P19:Inception v1算法实战与解析
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
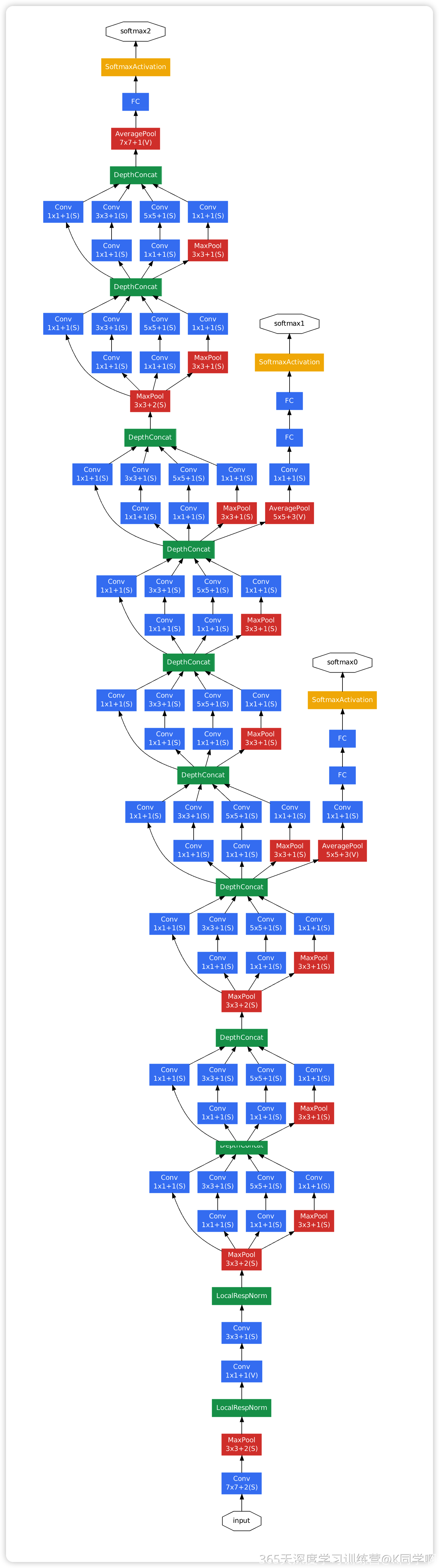
一、模型结构
Inception V1 的主要特点是在一个网络中同时使用不同大小的卷积核(1x1、3x3、5x5)和池化操作来提取多尺度特征。以下是 Inception V1 的主要结构:
-
卷积和池化层
- 模型开始部分使用常规的卷积层和池化层对输入图像进行特征提取和降维。
- 示例代码中,
conv1和maxpool1组合用于初步特征提取和下采样。
-
Inception 模块
- Inception 模块是 Inception V1 的核心,每个模块包含四个分支:
- 1x1 卷积分支:用于降低通道数,减少计算量,同时提取低级特征。
- 1x1 卷积 + 3x3 卷积分支:先降低通道数,再使用 3x3 卷积提取中等尺度特征。
- 1x1 卷积 + 5x5 卷积分支:用于提取更大尺度的特征,5x5 卷积前的 1x1 卷积用于降维以减少计算量。
- 3x3 最大池化 + 1x1 卷积分支:池化用于特征压缩,随后 1x1 卷积调整通道数。
- Inception 模块是 Inception V1 的核心,每个模块包含四个分支:
-
辅助分类器
- Inception V1 引入了两个辅助分类器(
InceptionAux),它们连接在后面的 Inception 模块中。 - 辅助分类器的作用是:
- 在训练过程中提供额外的梯度信号,帮助缓解梯度消失问题。
- 对中间层的特征进行分类,促使网络在不同层次学习到有用的特征。
- Inception V1 引入了两个辅助分类器(
-
全局平均池化和全连接层
- 网络最后使用全局平均池化(
AdaptiveAvgPool2d)将特征图转化为固定大小的特征向量。 - 随后通过全连接层(
fc)进行最终的分类。
- 网络最后使用全局平均池化(
训练过程
在训练过程中,模型会同时计算主分类器和辅助分类器的损失,并将它们加权求和作为总损失。这种设计有助于网络更快地收敛。
模型优势
- 多尺度特征提取:Inception 模块通过不同大小的卷积核同时捕捉多种尺度的特征,提高模型的特征表达能力。
- 计算效率:1x1 卷积用于降维,有效减少计算量和参数数量。
- 梯度流动改善:辅助分类器帮助缓解梯度消失问题,使深层网络更容易训练。
程序结构图
卷积层并行结构
Inception V1 的卷积层并行结构是其核心创新之一。这种结构在一个层中并行使用多个不同大小的卷积核(1×1、3×3、5×5)以及池化操作,目的是同时提取不同尺度的特征。具体来说:
- 多尺度特征提取:不同大小的卷积核可以捕捉到图像的不同尺度特征。小卷积核(如 1×1)适合捕捉精细的局部特征,而大卷积核(如 5×5)适合捕捉更广泛的上下文信息。
- 并行分支:每个分支独立进行卷积操作,然后将所有分支的输出在通道维度上进行拼接,形成最终的输出特征图。这种设计使得网络能够在同一层中处理多种尺度的信息。
这种并行结构的优点包括:
- 丰富的特征表达:通过多尺度特征提取,网络能够更好地理解和表示图像内容。
- 灵活的特征组合:不同分支的特征可以相互补充,提高模型的表达能力。
1×1 的卷积块
1×1 卷积块在 Inception V1 中起着至关重要的作用,主要有两个用途:
-
降维:
- 在 3×3 或 5×5 卷积之前使用 1×1 卷积可以减少输入的通道数,从而降低计算量。
- 例如,如果输入通道数为 192,通过 1×1 卷积将其降至 96,然后再进行 3×3 卷积,这样可以减少参数数量和计算量。
-
特征变换:
- 1×1 卷积可以看作是一种特征变换操作,它可以在不改变空间尺寸的情况下,对特征进行线性组合和非线性变换。
- 这种变换有助于提取更高级的特征表示。
具体来说,1×1 卷积的操作可以表示为:
y i , j , k = σ ( ∑ m = 0 C − 1 w k , m ⋅ x i , j , m + b k ) y_{i,j,k} = \sigma\left( \sum_{m=0}^{C-1} w_{k,m} \cdot x_{i,j,m} + b_k \right) yi,j,k=σ(m=0∑C−1wk,m⋅xi,j,m+bk)
其中:
- (x_{i,j,m}) 是输入特征图在位置 ((i,j)) 的第 (m) 个通道的值。
- (w_{k,m}) 是第 (k) 个 1×1 卷积核在第 (m) 个输入通道的权重。
- (b_k) 是偏置项。
- (\sigma) 是激活函数,如 ReLU。
1×1 卷积的优点包括:
- 减少参数量:通过降维,显著减少后续卷积层的参数数量。
- 增加非线性:结合激活函数,增加网络的非线性表达能力。
- 加速计算:降低计算复杂度,提高网络的运行效率。
这种卷积块在 Inception V1 的每个模块中都被广泛应用,是实现模型高效性和有效性的关键组件之一。
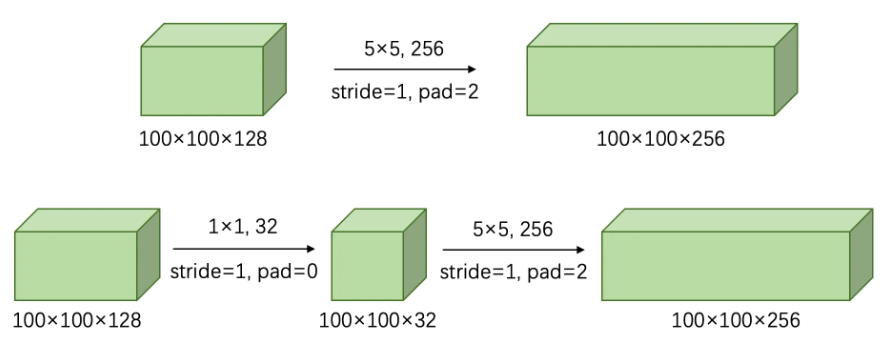
卷积块计算量对比
如下是相同的卷积结果但是不同的卷积方式,下面将计算一下计算量,观察为何能通过小卷积核升维减少计算量
好的,我将详细列出每一步的结果。
第一种:直接使用5×5卷积核的计算过程
输入特征图大小:100×100×128
卷积核大小:5×5×128
卷积核数量:256
填充大小:2
步幅:1
-
填充后的输入大小:
- 填充后输入特征图大小为 104×104×128
-
卷积操作:
- 将每个 5×5×128 的卷积核与输入特征图进行逐元素相乘并求和,得到一个100×100的特征图,对应一个输出通道。
-
输出特征图大小:
