloads #进入储存目录
sudo dnf install cudnn-local-repo-rhel9-9.8.0-1.0-1.x86_64.rpm #安装cuDNN软件包5、 清理缓存并更新仓库
安装完仓库后,需要清理缓存并重新加载仓库信息,以确保 dnf 能够识别新添加的仓库:
sudo dnf clean all
sudo dnf makecache6、安装cuDNN前端(可选/非必须)
cuDNN前端GitHub项目地址
安装 cuDNN 前端 — NVIDIA cuDNN 安装
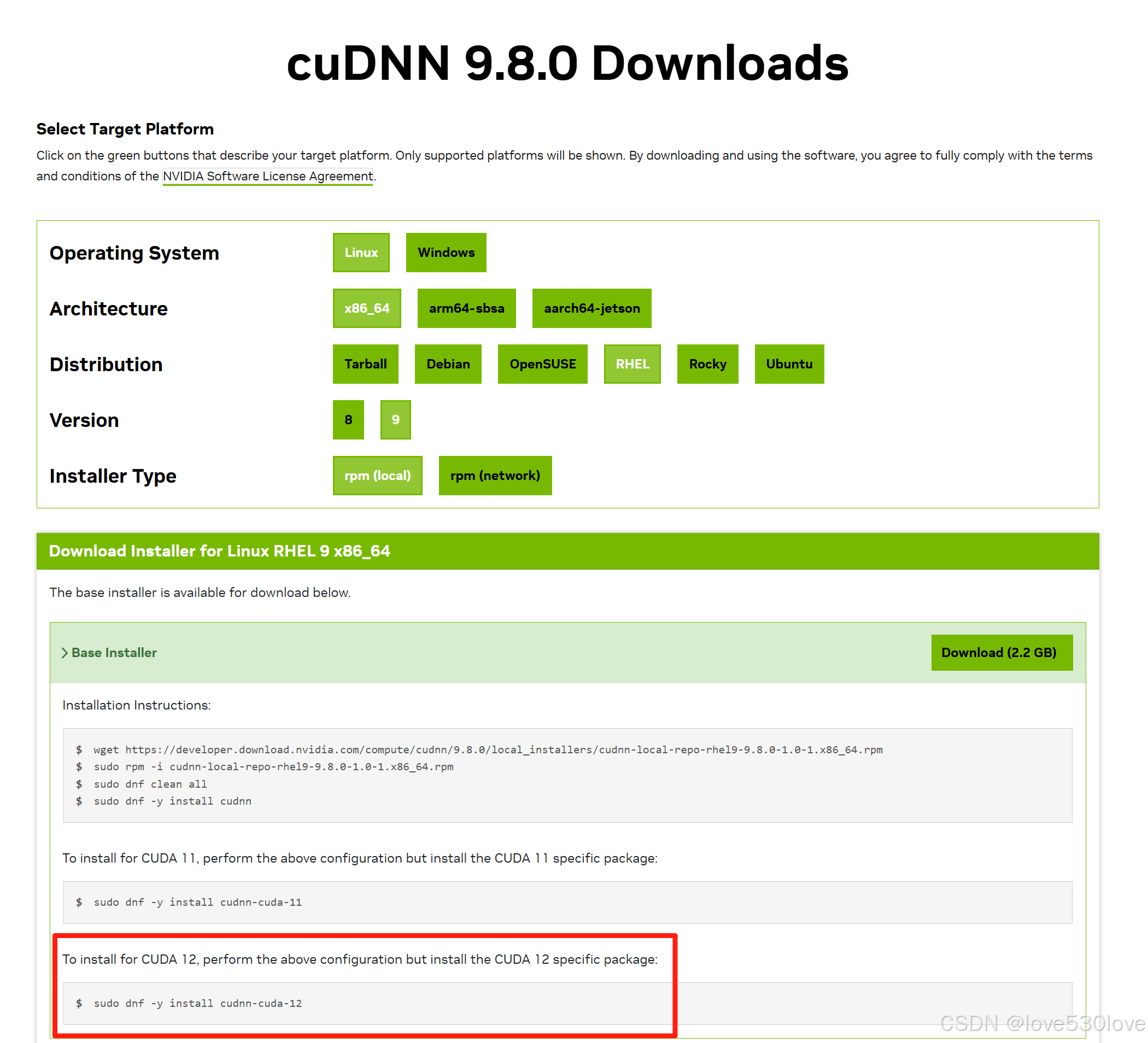
cuDNN官网的这条命令,一般不用理会。
sudo dnf -y install cudnn-cuda-12这条命令会安装适合 CUDA 12 版本的 cuDNN 包,一般安装过程中遵照顺序安装的话,cuDNN版本会自动匹配。
(九)验证cuDNN的系统环境变量
一般不用手动配置cuDNN的系统环境变量,因为cuDNN是安装到CUDA的目录中,在前边配置CUDA系统环境变量时,已经包含这些目录;
检查环境变量:
-
确保
CUDA_HOME和LD_LIBRARY_PATH环境变量正确设置,指向 CUDA 和 cuDNN 的安装目录。我们可以检查这些变量:
echo $CUDA_HOME
echo $LD_LIBRARY_PATH
确保输出中包含了/usr/local/cuda-12.8和/usr/local/cuda/lib64,这两个目录通常包含了cuDNN的可执行文件和库文件。
(十)暂时性地验证cuDNN的安装
通过简单的命令,暂时性的验证cuDNN的安装结果,后续会用专门的命令统一进行验证,因为python和有些库还没安装,所以统一验证的命令暂时还不能运用。
