深度学习 视觉处理(CNN) day_02
1. 卷积知识扩展
1.1 卷积结果
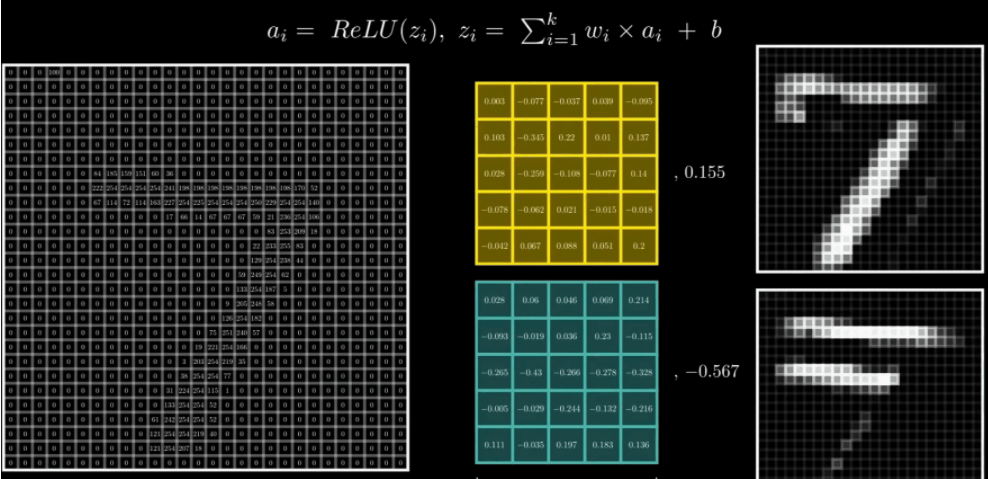
1.2 二维卷积
分单通道版本和多通道版本。
1.2.1 单通道版本
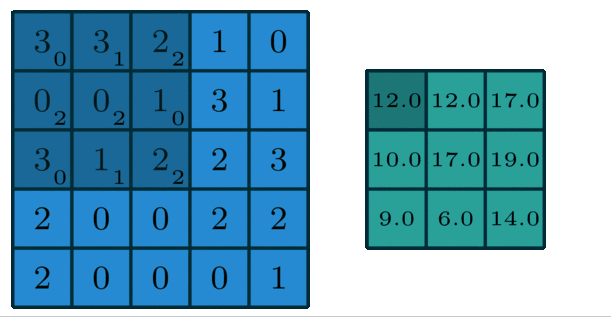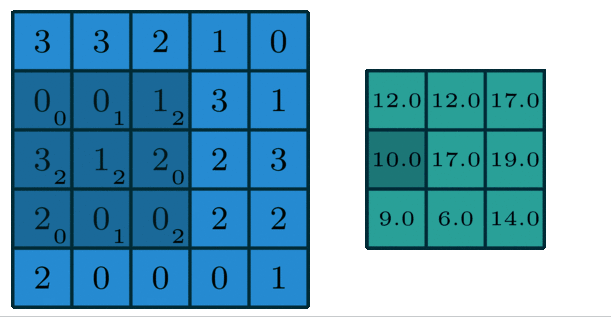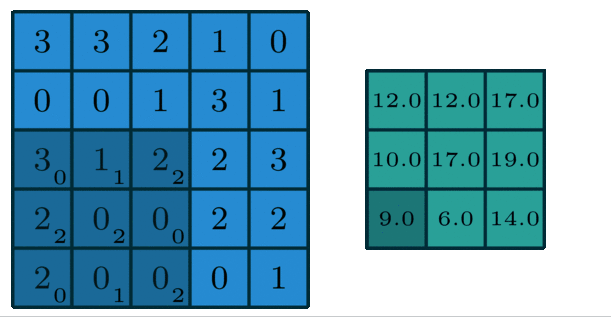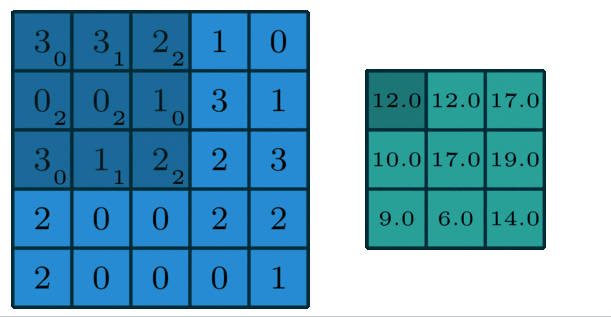
之前所讲卷积相关内容其实真正意义上叫做二维卷积(单通道卷积版本),即只有一个通道的卷积。
如下图,我们对于卷积核(kernel)的描述一般是大小3x3、步长(stride)为1、填充(Padding)为0。
1.2.2 多通道版本
彩色图像拥有R、G、B这三层通道,因此我们在卷积时需要分别针对这三层进行卷积
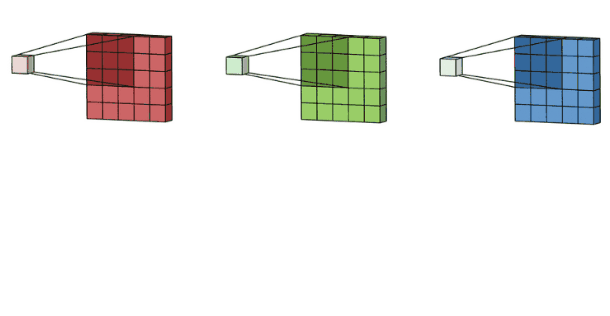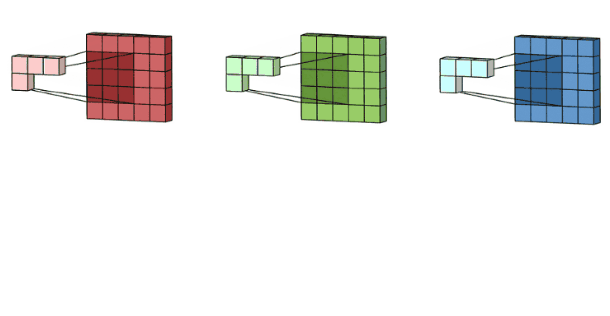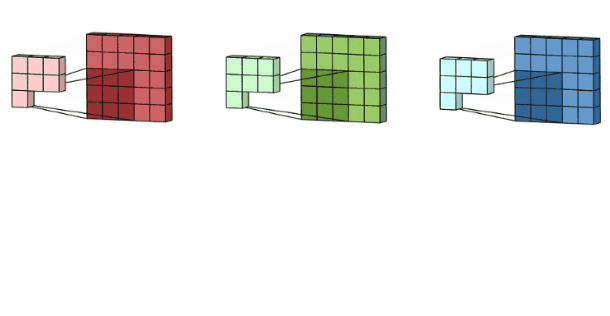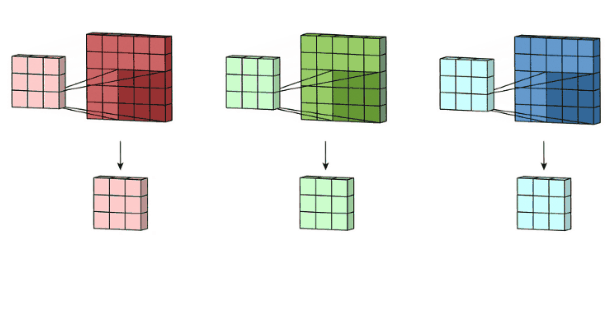
最后将三个通道的卷积结果进行合并(元素相加,就是在通道上进行特征的一个融合操作),得到卷积结果。

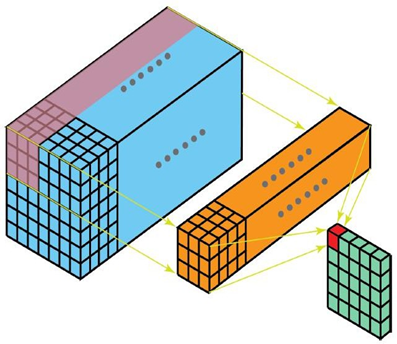
1.3 三维卷积
二维卷积是在单通道的一帧图像上进行滑窗操作,输入是高度H宽度W的二维矩阵。
而如果涉及到视频上的连续帧或者立体图像中的不同切片,就需要引入深度通道,此时输入就变为高度H宽度W*深度C的三维矩阵。
不同于二维卷积核只在两个方向上运动,三维卷积的卷积核会在三个方向上运动,因此需要有三个自由度。
这种特性使得三维卷积能够有效地描述3D空间中的对象关系,它在一些应用中具有显著的优势,例如3D对象的分割以及医学图像的重构等。
1.4 反卷积
卷积是对输入图像及进行特征提取,这样会导致尺寸会越变越小,而反卷积是进行相反操作。并不会完全还原到跟输入图一样,只是保证了与输入图像尺寸一致,主要用于向上采样。从数学上看,反卷积相当于是将卷积核转换为稀疏矩阵后进行转置计算。也被称为转置卷积。
