第11章 面向分类任务的表示模型微调
- 第1章 对大型语言模型的介绍
- 第2章 分词和嵌入
- 第3章 解析大型语言模型的内部机制
- 第4章 文本分类
- 第5章 文本聚类与主题建模
- 第6章 提示工程
- 第7章 高级文本生成技术与工具
- 第8章 语义搜索与检索增强生成
- 第9章 多模态大语言模型
- 第10章 构建文本嵌入模型
- 第12章 微调生成模型
在第四章中,我们使用了预训练模型对文本进行分类。我们直接使用了未经任何修改的预训练模型。这可能会让你产生疑问:如果我们对模型进行微调会发生什么?
如果有充足的数据,微调通常能产生性能最佳的模型。在本章中,我们将探讨几种微调BERT模型的方法和应用:
- 《监督式分类》展示了微调分类模型的通用流程;
- 《少样本分类》将介绍SetFit方法——一种通过少量训练样本高效微调高性能模型的技术;
- 《基于掩码语言建模的继续预训练》探讨了如何对预训练模型进行持续训练;
- 《命名实体识别》研究了基于词元级别的分类任务。
我们将专注于非生成式任务,生成式模型相关内容将在第十二章中讨论。
监督式分类
在第4章中,我们通过利用预训练的表示模型探索了监督式分类任务。这些模型要么是经过训练以预测情感(任务特定模型),要么是用于生成嵌入表示(嵌入模型),如图11-1所示。
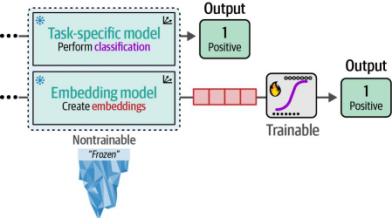
图11-1. 在第4章中,我们使用了预训练模型执行分类任务,但未更新其权重。这些模型被保持为"冻结"状态
这两个模型均保持冻结(不可训练)状态,以展示利用预训练模型进行分类任务的潜力。嵌入模型采用了独立的可训练分类头(classifier)来预测电影评论的情感极性。在本节中,我们将采取类似方法,但允许同时对基础模型和分类头进行训练更新。如图11-2所示,我们将不再使用独立的嵌入模型,而是通过微调预训练BERT模型来创建任务专用模型(类似于第2章中的实现方式)。与嵌入模型方法相比,这次我们将表示模型(representation model)和分类头作为统一架构进行联合微调。
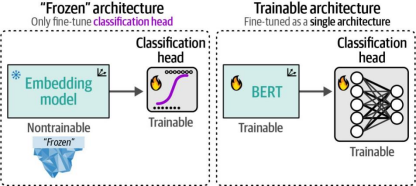
图11-2. 与"冻结"架构不同,我们会对预训练BERT模型和分类头都进行训练。反向传播过程将从分类头开始,经过BERT模型(进行传播)
为此,我们不是冻结模型,而是使其在整个训练过程中保持可训练状态并更新参数。如图11-3所示,我们将采用一个预训练的BERT模型,并在其基础上添加一个作为分类头的神经网络结构。这两部分组件都将通过微调过程进行优化,以适配具体的分类任务需求。
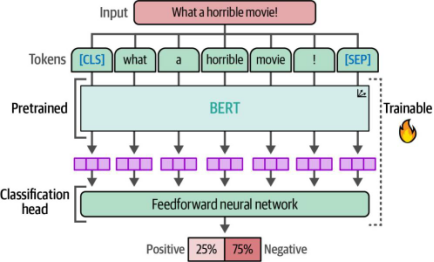
图11-3. 任务特定模型的架构。它包含一个预训练模型(例如BERT),并附加了一个专用于该任务的分类头
实际应用中,这意味着预训练BERT模型和分类头会共同更新。它们并非独立运行,而是通过相互学习实现更精准的特征表征。
微调预训练的BERT模型
我们将使用第4章中使用的相同数据集来微调模型,即包含来自烂番茄的5,331条正面和5,331条负面电影评论的烂番茄数据集。
from datasets import load_dataset# Prepare data and splits
tomatoes = load_dataset("rotten_tomatoes")
train_data, test_data = tomatoes["train"], tomatoes["test"]我们分类任务的第一步是选择要使用的基础模型。我们选用了"bert-base-cased",该模型在英文维基百科以及包含未发表书籍的大型数据集上进行了预训练[1]。我们需要预先定义想要预测的标签数量,这是构建于预训练模型之上的前馈神经网络所必需的步骤:
from transformers import AutoTokenizer, AutoModelForSequenceClassification# Load model and tokenizer
model_id = "bert-base-cased"
model = AutoModelForSequenceClassification.from_pretrained(model_id, num_labels=2
)
tokenizer = AutoTokenizer.from_pretrained(model_id) 接下来,我们将对数据进行分词处理:
from transformers import DataCollatorWithPadding# Pad to the longest sequence in the batch
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
def preprocess_function(examples):"""Tokenize input data"""return tokenizer(examples["text"], truncation=True)
# Tokenize train/test data
tokenized_train = train_data.map(preprocess_function, batched=True)
tokenized_test = test_data.map(preprocess_function, batched=True)在创建Trainer之前,我们需要准备一个特殊的DataCollator。DataCollator是一个帮助我们构建数据批次的工具类,同时它还允许我们应用数据增强技术。
在分词过程中(如第9章所示),我们会通过填充(padding)手段使输入文本形成统一长度的表征。为此,我们使用DataCollatorWithPadding来实现这一功能。
当然,如果没有定义一些评估指标(metrics),完整的示例代码就略显遗憾了:
import numpy as np