验证 cuDNN 安装的步骤:
-
确认 cuDNN 头文件位置:
ls /usr/include/cudnn*
-
确认 cuDNN 库文件位置:
ls /usr/lib64/libcudnn*
-
检查
cudnn.h文件位置:
ls /usr/include/cudnn.h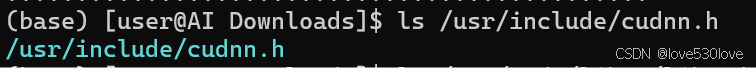
-
检查cuDNN 版本:
我们可以通过查看头文件来获取 cuDNN 版本信息
cat /usr/include/cudnn_version.h | grep CUDNN_MAJOR -A 2这条命令的作用是:
-
读取
/usr/include/cudnn_version.h文件。 -
查找包含
CUDNN_MAJOR的行。 -
显示该行以及其后的两行,从而获取 cuDNN 的主版本号、次版本号和补丁级别。
通过这条命令,我们可以快速查看系统中安装的 cuDNN 版本,这对于确认 cuDNN 是否正确安装以及了解其版本信息非常有用。

如果输出类似以下内容,则表示安装成功:
#define CUDNN_MAJOR 9
#define CUDNN_MINOR 8
#define CUDNN_PATCHLEVEL 0(base) [user@AI ~]$ cat /usr/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
#define CUDNN_MAJOR 9
#define CUDNN_MINOR 8
#define CUDNN_PATCHLEVEL 0
--