1.4.1 反卷积计算过程
如图,在2x2的输入图像上使用【步长1、边界全0填充】的3x3卷积核,进行转置卷积(反卷积)计算,向上采样后输出的图像大小为4x4。
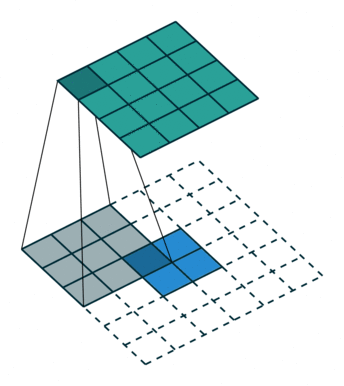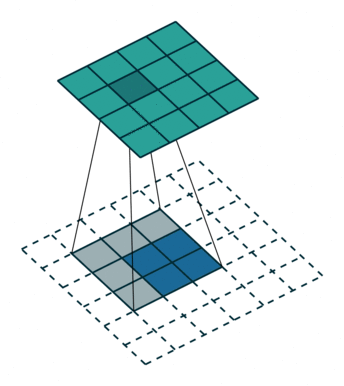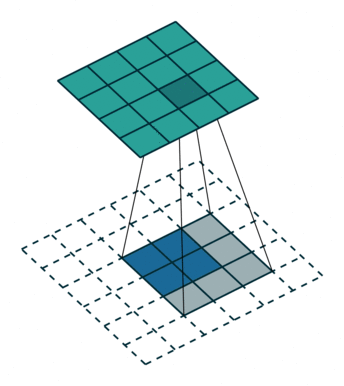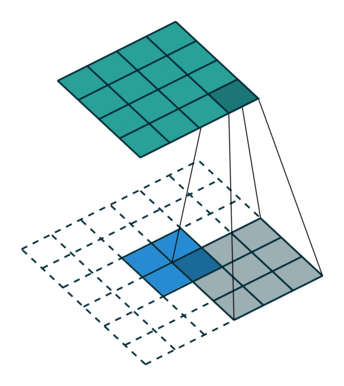
如我们的语义分割里面就需要反卷积还原到原始图像大小。
1.4.2 反卷积底层计算
反卷积的计算过程如下图:
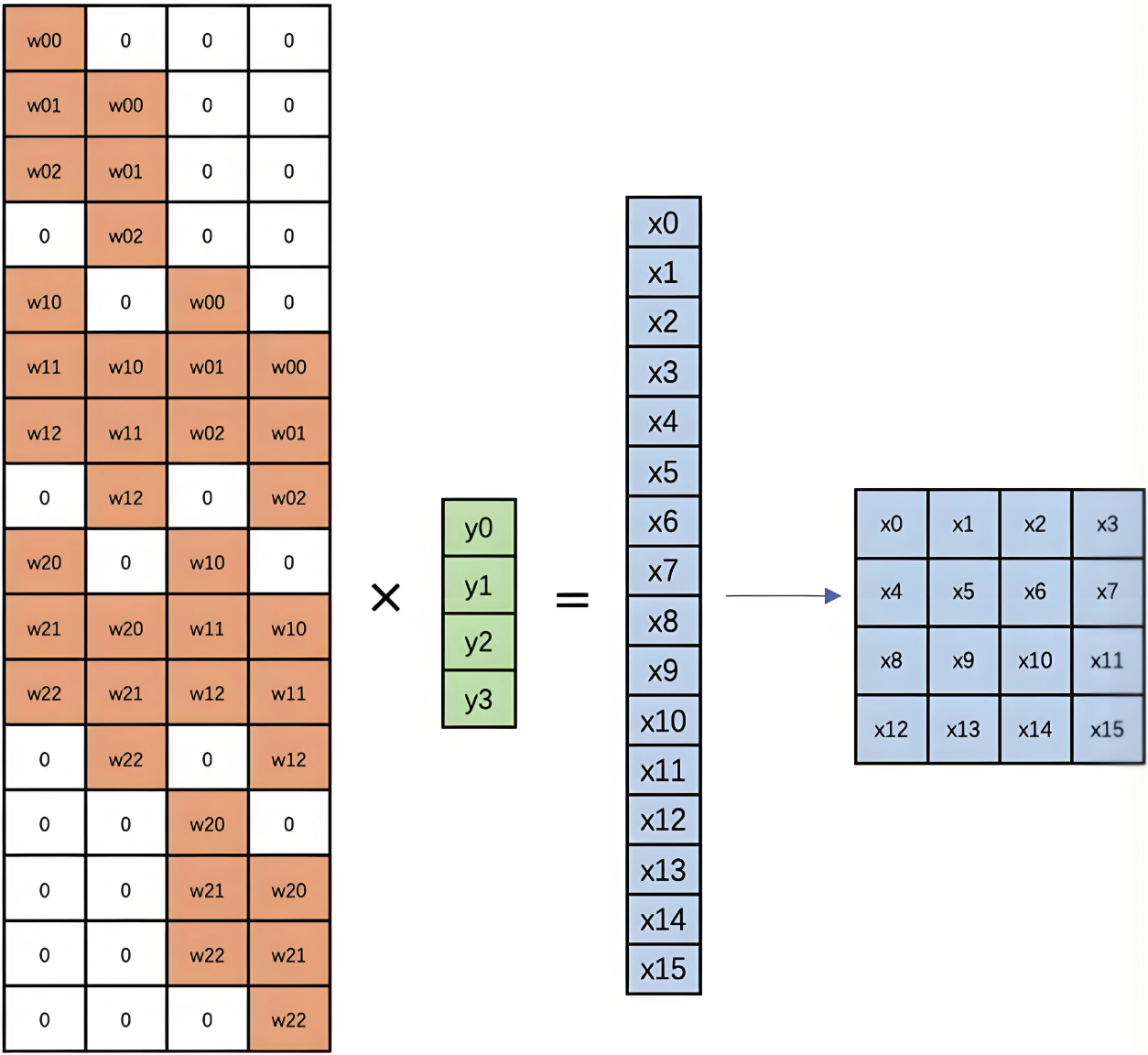
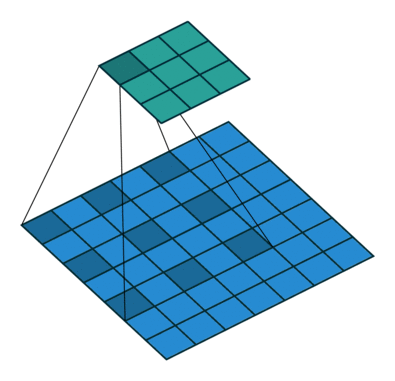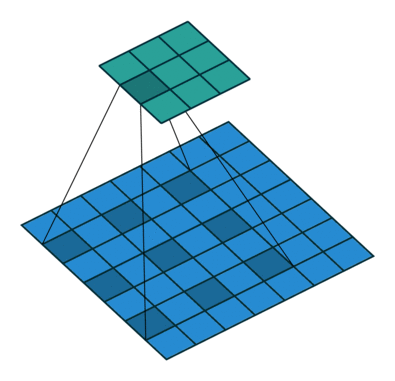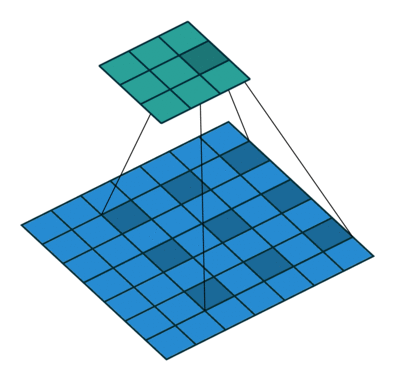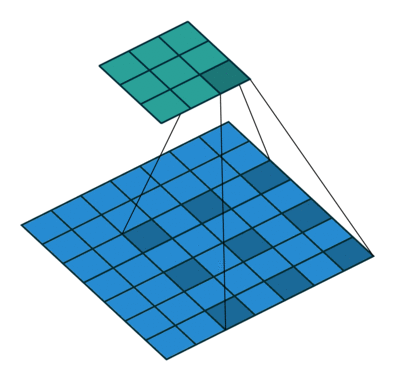
1.5 膨胀卷积
也叫膨胀卷积。为扩大感受野,在卷积核的元素之间插入空格“膨胀”内核,形成空洞卷积,并用膨胀率参数L表示要扩大内核的范围,即在内核元素之间插入L-1个空格。当L=1时,内核元素之间没有插入空格,变为标准卷积。图中是L=2的空洞卷积。
1.6 可分离卷积
1.6.1 空间可分离卷积
空间可分离卷积是将卷积核分解为两项独立的核分别进行操作。在数学中我们可以将矩阵分解:
所以对3x3的卷积核,我们同样可以拆分成 3x1 和 1x3 的两个卷积核,对其进行卷积,且采用可分离卷积的计算量比标准卷积要少。
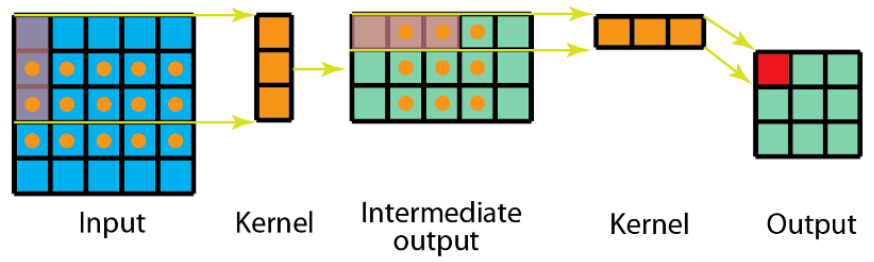
1.6.2 深度可分离卷积
深度可分离卷积由两部组成:深度卷积核$1\times1$卷积,我们可以使用`Animated AI`官网的图来演示这一过程。
图1:输入图的每一个通道,我们都使用了对应的卷积核进行卷积。 通道数量 = 卷积核个数,每个卷积核只有一个通道。

图2:完成卷积后,对输出内容进行`1x1`的卷积。

1.7 扁平卷积
扁平卷积是将标准卷积拆分成为3个`1x1`的卷积核,然后再分别对输入层进行卷积计算。
