Java基本概念
一、基本概念
1、基本概述
Java 是一种广泛使用的面向对象编程语言,由 Sun 公司的詹姆斯·高斯林团队于 1995 年推出,具有 跨平台、高性能、强类型 等特点。
2、核心特征
1、面向对象
所有代码通过 类(Class) 和 对象(Object) 组织实现,支持 封装、继承、多态、抽象。
2、无关性
通过 JVM(Java虚拟机) 实现“一次编写,到处运行”,源码编译为 .class 字节码文件,由 JVM 解释执行。
3、内存管理
使用 垃圾回收器(GC) 自动回收不再使用的对象内存,避免内存泄漏。
4、强类型
变量需显式声明类型,编译器会进行类型检查。
3、核心组件
1、JVM:执行字节码的虚拟机。
2、JDK:包含 JVM 和运行库(如 java.lang, java.util)。
3、JRE:开发工具包(编译器 javac、调试器等)。
4、跨平台
1、编译过程
源代码编译:Java源代码(.java文件)首先被编译成字节码(.class文件)。这一过程是通过Java编译器(javac)完成的。
平台无关性:由于字节码不依赖于任何特定的硬件或操作系统,因此它是Java实现跨平台的基础。这意味着,无论在何种操作系统上编译Java源代码,生成的字节码都是相同的。
2、执行过程
Java虚拟机(JVM):Java虚拟机是Java语言实现跨平台性的关键。JVM是一个虚拟的计算机,它可以模拟执行字节码文件。每个操作系统上都有对应的JVM实现,这使得Java程序能够在不同平台上运行而不需要做任何修改。
字节码执行:当Java程序运行时,JVM会加载并解释执行字节码。JVM还可以利用即时编译器(JIT Compiler)将频繁执行的热点代码编译成特定平台的机器码,以提高程序的执行效率。
3、标准库和抽象操作系统接口
Java标准库:Java提供了一个丰富的标准库,这些库是用Java编写的,对所有平台都是相同的。Java程序可以利用这些标准库来进行文件操作、网络通信等,而不必担心底层操作系统的差异。
抽象操作系统接口:Java提供了一套抽象的接口来代表底层操作系统的功能,这样Java程序就可以通过这些接口与操作系统交互,而不需要直接与操作系统打交道。
二、Java语言基础
1、基本数据类型及封装类对比
基本数据类型 位数 字节数 封装类 默认值 封装类默认值
byte 8 位 1 字节 Byte 0 null
short 16 位 2 字节 Short 0 null
int 32 位 4 字节 Integer 0 null
long 64 位 8 字节 Long 0L null
float 32 位 4 字节 Float 0.0f null
double 64 位 8 字节 Double 0.0d null
char 16 位 2 字节 Character '\u0000' null
boolean 1 位 未严格定义 Boolean false null
2、基本数据类型
直接存储值,内存分配在栈(或堆中的局部变量表)。
性能高,无对象开销,适用于高频计算场景(如循环、数组操作)。
默认值:声明为类成员变量时自动赋默认值,局部变量必须显式初始化。
3、封装类(包装类)
对象形式存储,内存分配在堆,提供对象方法(如类型转换、数值操作)。
使用场景:
集合类(如 List<Integer>)必须使用封装类。
泛型、反射、序列化等需要对象操作的场景。
自动装箱/拆箱:JDK5+ 支持 int ↔ Integer 等隐式转换,但频繁操作可能影响性能。
4、注意事项
比较问题:
Integer a = 100;
Integer b = 100;
System.out.println(a == b); // true(缓存范围 -128~127)
Integer c = 200;
Integer d = 200;
System.out.println(c == d); // false(超出缓存范围)
NPE 风险:封装类默认值为 null,拆箱时需判空:
Integer num = null;
int value = num; // 抛出 NullPointerException
性能权衡:优先使用基本类型,仅在必要场景(如集合、泛型)使用封装类。
总结
| 特性 | 基本数据类型 | 封装类 |
|---|---|---|
| 存储方式 | 直接存储值 | 存储对象引用 |
| 内存开销 | 低(如 int 占 4 字节) | 高(对象头 + 实例数据,通常 16~24 字节) |
| 功能扩展 | 无 | 提供工具方法(如 Integer.parseInt()) |
| 适用场景 | 高频计算、局部变量 | 集合、泛型、需要对象操作的场景 |
2 Java 类型转换
1 自动类型转换(隐式转换)
概念
自动类型转换是指Java编译器在不丢失数据信息的前提下,自动将一种基本数据类型转换为另一种兼容类型的过程。这种转换通常发生在赋值或运算过程中,无需程序员显式声明。
条件
类型兼容:两种数据类型必须是兼容的(如数值类型之间,char与int之间)。
目标类型范围 ≥ 源类型范围:
整数类型:byte < short < int < long
浮点类型:float < double
混合类型:int可转float,long可转double(但可能丢失精度)
应用场景
整数升级:
byte a = 10;
int b = a; // byte → int(自动转换)
整数转浮点:
int num = 100;
double d = num; // int → double(自动转换,结果为100.0)
字符转整数:
char c = 'A';
int code = c; // char → int(自动转换,结果为65)
注意事项
精度丢失风险:
当int转float或long转double时,可能因浮点数的精度限制导致数据丢失。
int bigInt = 123456789;
float f = bigInt; // 实际值为1.23456792E8(精度丢失)
boolean不参与:
布尔类型(boolean)与其他类型互不兼容,无法转换。
** 2.2.2 强制类型转换(显式转换)**
概念
强制类型转换是程序员主动要求的转换,需用(目标类型)语法明确声明。这种转换可能伴随数据丢失或溢出风险,常用于以下场景:
目标类型范围 < 源类型范围
类型不完全兼容但逻辑上可转换
语法形式
目标类型 变量名 = (目标类型) 源值;
应用场景
大范围转小范围:
int a = 300;
byte b = (byte) a; // int → byte(强制转换,结果为44,溢出)
浮点转整数:
double price = 99.95;
int intPrice = (int) price; // 结果为99(截断小数,非四舍五入)
字符与数值互转:
int code = 97;
char letter = (char) code; // 结果为'a'
注意事项
数据溢出:
long bigNum = 9_876_543_210L;
int smallNum = (int) bigNum; // 结果溢出为负数(-2147483648)