- 输出特征图大小为 (100 ×100 × 256)。
-
参数数量:
- 每个卷积核参数数量为 (5 × 5 × 128 = 3200)。
- 256个卷积核的总参数数量为 (256 ×3200 = 819200)。
第二种:先使用1×1卷积降维,再使用5×5卷积的计算过程
输入特征图大小:100×100×128
1×1卷积核大小:1×1×128
1×1卷积核数量:32
5×5卷积核大小:5×5×32
5×5卷积核数量:256
填充大小(1×1卷积):0
填充大小(5×5卷积):2
步幅:1
-
1×1卷积降维过程:
- 输入特征图大小:(100 × 100 ×128)
- 卷积核大小:(1 ×1 ×128)
- 卷积核数量:32
- 填充大小:0
- 步幅:1
- 输出特征图大小:(100×100×32)
- 参数数量:(1 ×1 ×128 ×32 = 4096)
-
5×5卷积升维过程:
- 输入特征图大小:(100×100 ×32)
- 卷积核大小:(5×5×32)
- 卷积核数量:256
- 填充大小:2
- 步幅:1
- 填充后输入特征图大小:(104×104×32)
- 输出特征图大小:(100×100×256)
- 参数数量:(5 ×5 ×32×256 = 204800)
-
总参数数量:
- 1×1卷积参数数量:4096
- 5×5卷积参数数量:204800
- 总参数数量:(4096 + 204800 = 208896)
两种方式的对比
-
第一种方式:
- 输出特征图大小:(100×100×256)
- 参数数量:819200
-
第二种方式:
- 输出特征图大小:(100 ×100 ×256)
- 参数数量:208896
通过对比可以看出,第二种方式在保持输出特征图大小不变的情况下,参数数量显著减少,计算量也更小,这是由于1×1卷积有效地降低了通道数。
二、 前期准备
1. 导入库
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib
import os,PIL,random,pathlib
import torch.nn.functional as F
from PIL import Image
import matplotlib.pyplot as plt
#隐藏警告
import warnings
2.导入数据
data_dir = './data/4-data/'
data_dir = pathlib.Path(data_dir)
#print(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[2] for path in data_paths]
#print(classeNames)
total_datadir = './data/4-data/'train_transforms = transforms.Compose([transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])total_data = datasets.ImageFolder(total_datadir,transform=train_transforms)
3.划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
batch_size = 32train_dl = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,batch_size=batch_size,shuffle=True,num_workers=1)
三、模型设计
1. 神经网络的搭建
class InceptionV1(nn.Module):def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):super(InceptionV1, self).__init__()# 1x1 conv branchself.branch1 = nn.Sequential(nn.Conv2d(in_channels, ch1x1, kernel_size=1),nn.BatchNorm2d(ch1x1),nn.ReLU(inplace=True))# 1x1 conv -> 3x3 conv branchself.branch2 = nn.Sequential(nn.Conv2d(in_channels, ch3x3red, kernel_size=1),nn.BatchNorm2d(ch3x3red),nn.ReLU(inplace=True),nn.Conv2d(ch3x3red, ch3x3, kernel_size=3, padding=1),nn.BatchNorm2d(ch3x3),nn.ReLU(inplace=True))# 1x1 conv -> 5x5 conv branchself.branch3 = nn.Sequential(nn.Conv2d(in_channels, ch5x5red, kernel_size=1),nn.BatchNorm2d(ch5x5red),nn.ReLU(inplace=True),nn.Conv2d(ch5x5red, ch5x5, kernel_size=5, padding=2),nn.BatchNorm2d(ch5x5),nn.ReLU(inplace=True))# 3x3 max pooling -> 1x1 conv branchself.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),nn.Conv2d(in_channels, pool_proj, kernel_size=1),nn.BatchNorm2d(pool_proj),nn.ReLU(inplace=True))def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(x)outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1)# 定义 Inception 辅助分类器