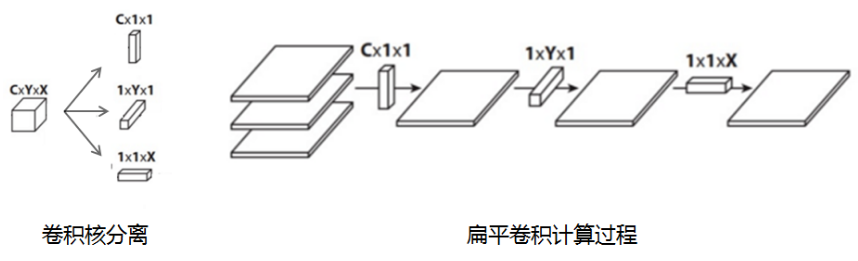
- 标准卷积参数量XYC,计算量为MNCXY
- 拆分卷积参数量(X+Y+C),计算量为MN(C+X+Y)
1.8 分组卷积
2012年,AlexNet论文中最先提出来的概念,当时主要为了解决GPU显存不足问题,将卷积分组放到两个GPU中并行执行。
在分组卷积中,卷积核被分成不同的组,每组负责对相应的输入层进行卷积计算,最后再进行合并。
下图中卷积核被分成两个组,前半部负责处理前半部的输入层,后半部负责后半部的输入层,最后将结果组合。
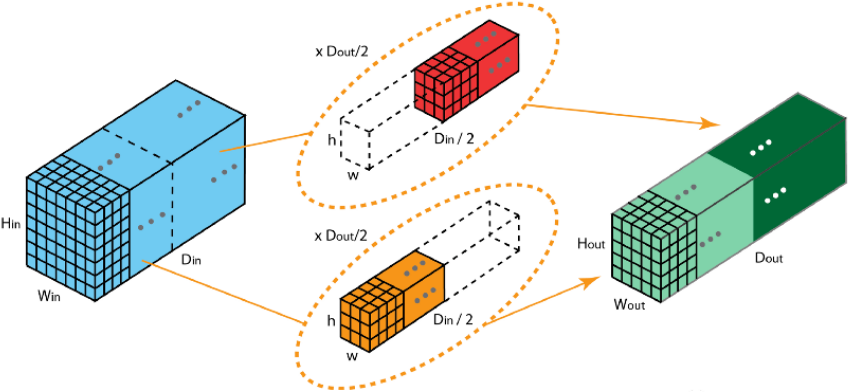
分组卷积中:
1. 输入通道被划分为若干组。
2. 每组通道只与对应的卷积核计算。
3. 不同组之间互相独立,卷积核不共享。
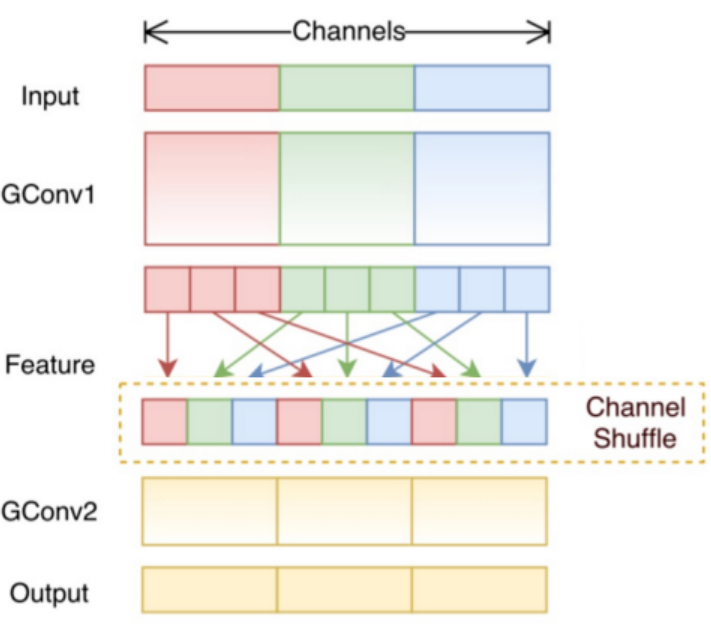
1.9 混洗分组卷积
分组卷积中最终结果会按照原先的顺序进行合并组合,阻碍了模型在训练时特征信息在通道间流动,削弱了特征表示。混洗分组卷积,主要是将分组卷积后的计算结果混合交叉在一起输出。
2. 感受野
2.1 理解感受野
字面意思是感受的视野范围
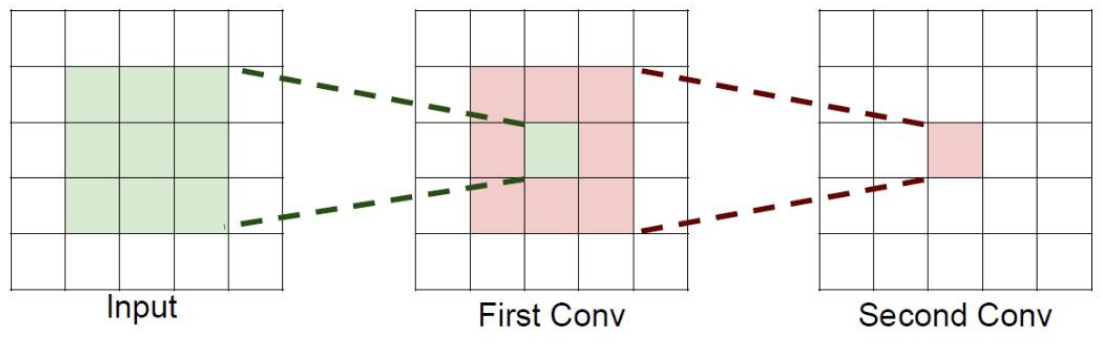
如果堆叠3个3 x 3的卷积层,并且保持滑动窗口步长为1,其感受野就是7×7的了, 这跟一个使用7x7卷积核的结果是一样的,那为什么非要堆叠3个小卷积呢?
2.2 感受野的作用
假设输入大小都是h × w × C,并且都使用C个卷积核(得到C个特征图),可以来计算 一下其各自所需参数。
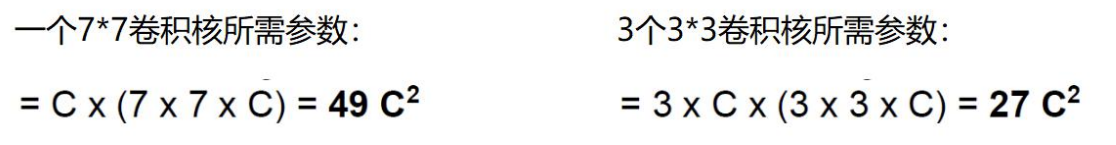
很明显,堆叠小的卷积核所需的参数更少一些,并且卷积过程越多,特征提取也会越细致,加入的非线性变换也随着增多,还不会增大权重参数个数,用小的卷积核来完成体特征提取操作。
3. 卷积神经网络案例
3.1 模型结构
网络结构如下:
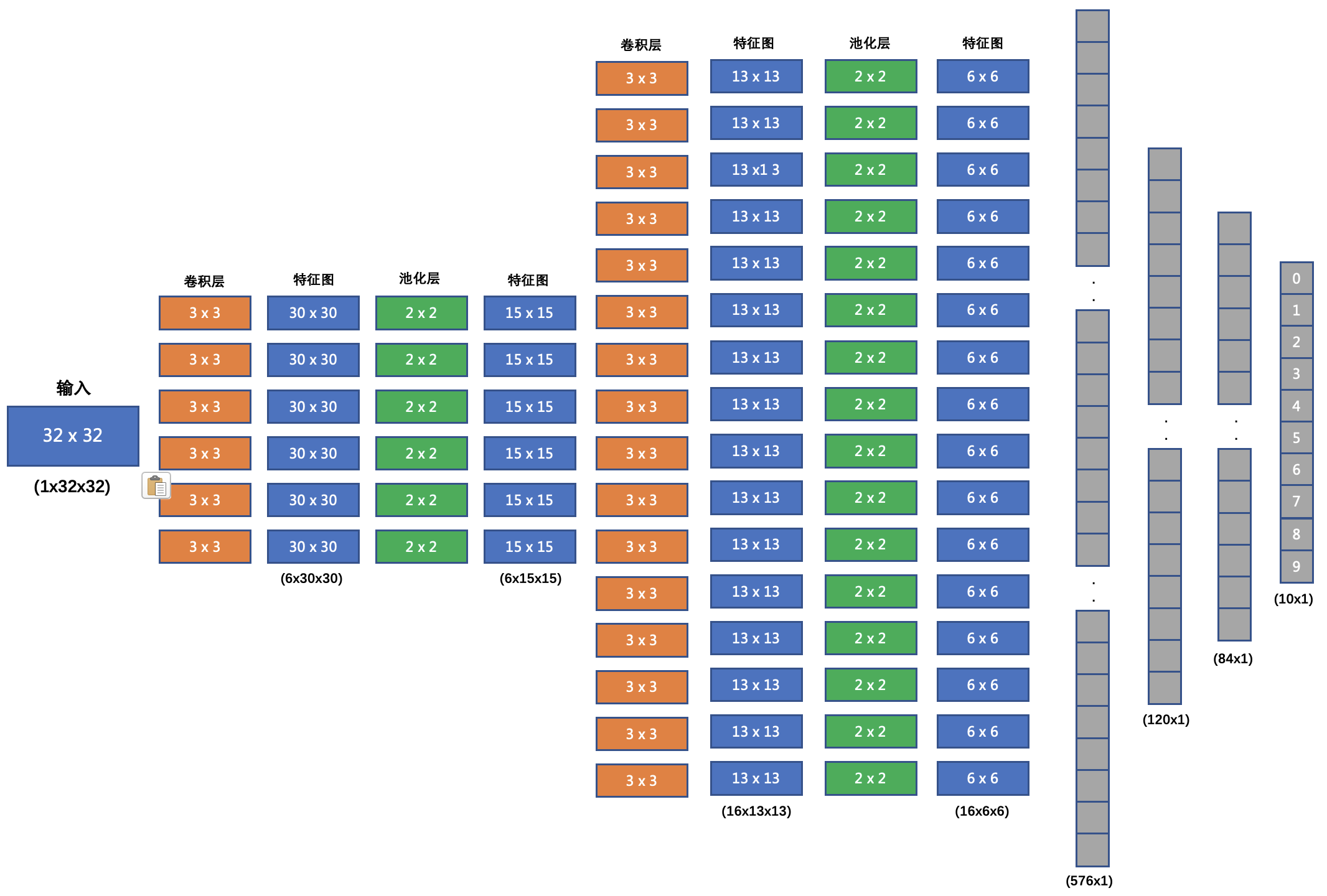
1. 输入形状: 32x32
2. 第一个卷积层输入 3 个 Channel, 输出 6 个 Channel, Kernel Size 为: 3x3
3. 第一个池化层输入 30x30, 输出 15x15, Kernel Size 为: 2x2, Stride 为: 2
