【Hive入门】Hive数据导出完全指南:从HDFS到本地文件系统的专业实践
目录
引言
1 Hive数据导出概述
1.1 数据导出的核心概念
1.2 典型导出场景
2 Hive到HDFS导出详解
2.1 INSERT OVERWRITE DIRECTORY方法
2.2 多目录导出技术
2.3 动态分区导出
3 HDFS到本地文件系统转移
3.1 hadoop fs命令操作
3.2 分布式拷贝工具DistCp
4 直接导出到本地文件系统
4.1 本地目录导出
4.2 单文件导出技巧
5 高级导出技术与优化
5.1 自定义输出格式
5.2 并行导出优化
5.3 增量导出策略
6 案例解析
6.1 数据日报导出
6.2 跨集群数据迁移
7 常见问题与解决方案
7.1 导出性能瓶颈排查
7.2 中文乱码问题
7.3 权限问题处理
8 总结
8.1 选型建议
8.2 性能优化清单
引言
在大数据生态系统中,Hive作为数据仓库解决方案,不仅需要高效地导入数据,还需要将处理结果导出到各种目标系统。本文将全面介绍Hive数据导出的多种方法,特别聚焦于从HDFS到本地文件系统的专业实践,帮助数据工程师构建完整的数据工作流。
1 Hive数据导出概述
1.1 数据导出的核心概念
数据导出是指将Hive表中的数据提取出来,以特定格式和结构传输到外部系统的过程。与数据导入相比,导出操作需要考虑:
- 数据一致性:确保导出过程中数据不被修改
- 格式兼容性:选择适合目标系统的文件格式
- 性能考量:大数量导出时的效率问题
- 权限管理:跨系统访问的权限控制
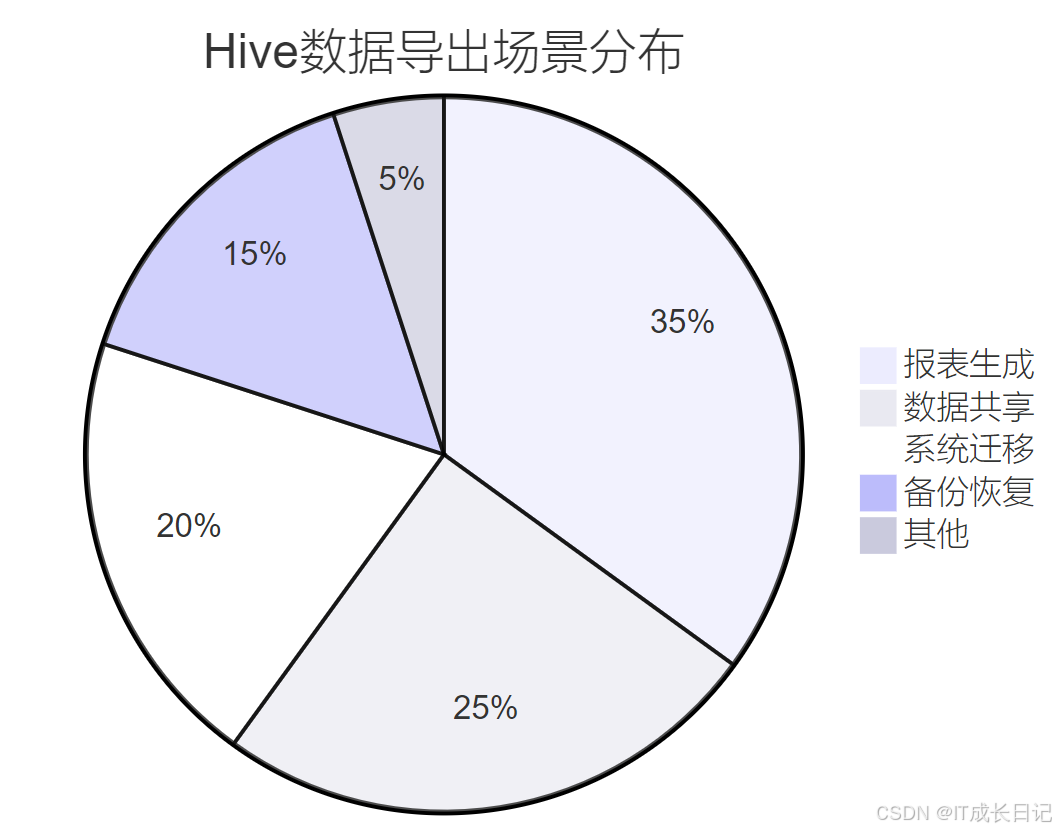
1.2 典型导出场景
2 Hive到HDFS导出详解
2.1 INSERT OVERWRITE DIRECTORY方法
- 最常用的Hive数据导出方式,语法灵活且支持多种文件格式:
INSERT OVERWRITE DIRECTORY '/output/path'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
SELECT * FROM source_table;参数说明:
- ROW FORMAT DELIMITED:指定行格式
- FIELDS TERMINATED BY:字段分隔符
- STORED AS:输出文件格式(TEXTFILE/SEQUENCEFILE等)
2.2 多目录导出技术
- Hive支持通过单个查询将数据导出到多个目录:
FROM source_table
INSERT OVERWRITE DIRECTORY '/output/path1'
SELECT col1, col2 WHERE condition1
INSERT OVERWRITE DIRECTORY '/output/path2'
SELECT col3, col4 WHERE condition2;2.3 动态分区导出
- 结合动态分区特性实现智能导出