精度丢失:
float pi = 3.14159f;
int approx = (int) pi; // 结果为3(丢弃小数部分)
boolean不参与:
boolean flag = true;
// int num = (int) flag; // 编译错误
总结
特征 自动类型转换 强制类型转换
触发方式 编译器自动完成 程序员显式声明
数据安全性 无数据丢失风险(浮点精度除外) 可能发生溢出或精度丢失
转换方向 小类型→大类型 大类型→小类型
语法要求 无需特殊语法 必须用(目标类型)强制声明
典型场景 int→long, int→double double→int, long→int
1、避免滥用强制转换:优先使用自动转换,强制转换需明确知晓后果。
2、范围检查:对大数转小数时,可先判断是否超出目标类型范围。
3、浮点精度处理:需要保留小数时,用Math.round()代替强制截断。
4、字符转换验证:确保数值在0~65535范围内再转char。
// 安全转换示例
double value = 123.56;
int safeValue = (value > Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int) value;
3 Java自动装箱与拆箱
装箱:将基本类型用它们对应的引用类型包装起来;
拆箱:将包装类型转换为基本数据类型;
对比项 装箱(Boxing) 拆箱(Unboxing)
定义 将基本数据类型自动转换为对应的包装类对象 将包装类对象自动转换为对应的基本数据类型
示例 int a = 10;Integer b = a;(编译器自动转换为 Integer b = Integer.valueOf(a);) Integer c = 20;int d = c;(编译器自动转换为 int d = c.intValue();)
触发条件 - 基本类型赋值给包装类变量
- 基本类型作为参数传递给需要包装类的方法 - 包装类对象赋值给基本类型变量
- 包装类参与基本类型运算或比较
底层实现 调用包装类的静态方法 valueOf()(如 Integer.valueOf(int)) 调用包装类对象的实例方法(如 intValue()、doubleValue())
性能影响 - 频繁装箱可能产生临时对象,影响性能(如循环中大量装箱操作) - 拆箱时若包装类对象为 null,会抛出 NullPointerException
应用场景 - 集合框架存储基本类型(如 List<Integer>)
- 需要对象类型的场景(如泛型) - 从集合中取出基本类型数据
- 数值运算或逻辑判断
自动装箱的优化
部分包装类(如 Integer、Long)会缓存常用值(-128 ~ 127),直接复用缓存对象而非新建。
Integer x = 127; // 使用缓存对象
Integer y = 128; // 新建对象
拆箱的风险
若包装类对象为 null,拆箱时会抛出 NullPointerException:
Integer num = null;
int value = num; // 抛出 NullPointerException
性能陷阱
避免在循环或高频代码中隐式装箱/拆箱:
Long sum = 0L;
for (int i = 0; i < 10000; i++) {
sum += i; // 每次循环触发自动装箱(i → Long)
}
总结
自动装箱与拆箱简化了基本类型与包装类之间的转换,但需注意其潜在的性能开销和空指针风险。优先在以下场景使用:
需要对象类型时(如集合操作、泛型)
逻辑简洁性要求高于性能的场景
在性能敏感场景(如大规模数据处理),建议直接使用基本数据类型(如 int 而非 Integer)。
4、Java关系运算符
- 等于运算符 (
==) - 不等于运算符 (
!=) - 大于运算符 (
>) - 小于运算符 (
<) - 大于等于运算符 (
>=) - 小于等于运算符 (
<=)
5、Java条件运算符
&&运算符:(value1 == 1) && (value2 == 2)检查value1是否等于 1 且value2是否等于 2。两个条件都为真,因此打印出"value1 is 1 AND value2 is 2"。||运算符:(value1 == 1) || (value2 == 1)检查value1是否等于 1 或value2是否等于 1。第一个条件为真,因此打印出"value1 is 1 OR value2 is 1",即使第二个条件不再被计算。
3. 三元运算符(? :)
三元运算符也被称为条件运算符,用于简化 if-else 语句。它使用三个操作数,其结构为:
condition ? value1 : value2;- 如果
condition为true,则返回value1。 - 如果
condition为false,则返回value2。
6、Java循环
下面我们介绍循环控制结构。如果您想要同样的操作执行多次,就需要使用循环结构。Java中有三种主要的循环结构:
- for 循环
- while 循环
- do…while 循环
7 、Java自增自减运算符
自增运算符 ++
自增运算符用于将变量的值加1。它有两种形式:前缀形式(++variable)和后缀形式(variable++)。
前缀自增:先将变量值加1,然后再使用这个新的值。
后缀自增:先使用变量当前的值,然后将其值加1。
自减运算符 --
类似地,自减运算符用于将变量的值减1。它也有两种形式:前缀形式(--variable)和后缀形式(variable--)。
前缀自减:先将变量值减1,然后再使用这个新的值。
后缀自减:先使用变量当前的值,然后将其值减1。
示例分析
前缀自增示例
int a = 5;
System.out.println(++a); // 输出6, 因为先自增再使用
在这个例子中,a首先被自增到6,然后打印出这个新值。
后缀自增示例
int b = 5;
System.out.println(b++); // 输出5, 因为先使用再自增
System.out.println(b); // 输出6, 因为上一步已经自增
这里,第一次打印时输出的是b原来的值5,之后b才被自增到6。
前缀自减示例
int c = 5;
System.out.println(--c); // 输出4, 因为先自减再使用
后缀自减示例
int d = 5;
System.out.println(d--); // 输出5, 因为先使用再自减
System.out.println(d); // 输出4, 因为上一步已经自减
8、 Java泛型
1、泛型类和泛型接口
如果定义的一个类或接口有一个或多个类型变量,则可以使用泛型。泛型类型变量由尖括号界定,放在类或接口名的后面,下面定义尖括号中的T称为类型变量。意味着一个变量将被一个类型替代替代类型变量的值将被当作参数或返回类型。对于List接口来说,当一个实例被创建以后,T将被当作一个函数的参数下面分别是泛型类、泛型接口的定义:
1public class Gen<T>{/泛型类 2 3…… 4 5}
1public interface List<T> extends Collection<T>{//泛型接口 2…… 3}
2、泛型方法
是否拥有泛型方法,与其所在的类是否泛型无关。
要定义泛型方法,只需将泛型参数列表置于返回值前。
如:
1public class ExampleA{ 2 public<> voidf(Tx){ 3 System.out.println(x.getClass().get Name()); 4 } 5 publiec static void main(String args[ ]){ 6 ExampleA ea= new ExampleA(); 7 ea-f(""); 8 ea.f(10); 9 ea.f(a); 10 ea.f(ea); 11 } 12}
使用泛型方法时,不必指明参数类型,编译器会自己找出具体的类型。泛型方法除了定义不同,调用就像普通方法一样。需要注意,一个static方法,无法访问泛型类的类型参数,所以,若要static方法需要使用泛型能力,必须使其成为泛型方法。 [1]
优点
播报
编辑
Java语言中引入泛型是一个较大的功能增强。不仅语言、类型系统和编译器有了较大的变化,以支持泛型,而且类库也进行了很大的改动,许多重要的类,比如集合框架,都已经成为泛型化的了。这带来了很多好处:
1、类型安全
泛型的主要目标是提高Java程序的类型安全。通过知道使用泛型定义的变量的类型限制,编译器可以在非常高的层次上验证类型假设。没有泛型,这些假设就只存在于系统开发人员的头脑中。
通过在变量声明中捕获这一附加的类型信息,泛型允许编译器实施这些附加的类型约束。类型错误就可以在编译时被捕获了,而不是在运行时当作ClassCastException展示出来。将类型检查从运行时挪到编译时有助于Java开发人员更早、更容易地找到错误,并可提高程序的可靠性。
2、消除强制类型转换
泛型的一个附带好处是,消除源代码中的许多强制类型转换。这使得代码更加可读,并且减少了出错机会。尽管减少强制类型转换可以提高使用泛型类的代码的累赞程度,但是声明泛型变量时却会带来相应的累赞程度。在简单的程序中使用一次泛型变量不会降低代码累赞程度。但是对于多次使用泛型变量的大型程序来说,则可以累积起来降低累赞程度。所以泛型消除了强制类型转换之后,会使得代码加清晰和筒洁。
3、更高的运行效率
在非泛型编程中,将筒单类型作为Object传递时会引起Boxing(装箱)和Unboxing(拆箱)操作,这两个过程都是具有很大开销的。引入泛型后,就不必进行Boxing和Unboxing操作了,所以运行效率相对较高,特别在对集合操作非常频繁的系统中,这个特点带来的性能提升更加明显。
4、潜在的性能收益
泛型为较大的优化带来可能。在泛型的初始实现中,编译器将强制类型转换(没有泛型的话,Java系统开发人员会指定这些强制类型转换)插入生成的字节码中。但是更多类型信息可用于编译器这一事实,为未来版本的JVM的优化带来可能。 [3]
使用注意事项
播报
编辑
使用Java泛型应该注意如下几点:
①在定义一个泛型类时,在“<>”之间定义形式类型参数,例如:“class TestGen<K,V>”,其中“K”,“V”不代表值,而是表示类型。
②实例化泛型对象时,一定要在类名后面指定类型参数的值(类型),一共要有两次书写。
③泛型中<Kextends ObjecD,extends>并不代表继承,它是类型范围限制。
④使用泛型时,泛型类型必须为引用数据类型,不能为基本数据类型,Java中的普通方法,构造方法,静态方法中都可以使用泛型,方法使用泛型之前必须先对泛型进行声明,可以使用任意字母,一般都要大写。
⑤不可以用一个本地类型(如int float)来替换泛型。
⑥运行时类型检查,不同类型的泛型类是等价的(Pair与Pair是属于同一个类型Pair),这一点要特别注意,即如果obj instance of Pai == true的话,并不代表objget First()的返回值是一个String类型。
⑦泛型类不可以继承Exception类,即泛型类不可以作为异常被抛出。
⑧不可以定义泛型数组。
⑨不可以用泛型构造对象,即:first = new T();是错误的。
⑩在static方法中不可以使用泛型,泛型变量也不可以用static关键字来修饰
⑪不要在泛型类中定义equals(Tx)这类方法,因为Object类中也有equals方法,当泛型类被擦除后,这两个方法会冲突。
⑫根据同一个泛型类衍生出来的多个类之间没有任何关系,不可以互相赋值。
⑬若某个泛型类还有同名的非泛型类,不要混合使用,坚持使用泛型类。
三、Java面向对象
3.1 面向对象与面向过程
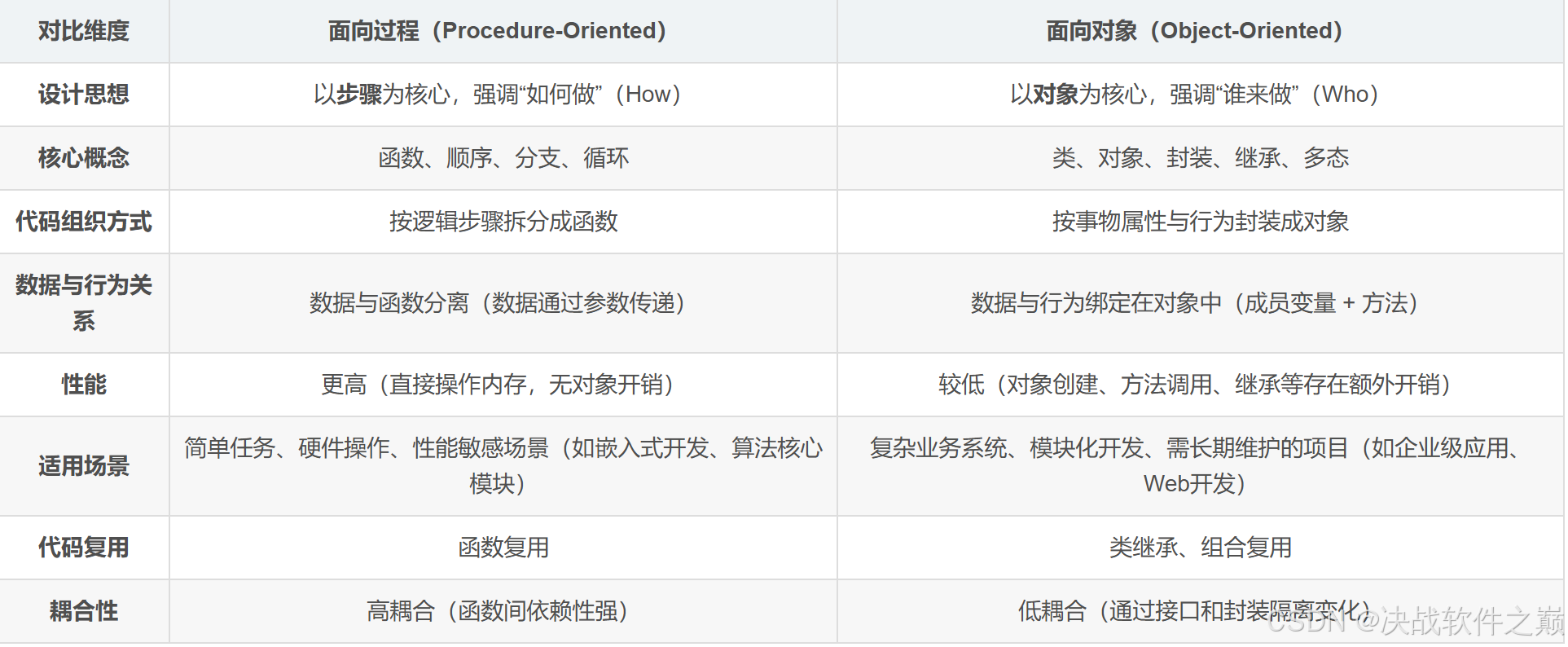
性能差异
面向过程:直接操作内存和寄存器,无对象实例化、方法表查询等开销。
面向对象:动态绑定、继承链查询等机制需要额外计算(现代 JVM 已优化,差距缩小)。
开发效率

范式选择原则

3.2 面向对象的特性
-
封装:封装是将数据和操作数据的方法捆绑在一起,形成一个独立的单元——类。通过访问控制机制,隐藏内部的实现细节,只暴露必要的接口与外界交互。封装可以提高代码的可维护性和复用性,同时降低系统的耦合度。例如,在Java中,可以通过public、protected、private等权限修饰符来控制属性的访问权限,提供get和set方法来操作属性,从而隐藏内部的实现细节。
-
继承:继承允许一个类基于另一个类的属性和方法来创建新的类,从而实现代码的重用和扩展。通过继承,子类可以继承父类的属性和方法,并且可以添加新的属性和方法,或者重写父类的方法。继承提高了代码的复用性,减少了代码的重复编写,并且使得系统结构更加清晰。
-
多态:多态是指在不同的上下文中,同一个操作可以表现出不同的行为。多态可以通过接口、抽象类和继承来实现。多态允许我们在程序中使用更加灵活和可扩展的代码结构,同一个接口可以被不同的类实现,表现出不同的行为。多态提高了代码的可扩展性和灵活性12。
3.4 重载和重写
重载: 发生在同一个类中,方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同,发生在编译时。
重写: 发生在父子类中,方法名、参数列表必须相同,返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类;如果父类方法访问修饰符为 private 则子类就不能重写该方法。
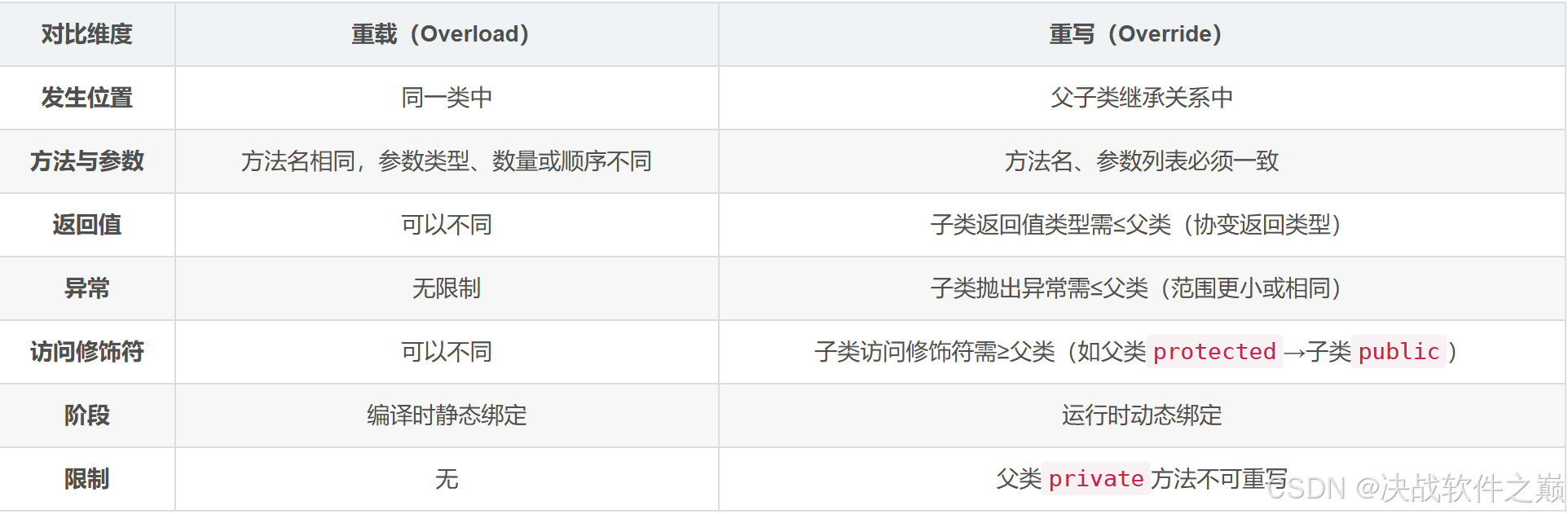
总结
- 重载:同一类中方法名相同,参数不同,用于扩展方法的多态性。
- 重写:子类覆盖父类方法,用于实现多态行为,遵循“里氏替换原则”。
3.5 访问修饰符
1、是什么
Java访问修饰符是一种关键字,用来控制类、方法和变量的访问权限。
2、作用
作用
- 封装性:访问修饰符可以用来限制其他类对于某个类、方法或变量的访问,从而保护类的数据安全性,实现类的封装。 Java 面向对象的封装性就依赖访问修饰符来实现!