from datasets import load_metricdef compute_metrics(eval_pred):"""Calculate F1 score"""logits, labels = eval_predpredictions = np.argmax(logits, axis=-1)load_f1 = load_metric("f1")f1 = load_f1.compute(predictions=predictions, references=labels)["f1"]return {"f1": f1}1 Jacob Devlin et al. “BERT: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
通过compute_metrics,我们可以定义任意数量的感兴趣的指标,这些指标可以在训练过程中打印输出或记录日志。这在训练过程中特别有用,因为它可以帮助检测模型的过拟合行为。接下来我们将实例化我们的训练器(Trainer):
from transformers import TrainingArguments, Trainer# Training arguments for parameter tuning
training_args = TrainingArguments("model",learning_rate=2e-5,per_device_train_batch_size=16,per_device_eval_batch_size=16,num_train_epochs=1,weight_decay=0.01,save_strategy="epoch",report_to="none"
)# Trainer which executes the training process
trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_train,eval_dataset=tokenized_test,tokenizer=tokenizer,data_collator=data_collator,compute_metrics=compute_metrics,
)TrainingArguments类定义了需要调整的超参数,例如学习率和训练轮次(rounds)。Trainer用于执行训练过程。
最后,我们可以训练模型并进行评估:
trainer.evaluate()
{'eval_loss': 0.3663691282272339,
'eval_f1': 0.8492366412213741,
'eval_runtime': 4.5792,
'eval_samples_per_second': 232.791,
'eval_steps_per_second': 14.631,
'epoch': 1.0}
我们的F1分数达到了0.85,明显高于第四章中使用的任务特定模型的0.80。这表明自行微调模型比直接使用预训练模型更具优势,而整个训练过程仅需花费我们几分钟时间。
冻结层
为了进一步展示训练整个网络的重要性,接下来的示例将演示如何使用 Hugging Face Transformers 冻结网络的特定层。
我们将冻结主 BERT 模型,并仅允许更新通过分类头(classification head)。这将是一个很好的对比,因为我们除冻结特定层外,其他设置均保持不变。
首先,让我们重新初始化模型,以便从头开始训练:
# Load model and tokenizermodel = AutoModelForSequenceClassification.from_pretrained(model_id, num_labels=2
)tokenizer = AutoTokenizer.from_pretrained(model_id)我们预训练的BERT模型包含许多可以冻结的层。审视这些层有助于深入了解网络结构,并明确哪些部分可能需要冻结:
# Print layer names
for name, param in model.named_parameters():
print(name)bert.embeddings.word_embeddings.weight
bert.embeddings.position_embeddings.weight
bert.embeddings.token_type_embeddings.weight
bert.embeddings.LayerNorm.weight
bert.embeddings.LayerNorm.bias
bert.encoder.layer.0.attention.self.query.weight
bert.encoder.layer.0.attention.self.query.bias
...
bert.encoder.layer.11.output.LayerNorm.weight
bert.encoder.layer.11.output.LayerNorm.bias
bert.pooler.dense.weight
bert.pooler.dense.bias
classifier.weight
classifier.bias
有12个(编号0至11)编码器块,每个包含注意力头、密集网络和层归一化模块。我们在图11-4中进一步详细说明了该架构,以展示所有可能被冻结的部分。此外,我们还添加了分类头模块。
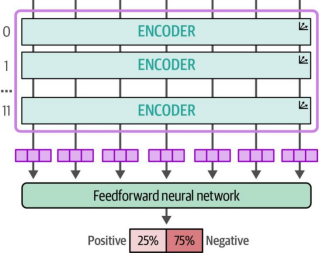
图11-4. 带有额外分类头的BERT基础架构
我们可以选择仅冻结某些层以加快计算速度,同时仍允许主模型从分类任务中学习。通常,我们希望被冻结的层后面跟着可训练层。
我们将像第2章中那样,冻结除分类头之外的所有部分。
for name, param in model.named_parameters():# Trainable classification headif name.startswith("classifier"):param.requires_grad = True# Freeze everything elseelse:param.requires_grad = False如图11-5所示,我们冻结了除前馈神经网络(即分类头)之外的所有组件。