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;INSERT OVERWRITE DIRECTORY '/output/base_path'
PARTITION(dt, country)
SELECT col1, col2, dt, country
FROM source_table;3 HDFS到本地文件系统转移
3.1 hadoop fs命令操作
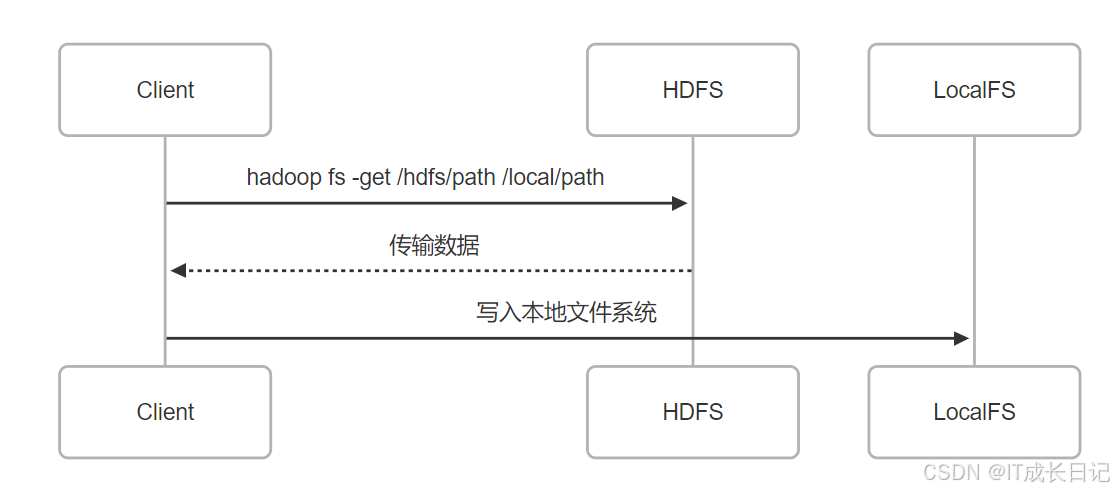
- 常用命令示例:
# 基本导出
hadoop fs -get /user/hive/output/data.csv /home/user/# 递归导出目录
hadoop fs -getmerge -nl /user/hive/output/ /home/user/merged_data.csv# 带权限控制导出
hadoop fs -Ddfs.permissions.superusergroup=admin -get /secure/path /local/3.2 分布式拷贝工具DistCp
- 对于大规模数据迁移,DistCp是更高效的选择:
hadoop distcp \
-Dmapreduce.job.queuename=high_priority \
-update \
-strategy dynamic \
-bandwidth 50 \
hdfs://namenode:8020/source \
file:///local/target/关键参数:
- -update:仅拷贝更新的文件
- -bandwidth:限制带宽使用(MB/s)
- -strategy:选择拷贝策略
4 直接导出到本地文件系统
4.1 本地目录导出
INSERT OVERWRITE LOCAL DIRECTORY '/tmp/hive_export'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
SELECT * FROM sales_data;注意事项:
- 需要HiveServer2机器上的本地写权限
- 输出为多个文件(对应MapReduce任务数)
- 默认文件名为000000_0等
4.2 单文件导出技巧

- 示例代码
SET mapreduce.job.reduces=1;INSERT OVERWRITE LOCAL DIRECTORY '/tmp/single_file'
SELECT * FROM large_table;mv /tmp/single_file/000000_0 /tmp/single_file/full_data.csv;5 高级导出技术与优化
5.1 自定义输出格式
- 通过实现Hive的FileFormat接口支持自定义输出:
public class CustomJsonOutputFormat extends FileOutputFormat<NullWritable, Text> {// 实现记录写入逻辑
}- 注册后使用
SET hive.output.fileformat=com.example.CustomJsonOutputFormat;