#define CUDNN_VERSION (CUDNN_MAJOR * 10000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL)/* cannot use constexpr here since this is a C-only file */
(base) [user@AI ~]$
根据输出显示了 cuDNN 库的版本信息,这些信息是从 cudnn_version.h 头文件中提取的。
下面是输出内容的详细解释:
-
版本定义:
-
#define CUDNN_MAJOR 9:这行定义了 cuDNN 的主版本号(Major version)为 9。 -
#define CUDNN_MINOR 8:这行定义了 cuDNN 的次版本号(Minor version)为 8。 -
#define CUDNN_PATCHLEVEL 0:这行定义了 cuDNN 的补丁级别(Patch level)为 0。
-
-
版本计算:
-
CUDNN_VERSION=(9×10000)+(8×100)+0=90000+800+0=90800#define CUDNN_VERSION (CUDNN_MAJOR * 10000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL):这行定义了一个宏,用于计算 cuDNN 的完整版本号。计算方法是将主版本号乘以 10000,次版本号乘以 100,然后加上补丁级别。根据这个公式,版本号计算如下: -
这个计算结果是一个数字,表示 cuDNN 的完整版本号,格式为
主版本号.次版本号.补丁级别,即 9.8.0。
-
-
注释:
-
/* cannot use constexpr here since this is a C-only file */:这行注释说明了为什么没有使用constexpr关键字。constexpr是 C++ 中的一个关键字,用于定义编译时常量。由于cudnn_version.h是一个 C 语言头文件,它不支持 C++ 的constexpr关键字,因此使用了宏定义来代替。
-
总的来说,这个输出表明我们系统中安装的 cuDNN 版本是 9.8.0。
这个版本信息对于确保 cuDNN 与我们的 CUDA 版本和其他深度学习框架兼容非常重要。
(十一)安装Anaconda或Miniconda
用来管理python版本和conda虚拟环境。
为了更好地管理 Python 版本和 Conda 虚拟环境,建议安装 Anaconda 或 Miniconda。
可以使用以下命令下载并安装最新版的 Anaconda:
wget -P /tmp https://repo.anaconda.com/archive/Anaconda3-2024.10-1-Linux-x86_64.sh # 下载anaconda安装包至 /tmp 目录下,可以替换为最新的Anaconda版本号
bash /tmp/Anaconda3-2024.10-1-Linux-x86_64.sh # 安装anaconda 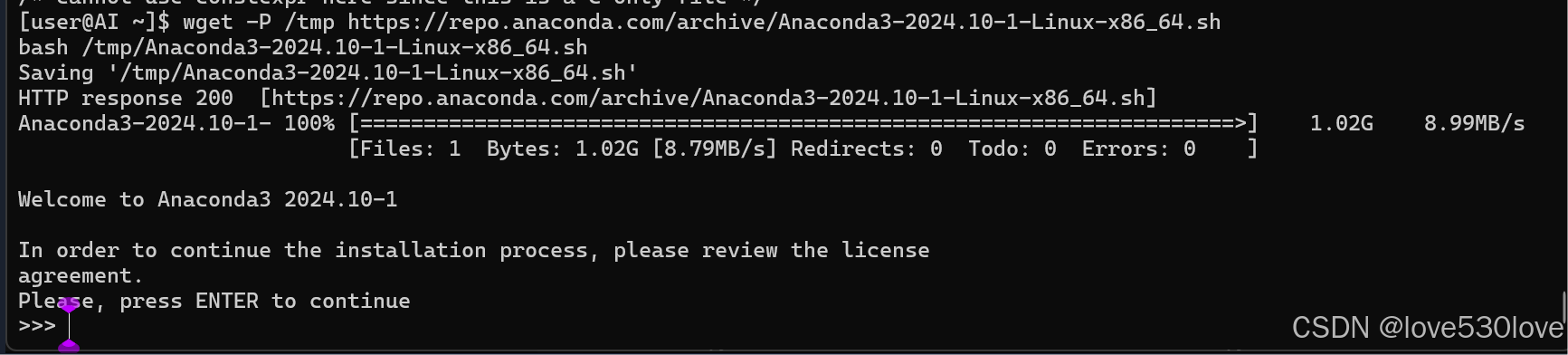
可以使用以下命令下载并安装最新版本的 Miniconda:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh #下载最新版本的 Miniconda 安装脚本
bash Miniconda3-latest-Linux-x86_64.sh #启动安装期间按“ENTER”键翻阅协议和输入两次“yes”或“ENTER”即可完成默认位置和默认配置的安装,安装完后自动集成到SHELL中。
