[感知机]:基于感知机模型的二分类问题训练与预测实现(C语言版)
![[LOGO]:CoreKSets](https://i-blog.csdnimg.cn/direct/731088657ae348d4a1f679ad3008534a.png)
【核知坊】:释放青春想象,码动全新视野。
我们希望使用精简的信息传达知识的骨架,启发创造者开启创造之路!!!
内容摘要: 已知一组[(x1,y1),(x2,y2), ....]标注好的数据集,需要在预测之前提前训练模型,获取权重,然后进行预测。本文介绍了感知机模型在二分类问题中的应用,通过一组标注好的数据集进行模型训练,并获取相应的权重值。文章重点展示了感知机模型的基本原理,并使用 C 语言实现了训练和预测过程。通过对训练数据的处理和权重的更新,模型能够对新的输入数据进行有效的预测,从而实现数据的分类。
关键词:感知机 C语言 训练 预测
其他相关文章:
⛏赶制中。。。
1.感知机
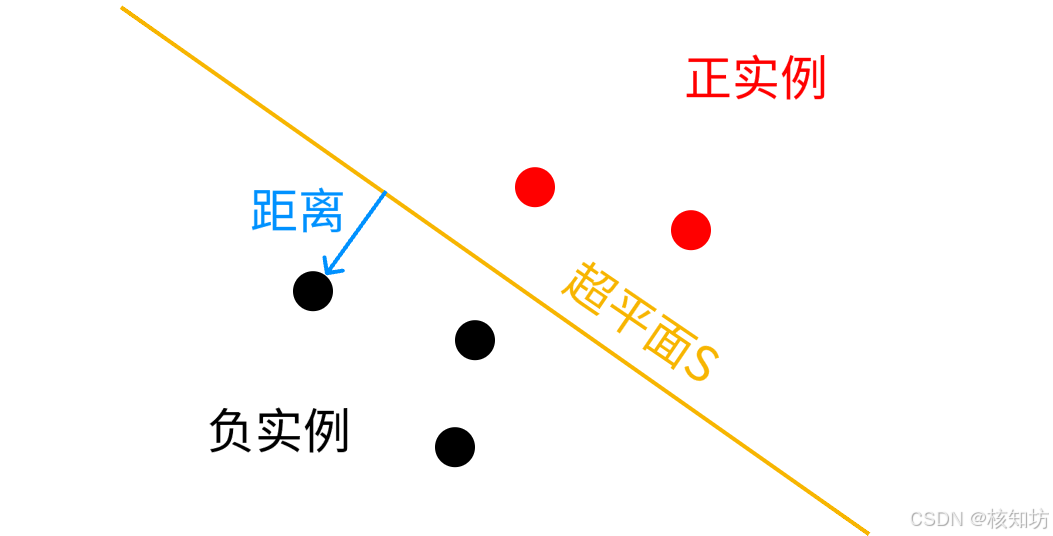
1.1 什么是感知机?
通过训练(循环测试)找到合适的权重,让函数模型趋于正确分类。
感知机是统计学习中的一种基础算法,主要用于二类分类问题。其主要思想是迭代寻找参数 使损失函数
最小。它的目标是找到一个能够将训练数据进行线性划分的分离超平面
, 所谓超平面
是指
两侧的点分别称为正实例点和负实例点。感知机模型由输入空间到输出空间的函数表示,具体为:
其中,x 是实例的特征向量,w 是权值向量(与 x 同维度),b 是偏置, 是符号函数,具体定义为:
因此f(x) 的值就是 -1 或 +1 , 正例和负例判别式
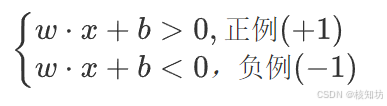
1.2感知机的损失函数是什么?
感知机选用误分类点 到超平面
的总距离作为度量预测错误的程度,如果距离越近则有可能被正确分类。那么距离怎算呢?你想到点到直线距离公式了吗?我们要算的不就是
到
的距离吗?于是有了 :
叫做
的
范数
什么是范数,范数是一种机器学习里的专业用语。看公式:
就是向量 w 里的元素)
(了解: 范数:
除了距离公式,我们还可以发现一个事实:
为什么呢?因为当误分类后的 y 就反过来了, 那么

于是误分类点到分离超平面的总距离具体形式为:
其中,M 是误分类点的集合, 是实例
的真实类别。由于
是常数(在
的范数不为零时),通常忽略它节省计算资源,直接优化:
, 该式就叫损失函数。
1.3求解
如何 呢?也就是如何找到最佳
?
