大数据分析04 数据查询分析
构建数据源
- 引入pandas包
数据map中ID为列,值为行,每一列中值个数要一致
import pandas as pd
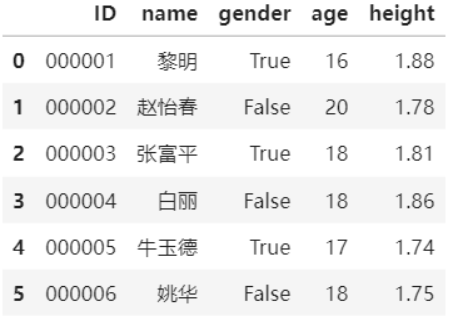
data = {'ID': ['000001', '000002', '000003', '000004', '000005', '000006', '000007'],'name':['黎明', '赵怡春', '张富平', '白丽', '牛玉德', '姚华', '李南'], 'gender':[True, False, True, False, True, False, True], 'age':[16, 20, 18, 18, 17, 18, 16], 'height':[1.88, 1.78, 1.81, 1.86, 1.74, 1.75, 1.76]}frame = pd.DataFrame(data)
frame
print打印的不是二维表格 直接用frame显示更好看
- 读取文本文件数据
datau.txt内容格式
1|24|M|technician|85711
2|53|F|other|94043
3|23|M|writer|32067
4|24|M|technician|43537
5|33|F|other|15213
6|42|M|executive|98101
按分隔符读取内容
import pandas as pdunames = ['uid', 'age', 'gender', 'occupation', 'zip']
users = pd.read_table('datau.txt', sep='|', header=None, names=unames)users.head(5)
-读取CSV
frame1 = pd.read_csv("data.csv", encoding='GBK') # 将数据加载成DataFrame格式
frame1.head(5)
数据的选择
筛选行
- 选择一列并使用index更改行号
frame = pd.DataFrame(data, index=[6, 5, 4, 3, 2, 1, 0])
frame['name'] //frame.name
- 多列选择
frame[['name', 'age', 'gender']]
- 指定数据行
包含下届不包含上届
frame[2:4]
- 按索引
要求准确的编号,包含下上下界
frame.loc[1]
- 展示所有数据,筛选多列
fream.loc[:,["age","name"]]
- 根据序号获取
frame.iloc[1,3]
与loc的区别是:loc取的是绝对数值,值不存在的不展示,iloc从0开始的索引号
- 条件范围
frame[frame['age'] > 17]
与frame[frame[‘age’] ]>17做区别,前者返回年龄大于17的数据行,后者返回所有的数据行值是否大于17,是个bool值
- 多条件
frame[(frame['age'] > 17) & (frame['height'] == 1.80)]
- 范围
取一个离散范围,年龄在16-20之间
frame[frame['age'].isin([16, 20])]
- 列名修改
frame.rename(columns=["ID":"学号"])
- 截取字符
frame["name"].str[0:1]
- 格式化小数
frame.["height"].round(2)
- 自定义函数
apply 用来执行函数,可以通过args传递参数
def xinbie(val):if val is True:return "男"else:return "女"
frame['gender'].apply(xinbie)
输出格式
- 直接打印
print(frame)
- 输出表格
frame
- 输出HTML
print(frame.to_html())
设置数据展示
- 设置展示最大行数None为所有
pd.set_option('display.max_rows',None)