4. 第二个卷积层输入 6 个 Channel, 输出 16 个 Channel, Kernel Size 为 3x3
5. 第二个池化层输入 13x13, 输出 6x6, Kernel Size 为: 2x2, Stride 为: 2
6. 第一个全连接层输入 576 维, 输出 120 维
7. 第二个全连接层输入 120 维, 输出 84 维
8. 最后的输出层输入 84 维, 输出 10 维
我们在每个卷积计算之后应用 relu 激活函数来给网络增加非线性因素。
3.2 网络模型定义
示例:
import torch
import torch.nn as nnclass ImageClassification(nn.Module):def __init__(self):super(ImageClassification, self).__init__()# 这是一层卷积层self.layer1 = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Dropout(0.25),)self.layer2 = nn.Sequential(nn.Conv2d(in_channels=32, out_channels=128, kernel_size=3, stride=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Dropout(0.25),)self.linear1 = nn.Sequential(nn.Linear(128 * 6 * 6, 2048), nn.ReLU(), nn.Dropout(0.5))self.linear2 = nn.Sequential(nn.Linear(2048, 1024), nn.ReLU(), nn.Dropout(0.5))self.out = nn.Linear(1024, 10)def forward(self, x):x = self.layer1(x)x = self.layer2(x)x = x.reshape(x.size(0), -1)x = self.linear1(x)x = self.linear2(x)return self.out(x)3.3 用到的模块