- 可读性:访问修饰符可以用来表明类、方法或变量的访问范围,使代码更易于理解和维护。 我对这种可读性的理解是对于访问范围进行了直接标明!
- 重用性:访问修饰符可以用来控制子类对于父类中属性和方法的访问,从而实现代码的重用。 我觉得更多的,访问修饰符对这方面提供了灵活的控制!我觉得子类继承父类最大的目的就是为了代码复用,访问修饰符提供了灵活的控制!
- 可维护性:访问修饰符可以用来限制对于某个类、方法或变量的访问,从而使得修改代码更加容易,不会影响其他部分的代码。 访问修饰符限制了可访问范围,代码修改带来的影响也是在一定范围内的!
- **安全性:**访问修饰符可以用来限制对于某个类、方法或变量的访问,从而提高程序的安全性,防止恶意操作或者不合理的访问。 限制的大多数目的就是为了安全!凡是容易造成安全问题的行为都应该得到限制!目标 => 策略 => 规则(限制)!
总之,Java访问修饰符可以用来控制程序中各个部分的访问范围,从而实现类的封装,增强程序的可读性、重用性、可维护性和安全性。
问题
访问修饰符并不是只有优点,也会带来一些问题!如带来了程序设计的复杂性,垂直和水平方向的访问限制设置提高了对软件开发人员的要求,如果访问修饰符使用不当,会导致代码的可读性大大降低,提高了系统的复杂性!访问修饰符设置得当的时候,往往带来很多好处,但如果设置不当便适得其反!
3、访问修饰符有哪些
Java中有四种访问修饰符,它们分别是:
- public(公共的):被声明为
public的类、方法和变量可以被任何其他类访问。 - protected(受保护的):被声明为
protected的方法和变量只能被同一包内的其他类访问,或者是其他包中的子类访问。 - default(默认的):如果没有指定任何访问修饰符,则默认为
default,被声明为default的方法和变量只能被同一包内的其他类访问。 - private(私有的):被声明为
private的方法和变量只能被同一类内部的其他方法访问,不能被其他类访问。
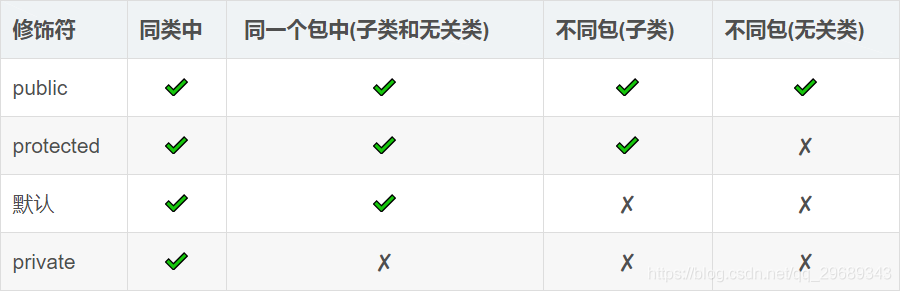
img
4、作用对象
Java访问修饰符可以用于以下三个对象:
- 类:Java 中的类可以使用
public和默认的访问修饰符。如果使用public访问修饰符,这个类将被其他任何类所访问。如果使用默认的访问修饰符,则只能在同一包内的其他类中访问这个类。 - 方法:Java 中的方法可以使用
public、protected、private和默认的访问修饰符。如果使用public访问修饰符,这个方法将被其他任何类所访问。如果使用protected访问修饰符,这个方法将被同一包中的其他类和其他包中的子类所访问。如果使用private访问修饰符,这个方法只能在同一类中访问。如果使用默认的访问修饰符,则只能在同一包中的其他类中访问这个方法。 - 变量:Java 中的变量可以使用
public、protected、private和默认的访问修饰符。如果使用public访问修饰符,这个变量将被其他任何类所访问。如果使用protected访问修饰符,这个变量将被同一包中的其他类和其他包中的子类所访问。如果使用private访问修饰符,这个变量只能在同一类中访问。如果使用默认的访问修饰符,则只能在同一包中的其他类中访问这个变量。
3.6 this 关键字
在Java中,this 是一个非常重要的关键字,它表示当前对象的引用。也就是说,当你在某个类的实例方法或构造器中时,this 指向调用该方法或创建的当前对象实例。以下将结合代码示例和具体场景,详细讲解 this 的用法及其作用。
1. 区分实例变量与局部变量或参数
在Java中,当方法的参数或局部变量与类的实例变量同名时,会出现命名冲突。此时,this 可以用来明确指定访问的是实例变量,而不是参数或局部变量。
示例代码:
public class Car {
private String color; // 实例变量
public void setColor(String color) { // 参数与实例变量同名
this.color = color; // this.color 是实例变量,color 是参数
}
public String getColor() {
return this.color; // 显式使用 this 访问实例变量
}
public static void main(String[] args) {
Car car = new Car();
car.setColor("Blue");
System.out.println(car.getColor()); // 输出: Blue
}
}
场景分析:
在 setColor 方法中,参数 color 和实例变量 color 同名。如果直接写 color = color;,Java会认为你将参数赋值给自身,实例变量不会被修改。
使用 this.color 明确指定操作的是实例变量,避免歧义。
在 getColor 方法中,虽然直接写 return color; 也能正确返回实例变量(因为没有同名局部变量),但使用 this.color 可以提高代码的可读性,表明意图是访问当前对象的属性。
2. 在构造器中调用另一个构造器
this 可以用来在一个构造器中调用同一个类的另一个构造器。这种用法通常用于代码复用,避免重复编写初始化逻辑。注意:调用 this() 必须是构造器中的第一条语句。
示例代码:
public class Car {
private String color;
private int year;
public Car(String color) {
this.color = color;
this.year = 2023; // 默认年份
}
public Car(String color, int year) {
this(color); // 调用单参数构造器
this.year = year; // 覆盖默认年份
}
public void printDetails() {
System.out.println("Color: " + color + ", Year: " + year);
}
public static void main(String[] args) {
Car car1 = new Car("Red");
Car car2 = new Car("Blue", 2020);
car1.printDetails(); // 输出: Color: Red, Year: 2023
car2.printDetails(); // 输出: Color: Blue, Year: 2020
}
}
场景分析:
Car(String color) 是基础构造器,设置颜色并赋予默认年份。
Car(String color, int year) 通过 this(color) 调用基础构造器来设置颜色,然后再设置特定的年份。
这种方式避免了重复编写 this.color = color; 的逻辑,提高代码复用性。
3. 将当前对象作为参数传递
this 可以用来将当前对象传递给其他方法,常见于对象之间的协作场景。
示例代码:
public class Car {
public void startEngine() {
Engine engine = new Engine();
engine.start(this); // 将当前 Car 对象传递给 Engine
}
public String toString() {
return "A Car";
}
}
class Engine {
public void start(Car car) {
System.out.println("Starting " + car); // 输出: Starting A Car
}
}
public class Main {
public static void main(String[] args) {
Car car = new Car();
car.startEngine();
}
}
场景分析:
在 startEngine 方法中,this 表示当前 Car 对象。
将 this 传递给 Engine 的 start 方法,使得 Engine 可以操作调用它的 Car 实例。
这种用法在对象交互(如事件处理或依赖关系)中非常常见。
4. 返回当前对象以支持方法链调用
通过让方法返回 this,可以实现方法的链式调用,这种模式在许多API(如 StringBuilder)中广泛使用。
示例代码:
public class Car {
private String color;
private int year;
public Car setColor(String color) {
this.color = color;
return this; // 返回当前对象
}
public Car setYear(int year) {
this.year = year;
return this; // 返回当前对象
}
public void printDetails() {
System.out.println("Color: " + color + ", Year: " + year);
}
public static void main(String[] args) {
Car car = new Car()
.setColor("Green")
.setYear(2021);
car.printDetails(); // 输出: Color: Green, Year: 2021
}
}
场景分析:
setColor 和 setYear 方法返回 this,允许连续调用多个方法。
这种链式调用的写法简洁优雅,尤其适合需要多次设置对象属性的场景。
5. 在静态方法中不能使用 this
this 表示当前对象,而静态方法属于类而不是某个对象,因此在静态方法中使用 this 会导致编译错误。
示例代码:
public class Car {
private String color = "White";
public static void printSomething() {
// System.out.println(this.color); // 错误: 静态方法中不能使用 this
System.out.println("This is a static method.");
}
public static void main(String[] args) {
Car.printSomething(); // 输出: This is a static method.