INSERT OVERWRITE DIRECTORY '/json/output'
SELECT * FROM table;5.2 并行导出优化

- 实现方法
-- 设置并行度
SET hive.exec.parallel=true;
SET hive.exec.parallel.thread.number=8;-- 分区并行导出
EXPORT TABLE partitioned_table
PARTITION(dt='2023-01')
TO '/output/parallel';5.3 增量导出策略
- 基于时间戳的增量导出方案:
-- 创建增量记录表
CREATE TABLE export_metadata (table_name STRING,last_export TIMESTAMP
);-- 增量导出查询
INSERT OVERWRITE DIRECTORY '/incremental'
SELECT * FROM source_table
WHERE update_time > (SELECT last_export FROM export_metadata WHERE table_name = 'source_table');6 案例解析
6.1 数据日报导出
- 需求:每日将订单数据导出为CSV供财务系统使用
- 解决方案
#!/bin/bash
# 设置日期变量
EXPORT_DATE=$(date -d "yesterday" +%Y-%m-%d)# Hive导出到HDFS
hive -e "
SET hive.cli.print.header=true;
INSERT OVERWRITE DIRECTORY '/data/export/orders_${EXPORT_DATE}'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
SELECT * FROM dw_orders
WHERE dt='${EXPORT_DATE}';"# 传输到本地系统
hadoop fs -getmerge /data/export/orders_${EXPORT_DATE} \
/home/finance/orders_${EXPORT_DATE}.csv# 添加标题行
sed -i '1i order_id,user_id,amount,create_time' \
/home/finance/orders_${EXPORT_DATE}.csv6.2 跨集群数据迁移
- 场景:将生产集群Hive数据导出到测试集群
- 实现方案:

- 具体命令:
# 生产集群导出
hive -e "EXPORT TABLE prod_db.sales TO '/migration/sales'"# 跨集群拷贝
hadoop distcp \
hdfs://prod-nn:8020/migration/sales \
hdfs://test-nn:8020/migration/sales# 测试集群导入
