机器学习的基本概念
机器学习是人工智能的一个重要研究领域。与计算机科学、心理学等多种学科都有密切的关系,牵涉的面比较宽,而且许多理论及技术上的问题尚处于研究之中,接下来对它的一些基本概念和方法作一简要讨论,以便对它有一个初步的认识。
一、什么是机器学习
(一)学习:从数据到知识的映射
1. 基本思想与定义
基本思想:学习是智能系统通过与环境交互,从经验数据中获取规律、改进性能的过程。其核心是通过算法自动发现数据中的模式,并将其转化为可用于预测或决策的知识。
目前,对“学习”这一概念的研究有较大影响的观点主要有以下几种:
(1)学习是系统改进其性能的过程。这是西蒙关于“学习”的观点。1980年他在卡内基-梅隆大学召开的机器学习研讨会上做了“为什么机器应该学习”的发言,在此发言中他把学习定义为:学习是系统中的任何改进,这种改进使得系统在重复同样的工作或进行类似的工作时,能完成得更好。这一观点在机器学习研究领域中有较大的影响,学习的基本模型就是基于这一观点建立起来的。
(2)学习是获取知识的过程。这是从事专家系统研究的人们提出的观点。由于知识获取一直是专家系统建造中的困难问题,因此他们把机器学习与知识获取联系起来,希望通过对机器学习的研究,实现知识的自动获取。
(3)学习是技能的获取。这是心理学家关于如何通过学习获得熟练技能的观点。人们通过大量实践和反复训练可以改进机制和技能,如像骑自行车、弹钢琴等都是这样。但是,学习并不仅仅只是获得技能,它只是反映了学习的一个方面。
(4)学习是事物规律的发现过程。在20世纪80年代,由于对智能机器人的研究取得了一定的进展,同时又出现了一些发现系统,于是人们开始把学习看作是从感性知识到理性知识的认识过程,从表层知识到深层知识的特化过程,即发现事物规律、形成理论的过程。
上述各种观点分别是从不同角度理解“学习”这一概念的,若把它们综合起来可以认为:学习是一个有特定目的的知识获取过程,其内在行为是获取知识、积累经验、发现规律;外部表现是改进性能、适应环境、实现系统的自我完善。
定义(基于王永庆理论拓展):设学习系统的输入为数据集![]() ,其中 x_i ∈X为输入空间的样本,y_i ∈Y为输出空间的标签。学习过程可形式化为寻找一个映射 f: X → Y,使得在新样本 x_new 上的预测误差 L(f(x_new), y_new) 最小化,其中 L 为损失函数。
,其中 x_i ∈X为输入空间的样本,y_i ∈Y为输出空间的标签。学习过程可形式化为寻找一个映射 f: X → Y,使得在新样本 x_new 上的预测误差 L(f(x_new), y_new) 最小化,其中 L 为损失函数。
2. 表示形式与实现过程
表示形式:
(1)参数化表示:如线性模型![]() ,通过参数 w, b 描述输入输出关系;
,通过参数 w, b 描述输入输出关系;
(2)非参数化表示:如决策树、支持向量机(SVM),通过结构或核函数隐式定义映射;
(3)概率表示:如贝叶斯模型,通过后验概率 P(y|x) 建模不确定性。
实现过程(以监督学习为例):
(1)数据预处理:清洗数据、特征工程(如归一化 ![]() );
);
(2)模型假设:选择模型类![]() ,如神经网络
,如神经网络![]() ;
;
(3)损失定义:定义经验风险![]() ;
;
(4)优化求解:通过梯度下降![]() 寻找最优参数;
寻找最优参数;
(5)泛化评估:使用测试集计算泛化误差![]() 。
。
3. 算法描述:以线性回归为例
(1)目标函数:最小化均方误差![]()
(2)梯度计算:![]()
(3)更新规则:![]()
4. 具体示例:房价预测流程
数据:输入特征 x = [面积, 房间数],输出 y = 价格;
模型:线性函数 ![]() ;
;
训练:
(1)初始化 w = [0, 0], b = 0;
(2)计算预测值![]() ;
;
(3)计算梯度![]() ,更新 w, b;
,更新 w, b;
(4)重复直至收敛;
预测:输入新样本 x_new,输出 f(x_new)。
(二)机器学习:自动化知识获取的工程范式
所谓机器学习,就是要使计算机能模似人的学习行为,自动地通过学习获取知识和技能,不断改善性能,实现自我完善。作为人工智能的一个研究领域,机器学习的研究工作主要是围绕着以下三个基本方面进行的:
(1)学习机理的研究。这是对人类学习机制的研究,即人类获取知识、技能和抽象概念的天赋能力。通过这一研究,将从根本上解决机器学习中存在的种种问题。
(2)学习方法的研究。研究人类的学习过程,探索各种可能的学习方法,建立起独立于具体应用领域的学习算法。
(3)面向任务的研究。根据特定任务的要求,建立相应的学习系统。
定义:机器学习是研究如何让计算机系统从数据中自动学习规律,以完成预测、分类、控制等任务的学科。其本质是通过算法将数据转化为可复用的模型,实现“数据→模型→决策”的闭环。 核心特征:
(1)数据驱动:依赖大规模数据集而非手工规则;
(2)迭代优化:通过训练数据调整模型参数或结构;
(3)泛化能力:模型需在未知数据上表现良好(如通过正则化![]() 防止过拟合)。
防止过拟合)。
二、学习系统的构成要素(王永庆系统理论拓展)
为了使计算机系统具有某种程度的学习能力,使它能通过学习增长知识、改善性能、提高智能水平,需要为它建立相应的学习系统。
所谓学习系统,是指能够在一定程度上实现机器学习的系统。1973年萨利斯(Saris)曾对学习系统给出如下定义:如果一个系统能够从某个过程或环境的未知特征中学到有关信息,并且能把学到的信息用于未来的估计、分类、决策或控制,以便改进系统的性能,那么它就是学习系统。1977年施密斯等人又给出了一个类似的定义:如果一个系统在与环境相互作用时,能利用过去与环境作用时得到的信息,并提高其性能,那么这样的系统就是学习系统。
由上述定义可以看出,一个学习系统应具有如下条件和能力:
(一)具有适当的学习环境
无论是在萨利斯的定义中还是在施密斯等人的定义中,都使用了“环境”这一术语。这里对环境定义是:为学习系统提供原始信息的来源,包括训练数据、交互反馈等。
(1)监督学习环境:提供带标签数据 (x, y),如图像分类中的标注数据集;
(2)强化学习环境:提供状态 s、动作 a、奖励 r 的序列,如机器人控制中的实时反馈。
示例:垃圾邮件分类系统的环境是用户标记的邮件集合 D = {(x_i, y_i)},其中 x_i 是邮件特征向量(如词频),y_i ∈ {0, 1}表示是否为垃圾邮件。
(二)具有一定的学习能力
环境只是为学习系统提供了学习及应用的条件,为要从中学到有关信息,它还必须有合适的学习方法及一定的学习能力。否则它仍然学不到知识,或者学得不好。
学习能力的度量:
(1)假设空间容量:模型类 F 的表达能力,如 VC维 VC(F);
(2)优化效率:算法在多项式时间内找到近似解的能力,如梯度下降的收敛速率![]() 。
。
算法示例:决策树学习能力体现在递归划分特征空间,ID3 算法通过信息增益![]() 选择分裂特征,其中熵
选择分裂特征,其中熵 ![]() 。
。
(三)能应用学到的知识求解问题
学习的目的在于应用,对人是这样,对学习系统也是这样。在萨利斯的定义中,就明确指出了学习系统应“能把学到的信息用于未来的估计、分类、决策或控制”,强调学习系统应该做到学以致用。事实上,如果一个人或者一个系统不能应用学到的知识求解遇到的现实问题,那他(它)也就失去了学习的作用及意义。
知识应用形式:
(1)预测任务:回归(如房价预测)、分类(如垃圾邮件识别);
(2)生成任务:图像合成(如GAN模型 ![]() );
);
(3)决策任务:强化学习中的策略 pi(a|s) 选择最优动作。
流程示例:图像识别系统的推理过程:
(1)输入图像 x 预处理为张量;
(2)通过CNN模型 f(x; θ) 提取特征(卷积层 ![]() );
);
(3)全连接层输出类别概率 p(c|x) = softmax(f(x));
(4)选择概率最高的类别![]() 作为预测结果。
作为预测结果。
(四)能提高系统的性能
这是学习系统应该达到的目标。通过学习,系统应能增长知识,提高技能,改善系统的性能,使它能完成原来不能完成的任务,或者比原来做得更好。例如对于博弈系统,如果它第一次失败了,那么它应能从失败中吸取经验教训,通过与环境的相互作用学到新的知识,做到“吃一堑,长一智”,使得以后不重蹈覆辙。
由以上分析可以看出,一个学习系统一般应该有环境、学习、知识库、执行与评价等四个基本部分组成,各部分之间的关系如图所示。

1.性能指标:
(1)准确率:分类正确样本数 / 总样本数;