如果没有集成到shell中,可以运行以下命令:
conda init然后关闭终端然后重新打开。
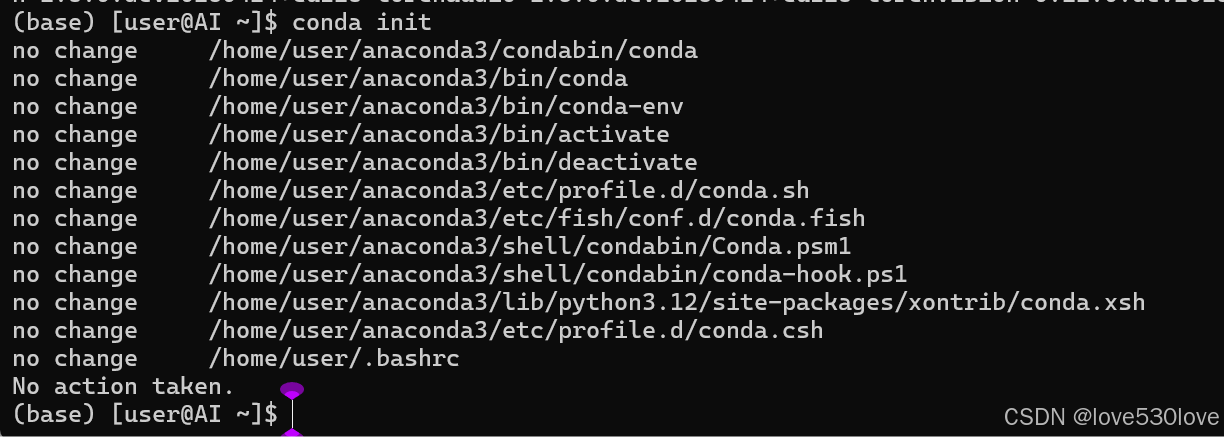
安装方法与WSL-Ubuntu 24.04 中的一致,具体详情可以参考:
在 Windows 11 下的 WSL - Ubuntu 24.04 中安装 Anaconda3_wsl2 ubuntu 24.04 anaconda-CSDN博客
(十二)安装PyTorch
通过安装PyTorch来检验podman-machine-default(WSL-Linux)对PyTorch GPU的支持。
11. 安装 PyTorch
PyTorch 是深度学习中常用的框架,支持 GPU 加速。
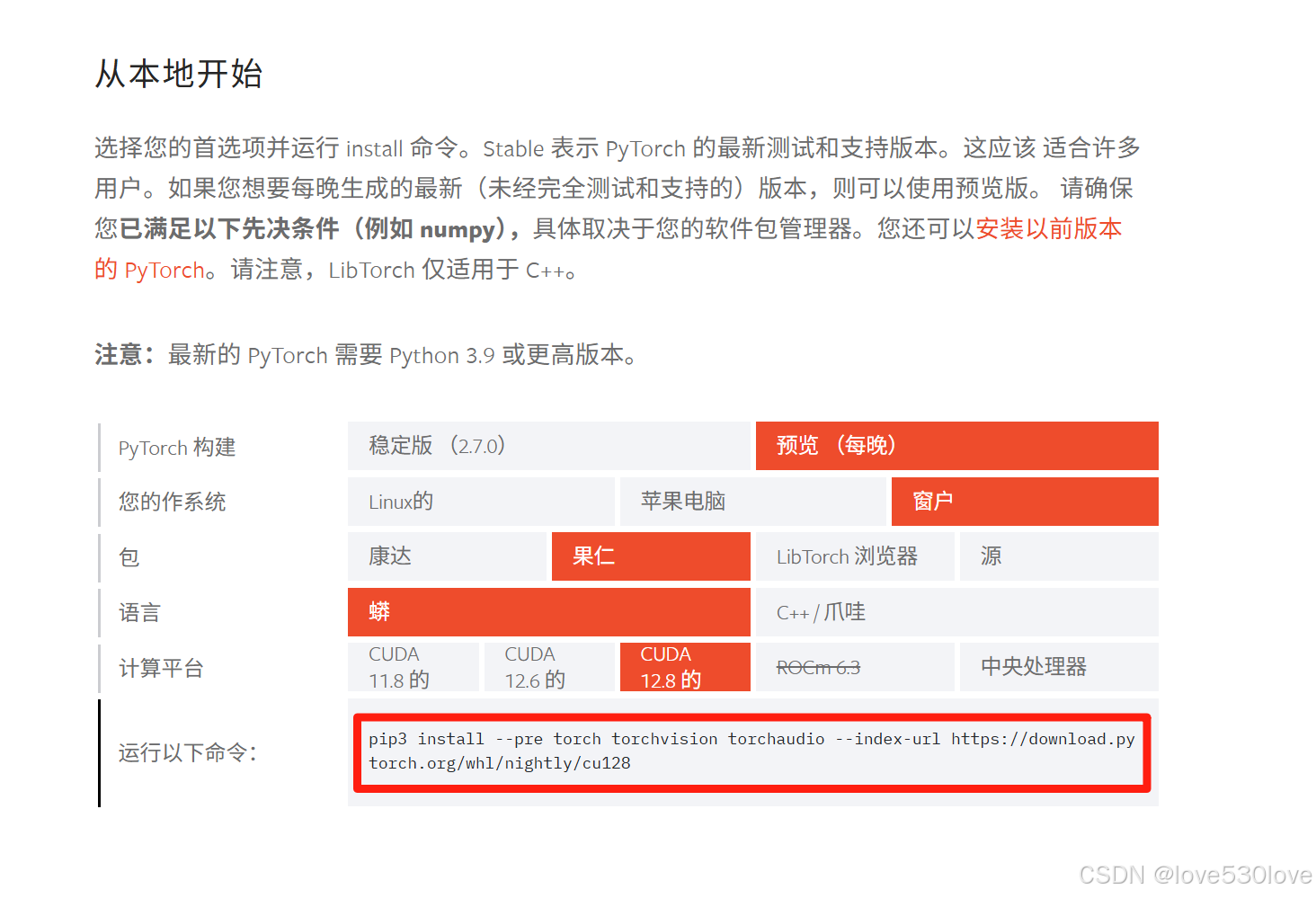
建议选择官网的最新命令安装最新版本 PyTorch来保证配置的正确性:
pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu128
该命令会安装适配当前 CUDA 版本的 PyTorch。
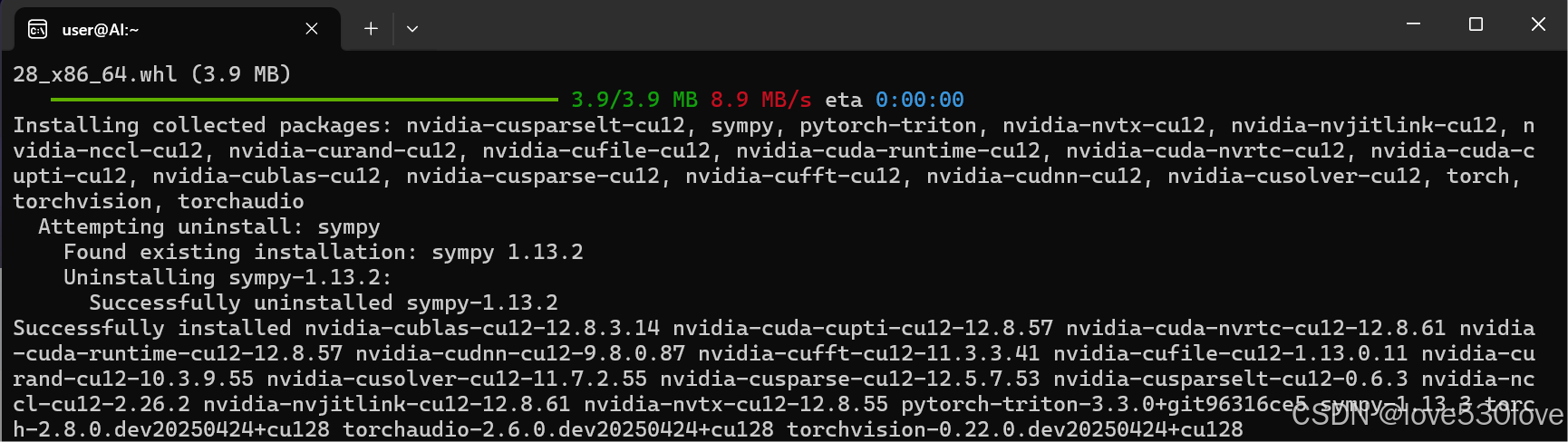
安装过程可参考:
在 Windows 11 下的 WSL - Ubuntu 24.04 中安装 Torch 的记录_wsl 安装 torch-CSDN博客
(十三)通过命令全面验证CUDA、cuDNN、Anaconda、PyTorch 等是否安装成功
全面验证podman-machine-default(WSL-Linux)的深度学习环境搭建情况
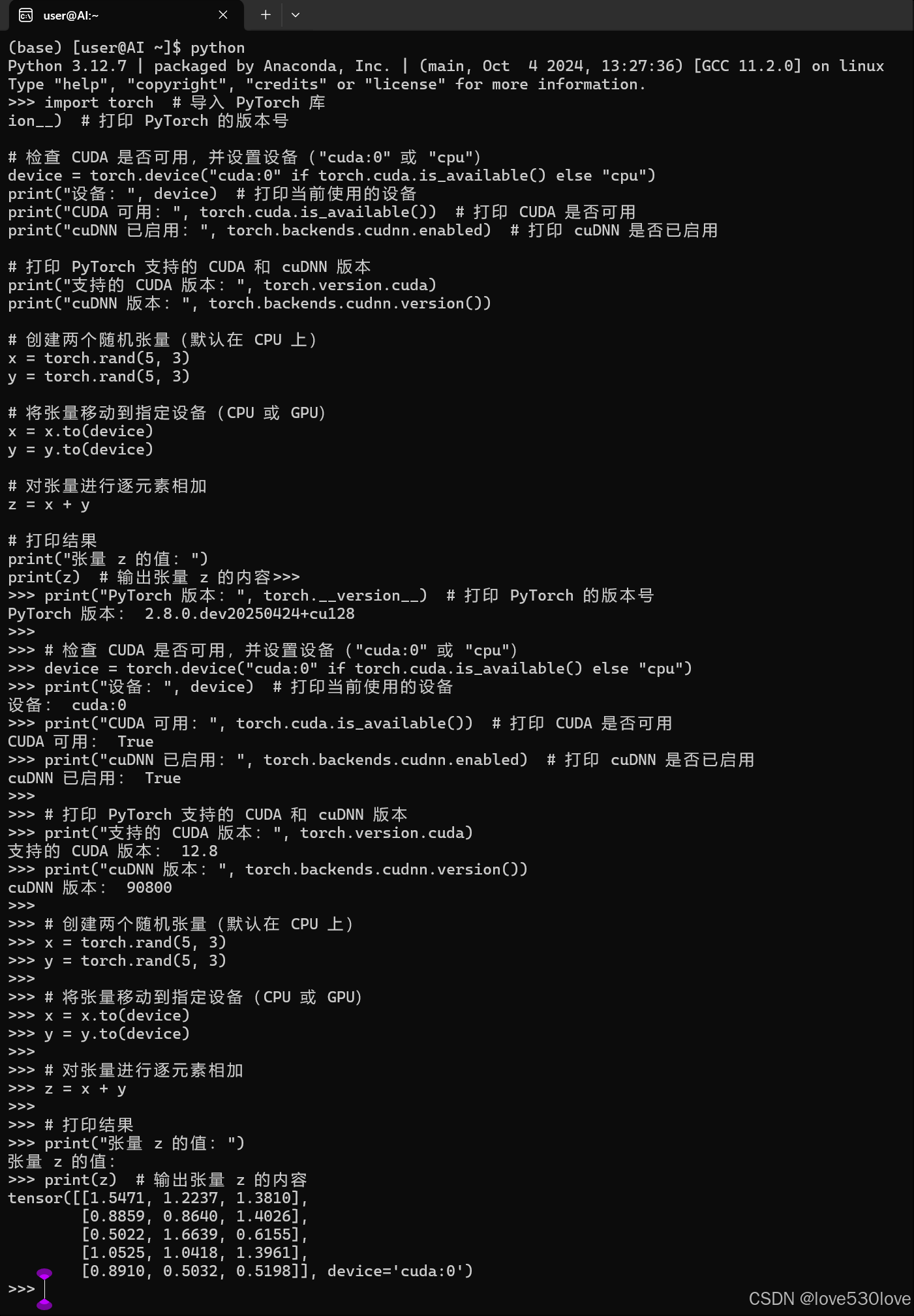