示例:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision.datasets import CIFAR10
from torchvision.transforms import Compose, ToTensor
from torch.utils.data import DataLoader
import os
import time# 从modele目录导入模型
from model.image_classification import ImageClassification3.4 CIFAR10数据源
示例:
def test001():dir = os.path.dirname(__file__)# 加载数据集train = CIFAR10(root=os.path.join(dir, "data"),train=True,download=True,transform=Compose([ToTensor()]),)vaild = CIFAR10(root=os.path.join(dir, "data"),train=False,download=True,transform=Compose([ToTensor()]),)# 观察一下数据集信息print("训练数据集数量:", train.__len__())# 观察一下数据集分类情况print("训练数据集分类情况:", train.class_to_idx)train_loader = DataLoader(train, batch_size=128, shuffle=True)vaild_loader = DataLoader(vaild, batch_size=128, shuffle=True)for i, (x, y) in enumerate(train_loader):print(i, x.shape, y.shape)3.5 模型训练及保存
示例:
def train():dir = os.path.dirname(__file__)device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 加载数据集train = CIFAR10(root=os.path.join(dir, "data"),train=True,download=True,transform=transform,)# 导入模型model = ImageClassification()model.to(device)# 定义i模型训练的超参数epochs = 80lr = 1e-3batch_size = 256loss_history = []# 构建训练用的损失函数及优化器criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=lr)for i, epoch in enumerate(range(epochs)):# 构建训练数据批次train_loader = DataLoader(train, batch_size=batch_size, shuffle=True)# 记录样本数量train_num = 0# 记录总的损失值:用于计算平均损失total_loss = 0.0# 记录正确记录数correct = 0# 记录训练开始时间start = time.time()# 开始使用批次数据进行训练for x, y in train_loader:# 更改模型训练设备x = x.to(device)y = y.to(device)# 送入模型output = model(x)# 计算损失loss = criterion(output, y)# 梯度清零optimizer.zero_grad()# 反向传播loss.backward()# 更新参数optimizer.step()# 更新训练过程的数据train_num += len(y)total_loss += loss.item() * len(y)correct += output.argmax(1).eq(y).sum().item()print("epoc:%d loss:%.3f accuracy:%.3f time:%.3f"% (i + 1, total_loss / train_num, correct / train_num, time.time() - start))loss_history.append(total_loss / train_num)# 更新图形update_plot(loss_history)# 训练完成之后,保存模型torch.save(model.state_dict(), os.path.join(dir, "model.pth"))print("模型保存成功:", i)3.6 模型加载及验证