}
}
场景分析:
printSomething 是静态方法,与具体对象无关,因此无法使用 this 访问实例变量 color。
如果需要访问实例变量,必须通过对象的引用而不是 this。
综合示例
以下是一个综合运用 this 的例子,展示其多种用法:
public class Person {
private String name;
private int age;
// 构造器1:只设置姓名
public Person(String name) {
this.name = name;
this.age = 0; // 默认年龄
}
// 构造器2:设置姓名和年龄,调用构造器1
public Person(String name, int age) {
this(name); // 调用单参数构造器
this.age = age;
}
// 支持链式调用的 setter 方法
public Person setName(String name) {
this.name = name;
return this;
}
public Person setAge(int age) {
this.age = age;
return this;
}
// 使用 this 访问实例变量
public void introduce() {
System.out.println("Hi, I'm " + this.name + " and I'm " + this.age + " years old.");
}
public static void main(String[] args) {
// 使用链式调用
Person person1 = new Person("Alice").setAge(30);
person1.introduce(); // 输出: Hi, I'm Alice and I'm 30 years old.
// 使用多参数构造器
Person person2 = new Person("Bob", 25);
person2.introduce(); // 输出: Hi, I'm Bob and I'm 25 years old.
}
}
场景分析:
this(name) 在构造器中复用代码。
this.name 和 this.age 明确访问实例变量。
setName 和 setAge 返回 this,支持链式调用。
main 方法是静态的,无法使用 this,只能通过对象实例调用方法。
注意事项
与 super 的区别:
this 指当前对象,super 指父类对象或父类构造器。
在构造器中,this() 和 super() 不能同时出现,且必须是第一条语句。
在嵌套类中的特殊用法:
在内部类中,this 指内部类实例,若需访问外部类实例,可用 OuterClass.this。
示例:
public class Outer {
int x = 10;
class Inner {
int x = 20;
void print() {
System.out.println(this.x); // 20
System.out.println(Outer.this.x); // 10
}
}
}
总结
Java中的 this 关键字主要有以下用途:
区分同名变量:解决实例变量与局部变量或参数的命名冲突。
构造器调用:在构造器中调用同一类的其他构造器。
传递当前对象:将当前对象作为参数传递给其他方法。
方法链调用:通过返回 this 实现流畅的链式调用。
限制:不能在静态方法中使用。
通过上述代码示例和场景分析,this 的作用和用法应该已经非常清晰。它不仅是Java面向对象编程的核心概念之一,也是编写清晰、可维护代码的重要工具
7 抽象类与接口
在Java中,抽象类和接口是实现抽象概念的两个主要机制,它们在设计和使用上有所不同,主要体现在以下几个方面:
1. 定义方式
-
抽象类:使用关键字
abstract定义的类,可以有抽象方法(即没有具体实现的方法,仅声明方法签名)和具体方法(有具体实现的方法)。一个类可以继承一个抽象类,并实现其所有抽象方法。 -
接口:使用关键字
interface定义,只能包含抽象方法(JDK 8之前)和默认方法、静态方法(JDK 8及以后)。一个类可以实现多个接口,并通过实现接口中的所有方法(或默认方法)来使用接口。
2. 继承与实现
-
抽象类:一个类只能继承一个抽象类(尽管可以有多个接口实现)。这意味着抽象类提供了更严格的继承结构。
-
接口:一个类可以实现多个接口,这使得接口提供了更灵活的扩展机制。
3. 构造器
-
抽象类:可以有构造器,用于初始化状态或调用父类的构造器。
-
接口:不能有构造器。
4. 字段和方法
-
抽象类:可以包含字段、具体方法和抽象方法。
-
接口:只能包含常量字段(通过
public static final修饰,隐式定义)和抽象方法(JDK 8之前)或默认方法和静态方法(JDK 8及以后)。
5. 使用场景
-
抽象类:适合用于那些需要被继承且有共同行为的场景。例如,你可以创建一个表示动物的抽象类,其中包含所有动物共有的属性和一些共有的行为。
-
接口:适合用于那些需要被多个类实现但彼此之间没有明显的继承关系的情况。例如,你可以定义一个可以行走的接口,然后让猫、狗等不同的动物去实现这个接口。
6. 默认方法和静态方法(Java 8及以后)
-
接口:可以包含默认方法和静态方法,这允许在不破坏现有实现的情况下添加新方法。默认方法可以用
default关键字声明,而静态方法可以用static关键字声明。 -
抽象类:虽然也可以在JDK 8及以后的版本中添加默认方法和静态方法,但这并不是其主要用途或设计初衷。
8、 成员变量与局部变量
一、定义
1.成员变量:在变量声明部分声明的变量被称为类的成员变量。
2.局部变量:在方法体中声明的变量和方法的参数。
class people{
int boy;
float a[];
void f(){
boolean cool;
Student zhangBoy;
}
}
如:这里的boy、a数组为成员变量,cool和zhangBoy为局部变量。
二、变量的有有效范围
1.成员变量在整个类中的所有方法都有效,且其有效性与声明成员变量的位置无关。
2.局部变量只在声明它的方法内有效。
public class A{
int m=10,sum=0;//成员变量在整个类中都有效
void f(){
if(m>9){
int z=10;//z为局部变量,只在此复合语句中有效
z=2*m+z;
}
for(int i=0;i<m;i++){
sum=sum+i;//i只在此循环语句中有效
}
m=sum;//合法,因为m和sum在整个类中都有效
z=i+sum;//不合法,局部变量已失效
}
}
三、实例变量与类变量
在声明成员变量时,用关键字static修饰的叫类变量(static变量,静态变量),无static修饰的叫实例变量。
class Dog{
float x;//实例变量
static int y;//类变量
}
注意:static需要放在类型的前面。
四、成员变量的隐藏
局部变量的名字与成员变量的名字相同,则成员变量被隐藏(即成员变量在此方法内暂时失效),想在该方法内使用被隐藏的成员变量必须用this关键字。
class Tom{
int x=98,y;
void f(){
int x=3;
y=x;//y得到的值是3
}
}
class 三角形{
float sideA,sideB,sideC,lengthSum;
void setSide(float sideA,float sideB,float sideC){
this.sideA=sideA;
this.sideB=sideB
this.sideC=sideC;
}
}
9 static 关键字
static关键字在编程中主要用于将类成员(变量、方法、代码块等)提升为类级别,使其不依赖于对象实例即可访问。使用static关键字修饰的成员属于类级别,而不是对象级别,具有以下特性:
- 独立于对象存在:静态成员在类加载时即初始化,生命周期与类一致,而不是与某个特定对象绑定。
- 共享性:静态成员被所有对象共享,内存中仅存一份。这意味着无论创建多少个对象,静态成员都只有一个副本。
static关键字的用法
- 修饰成员变量:使用static修饰的成员变量称为静态变量或类变量。静态变量在内存中只有一份,所有对象共享这个变量。例如,一个计数器变量可以用来记录类的实例数量。
- 修饰成员方法:使用static修饰的方法称为静态方法。静态方法可以通过类名直接调用,不需要创建对象实例。静态方法只能直接访问其他静态成员,不能直接访问非静态成员。
- 静态代码块:用于初始化静态变量。静态代码块在类加载时执行一次,且只执行一次。
- 静态内部类:定义在类内部的静态内部类,可以直接通过外部类名访问,不需要创建外部类的实例4。
示例代码
以下是一个简单的Java示例,演示了static关键字的用法:
javaCopy Code