class InceptionAux(nn.Module):def __init__(self, in_channels, num_classes):super(InceptionAux, self).__init__()self.conv = nn.Sequential(nn.Conv2d(in_channels, 128, kernel_size=1),nn.BatchNorm2d(128),nn.ReLU(inplace=True))self.fc = nn.Sequential(nn.Linear(2048, 1024),nn.ReLU(inplace=True),nn.Dropout(0.7),nn.Linear(1024, num_classes))def forward(self, x):x = F.adaptive_avg_pool2d(x, (4, 4))x = self.conv(x)x = torch.flatten(x, 1)x = self.fc(x)return x# 定义完整的 Inception V1 模型
class InceptionV1Model(nn.Module):def __init__(self, num_classes=4):super(InceptionV1Model, self).__init__()self.conv1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),nn.BatchNorm2d(64),nn.ReLU(inplace=True))self.maxpool1 = nn.MaxPool2d(3, stride=2, padding=1)self.conv2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),nn.BatchNorm2d(64),nn.ReLU(inplace=True),nn.Conv2d(64, 192, kernel_size=3, padding=1),nn.BatchNorm2d(192),nn.ReLU(inplace=True))self.maxpool2 = nn.MaxPool2d(3, stride=2, padding=1)# Inception blocksself.inception3a = InceptionV1(192, 64, 96, 128, 16, 32, 32)self.inception3b = InceptionV1(256, 128, 128, 192, 32, 96, 64)self.maxpool3 = nn.MaxPool2d(3, stride=2, padding=1)self.inception4a = InceptionV1(480, 192, 96, 208, 16, 48, 64)self.inception4b = InceptionV1(512, 160, 112, 224, 24, 64, 64)self.inception4c = InceptionV1(512, 128, 128, 256, 24, 64, 64)self.inception4d = InceptionV1(512, 112, 144, 288, 32, 64, 64)self.inception4e = InceptionV1(528, 256, 160, 320, 32, 128, 128)self.maxpool4 = nn.MaxPool2d(3, stride=2, padding=1)self.inception5a = InceptionV1(832, 256, 160, 320, 32, 128, 128)self.inception5b = InceptionV1(832, 384, 192, 384, 48, 128, 128)# Auxiliary classifiersself.aux1 = InceptionAux(512, num_classes)self.aux2 = InceptionAux(528, num_classes)self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.dropout = nn.Dropout(0.4)self.fc = nn.Linear(1024, num_classes)def forward(self, x):x = self.conv1(x)x = self.maxpool1(x)x = self.conv2(x)x = self.maxpool2(x)x = self.inception3a(x)x = self.inception3b(x)x = self.maxpool3(x)x = self.inception4a(x)aux1 = self.aux1(x) if self.training else Nonex = self.inception4b(x)x = self.inception4c(x)x = self.inception4d(x)aux2 = self.aux2(x) if self.training else Nonex = self.inception4e(x)x = self.maxpool4(x)x = self.inception5a(x)x = self.inception5b(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.dropout(x)x = self.fc(x)if self.training:return x, aux1, aux2else:return x2.设置损失值等超参数