示例:
# 测试集评估
def vaild():dir = os.path.dirname(__file__)device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 定义超参数batch_size = 100# 定义测试记录数据vaild_num = 0total_correct = 0vaild_data = CIFAR10(root=os.path.join(dir, "data"),train=False,download=False,transform=transform,)# 构建测评数据集批次vaild_loader = DataLoader(vaild_data, batch_size=batch_size, shuffle=False)model = ImageClassification()# 加载模型参数model.load_state_dict(torch.load(os.path.join(dir, "model.pth")))# 切换为验证模式model.to(device)model.eval()for x, y in vaild_loader:x = x.to(device)y = y.to(device)output = model(x)total_correct += output.argmax(1).eq(y).sum().item()vaild_num += len(y)print("测试集正确率:%.3f" % (total_correct / vaild_num))我们可以从以下几个方面来调整网络:
1. 增加卷积核输出通道数;
2. 增加全连接层的参数量;
3. 调整学习率;
4. 调整优化方法;
5. 修改激活函数;
6. 进行数据增强,等等。
3.7 数据增强
示例:
data_transforms = {'train': transforms.Compose([transforms.RandomRotation(45),#随机旋转,-45到45度之间随机选transforms.CenterCrop(224),#从中心开始裁剪transforms.RandomHorizontalFlip(p=0.5),#随机水平翻转 选择一个概率概率transforms.RandomVerticalFlip(p=0.5),#随机垂直翻转transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),#参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相transforms.RandomGrayscale(p=0.025),#概率转换成灰度率,3通道就是R=G=Btransforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#均值,标准差]),'valid': transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
}from torchvision import transforms
from PIL import Image# 定义图像预处理步骤
preprocess = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])# 打开图像
img = Image.open("path_to_image.jpg")# 应用预处理步骤
img_tensor = preprocess(img)3.8 实时渲染训练效果
示例:
# 更新图形的函数
def update_plot(loss_history):plt.cla() # 清除之前的图形plt.plot(loss_history, marker="o", color="green", linestyle="-") # 绘制损失率曲线plt.xlabel("Epoch")plt.ylabel("Loss")plt.title("Training Loss")plt.grid(True)plt.pause(0.001) # 暂停一段时间以便更新图形# 开始训练模型并动态显示损失率变化plt.ion() # 打开交互模式train()plt.ioff() # 关闭交互模式plt.show()#在训练的时候实时更新数据
loss_history = []
loss_history.append(total_loss / train_num)
# 更新图形
update_plot(loss_history)