hive -e "IMPORT TABLE test_db.sales FROM '/migration/sales'"7 常见问题与解决方案
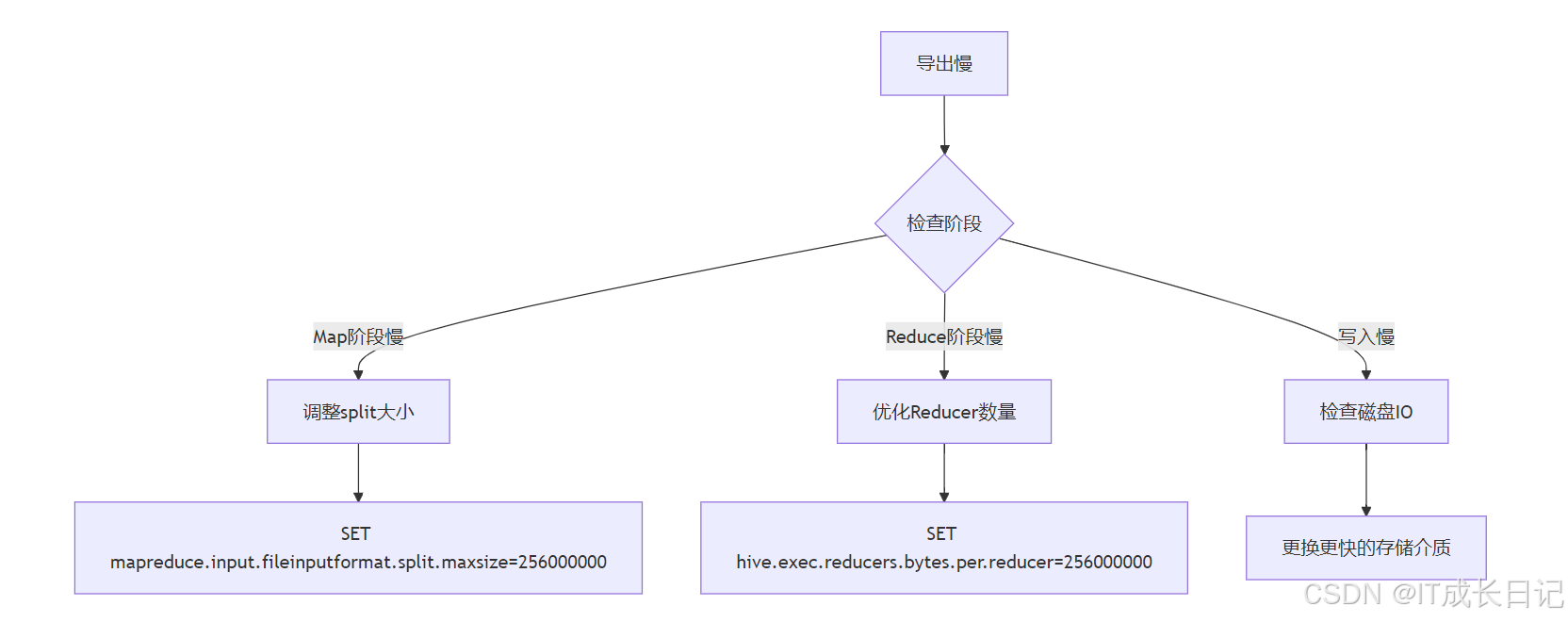
7.1 导出性能瓶颈排查
7.2 中文乱码问题
-- 在导出时指定编码
SET hive.exec.default.charset=utf-8;
SET mapreduce.output.fileoutputformat.output.encoding=utf-8;INSERT OVERWRITE DIRECTORY '/output'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '|'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE
SELECT * FROM chinese_table;7.3 权限问题处理
- 典型错误场景:
Permission denied: user=impala, access=WRITE, inode="/export"- 解决方法:
# 临时方案
hadoop fs -chmod -R 777 /export# 生产环境推荐
hadoop fs -mkdir /export
hadoop fs -chown impala:supergroup /export
hadoop fs -chmod 750 /export8 总结
8.1 选型建议
| 导出需求 | 推荐方案 |
| 小量数据到本地 | INSERT OVERWRITE LOCAL |
| 大量数据到HDFS | INSERT OVERWRITE DIRECTORY |
| 跨集群迁移 | EXPORT + DistCp |
| 增量导出 | 时间戳过滤+元数据记录 |
| 结构化格式需求 | 自定义FileFormat |
8.2 性能优化清单
- 资源分配:适当增加导出任务内存
SET mapreduce.map.memory.mb=4096;
SET mapreduce.reduce.memory.mb=8192;- 压缩输出:减少传输数据量
SET hive.exec.compress.output=true;
SET mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.GzipCodec;- 文件合并:避免小文件问题
SET hive.merge.mapfiles=true;
SET hive.merge.size.per.task=256000000;- 错误处理:自动重试机制
SET mapreduce.map.maxattempts=4;
SET mapreduce.reduce.maxattempts=4;掌握Hive数据导出技术是大数据工程师的核心能力之一。本文介绍的各种方法和最佳实践,希望能帮助您了解构建高效可靠的数据导出流程。在实际应用中,建议根据具体场景灵活组合这些技术,并持续监控和优化导出性能。