1.3.1原始形式
感知机学习算法的原始形式采用梯度下降法极小化损失函数。具体算法如下:
输入:训练集 学习率或步长。
输出: 感知机模型:
-
选取
的初值。(选取 0)
-
在训练集T中选取数据
-
如果
,则更新
:
-
重复步骤 2 和 3,直至训练集中没有误分类点
1.3.2对偶形式
感知机学习算法的对偶形式将 w 和 b 表示为实例 x_i 和标记 y_i 的线性组合。具体算法如下:
输入:训练集 学习率或步长。输出:
, 感知机模型:
表示点
被误分类的次数
-
初始化
-
在训练集中选取数据
-
如果
,则更新
:
其中,N 是训练集的大小。
-
重复步骤 2 和 3,直至训练集中没有误分类点
在对偶形式中,通常还会计算 Gram 矩阵以优化内积的计算。
2. 数据集准备
下列模拟了一组数据集,当CH1_X_List 里的数字大于189.5判为正例1,反之为0 。
为了方便处理,数据格式分为了两个数组,CH1_X_List为输入(样本),CH1_Y_List为输出(标签)。
float CH1_X_List[TrainDataSize] = {105, 110, 115, 120, 125, 130, 135, 140, 145, 150,155, 160, 165, 170, 175, 180, 185, 188, 189, 189.5,190, 192, 195, 198, 200, 205, 210, 215, 220, 225,230, 235, 238, 240, 242, 245, 246, 248, 249, 250};int CH1_Y_List[TrainDataSize] = {0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0,1, 1, 1, 1, 1, 1, 1, 1, 1, 1,1, 1, 1, 1, 1, 1, 1, 1, 1, 1};3.训练
3.1 激活函数(决策)
3.1.1 hardlim激活函数
hardlim是 硬限幅激活函数,它在感知机模型中常被用作决策函数,能够将输入的信号进行简单的二分类处理。其作用是将输入信号与某个阈值进行比较,输出二值化的结果。这个激活函数的特点是计算简单且效率高,常用于早期的神经网络模型,如感知机和一些早期的神经网络应用。
📐 数学公式
🔍 特点:输出范围:0,1
-
当输入
x大于或等于零时,输出1; -
当输入
x小于零时,输出0。
3.1.2Sigmoid 激活函数(Logistic Function)
📐 数学公式:
🔍 特点:输出范围:(0, 1)
-
常用于二分类问题**,尤其是在输出层。
-
平滑可微,并且梯度容易计算。
-
在深度网络中可能会出现 梯度消失问题,特别是在深层网络中,导致学习变慢。
3.1.3 ReLU(Rectified Linear Unit)
📐 数学公式:
🔍 特点:
-
输出范围:
[0, +∞) -
计算效率高,非常适合于深度学习模型。
-
避免梯度消失问题,对大多数任务有较好效果。
-
可能导致 "死神经元"(Dead Neurons) 问题,即某些神经元在训练过程中永远输出 0,导致无法更新。
3.1.4 Tanh(双曲正切函数)
📐 数学公式:
🔍 特点:
-
输出范围:
(-1, 1) -
是 Sigmoid 函数 的扩展,输出范围是
(-1, 1),适用于需要负值的情况。 -
比 Sigmoid 更加平衡,但依然会存在梯度消失问题,尤其是在值较大或较小的输入时。
3.1.4 Leaky ReLU
📐 数学公式:
🔍 特点:
-
输出范围:
(-∞, +∞) -
与 ReLU 相似,但在
x < 0时输出一个 小的负数(由参数α控制)。 -
解决了 ReLU 中的 死神经元问题,但可能会导致梯度爆炸。
3.1.5 Softmax 激活函数
📐 数学公式:
🔍 特点:
-
输出范围:
(0, 1),并且所有输出之和为 1。 -
常用于 多分类问题的输出层,表示每个类别的概率。
-
归一化输出,使得所有输出值加起来等于 1,因此常用于分类问题。
3.1.6 感知机公式
y=hardlim(x⋅w+b)
x: 灰度值;w: 权重;b: 偏置;y: 预测值(0或1)
3.1.7 训练函数
激活函数如下:
// hardlim 激活函数int hardlim(float x){return (x >= 0) ? 1 : 0;}训练之前,最好将原始数据进行归一化处理,防止梯度爆炸,训练的模型效果差。我建议:如果你的原始数据在[N, W]之间,请使用将原始数据除以 abs(W) 进行缩放归一化。训练时的学习率Lr设置为0.05,请根据你的训练测试结果进行调整。训练轮次epoch可以自行配置,一般50轮以上。
下列MPL_train_perceptron函数主要工作:初始化权重,进行epoch次训练,每次训练将提取每个样本x[i]进行归一化,然后投入y = hardlim(w*x + b),根据真实值与预测值的误差决定是否更新权重mpl_data(w,b)。
// y = hardlim(w*x + b)// 感知机训练函数MPL_Data MPL_train_perceptron(float* x, int* y, int data_size, int epoch){// 初始化 w = 0 ; b = 0;MPL_Data mpl_data = {0, 0};for (int e = 0; e < epoch; e++) {//预测错误次数int error_count = 0;// 取出每个数据进行预测for (int i = 0; i < data_size; i++) {// 预测float x_norm = x[i] / DataMaxNum;float net = mpl_data.w * x_norm + mpl_data.b;int y_pred = hardlim(net);// 误差:预测值与真实值的差距int error = y[i] - y_pred;// 有误差说明权重需要调整if (error != 0) {mpl_data.w += Lr * error * x_norm;mpl_data.b += Lr * error;printf("训练参数:w=%1f, b=%1f \n", mpl_data.w, mpl_data.b);error_count++;}}// 如果本轮完全分类正确,说明已经训练完毕,可提前结束if (error_count == 0){break;} }// 返回训练好的权重信息return mpl_data;}3.1.8 训练
下列函数是为了照顾一些有多组数据的同学,如果嫌麻烦可以直接使用MPL_train_perceptron进行训练。
// 根据手动获取的标注数据进行训练void MPL_Train(int epoch, MPL_Data* out_models){out_models[0] = MPL_train_perceptron(CH1_X_List, CH1_Y_List,TrainDataSize, epoch);}训练 200 轮次,并将权重信息存储到 models 中,由于我们只测试一组数据,所以使用models[0] 进行之后的预测。
static MPL_Data models[1];MPL_Train(200, models);printf("y = hardlim(%.4f*x + %.4f)\n", models[0].w, models[0].b);3.1.9 预测
训练后的模型可以获得 models[0].w, models[0].b,本示例获取的训练参数:w=0.342500, b=-0.650000,等价于
y = hardlim(0.3425*x + -0.6500)
预测函数:预测之前的样本需要归一化
// 预测函数,就是已知x,通过y = hardlim(w*x + b)解yint MPL_predict(float x, MPL_Data mpl_data){ float x_norm = x / DataMaxNum;int y = hardlim(mpl_data.w*x_norm + mpl_data.b);return y;}预测函数使用:
Y = MPL_predict(X, models[0]);printf("X = %.1f => Y = %d\n", X, Y);文章总结
本文详细介绍了感知机原理,并使用C语言实现了一个简单的二分类感知机。经过测试,训练好的模型有良好的分类效果。
感谢阅览,如果你喜欢该内容的话,可以点赞,收藏,转发。由于 Koro 能力有限,有任何问题请在评论区内提出,Koro 看到后第一时间回复您!!!
