【T-MRMSM】文本引导多层次交互多尺度空间记忆融合多模态情感分析
在特征提取的部分用了k-means
abstract
(背景)
近年来,随着多模态数据量的迅速增加,多模态情感分析(MSA)越来越受到关注.该方法通过整合不同数据模态间的信息,提高了情感极性提取的准确性,从而实现了信息的全面融合,提高了情感分析的精度。
(针对创新处的不足)
然而,现有的深度模型往往忽略了空间和全局记忆信息对情感分析的辅助作用。此外,对语篇模态的强调往往会阻碍视觉和听觉模态信息的表达。
(整个框架的创新)
为解决该问题,提出了一种基于文本引导的多层次表示集成和多尺度空间-记忆信息融合模型T-MRMSM。具体介绍了三个主要模块:尺度全局信息提取(S-GIE)模块、增强记忆(EM)模块和两步交叉注意融合(2Steps-AT)模块。
(优势之处)
该模型能够保证提取多层次、多尺度的特征表示,增强模型的记忆能力,从而为模态内特征提取和模态间表示融合提供长程和空间信息,在一定程度上解决了对文本模态的依赖性,同时增强了其他两种模态的影响因子。在基准数据集(MOSI,MOSEI)上的大量实验表明,TMRMSM方法比现有方法具有显著的优势.
intro
(近些年来的发展)
近年来,社交媒体的快速扩张推动了用户生成内容的大幅增加,特别是视频。跨不同模态的自动情感分析已成为旨在增强人机交互的关键研究领域[1],[2]。情感分析最初专注于提取和分析通过文本传达的情感。然而,随着计算能力的提高和视听通信的兴起,多模态情感分析(MSA)已经出现。这种方法整合了文本、音频和视觉输入,以加深对人类情感的理解。MSA在教育、客户反馈分析、心理健康监测和个性化广告等多个领域都有应用,显著增强了我们在各种沟通形式中解释和应对情感线索的能力。多模态情感分析(MSA)旨在整合来自视觉、声学和文本来源的情感线索,以预测说话者的情感状态或倾向。然而,这些模式的情绪信号可能会有微妙的变化。
(多模态情感分析的重要性)
图1说明了MSA的好处,展示了如何添加visaul和音频信息可以提高模糊句子和不同上下文中情感极性预测的准确性,例如,一个男人说“我看到了一只猫”,单独的文本线索可能无法揭示他的情绪并判断可能保持中立,但我们可以在添加他的快乐表情和积极语气后推断他的真实情绪。因此,开发有效的融合方案,整合这些不同的方式的信息是至关重要的。
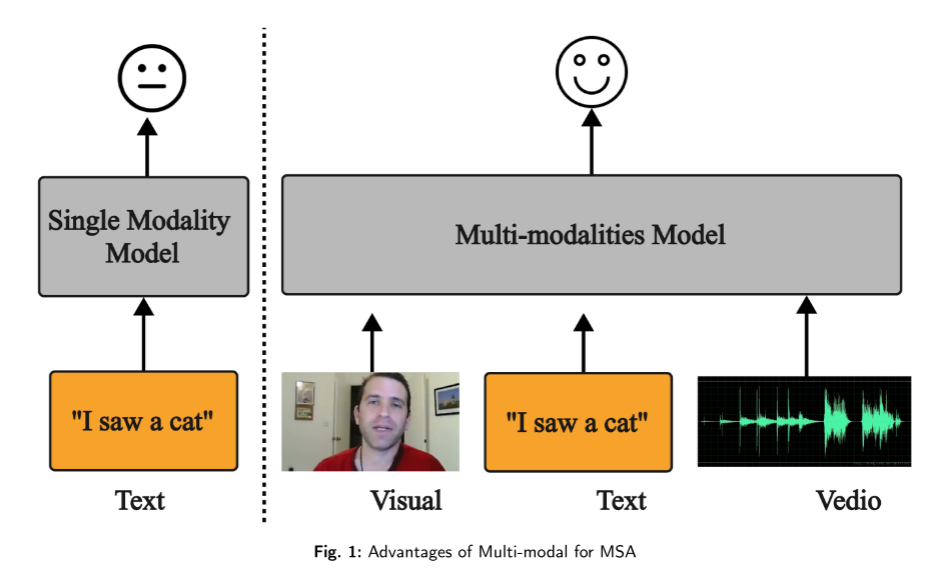
(联系创新,解释互补-一致的意思)
多模态学习研究强调了跨模态整合信息以实现全面语义理解的必要性[3]。鉴于人类心理状态的细微差别,全面的信息交换确保了多模态语义的互补和一致的解释。互补性是指模态填补了其他模态留下的信息空白,而一致性则确保了所学信息在相同的语义语境中保持相关性。至关重要的是,不同的模式保持重点;例如,一个侧重于情感分析,而另一个侧重于性别的模式就不合适。目前的策略涉及设计促进多式联运交互的结构[4][5][6],通常利用Transformer的查询键值(QKV)操作,因为它们在自然语言处理(NLP)和计算机视觉(CV)方面取得了进步。此外,H.Zhu等人[7]提出了一种双边加权回归排序模型(BWRR)。该方法将原始的相关滤波回归问题转化为带排序的回归问题,有效地解决了正负样本不平衡的问题。
(主要挑战)
多模态语义分析的主要挑战是将不同输入模态所传达的情感信息进行联合收割机联合表示,为情感消歧提供更多的基础。这允许对说话者所表达的真实的情感进行更准确的分析。Truong等人[8]认为多模态信息之间的一致性和互补性可以提高情感预测的准确性。在互补性方面,情感极性判断可以通过利用来自其他模态的信息来填补模糊情感表达的空白。
(具体文献举例发展)
集成不同的模式是多模态情感分析任务的必要和具有挑战性的问题。现有的多模态融合方法通常包括特征级融合[9][10]、决策级融合[11][12]和一致性回归融合[13][14]。J. Guo等人[15]提出了一种用于图像-文本检索的新型分层图对齐网络(HGAN)。该方法为图像和文本模态构建特征图,并引入多粒度特征聚合和重排模块来建立共享空间。这增强了局部和全局信息之间的语义对齐,从而为两种模态提供更准确的特征表示。基于注意力的多模态情感分析(MSA)模型的最新进展,如多注意力回路网络(MARN)[16],在捕获模态内和模态间动态方面取得了重大突破。这些模型增强了对不同通信模式(文本、音频和视觉)如何相互作用以表达和影响人类情感的理解,标志着情感分析研究向前迈出了显著的一步。此外,来自多个输入表示的特征的基于张量的融合[4]已被证明在实现鲁棒结果方面是有效的。Liu等人[17]研究了维数变化和张量计算对模态表示的影响,提出了低秩多模态融合以简化张量复杂性。R.Zhang等人[18]将交替方向乘法器法(ADMM)与梯度下降法相结合进行参数优化。对融合后的高频分量和低频分量进行逆NSST重构,得到融合图像。He等人[19]引入了一种层次图融合网络来动态地合并模态表示。然而,现有的特征融合方法往往忽略了不同模态之间的一致性和互补性的重要性。在广泛的文本语料库上训练的预先训练的语言模型显著地增强了文本中的情感理解。相比之下,声学和视觉模态则依赖于COVAREP[20]和Fac