打开podman-machine-default终端,默认进入(base)虚拟环境,可以通过以下 Python 代码验证 CUDA 、cuDNN和 PyTorch 是否能正常工作:
import torch # 导入 PyTorch 库print("PyTorch 版本:", torch.__version__) # 打印 PyTorch 的版本号# 检查 CUDA 是否可用,并设置设备("cuda:0" 或 "cpu")
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("设备:", device) # 打印当前使用的设备
print("CUDA 可用:", torch.cuda.is_available()) # 打印 CUDA 是否可用
print("cuDNN 已启用:", torch.backends.cudnn.enabled) # 打印 cuDNN 是否已启用# 打印 PyTorch 支持的 CUDA 和 cuDNN 版本
print("支持的 CUDA 版本:", torch.version.cuda)
print("cuDNN 版本:", torch.backends.cudnn.version())# 创建两个随机张量(默认在 CPU 上)
x = torch.rand(5, 3)
y = torch.rand(5, 3)# 将张量移动到指定设备(CPU 或 GPU)
x = x.to(device)
y = y.to(device)# 对张量进行逐元素相加
z = x + y# 打印结果
print("张量 z 的值:")
print(z) # 输出张量 z 的内容如果输出为 True 且显示 GPU 名称,说明 CUDA 和 PyTorch 安装成功,并能正确使用 GPU。