其他精彩内容:
参考内容:
附录(源码)
// main.c#include <stdlib.h>#include "mpl.h"#include <windows.h>static MPL_Data models[1];int main(){MPL_Train(200, models);printf("y = hardlim(%.4f*x + %.4f)\n", models[0].w, models[0].b);float X;int Y;while (1){X = 100 + (rand() % 151);Y = MPL_predict(X, models[0]);printf("X = %.1f => Y = %d\n", X, Y);Sleep(1000); // 延时 1000 毫秒,即 1 秒}return 0;}
// mpl.c#include "mpl.h"// 记录的数据,TrainDataSize = 40个数据长度,// 示例:用于 CH1 通道训练的 X 和 Y 数据float CH1_X_List[TrainDataSize] = {105, 110, 115, 120, 125, 130, 135, 140, 145, 150,155, 160, 165, 170, 175, 180, 185, 188, 189, 189.5,190, 192, 195, 198, 200, 205, 210, 215, 220, 225,230, 235, 238, 240, 242, 245, 246, 248, 249, 250};int CH1_Y_List[TrainDataSize] = {0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0,1, 1, 1, 1, 1, 1, 1, 1, 1, 1,1, 1, 1, 1, 1, 1, 1, 1, 1, 1};// hardlim 激活函数int hardlim(float x){return (x >= 0) ? 1 : 0;}// y = hardlim(w*x + b)// 感知机训练函数MPL_Data MPL_train_perceptron(float* x, int* y, int data_size, int epoch){// 初始化 w = 0 ; b = 0;MPL_Data mpl_data = {0, 0};for (int e = 0; e < epoch; e++) {//预测错误次数int error_count = 0;// 取出每个数据进行预测for (int i = 0; i < data_size; i++) {// 预测float x_norm = x[i] / DataMaxNum;float net = mpl_data.w * x_norm + mpl_data.b;int y_pred = hardlim(net);// 误差:预测值与真实值的差距int error = y[i] - y_pred;// 有误差说明权重需要调整if (error != 0) {mpl_data.w += Lr * error * x_norm;mpl_data.b += Lr * error;printf("训练参数:w=%1f, b=%1f \n", mpl_data.w, mpl_data.b);error_count++;}}// 如果本轮完全分类正确,说明已经训练完毕,可提前结束if (error_count == 0){break;} }// 返回训练好的权重信息return mpl_data;}// 预测函数,就是已知x,通过y = hardlim(w*x + b)解yint MPL_predict(float x, MPL_Data mpl_data){ float x_norm = x / DataMaxNum;int y = hardlim(mpl_data.w*x_norm + mpl_data.b);return y;}// 根据手动获取的标注数据进行训练void MPL_Train(int epoch, MPL_Data* out_models){out_models[0] = MPL_train_perceptron(CH1_X_List, CH1_Y_List, TrainDataSize, epoch);}// mpl.h#ifndef __MPL_H__#define __MPL_H__#include <stdio.h>#define Lr 0.05#define TrainDataSize 40#define DataMaxNum 100// 权重结构体typedef struct {float w;float b; } MPL_Data;void MPL_Train(int epoch, MPL_Data* out_models);int MPL_predict(float x, MPL_Data mpl_data);#endif运行日志训练参数:w=0.312500, b=-0.550000训练参数:w=0.222500, b=-0.600000训练参数:w=0.317500, b=-0.550000训练参数:w=0.230000, b=-0.600000训练参数:w=0.325000, b=-0.550000训练参数:w=0.240000, b=-0.600000训练参数:w=0.335000, b=-0.550000训练参数:w=0.252500, b=-0.600000训练参数:w=0.347500, b=-0.550000训练参数:w=0.267500, b=-0.600000训练参数:w=0.362500, b=-0.550000训练参数:w=0.285000, b=-0.600000训练参数:w=0.380000, b=-0.550000训练参数:w=0.307500, b=-0.600000训练参数:w=0.402500, b=-0.550000训练参数:w=0.332500, b=-0.600000训练参数:w=0.240000, b=-0.650000训练参数:w=0.335000, b=-0.600000训练参数:w=0.245000, b=-0.650000训练参数:w=0.340000, b=-0.600000训练参数:w=0.250000, b=-0.650000训练参数:w=0.345000, b=-0.600000训练参数:w=0.257500, b=-0.650000训练参数:w=0.352500, b=-0.600000训练参数:w=0.265000, b=-0.650000训练参数:w=0.360000, b=-0.600000训练参数:w=0.275000, b=-0.650000训练参数:w=0.370000, b=-0.600000训练参数:w=0.287500, b=-0.650000训练参数:w=0.382500, b=-0.600000训练参数:w=0.302500, b=-0.650000训练参数:w=0.397500, b=-0.600000训练参数:w=0.320000, b=-0.650000训练参数:w=0.415000, b=-0.600000训练参数:w=0.342500, b=-0.650000y = hardlim(0.3425*x + -0.6500)X = 141.0 => Y = 0X = 145.0 => Y = 0X = 243.0 => Y = 1X = 175.0 => Y = 0X = 243.0 => Y = 1X = 120.0 => Y = 0X = 102.0 => Y = 0X = 164.0 => Y = 0X = 184.0 => Y = 0X = 102.0 => Y = 0X = 218.0 => Y = 1X = 159.0 => Y = 0