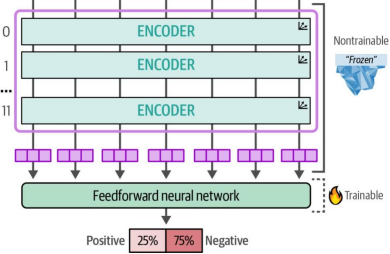
图11-5. 我们对所有编码器模块和嵌入层进行完全冻结,使得BERT模型在微调过程中不会学习新的表示
由于我们已成功冻结了除分类头之外的所有组件,现在可以开始训练模型了:
from transformers import TrainingArguments, Trainer# Trainer which executes the training process
trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_train,eval_dataset=tokenized_test,tokenizer=tokenizer,data_collator=data_collator,compute_metrics=compute_metrics,
)trainer.train()你可能会注意到训练速度变得快了很多。这是因为我们仅训练了分类头(classification head),与微调整个模型相比,这种做法为我们带来了显著的速度提升:
trainer.evaluate()
{'eval_loss': 0.6821751594543457,
'eval_f1': 0.6331058020477816,
'eval_runtime': 4.0175,
'eval_samples_per_second': 265.337,
'eval_steps_per_second': 16.677,
'epoch': 1.0}
在评估模型时,我们只得到了0.63的F1分数,明显低于原来的0.85分。与其冻结几乎所有层,不如尝试按照图11-6的示意,将编码器块10之前的所有层进行冻结,观察这对性能会产生什么影响。这样做的主要优势在于既能减少计算量,又能让更新信息继续通过预训练模型的部分结构传递:
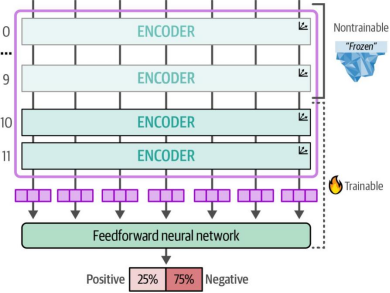
图11-6. 我们冻结了BERT模型的前10个编码器块。其余部分均可训练,并将进行微调
# Load modelmodel_id = "bert-base-cased"
model = AutoModelForSequenceClassification.from_pretrained(model_id, num_labels=2
)tokenizer = AutoTokenizer.from_pretrained(model_id)
# Encoder block 11 starts at index 165 and
# we freeze everything before that block
for index, (name, param) in enumerate(model.named_parameters()):if index < 165:param.requires_grad = False# Trainer which executes the training process
trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_train,eval_dataset=tokenized_test,tokenizer=tokenizer,data_collator=data_collator,compute_metrics=compute_metrics,
)trainer.train()训练结束后,我们评估结果:
trainer.evaluate()
{'eval_loss' : 0.40812647342681885,
'eval_f1' : 0.8,
'eval_runtime' : 3.7125,
'eval_samples_per_second' : 287.137,
'eval_steps_per_second' : 18.047,
'epoch' : 1.0}
我们的F1分数达到了0.8,这比之前冻结所有层时的0.63有了显著提升。这表明,尽管我们通常希望尽可能多地训练网络层,但在计算资源有限的情况下,适当减少训练层数仍然可以达到预期效果。
为了进一步验证这种效应,我们测试了分阶段冻结编码器块并进行微调的效果(如图11-7所示)。实验结果表明,仅训练前五个编码器块(红色垂直线标注位置)已能接近完全训练所有编码器块的性能水平。
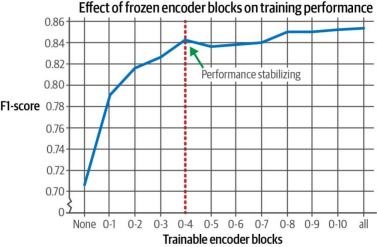
图11-7. 冻结特定编码器块对模型性能的影响。随着训练块数量的增加,模型性能有所提升,但该提升趋势在初期阶段即趋于稳定
在训练多个轮次(epoch)时,冻结(freeze)与不冻结模型在训练时间和资源消耗上的差异通常会变得更加显著。因此,建议你通过实践找到适合自身需求的平衡点。
少样本分类
少样本分类是监督分类中的一项技术,其特点是通过仅使用少量带标签的示例来训练分类器以学习目标标签。当面临分类任务但缺乏充足现成可用的标注数据时,这项技术尤为有效。换言之,该方法允许我们为每个类别标注少量高质量数据点用于模型训练(如图11-8所示)。这种通过少量标注数据训练模型的理念,充分体现了少样本分类的核心优势。
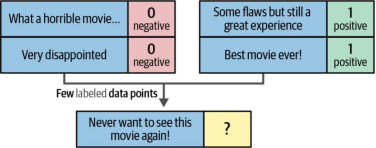
图 11-8. 在少样本分类中,我们仅使用少量词元数据点进行学习。
SetFit:仅需少量训练样本的高效微调框架
为了实现少样本文本分类,我们提出了一种名为 SetFit 的高效框架。该框架基于 sentence-transformers 的架构构建,能够生成高质量的文本表示,并在训练过程中动态更新这些表示。实验表明,仅需少量标注样本,SetFit 即可与基于大规模标注数据集微调类似 BERT 模型的方法相媲美(如前文案例所示)。
SetFit 的核心算法包含以下三个步骤:
1.训练数据采样
基于同类(in-class)和异类(out-class)标注数据的筛选,生成正(相似)、负(不相似)样本对。
2 Lewis Tunstall et al. “Efficient few-shot learning without prompts.” arXiv preprint arXiv:2209.11055 (2022).
2.微调嵌入
基于先前生成的训练数据对预训练的嵌入模型进行微调
3.训练分类器
在嵌入模型上方添加一个分类头(classification head),并使用先前生成的训练数据对其进行训练
在微调嵌入模型之前,我们需要生成训练数据。该模型要求训练数据是句子对的样本,包含正例(相似)和反例(不相似)两种类型。然而,当处理分类任务时,我们的输入数据通常并没有被这样标注。
例如,假设我们拥有图11-9所示的分类训练数据集,该数据集将文本分为两类:关于编程语言的文本和关于宠物的文本。
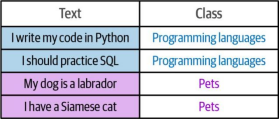
图11-9. 两类数据:编程语言相关文本与宠物相关文本
在步骤1中,SetFit通过基于同类别选样和跨类别选样的方式生成所需数据(如图11-10所示)。例如,当我们拥有16条关于体育的句子时,可以通过计算16 * (16 – 1) / 2 = 120生成词元为正样本对的配对。我们也可以通过收集不同类别之间的配对来生成负样本对。

图11-10 步骤1:采样训练数据。我们假设同一类别内的句子具有相似性并构建正样本对,而不同类别间的句子则构成负样本对
在第2步中,我们可以使用生成的句子对来微调嵌入模型。这种方法利用了名为对比学习的技术来微调预训练的BERT模型。如第10章所述,对比学习能够通过相似(正例)和不相似(反例)句子对的训练,学习到准确的句子嵌入表示。
由于这些句子对已在之前的步骤中生成,我们可以直接用于微调SentenceTransformers模型。虽然我们之前已讨论过对比学习方法,但为了便于回顾,在图11-11中再次展示了该方法的具体实现流程。
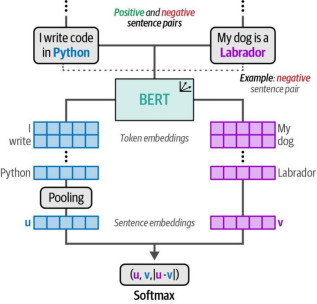
图11-11. 步骤2:微调SentenceTransformers模型。通过对比学习,模型从正负句子对中学习嵌入表示
微调此嵌入模型的目标是使其能够生成针对分类任务调整后的嵌入。通过微调嵌入模型,类别之间的相关性及其相对含义将被提炼并融入到生成的嵌入中。
在第三步中,我们为所有句子生成嵌入向量,并将其作为分类器的输入。我们可以使用微调后的SentenceTransformers模型将句子转换为可供特征使用的嵌入表示。分类器通过学习这些微调后的嵌入表示,能够准确预测未见过的句子。图11-12展示了这最后一步的实现过程。
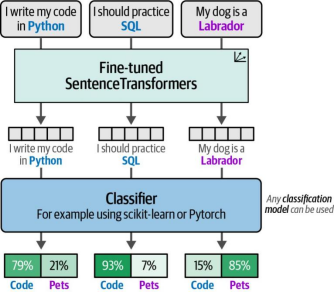
图11-12 步骤3:训练分类器。该分类器可以是任何scikit-learn模型或分类头。
将所有步骤整合后,我们得到了一套高效优雅的处理框架,可在每个类别仅有少量标注样本时完成文本分类任务。该方法巧妙运用了我们已标注数据的特点——尽管其形式与理想标注方式存在差异。图11-13通过三个步骤的示意图,全面概述了整个流程:
首先,基于同类样本和跨类样本选择策略生成句对;
其次,使用生成的句对对预训练的SentenceTransformer模型进行微调;
最后,通过微调后的模型对句子进行嵌入表征,并在其上训练分类器实现类别预测
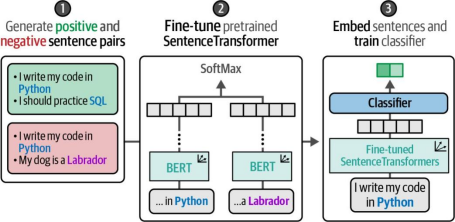
图11-13. SetFit的三个主要步骤
少样本分类的微调
我们之前训练时使用的数据集包含约8,500条电影评论。然而,在少样本设置下,我们将每个类别仅抽取16个样本。当只有两个类别时,相比之前使用的8,500条电影评论,我们现在仅有32个文档用于训练!
from setfit import sample_dataset# We simulate a few-shot setting by sampling 16 examples per class
sampled_train_data = sample_dataset(tomatoes["train"], num_samples=16)在完成数据采样后,我们选择一个预训练的SentenceTransformer模型进行微调。官方文档提供了预训练SentenceTransformer模型的概览,我们从中选用了"sentence-transformers/all-mpnet-base-v2"。该模型在MTEB(大规模多任务嵌入评估)排行榜上表现优异,该排行榜展示了嵌入模型在各类任务中的性能表现。
from setfit import SetFitModel# Load a pretrained SentenceTransformer model
model = SetFitModel.from_pretrained("sentence-transformers/all-mpnet-base-v2")在加载预训练的SentenceTransformer模型后,我们可以开始定义SetFitTrainer。默认情况下,系统会选择逻辑回归模型作为待训练的分类器。与我们在Hugging Face Transformers中的操作类似,可以通过训练器定义并调整相关参数。例如,我们将num_epochs设为3,这样对比学习将会进行三个轮次:
from setfit import TrainingArguments as SetFitTrainingArguments
from setfit import Trainer as SetFitTrainer# Define training arguments
args = SetFitTrainingArguments(num_epochs=3, # The number of epochs to use for contrastive learningnum_iterations=20 # The number of text pairs to generate
)args.eval_strategy = args.evaluation_strategy# Create trainer
trainer = SetFitTrainer(model=model,args=args,train_dataset=sampled_train_data,eval_dataset=test_data,metric="f1"
)我们只需调用train即可启动训练循环。此时应该会看到以下输出:
# Training loop
trainer.train()
***** Running training *****
Num unique pairs = 1280
Batch size = 16
Num epochs = 3
Total optimization steps = 240
请注意,输出内容中提到为微调SentenceTransformer模型生成了1,280个句子对。默认情况下,我们的每个样本会生成20组句子配对(即20×32=680组)。由于每个样本需要生成正向和反向两个方向的配对,因此需要将基数乘以2,即680×2=1,280个句子对。考虑到最初仅有32个标注句子作为起点,最终生成了1,280个句子对,这一成果真是了不起!
当我们没有明确指定分类头时,默认使用逻辑回归。如果希望自行指定分类头,可以通过在SetFitTrainer中配置以下模型实现:
# Load a SetFit model from Hub
model = SetFitModel.from_pretrained(
"sentence-transformers/all-mpnet-base-v2", use_differentiable_head=TΓue,
head_params={"out_features": num_classes},
)
# Create trainer
trainer = SetFitTrainer(
model=model,
...