device = "cuda" if torch.cuda.is_available() else "cpu"# 模型初始化
input_shape = (224, 224, 3)
num_classes = len(classeNames)
model = ResNeXt50(input_shape=input_shape, num_classes=num_classes).to(device)
print(summary(model, (3, 224, 224)))loss_fn = nn.CrossEntropyLoss() # 创建损失函数
learn_rate = 1e-4 # 学习率
opt = torch.optim.SGD(model.parameters(),lr=learn_rate)
epochs = 10
train_loss = []
train_acc = []
test_loss = []
test_acc = []
----------------------------------------------------------------Layer (type) Output Shape Param #
================================================================Conv2d-1 [-1, 64, 112, 112] 9,472BatchNorm2d-2 [-1, 64, 112, 112] 128ReLU-3 [-1, 64, 112, 112] 0MaxPool2d-4 [-1, 64, 56, 56] 0.... .....BatchNorm2d-207 [-1, 128, 7, 7] 256ReLU-208 [-1, 128, 7, 7] 0InceptionV1-209 [-1, 1024, 7, 7] 0
AdaptiveAvgPool2d-210 [-1, 1024, 1, 1] 0Dropout-211 [-1, 1024] 0Linear-212 [-1, 2] 2,050
================================================================
Total params: 10,324,502
Trainable params: 10,324,502
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 94.24
Params size (MB): 39.38
Estimated Total Size (MB): 134.20
----------------------------------------------------------------
3. 设置训练函数
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset)num_batches = len(dataloader)train_loss, train_acc = 0, 0model.train()for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)if isinstance(pred, tuple):loss = loss_fn(pred[0], y) + 0.3 * loss_fn(pred[1], y) + 0.3 * loss_fn(pred[2], y)else:loss = loss_fn(pred, y)optimizer.zero_grad()loss.backward()optimizer.step()train_acc += (pred[0].argmax(1) == y).type(torch.float).sum().item() if isinstance(pred, tuple) else (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss4. 设置测试函数
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)test_loss, test_acc = 0, 0model.eval()with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)if isinstance(pred, tuple):test_loss += (loss_fn(pred[0], y) + 0.3 * loss_fn(pred[1], y) + 0.3 * loss_fn(pred[2], y)).item()test_acc += (pred[0].argmax(1) == y).type(torch.float).sum().item()else:test_loss += loss_fn(pred, y).item()test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss5. 创建导入本地图片预处理模块
