Video-LLaVA
一、研究背景与现有方法局限性
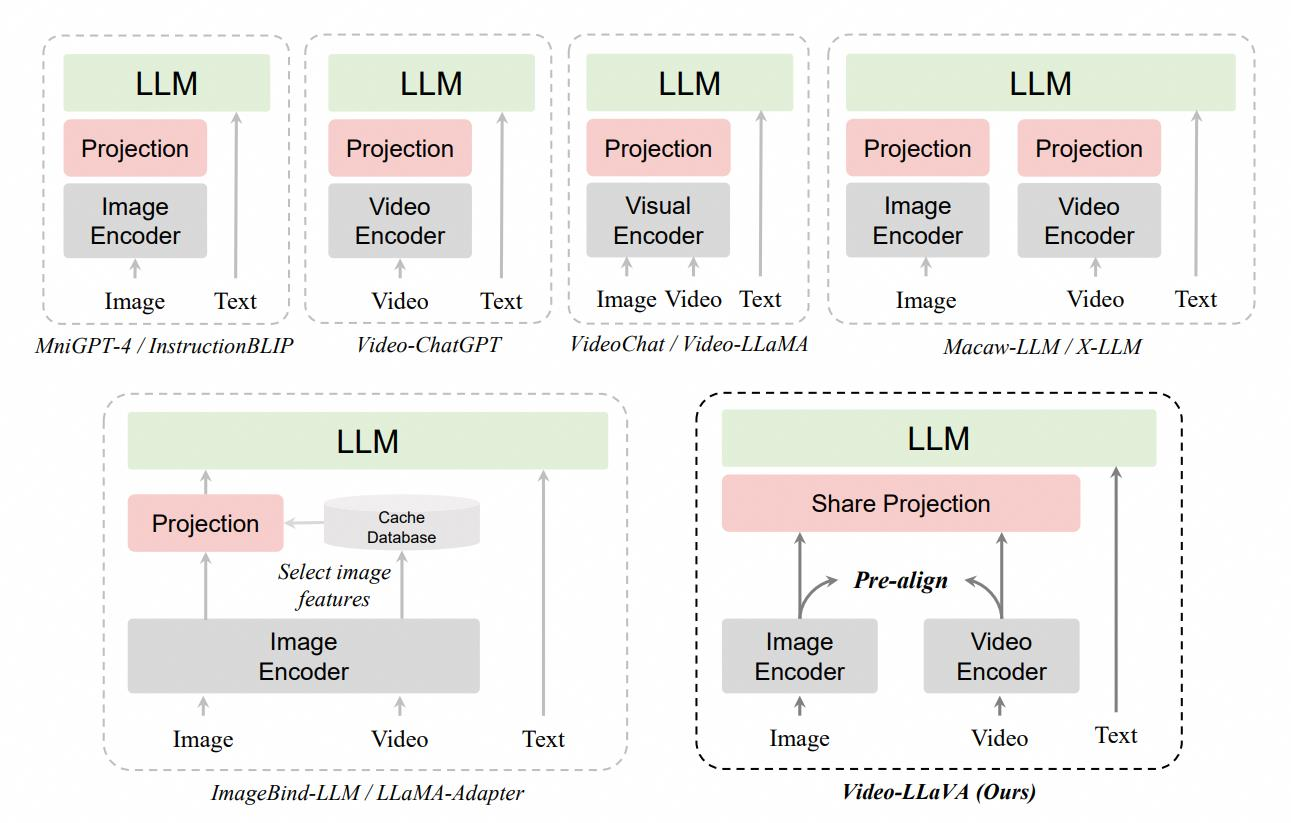
在多模态大语言模型(LVLMs)的发展中,现有方法面临两大核心挑战。其一为单一模态处理的局限,多数 LVLMs 仅能处理图像 - 语言或视频 - 语言等单一视觉模态,难以在统一框架下高效整合多种视觉输入。其二为统一表示的困难,尽管部分研究尝试通过共享视觉编码器处理图像和视频,但其性能远不及专门针对视频设计的模型,如 VideoChatGPT,反映出跨模态语义对齐的复杂性。
二、解决思路与创新点
针对上述问题,研究提出了 Video-LLaVA 的核心解决方案:在投影前对齐图像和视频的表示,通过共享投影层将统一的视觉表示映射至大语言模型(LLM),并采用联合训练策略优化跨模态交互。相较于 X-LLM/Macaw-LLM 为不同模态分配独立编码器、ImageBind-LLM 通过预对齐间接映射特征的方式,Video-LLaVA 通过直接对齐图像与视频的底层语义,避免了间接对齐导致的性能损失,实现了跨模态表示的深度融合。