详细命令解释请参考:
在WSL2-Ubuntu中安装CUDA12.8、cuDNN、Anaconda、Pytorch并验证安装_cuda 12.8 pytorch版本-CSDN博客
验证PyTorch深度学习环境Torch和CUDA还有cuDNN是否正确配置的命令_验证pytorch和cuda的命令-CSDN博客
(十四)安装Git
安装 Git 用于版本控制,执行以下命令:
sudo dnf install git
(十五)验证Git的安装
验证 Git 的安装
安装完成后,验证 Git 是否正确安装:
git --version
如果输出 Git 版本信息,说明安装成功。

(十六)配置Git
配置 Git
配置 Git 用户信息:
git config --global user.name "Your Name" # 设置全局 Git 用户名
git config --global user.email "your.email@example.com" # 设置全局 Git 用户电子邮件地址
git config --global http.postBuffer 524288000 # 设置 HTTP 缓冲区大小为 500MB(十七)其他安装和配置(自定义/可选)…
根据需要,继续安装其他必要的开发工具,如编辑器、调试工具等。
-
TensorFlow
-
OpenCV
-
Jupyter Notebook 等
总结
通过这些步骤,我们已成功在 podman-machine-default 中安装并配置了 CUDA、cuDNN、Anaconda、PyTorch 等深度学习所需的环境。现在,我们可以开始在 Windows 系统下的容器化环境中进行 GPU 加速的深度学习开发。