def predict_one_image(image_path, model, transform, classes):test_img = Image.open(image_path).convert('RGB')test_img = transform(test_img)img = test_img.to(device).unsqueeze(0)model.eval()output = model(img)_, pred = torch.max(output, 1)pred_class = classes[pred]print(f'预测结果是:{pred_class}')6. 主函数
if __name__ == '__main__':device = "cuda" if torch.cuda.is_available() else "cpu"# 模型初始化num_classes = len(classeNames)model = InceptionV1Model(num_classes=num_classes).to(device)print(summary(model, (3, 224, 224)))loss_fn = nn.CrossEntropyLoss()learn_rate = 1e-4opt = optim.SGD(model.parameters(), lr=learn_rate)epochs = 10train_loss = []train_acc = []test_loss = []test_acc = []for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}')print(template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss))print('Done')# 绘制训练和测试曲线warnings.filterwarnings("ignore")plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = Falseplt.rcParams['figure.dpi'] = 100epochs_range = range(epochs)plt.figure(figsize=(12, 3))plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')plt.plot(epochs_range, test_acc, label='Test Accuracy')plt.legend(loc='lower right')plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)plt.plot(epochs_range, train_loss, label='Training Loss')plt.plot(epochs_range, test_loss, label='Test Loss')plt.legend(loc='upper right')plt.title('Training and Validation Loss')plt.show()classes = list(total_data.class_to_idx.keys())predict_one_image(image_path='./data/4-data/Monkeypox/M01_01_00.jpg',model=model,transform=train_transforms,classes=classes)# 保存模型PATH = './model_inception.pth'torch.save(model.state_dict(), PATH)# 加载模型model.load_state_dict(torch.load(PATH, map_location=device))
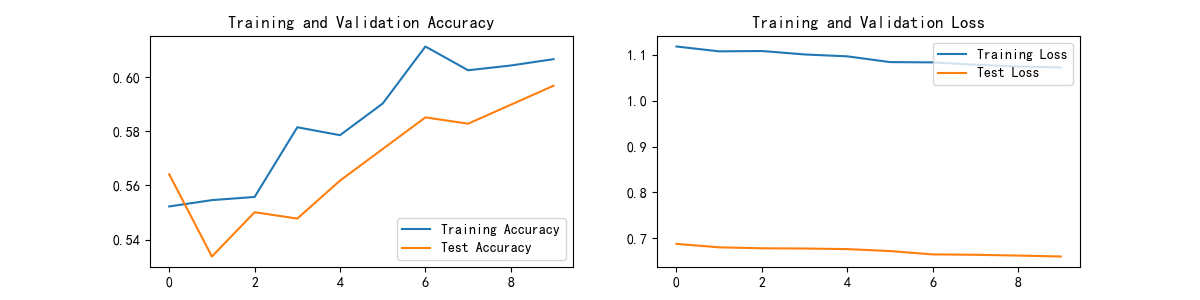
结果
Epoch: 1, Train_acc:55.2%, Train_loss:1.118, Test_acc:56.4%, Test_loss:0.688
Epoch: 2, Train_acc:55.5%, Train_loss:1.107, Test_acc:53.4%, Test_loss:0.680
Epoch: 3, Train_acc:55.6%, Train_loss:1.108, Test_acc:55.0%, Test_loss:0.678
Epoch: 4, Train_acc:58.1%, Train_loss:1.101, Test_acc:54.8%, Test_loss:0.678
Epoch: 5, Train_acc:57.9%, Train_loss:1.097, Test_acc:56.2%, Test_loss:0.676
Epoch: 6, Train_acc:59.0%, Train_loss:1.084, Test_acc:57.3%, Test_loss:0.672
Epoch: 7, Train_acc:61.1%, Train_loss:1.083, Test_acc:58.5%, Test_loss:0.665
Epoch: 8, Train_acc:60.2%, Train_loss:1.078, Test_acc:58.3%, Test_loss:0.664
Epoch: 9, Train_acc:60.4%, Train_loss:1.074, Test_acc:59.0%, Test_loss:0.662
Epoch:10, Train_acc:60.7%, Train_loss:1.072, Test_acc:59.7%, Test_loss:0.660
Done