)
此处,num_classes 表示需要预测的类别数量.
接下来,我们评估模型以了解其性能表现:
# Evaluate the model on our test data
trainer.evaluate()
{'f1': 0.8363988383349468}
仅凭32份标注文档,我们就获得了0.85的F1分数。考虑到该模型是在原始数据的极小子集上训练的,这一表现已经非常出色!此外,在第二章中,我们通过在全数据的嵌入表示上训练逻辑回归模型,取得了相同的性能。因此,这一流程展示了花费时间标注少量实例的潜力。
SetFit不仅可以执行少样本分类任务,还支持在完全没有标签的情况下使用(即零样本分类)。SetFit会从标签名称生成合成示例以模拟分类任务,然后用这些合成示例训练SetFit模型。例如,如果目标标签是"happy(开心)"和"sad(悲伤)",则生成的合成数据可能是"这个示例是开心的"和"这个示例是悲伤的"。
基于掩码语言模型的持续预训练
在之前的示例中,我们使用了预训练模型并对其进行微调以执行分类任务。这一过程包含两个步骤:首先进行模型的预训练(这一步已由我们完成),随后针对特定任务进行微调。我们通过图11-14展示了该过程的示意图。
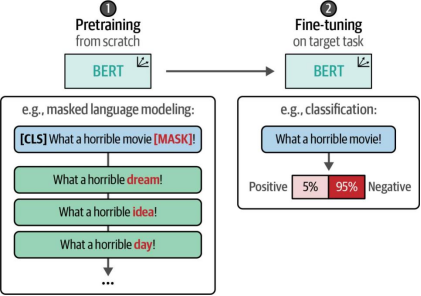
图11-14. 要在目标任务(例如分类任务)上微调模型,我们可以选择从头开始预训练BERT模型,或者使用已有的预训练模型
这种两步法广泛应用于众多场景。但当面对特定领域数据时存在局限性——预训练模型通常基于维基百科等通用数据进行训练,可能无法适配您特定领域的词汇。
与其采用这种两步法,我们可以在中间增加一个环节:对已预训练的BERT模型进行继续预训练(continued pretraining)。换言之,我们可以继续使用掩码语言建模(MLM)任务训练BERT模型,只不过改用领域内数据。这类似于从通用BERT模型到专注医疗领域的BioBERT模型,再到针对药物分类任务微调的BioBERT模型的演进过程。
这将更新子词表示,使其更适应模型之前未见过的词汇。如图11-15所示,这一过程展示了额外步骤如何更新掩码语言建模任务。在预训练的BERT模型上继续进行预训练已被证实能够提升模型在分类任务中的性能,这是微调流程中值得加入的关键步骤3。
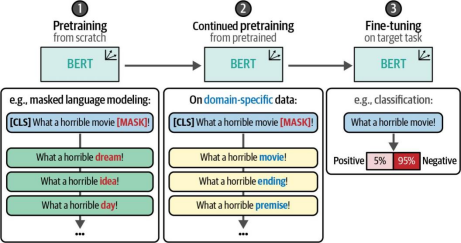
图11-15 与采用两步法不同,我们可以增加一个额外步骤——在目标任务的微调之前继续对预训练模型进行预训练。请注意,在图1中掩码被填充了抽象概念,而在图2中则填充了电影特定概念。
无需从头开始训练整个模型,我们可以直接在预训练基础上继续训练,随后再针对分类任务进行微调。这种方法还能帮助模型更好地适应特定领域,甚至掌握某个组织的内部术语。企业可能采用的模型传承关系如图11-16所示。
3 Chi Sun et al. “How to fine–tune GERT for text classification?” Chinese Computational Linguistics: 18th China National Conference, CCL 2019, Kunming, China, October 18-20, 2019, proceedings 18. Springer International Publishing, 2019.
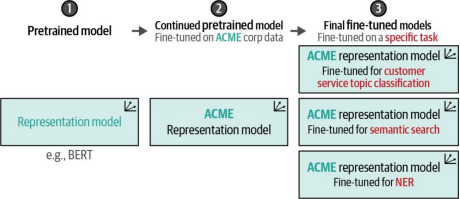
在本示例中,我们将演示如何应用第二步并继续预训练已经过预训练的BERT模型。我们使用最初启用的相同数据集,即Rotten Tomatoes影评数据。
首先加载我们迄今为止使用的"bert-base-cased"模型,并对其进行MLM(掩码语言建模)任务的准备:
from transformers import AutoTokenizer, AutoModelForMaskedLM# Load model for masked language modeling (MLM)
model = AutoModelForMaskedLM.from_pretrained("bert-base-cased")
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")我们需要对原始句子进行分词。由于这不是一个监督任务,我们还将移除标签:
def preprocess_function(examples):return tokenizer(examples["text"], truncation=True)# Tokenize data
tokenized_train = train_data.map(preprocess_function, batched=True)
tokenized_train = tokenized_train.remove_columns("label")
tokenized_test = test_data.map(preprocess_function, batched=True)
tokenized_test = tokenized_test.remove_columns("label")之前,我们使用的是DataCollatorWithPadding,它会动态填充接收到的输入。
现在我们将改用另一种数据整理器,由它来为我们执行词元的掩码处理。通常有两种实现方式:词元掩码(token masking)和全词掩码(whole-word masking)。在词元掩码方法中,我们会随机掩码句子中15%的词元,这可能会导致单词的部分字符被掩码。如图11-17所示,若要实现整个单词的掩码,我们可以采用全词掩码方法。
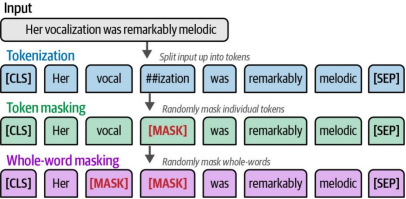