public class Student { private static int age; // 静态变量,所有对象共享 private double score; // 非静态变量,每个对象独立拥有 public Student(double score) { this.score = score; age++; // 每当创建对象时,静态变量age增加1 } public static void main(String[] args) { Student s1 = new Student(90); Student s2 = new Student(85); System.out.println(Student.age); // 通过类名访问静态变量age System.out.println(s1.score); // 通过对象s1访问非静态变量score } }
在这个例子中,age是一个静态变量,所有Student对象共享这个变量。而score是非静态变量,每个Student对象都有自己独立的score值。
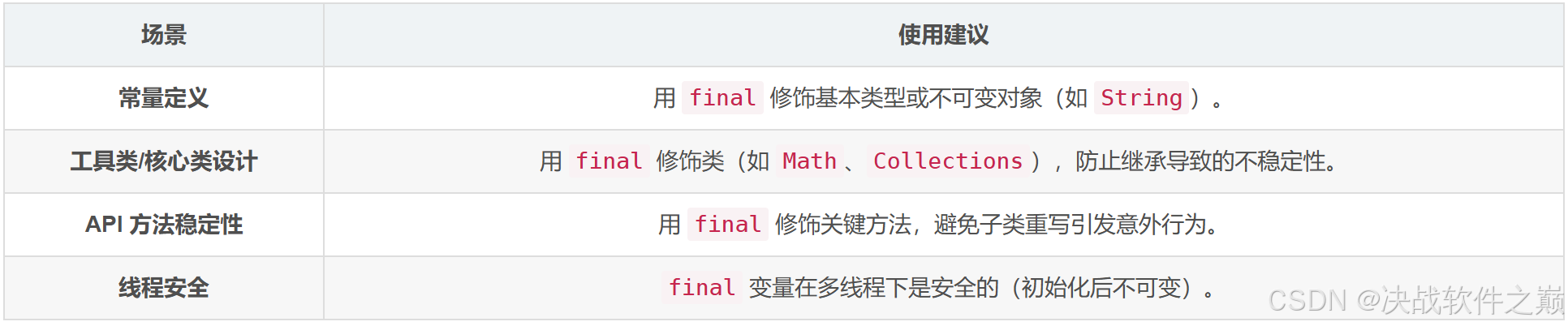
10 final 关键字

核心说明
变量初始化规则
final 变量必须在以下时机初始化:
声明时直接赋值:final int x = 100;
在构造器或静态代码块中赋值(实例变量/静态变量):
class Example {
final int a;
static final int B;
static { B = 200; } // 静态变量
Example() { a = 10; } // 实例变量
}
1
2
3
4
5
6
引用类型变量的可变性
final 仅限制引用地址,不限制对象内部状态:
final List<String> names = new ArrayList<>();
names.add("Alice"); // 允许操作对象内容
names = new ArrayList<>(); // 编译错误(地址不可变)
1
2
3
final 类的设计意图
防止继承破坏类的内部逻辑(如 String 类不可变的设计)。
隐式 final 方法:子类无法重写方法,但可以重载(参数不同)。
其他说明
早期 Java 版本中,final 方法会被内联(inline)以提升性能。
总结
11 finally和finalize 关键字
finally关键字
-
功能
用于定义异常处理中的finally代码块,无论try或catch块是否抛出异常,该代码块都会执行。- 资源释放:常用于关闭文件流、数据库连接等需要确保释放的资源。
- 执行顺序:即使
try或catch块中有return语句,finally代码块仍会在方法返回前执行。
-
示例
try { // 可能抛出异常的代码 } catch (Exception e) { // 异常处理 } finally { // 无论是否异常都会执行(除非调用System.exit()或JVM崩溃) }
finalize方法
-
功能
定义在Object类中,当对象被垃圾回收器(GC)回收时,会调用此方法进行非内存资源的清理(如文件句柄或网络连接)47。- 不确定性:JVM不保证
finalize的调用时机或是否调用。 - 废弃状态:Java 9后标记为废弃,推荐使用
AutoCloseable接口和try-with-resources代替。
- 不确定性:JVM不保证
-
示例
public class Example { @Override protected void finalize() throws Throwable { // 清理逻辑(不推荐依赖此方法) } }
核心区别
| 特性 | finally | finalize |
|---|---|---|
| 类型 | 异常处理关键字 | Object类的方法 |
| 执行时机 | 明确(try-catch结束后立即执行) | 由GC决定(可能完全不执行) |
| 用途 | 确保资源释放 | 对象回收前的清理(已不推荐使用) |
| 可靠性 | 高(除非极端情况) | 低(依赖GC且不保证调用) |
总结
-
finally 是异常处理中必须掌握的机制,用于保证代码的确定性执行28。 -
finalize 已过时,不应依赖其进行资源管理,应优先使用try-with-resources等现代机制
12 “==” 与 equals 对比
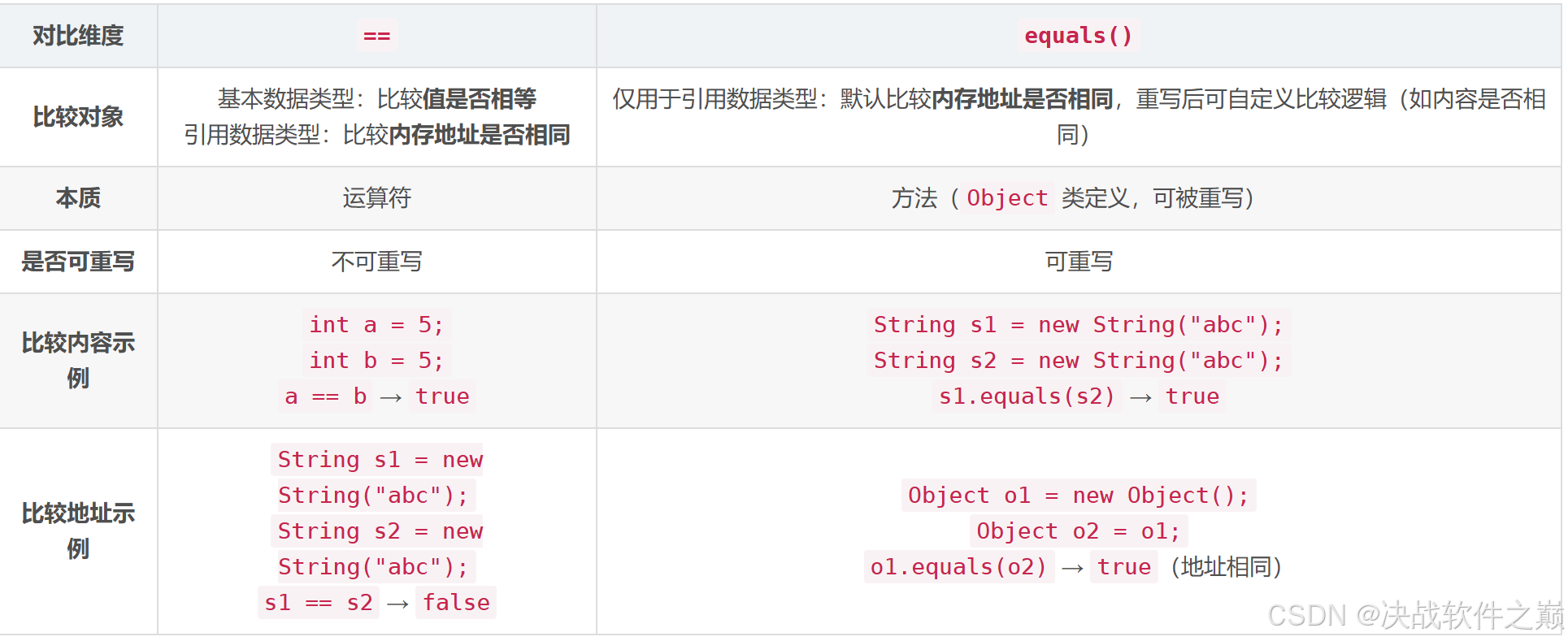
equals() 重写规则
若类重写 equals(),必须同时重写 hashCode() 以保证一致性(相同对象必须返回相同哈希值)。
示例:String、Integer 等包装类均已重写 equals(),比较值而非地址。
字符串常量池的特殊性
直接赋值字符串字面量时,JVM 会优先从常量池复用对象:
String s1 = "abc"; // 常量池中创建
String s2 = "abc"; // 复用常量池中的对象
System.out.println(s1 == s2); // true(地址相同)
new String("abc") 会强制创建新对象,地址不同:
String s3 = new String("abc"); // 堆中新对象
System.out.println(s1 == s3); // false
默认 equals() 行为
若类未重写 equals(),其行为与 == 一致(比较地址):
class MyClass {}
MyClass a = new MyClass();
MyClass b = new MyClass();
System.out.println(a.equals(b)); // false(等价于 a == b)
总结
基本数据类型:仅用 == 比较值。
引用数据类型:
需比较地址 → 用 ==
需比较内容 → 用重写后的 equals()(如 String、自定义对象)
注意:调用 equals() 前需确保对象非 null,否则可能抛出 NullPointerException。
String str = null;
if (str.equals("test")) {} // 抛出异常
if ("test".equals(str)) {} // 安全写法(推荐)
13 值传递与引用传递
在Java中,理解值传递和引用传递的概念非常重要,尤其是在学习面向对象编程时。这两种传递方式主要涉及到方法参数和对象之间的关系。下面将详细解释这两种传递方式:
1. 值传递(Pass by Value)
在Java中,基本数据类型(如int、double、char等)是通过值传递的。这意味着当你将一个基本类型的变量作为参数传递给一个方法时,实际上是将变量的副本传递给方法。在方法内部对参数的修改不会影响到原始变量。
示例代码:
public class ValuePassExample {
public static void main(String[] args) {
int num = 10;
changeValue(num);
System.out.println("num after method call: " + num); // 输出 10,因为num是基本类型,传递的是值
}
public static void changeValue(int number) {
number = 20;
}
}
在这个例子中,changeValue方法接收num的副本(即10),并将其改为20。但是,这不会影响原始变量num的值。
2. 引用传递(Pass by Reference)
对于对象(包括数组),Java使用的是引用传递。这意味着当你将一个对象传递给一个方法时,实际上传递的是对象的引用(内存地址)的副本。因此,在方法内部对对象状态的修改会影响到原始对象。
示例代码:
public class ReferencePassExample {
public static void main(String[] args) {
Person person = new Person("Alice");
changeName(person);
System.out.println("Person's name after method call: " + person.getName()); // 输出 Alice changed,因为person是引用传递
}
public static void changeName(Person p) {
p.setName("Alice changed");
}
}
class Person {
private String name;
public Person(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
在这个例子中,changeName方法接收person对象的引用。尽管在方法内部我们改变了person对象的name属性,这个改变会反映到原始的person对象上。这是因为我们操作的是对象的引用。
总结:
基本数据类型是通过值传递的。这意味着方法内部对参数的修改不会影响原始变量。
对象是通过引用传递的。这意味着方法内部对对象状态的修改会影响到原始对象。这里需要注意的是,虽然我们传递的是引用的副本,但通过这个引用的操作会影响到原始对象。
理解这两种传递方式对于编写高效和正确的Java代码至关重要。
14 深拷贝与浅拷贝
在Java中,深拷贝(Deep Copy)和浅拷贝(Shallow Copy)是对象复制的两种不同方式,它们在处理对象内部引用时有本质的区别。
浅拷贝(Shallow Copy)
浅拷贝创建一个新的对象,但是新对象的字段指向原对象字段的引用(即内存地址)。这意味着如果原对象中的字段是引用类型,那么新对象和原对象将共享这些引用类型的数据。
示例
public class Person implements Cloneable {
String name;
Address address; // 引用类型
public Person(String name, Address address) {
this.name = name;
this.address = address;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
public class Address {
String street;
// 其他字段和方法
}
在这个例子中,如果使用clone()方法进行浅拷贝,Person对象的新实例将与原实例共享Address对象的引用。
深拷贝(Deep Copy)
深拷贝不仅创建新对象,而且递归地复制对象中所有引用的对象。这意味着新对象和原对象不会共享任何引用类型的数据。
示例
public class Person implements Serializable { // 实现Serializable接口以支持序列化方法
String name;
Address address; // 引用类型
public Person(String name, Address address) {
this.name = name;
this.address = address;
}
// 使用序列化进行深拷贝
protected Person deepCopy() throws IOException, ClassNotFoundException {
// 将对象写入流中
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream out = new ObjectOutputStream(bos);
out.writeObject(this);
out.flush();
out.close();
// 从流中读取对象到新的对象实例中
ByteArrayInputStream bin = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream in = new ObjectInputStream(bin);
return (Person) in.readObject();
}
}
在这个例子中,通过序列化和反序列化实现了深拷贝,确保了Person对象及其引用的Address对象都被完全复制,互不共享。
选择使用深拷贝还是浅拷贝?
使用场景:如果你希望新对象和原对象完全独立,即修改一个对象不应影响另一个,应使用深拷贝。如果对象的引用类型字段可以被共享且不影响程序逻辑,可以使用浅拷贝。
性能考虑:深拷贝通常比浅拷贝更消耗资源,因为它需要复制更多的数据。如果对象的结构简单或者引用类型可以被共享,浅拷贝可能更合适。
实现方式:对于简单的对象,可以直接使用clone()方法(需要实现Cloneable接口并重写clone()方法)或者通过序列化实现深拷贝。对于复杂结构或需要控制深拷贝过程的场景,可能需要手动实现深拷贝的逻辑。
注意事项
确保在实现深拷贝时正确处理所有引用类型字段的复制。
对于包含大量数据或复杂引用的对象,深拷贝可能非常耗时和资源密集,需谨慎使用。
15 Java创建对象的方式(扩展)
在Java中,创建对象主要有以下几种方式:
1. 使用new关键字
这是最基本也是最常用的方式。当你需要创建一个类的实例时,可以使用new关键字。
public class MyClass {
// 类的定义
}
public class Test {
public static void main(String[] args) {
MyClass obj = new MyClass(); // 创建MyClass的一个实例
}
}
2. 使用反射(Reflection)
反射允许在运行时动态地创建对象和调用方法。这种方式通常用于当你需要根据字符串名称来动态地创建对象时。
import java.lang.reflect.Constructor;
public class Test {
public static void main(String[] args) {
try {
Class<?> cls = Class.forName("MyClass"); // 加载类
Constructor<?> constructor = cls.getConstructor(); // 获取默认构造函数
Object obj = constructor.newInstance(); // 创建实例
} catch (Exception e) {
e.printStackTrace();
}
}
}
3. 使用克隆(Clone)
克隆是另一种创建对象的方法,但这种方式通常用于复制一个已存在的对象。需要实现Cloneable接口并重写clone()方法。
public class MyClass implements Cloneable {
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone(); // 克隆当前对象
}
}
public class Test {
public static void main(String[] args) {
MyClass original = new MyClass(); // 原始对象
try {
MyClass cloned = (MyClass) original.clone(); // 克隆对象
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
}
}
4. 使用序列化(Serialization)和反序列化(Deserialization)
这种方法可以用来从一个文件或网络中读取对象的序列化版本,并将其恢复为对象。这种方式通常用于对象的持久化存储。
import java.io.*;
public class MyClass implements Serializable {
// 需要序列化的类定义,实现Serializable接口即可
}
public class Test {
public static void main(String[] args) {
MyClass obj = new MyClass(); // 创建对象
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("obj.ser"))) {
oos.writeObject(obj); // 序列化对象到文件
} catch (IOException e) {
e.printStackTrace();
}
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("obj.ser"))) {
MyClass restoredObj = (MyClass) ois.readObject(); // 从文件中反序列化对象
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
}
5. 使用工厂模式(Factory Pattern)或建造者模式(Builder Pattern)
这些设计模式可以用来控制对象的创建过程,使得创建逻辑更加灵活和可扩展。例如,工厂模式允许你根据输入来决定创建哪种类型的对象。建造者模式用于当你需要创建一个复杂对象时,通过分步骤构建。
// 工厂模式示例:创建一个动物工厂,根据类型返回不同动物实例。
public class AnimalFactory {
public static Animal getAnimal(String type) {
if ("dog".equalsIgnoreCase(type)) return new Dog();
else if ("cat".equalsIgnoreCase(type)) return new Cat();
return null; // 或者抛出异常等处理方式
}
}
或者建造者模式:
public class Pizza {
private String dough; // 面团类型等属性定义...