(2)均方误差(MSE):回归任务中 ![]() ;
;
(3)奖励累积:强化学习中 ![]() ,γ 为折扣因子。
,γ 为折扣因子。
2.提升机制:
(1)参数调整:通过梯度下降优化损失函数;
(2)结构优化:神经网络中的剪枝、AutoML 自动选择模型架构;
(3)数据增强:图像旋转、翻转等扩充训练数据,降低过拟合风险。
三、机器学习的发展历程(结合神经科学与符号主义演进)
(一)神经元模型的研究(1940s-1960s)
这一阶段主要研究工作是应用决策理论的方法研制可适应环境的通用学习系统(General PurposeLearningSystem)。它所基于的基本思想是:如果给系统一组刺激、一个反馈源和修改自身组织的自由度,那么系统就可以自适应地趋向最优组织。这实际上是希望构造一个神经网络和自组织系统。
在此期间有代表性的工作是1957年罗森勃拉特(F.Rosenblatt)提出的感知器模型,它由阈值性神经元组成,试图模拟动物和人脑的感知及学习能力。此外,这阶段最有影响的研究成果是塞缪尔研制的具有自学习、自组织、自适应能力的跳棋程序。该程序在分析了约175000幅不同棋局后,归纳出了棋类书上推荐的走法,能根据下棋时的实际情况决定走步的策略,准确率达到48%,是机器学习发展史上一次卓有成效的探索。
1969年明斯基和佩珀特(Papert)发表了颇有影响的论著“Perceptron”,对神经元模型的研究作出了悲观的论断。鉴于明斯基在人工智能界的地位及影响以及神经元模型自身的局限性,致使对它的研究开始走向低潮。
起源:McCulloch-Pitts神经元模型(1943)提出人工神经元概念,形式化为:
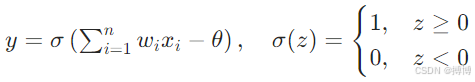
代表算法:Rosenblatt 感知机(1957),权重更新规则:![]()
局限:Minsky《感知机》(1969)指出其无法解决异或(XOR)问题,导致连接主义研究陷入低谷。
(二)符号学习研究(1970s-1990s)
当时对专家系统的研究已经取得了很大成功,迫切要求解决获取知识难的问题,这一需求刺激了机器学习的发展,研究者们力图在高层知识符号表示的基础上建立人类的学习模型,用逻辑的演绎及归纳推理代替数值的或统计的方法。莫斯托夫(D.J.Mostow)的指导式学习、温斯顿(Winston)和卡鲍尼尔(J.G.Carbonell)的类比学习以及米切尔(T.M.Mitchell)等人提出的解释学习都是在这阶段提出来的。
核心思想:通过符号逻辑表示知识,构建基于规则的学习系统。
代表方法:
(1)决策树:ID3 算法(Quinlan, 1986),通过信息增益选择分裂特征,示例流程:
1)计算根节点熵![]() ;
;
2)对每个特征 A,计算分裂后熵![]() ;
;
3)选择 IG(S, A) = H(S) - H(S|A) 最大的特征分裂;
4)递归生成子树,直至纯度达标。
(2)基于规则的学习:AQ算法(Michalski, 1969)生成“如果 - 那么”规则,如 色泽=青绿 ∧ 根蒂=蜷缩 ⇒ 好瓜。
优势与局限:可解释性强,但依赖人工特征工程,难以处理高维复杂数据。
(三)连接学习的复兴与深度学习(2000s至今)
当时由于人工智能的发展与需求以及VLSI技术、超导技术、生物技术、光学技术的发展与支持,使机器学习的研究进人了更高层次的发展时期。当年从事神经元模型研究的学者们经过10多年的潜心研究,克服了神经元模型的局限性,提出了多层网络的学习算法,从而使机器学习进人了连接学习的研究阶段。连接学习是一种以非线性大规模并行处理为主流的神经网络的研究;该研究目前仍在继续进行之中。
在这一阶段中,符号学习的研究也取得了很大进展,它与连接学习各有所长,具有较大的互补性。就目前的研究情况来看,连接学习适用于连续发音的语音识别及连续模式的识别;而符号学习在离散模式识别及专家系统的规则获取方面有较多的应用。现在人们已开始把符号学习与连接学习结合起来进行研究,里奇(E.Rich)开发的集成系统就是其中的一个例子。
1.关键突破:
(1)多层感知机与反向传播(Rumelhart, 1986):通过链式法则计算梯度,解决多层网络训练问题。对于隐含层 h,输出层 o,损失 L,梯度为:
![]()
(2)深度神经网络:AlexNet(2012)在ImageNet竞赛中准确率远超传统方法,引入ReLU激活函数![]() 缓解梯度消失。
缓解梯度消失。
(3)规模化训练:大数据(如ImageNet 1400万张图像)与GPU并行计算推动模型容量提升,Transformer模型(Vaswani, 2017)通过自注意力机制![]()
2.当前趋势:
(1)预训练模型:BERT(Devlin, 2019)通过掩码语言模型![]() 学习通用语义表示;
学习通用语义表示;
(2)神经符号结合:将神经网络与逻辑规则融合,如知识图谱嵌入模型![]() ,实现可解释推理。
,实现可解释推理。
四、机器学习的分类体系(多维视角下的模型划分)
(一)按学习方法分类(数据标注与交互方式)
1. 监督学习(Supervised Learning)
核心特征:利用带标签数据 (x, y) 学习映射 x → y。
(1)回归:输出为连续值,如线性回归![]() ,损失函数 MSE;
,损失函数 MSE;
(2)分类:输出为离散类别,如逻辑回归 ![]() ,损失函数交叉熵
,损失函数交叉熵 ![]() 。
。
示例:手写数字识别(MNIST数据集)
(1)输入:28×28 像素图像 ![]() ;
;
(2)输出:类别 y ∈ {0, 1, ..., 9};
(3)模型:全连接神经网络,Softmax 输出层 ![]() ;
;
(4)训练:最小化交叉熵损失,反向传播更新权重。
有关“模型优化之强化学习(RL)与监督微调(SFT)的区别和联系”可以看我的CSDN文章:模型优化之强化学习(RL)与监督微调(SFT)的区别和联系_sft和rl区别-CSDN博客
2. 无监督学习(Unsupervised Learning)
核心特征:仅利用无标签数据 x 发现内在结构。
聚类:如 K-means算法,流程:
(1)随机初始化 K 个质心![]() ;
;
(2)分配每个样本到最近质心 ![]() ;
;
(3)重新计算质心![]() ;
;
(4)重复直至质心稳定。
降维:如PCA,最大化投影方差 ![]() ,约束
,约束![]() ,解为样本协方差矩阵的前 d 个特征向量。
,解为样本协方差矩阵的前 d 个特征向量。
3. 半监督学习(Semi-Supervised Learning)
核心特征:结合少量标签数据 L = {(x_i, y_i)} 和大量无标签数据 U = {x_j},如自我训练(Self-Training):
(1)用标签数据训练分类器 f;
(2)对无标签数据预测伪标签![]() ;
;
(3)将高置信度样本![]() 加入训练集;
加入训练集;
(4)重复直至收敛。
4. 强化学习(Reinforcement Learning)
核心特征:智能体通过与环境交互,最大化长期累积奖励。
(1)要素:状态 S、动作 A、奖励 R、转移概率 P(s'|s, a)、策略 pi(a|s);
(2)值函数:状态值![]() ,动作值
,动作值![]() ;
;
(3)算法:Q-learning 更新规则 ![]() 。
。
示例:围棋AI AlphaGo的训练流程:
(1)监督学习阶段:从人类对弈数据学习策略网络 pi_θ (a|s);
(2)强化学习阶段:通过自我对弈,用Q-learning优化策略,结合蒙特卡洛树搜索(MCTS)选择动作。
(二)按推理方式分类(从特殊到一般的逻辑路径)
1. 归纳学习(Inductive Learning)
核心:从具体样本中归纳一般规律,即“从特殊到一般”。
(1)示例空间学习:如决策树通过样本划分特征空间,形成类别判断规则;
(2)统计学习:通过大数定律,用经验风险最小化(ERM)逼近期望风险,如SVM最大化分类间隔![]() ,等价于
,等价于![]() 约束
约束![]() 。
。
2. 演绎学习(Deductive Learning)
核心:从一般知识推导出具体结论,即“从一般到特殊”。
(1)基于知识的学习:将先验知识编码为逻辑规则,如专家系统中的产生式规则 IF 条件 THEN 结论,结合数据进行演绎推理;
(2)符号逻辑与神经网络结合:如神经符号系统(Neurosymbolic AI),用神经网络提取特征,再通过逻辑规则进行决策。