通常来说,预测整个单词比预测词元(tokens)更为复杂,这会使模型在训练过程中需要学习更准确、更精确的表征,从而表现更佳。然而,这种方式往往需要更多时间才能收敛。在本示例中,我们使用DataCollatorForLanguageModeling采用词元掩码(token masking)以实现更快的收敛速度。不过,通过将DataCollatorForLanguageModeling替换为DataCollatorForWholeWordMask,我们可以改用全词掩码(whole-word masking)。最后,我们将给定句子中被掩码词元的概率设置为15%(对应参数mlm_probability)。
from transformers import DataCollatorForLanguageModeling# Masking Tokens
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer,mlm=True,mlm_probability=0.15
)接下来,我们将创建用于运行MLM任务的Trainer,并指定某些参数:
# Training arguments for parameter tuning
training_args = TrainingArguments("model",learning_rate=2e-5,per_device_train_batch_size=16,per_device_eval_batch_size=16,num_train_epochs=10,weight_decay=0.01,save_strategy="epoch",report_to="none"
)# Initialize Trainer
trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_train,eval_dataset=tokenized_test,tokenizer=tokenizer,data_collator=data_collator
)有几个参数值得注意。我们训练20个轮次,并保持任务周期简短。你可以尝试调整学习率和权重衰减,以确定它们是否有助于模型的微调。在开始训练循环之前,我们首先要保存预训练的分词器。由于分词器在训练过程中不会更新,因此无需在训练后保存。不过,在继续预训练后,我们将保存模型:
# Save pre-trained tokenizer
tokenizer.save_pretrained("mlm")
# Train model
trainer.train()
# Save updated model
model.save_pretrained("mlm")这为我们提供了mlm文件夹中的一个更新后的模型。为了评估其性能,我们通常需要在多种任务上对模型进行微调。不过出于我们的目的,可以通过运行一些掩码任务来测试模型是否通过持续训练学习了新知识。具体方法是在继续预训练之前加载我们的预训练模型。使用句子"What a horrible [MASK]!",模型将预测[MASK]位置应该出现的单词:
from transformers import pipeline# Load and create predictions
mask_filler = pipeline("fill-mask", model="bert-base-cased")
preds = mask_filler("What a horrible [MASK]!")
# Print results
for pred in preds:print(f">>> {pred["sequence"]}")>>> What a horrible idea!
>>> What a horrible dream!
>>> What a horrible thing!
>>> What a horrible day!
>>> What a horrible thought!
输出结果展示了诸如“想法”、“梦想”和“天”这样的概念,这些显然是有意义的。接下来,让我们看看更新后的模型会预测出什么:
# Load and create predictionsmask_filler = pipeline("fill-mask", model="mlm")
preds = mask_filler("What a horrible [MASK]!")
# Print results
for pred in preds:print(f">>> {pred["sequence"]}")>>> What a horrible movie!
>>> What a horrible film!
>>> What a horrible mess!
>>> What a horrible comedy!
>>> What a horrible story!
一部糟糕透顶的电影、影片、混乱局面等,都清楚地表明相较于预训练模型,当前模型对我们输入的数据存在更严重的偏向性。
下一步应当是在本章开头进行的分类任务上对这个模型进行微调。只需按如下方式加载模型即可开始使用:
from transformers import AutoModelForSequenceClassification# Fine-tune for classification
model = AutoModelForSequenceClassification.from_pretrained("mlm", num_labels=2)
tokenizer = AutoTokenizer.from_pretrained("mlm")命名实体识别
在本节中,我们将深入探讨针对命名实体识别(NER)任务微调预训练BERT模型的具体过程。与文档级分类不同,该方法能够对单个词元(token)或词语进行细粒度分类,涵盖人物、地点等实体类别。这种特性在涉及敏感数据的去标识化与匿名化任务中尤为重要。
虽然NER与本章开头讨论的文档分类任务具有相似性,但两者在数据预处理和分类逻辑上存在显著差异。由于本任务关注词语级别的实体识别而非文档整体分析,我们需要对原始数据进行特殊处理以适配这种细粒度的建模需求。图11-18直观展示了该模型在词语级别进行实体识别的工作原理.
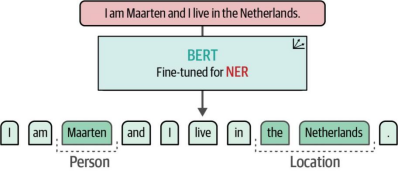
图11-18. 对BERT模型进行微调以用于命名实体识别(NER),可实现人物或地点等命名实体的检测。
对预训练BERT模型进行微调时采用的架构与我们在文档分类中所观察到的架构相似。然而,其分类方法存在根本性转变——该模型不再依赖词元嵌入的聚合或池化操作,转而直接对序列中的每个词元进行独立预测。需要特别说明的是,我们的词级分类任务并非对完整词语进行分类,而是针对共同构成这些词语的基础词元进行细粒度分类。图11-19直观展示了这种词元级别的分类机制。
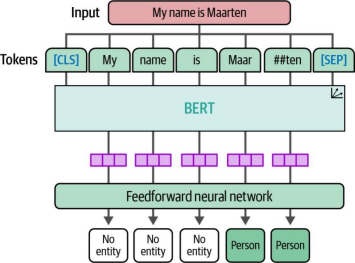
图11-19. 在BERT模型的微调过程中,系统会对单个词元(token)进行分类,而非对单词或整个文档进行分类
为命名实体识别准备数据
在本示例中,我们将使用英文版的CoNLL-2003数据集。该数据集包含多种类型的命名实体(人物、组织、地点、杂项以及无实体标注),共有约14,000个训练样本[4]。
# The CoNLL-2003 dataset for NER
dataset = load_dataset("conll2003", trust_remote_code=TΓue)在为本文寻找可用数据集时,我们还发现了另外几个值得分享的优质资源。WNUT_17数据集专注于识别新兴实体和罕见实体,这类实体往往更难以被有效检测。此外,tner/mit_movie_trivia和tner/mit_restaurant这两个数据集极具趣味性:前者用于检测演员、情节、原声音乐等电影相关实体,后者则专注于识别设施、菜肴、菜系等餐饮类实体5。
让我们通过一个例子来检查数据的结构:
example = dataset["train"][848]
{'id': '848',
'tokens': ['Dean',
'Palmer',
'hit',
'his',
'30th',
'homer',
'for',
'the',
'Rangers',
' .'],
'pos_tags': [22, 22, 38, 29, 16, 21, 15, 12, 23, 7],
'chunk_tags': [11, 12, 21, 11, 12, 12, 13, 11, 12, 0],
'ner_tags': [1, 2, 0, 0, 0, 0, 0, 0, 3, 0]}
该数据集为句子中的每个单词提供了标签。这些标签可在ner_tags键下找到,其对应以下可能的实体类型:
4 Erik F. Sang and Fien De Meulder. “Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition.” arXiv preprint cs/0306050 (2003).
5 Jingjing Liu et al. “Asgard: A portable architecture for multilingual dialogue systems.” 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, 2013.
label2id = {"O": 0, "B-PER": 1, "I-PER": 2, "B-ORG": 3, "I-ORG": 4,"B-LOC": 5, "I-LOC": 6, "B-MISC": 7, "I-MISC": 8
}
id2label = {index: label for label, index in label2id.items()}{'O': 0,
'B-PER': 1,
'I-PER': 2,
'B-ORG': 3,
'I-ORG': 4,
'B-LOC': 5,
'I-LOC': 6,
'B-MISC': 7,
'I-MISC': 8}
这些实体对应于特定类别:人物(PER)、组织(ORG)、地点(LOC)、杂项实体(MISC)和非实体(O)。需注意,这些实体词元前会添加前缀符号:B(表示短语起始)或 I(表示短语内部)。若两个连续词元属于同一短语,则该短语起始词元使用 B,后续词元使用 I 表明它们同属一个整体而非独立实体。
图11-20进一步阐释了此规则。如图所示,由于"Dean"是短语起始词元,"Palmer"是结束词元,因此"Dean Palmer"整体被识别为人物实体,而单独的"Dean"和"Palmer"并不构成独立的人物实体。
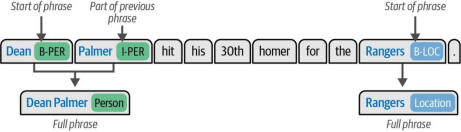
图11-20 通过用同一实体标示短语的起始和结束位置,我们可以识别整个短语中的实体
我们的数据已经过预处理并拆分为单词,但尚未转换为词元。为此,我们将使用本章贯穿始终的预训练模型(即bert-base-cased)的分词器对其进行进一步分词处理:
from transformers import AutoModelForTokenClassification# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")# Load model
model = AutoModelForTokenClassification.from_pretrained("bert-base-cased",num_labels=len(id2label),id2label=id2label,label2id=label2id
)让我们来看一下分词器将如何处理我们的示例:
# Split individual tokens into sub-tokens
token_ids = tokenizer(example["tokens"], is_split_into_words=True)["input_ids"]
sub_tokens = tokenizer.convert_ids_to_tokens(token_ids)['[CLS]',
'Dean',
'Palmer', 'hit',
'his',
'30th',
'home',
'##r',
'for',
'the',
'Rangers', ' '
. ,
'[SEP]']
正如我们在第2章和第3章所学,分词器会添加[CLS]和[SEP]词元。需要注意的是,单词"homer"被进一步拆分为"home"和"##r"两个子词。由于我们拥有的是词级别的标注数据而非子词级别的标注数据,这给我们带来了一些挑战。这个问题可以通过在分词过程中将标签与其对应的子词进行对齐来解决。
以标注为B-PER(表示人物)的单词"Maarten"为例,当通过分词器处理时,该词会被拆分为"Ma"、"##arte"和"##n"三个子词。我们不能简单地将B-PER实体应用于所有子词,因为这会错误地表示这三个子词代表三个独立的人物。当实体被拆分为多个子词时,第一个子词应使用B(表示起始)标签,后续子词应使用I(表示内部)标签。
因此,"Ma"将被词元为B-PER表示短语的开始,而"##arte"和"##n"则使用I-PER标签表明它们属于同一个短语。这种对齐过程如图11-21所示
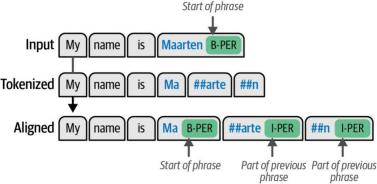
图11-21. 分词输入的标签对齐过程
我们创建了一个名为align_labels的函数,该函数将对输入进行分词,并在分词过程中将这些词元与其更新后的标签进行对齐:
def align_labels(examples):token_ids = tokenizer(examples["tokens"],truncation=True,is_split_into_words=True)labels = examples["ner_tags"]updated_labels = []for index, label in enumerate(labels):# Map tokens to their respective wordword_ids = token_ids.word_ids(batch_index=index)previous_word_idx = Nonelabel_ids = []for word_idx in word_ids:# The start of a new wordif word_idx != previous_word_idx:previous_word_idx = word_idxupdated_label = -100 if word_idx is None else label[word_idx]label_ids.append(updated_label)# Special token is -100elif word_idx is Nonelabel_ids.append(-100)# If the label is B-XXX we change it to I-XXXelse:updated_label = label[word_idx]if updated_label % 2 == 1:updated_label += 1label_ids.append(updated_label)updated_labels.append(label_ids)token_ids["labels"] = updated_labelsreturn token_idstokenized = dataset.map(align_labels, batched=True)在我们的示例中,请注意,额外的标签(-100)已被添加到[CLS]和[SEP]词元中:
# Difference between original and updated labels
print(f"Original: {example["ner_tags"]}")
print(f"Updated: {tokenized["train"][848]["labels"]}")Original: [1, 2, 0, 0, 0, 0, 0, 0, 3, 0]
Updated: [-100, 1, 2, 0, 0, 0, 0, 0, 0, 0, 3, 0, -100]
现在我们已经完成了分词和标签对齐工作,就可以开始着手定义评估指标了。这与我们之前处理单个文档单一预测的评估方式不同,现在每个文档会生成多个针对每个词元的预测结果。我们将使用Hugging Face的evaluate工具包来构建compute_metrics函数,该函数能够实现基于词元级别的性能评估:
import evaluate# Load sequential evaluation
seqeval = evaluate.load("seqeval")def compute_metrics(eval_pred):# Create predictionslogits, labels = eval_predpredictions = np.argmax(logits, axis=2)true_predictions = []true_labels = []# Document-level iterationfor prediction, label in zip(predictions, labels):# Token-level iterationfor token_prediction, token_label in zip(prediction, label):# We ignore special tokensif token_label != -100:true_predictions.append([id2label[token_prediction]])true_labels.append([id2label[token_label]])results = seqeval.compute(predictions=true_predictions, references=true_labels)return {"f1": results["overall_f1"]}命名实体识别的微调
我们即将完成配置。现在需要替换原来的DataCollatorWithPadding,改用适用于token级别分类的数据整理器,即DataCollatorForTokenClassification:
from transformers import DataCollatorForTokenClassification# Token-classification DataCollator
data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)至此我们已经完成模型加载,后续步骤与本章前面介绍的训练流程类似。我们将定义一个具有可调参数的训练器,并创建Trainer实例:
我们随后对所创建的模型进行评估:
# Evaluate the model on our test data
trainer.evaluate()
最后,让我们保存模型并将其集成到推理流水线中。这样我们可以审查特定数据,手动检查推理过程的具体行为,并验证输出结果是否符合预期:
# Training arguments for parameter tuning
training_args = TrainingArguments("model",learning_rate=2e-5,per_device_train_batch_size=16,per_device_eval_batch_size=16,num_train_epochs=1,weight_decay=0.01,save_strategy="epoch",report_to="none"
)# Initialize Trainer
trainer = Trainer(model=model,args=training_args,train_dataset=tokenized["train"],eval_dataset=tokenized["test"],tokenizer=tokenizer,data_collator=data_collator,compute_metrics=compute_metrics,
)trainer.train()我们随后对所创建的模型进行评估:
# Evaluate the model on our test datatrainer.evaluate()最后,让我们保存模型并将其集成到推理流水线中。这样我们可以审查特定数据,手动检查推理过程的具体行为,并验证输出结果是否符合预期:
from transformers import pipeline
# Save our fine-tuned model
trainer.save_model("ner_model")
# Run inference on the fine-tuned model
token_classifier = pipeline("token-classification",model="ner_model",
)token_classifier("My name is Maarten.")[{'entity': 'B-PER',
'score': 0.99534035,
'index': 4,
'word': 'Ma',
'start': 11,
'end': 13},
{'entity': 'I-PER',
'score': 0.9928328,
'index': 5,
'word': '##arte',
'start': 13,
'end': 17},
{'entity': 'I-PER',
'score': 0.9954301,
'index': 6,
'word': '##n',
'start': 17,
'end': 18}]
在句子"My name is Maarten"中,单词"Maarten"及其子词被正确识别为人名!
本章小结
在本章中,我们探讨了针对特定分类任务微调预训练表示模型的多项任务。我们首先演示了如何微调预训练的BERT模型,并通过冻结其架构中的某些层扩展了示例。
我们尝试了一种名为SetFit的少样本分类技术,该技术通过使用少量标注数据对预训练嵌入模型及其分类头进行联合微调。仅使用少量标注数据点,该模型的性能与我们在前几章探讨的模型相当。
随后,我们深入研究了继续预训练(continued pretraining)的概念,即以预训练的BERT模型为起点,使用不同数据进行持续训练。其底层机制——掩码语言建模——不仅用于创建表示模型,还可用于模型的继续预训练。
最后,我们研究了命名实体识别任务,该任务涉及从非结构化文本中识别特定实体(如人名和地名)。与先前示例相比,此类分类是在词级别(而非文档级别)上完成的。
在下一章中,我们将继续探索语言模型微调领域,但将聚焦于生成式模型。通过两步流程,我们将研究如何微调生成式模型以正确遵循指令,进而优化其符合人类偏好的表现。