3. 类比学习(Analogical Learning)
核心:通过相似性匹配,将已知领域的知识迁移到新领域。
(1)迁移学习:如微调预训练模型,将ImageNet上训练的ResNet迁移到医学影像分类,固定底层特征提取层,仅训练顶层分类器;
(2)度量学习:学习样本相似度函数 d(x_i, x_j),如三元组损失 L = max(0, d(x_a, x_p) - d(x_a, x_n) + \margin),其中 x_a 为锚样本,x_p 为正样本,x_n 为负样本。
(三)按综合属性分类(模型动态性与学习模式)
1. 批量学习(Batch Learning)
特征:一次性处理全部训练数据,训练完成后模型参数固定。
优势:便于并行计算,适合静态数据集;
局限:无法适应数据分布变化,如概念漂移(Concept Drift)场景。
2. 在线学习(Online Learning)
特征:按顺序处理数据样本,实时更新模型参数,如随机梯度下降(SGD)每接收一个样本即更新一次:![]()
应用:推荐系统实时响应用户行为变化,股票预测模型处理流式数据。
3. 增量学习(Incremental Learning)
特征:在已有知识基础上逐步学习新数据,避免“灾难性遗忘”。
技术:弹性权重巩固(EWC)通过惩罚参数变化![]() ,其中 F 为Fisher信息矩阵,记录旧任务重要参数;
,其中 F 为Fisher信息矩阵,记录旧任务重要参数;
示例:图像识别模型新增类别时,保留对旧类别识别能力。
4. 主动学习(Active Learning)
特征:主动选择最有价值的样本进行标注,降低数据标注成本。
查询策略:
(1)不确定性采样:选择模型预测最不确定的样本,如分类中概率接近 0.5 的样本;
(2)委员会查询:多个模型意见分歧大的样本;
流程:
(1)用少量初始标注数据训练模型;
(2)对无标签数据排序,选择 top-k 最有价值样本;
(3)人工标注后加入训练集,重复训练。
五、数学基础与理论保证(补充王永庆书中的形式化分析)
(一)泛化误差界
根据统计学习理论,对于假设空间 F 中的模型 f,泛化误差 R(f) 满足:
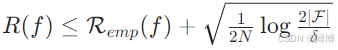
其中 |F| 为假设空间大小,N 为样本数,δ为置信度。该不等式表明模型复杂度与样本量的权衡关系(偏差 - 方差困境)。
(二)VC 维理论
VC维 d_VC 刻画模型的表达能力,对于二分类问题,若存在 d 个样本可被模型打散(即能表示所有 2^d 种标签组合),则 d_{VC} ≥ d。VC维越高,模型容量越大,但过拟合风险也越高。
(三)凸优化与非凸优化
(1)凸损失函数(如线性回归的 MSE):存在唯一全局最优解,梯度下降可收敛到全局最优;有关凸函数可以看我的CSDN文章:优化算法中的凸函数_凸优化-CSDN博客
(2)非凸损失函数(如神经网络的交叉熵):存在多个局部最优解,需通过初始化、学习率调度、动量项(![]() )等技巧逃离鞍点。有关非凸函数可以看我的CSDN文章:常用于优化算法测试的python非凸函数有哪些?_rastrigin函数-CSDN博客
)等技巧逃离鞍点。有关非凸函数可以看我的CSDN文章:常用于优化算法测试的python非凸函数有哪些?_rastrigin函数-CSDN博客
总结与展望
机器学习从早期的神经元模型和符号学习,发展到如今的深度学习与大规模预训练模型,其核心始终围绕 “如何从数据中高效提取可泛化知识”。未来发展将呈现以下趋势:
(1)神经符号融合:结合神经网络的感知能力与符号逻辑的推理能力,实现可解释AI;
(2)自监督学习:利用海量无标签数据,通过对比学习(如 SimCLR 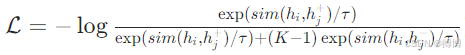 )构建通用特征表示;
)构建通用特征表示;
(3)低碳机器学习:研究高效模型压缩(如知识蒸馏![]() )与边缘设备部署,降低算力消耗。
)与边缘设备部署,降低算力消耗。
通过理解机器学习的基本概念、系统构成、发展脉络与分类体系,我们得以把握这一学科的核心逻辑,并为实际应用提供理论支撑。从数学建模到工程实现,机器学习始终是理论与实践紧密结合的典范,其进步将持续推动人工智能在各领域的落地与创新。