private String sauce; // 酱料等属性定义...
// 建造者内部类定义...省略细节以保持简洁性。实际使用时需要定义建造者类及其方法。
}
每种方法都有其适用场景,你可以根据具体需求选择最合适的方式。
四、Java核心数据
4.1 String、StringBuffer、StringBuilder 区别与联系
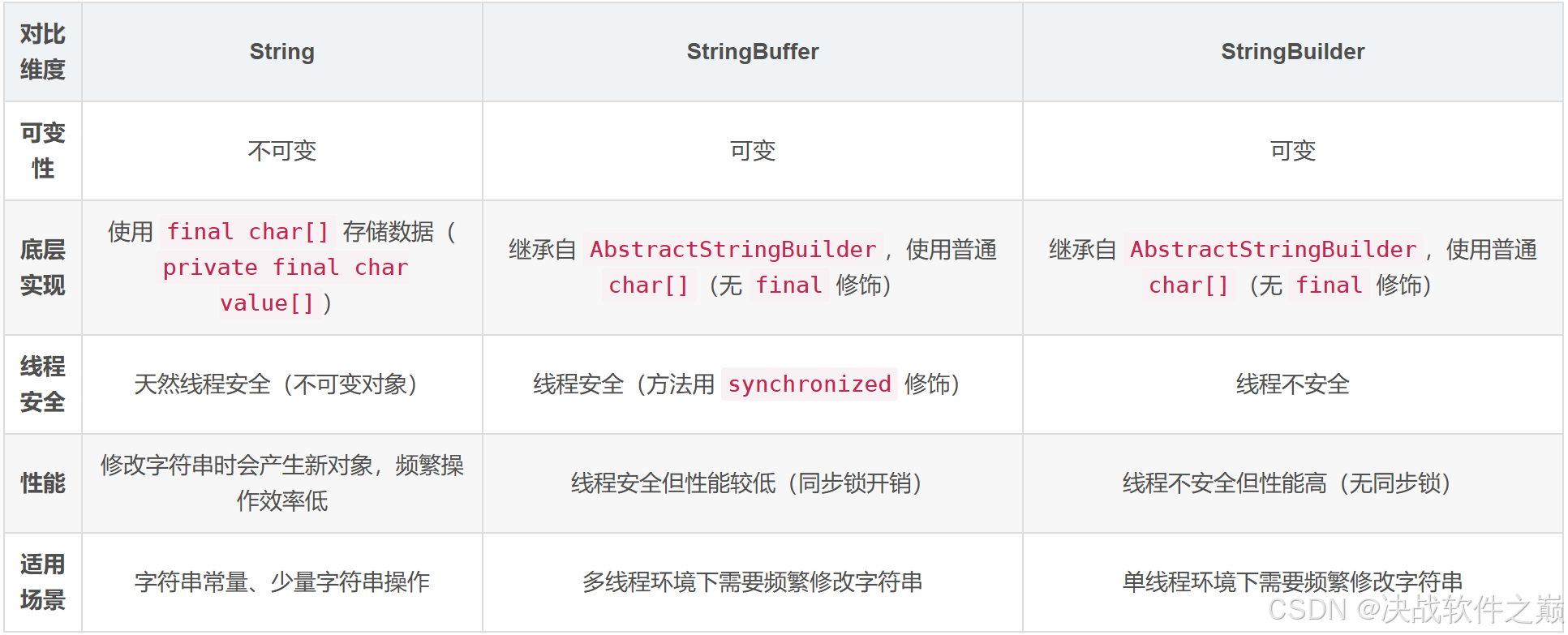
StringBuilder与StringBuffer可变性
StringBuilder与StringBuffer都继承自AbstractStringBuilder类,在AbstractStringBuilder中也是使用字符数组保存字符串char[] value, 但是没有用 final 关键字修饰,所以这两种对象都是可变的。
StringBuilder与StringBuffer 的构造方法都是调用父类构造方法也就是AbstractStringBuilder 实现的。
abstract class AbstractStringBuilder implements Appendable, CharSequence {
char[] value;
int count;
AbstractStringBuilder() {
}
AbstractStringBuilder(int capacity) {
value = new char[capacity];
}
String不可变的原因
底层数组被 final 修饰
String 内部通过 private final char value[] 存储字符数据,final 关键字保证数组引用不可变,且外部无法直接修改数组内容。
设计安全性
不可变性保证了字符串在哈希计算(如 HashMap 的键)、线程安全、网络传输等场景下的安全性。
字符串常量池优化:不可变特性允许 JVM 缓存字符串字面量,减少内存重复分配。
防止继承破坏
String 类本身被声明为 final,避免子类通过继承覆盖其方法,破坏不可变性。
线程安全性
String 中的对象是不可变的,也就可以理解为常量,线程安全。AbstractStringBuilder 是 StringBuilder 与StringBuffer 的公共父类,定义了一些字符串的基本操作,如 expandCapacity、append、insert、indexOf 等公共方法。
StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder 并没有对方法进行加同步锁,所以是非线程安全的。
性能
每次对 String 类型进行改变的时候,都会生成一个新的 String 对象,然后将指针指向新的 String 对象。StringBuffer 每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。
相同情况下使用StringBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
总结:优先使用 String 处理常量或少量修改;多线程频繁操作用 StringBuffer;单线程频繁操作用 StringBuilder。
4.2 Integer类的特性
4.3 Object类的常见方法
Object类是一个特殊的类,是所有类的父类。
public final native Class<?> getClass()
native方法,用于返回当前运行时对象的Class对象,使用了final关键字修饰,故不允许子类重写。
public native int hashCode()
native方法,用于返回对象的哈希码,主要使用在哈希表中,比如JDK中的HashMap。
public boolean equals(Object obj)
用于比较2个对象的内存地址是否相等,String类对该方法进行了重写用户比较字符串的值是否相等。
protected native Object clone() throws CloneNotSupportedException
naitive方法,用于创建并返回当前对象的一份拷贝。一般情况下,对于任何对象 x,表达式 x.clone() != x 为true,x.clone().getClass()== x.getClass() 为true。Object本身没有实现Cloneable接口,所以不重写clone方法并且进行调用的话会发生CloneNotSupportedException异常。
public String toString()
返回类的名字@实例的哈希码的16进制的字符串。建议Object所有的子类都重写这个方法。
public final native void notify()
native方法,并且不能重写。唤醒一个在此对象监视器上等待的线程(监视器相当于就是锁的概念)。如果有多个线程在等待只会任意唤醒一个。
public final native void notifyAll()
native方法,并且不能重写。跟notify一样,唯一的区别就是会唤醒在此对象监视器上等待的所有线程,而不是一个线程。
public final native void wait(long timeout) throws InterruptedException
native方法,并且不能重写。暂停线程的执行。注意:sleep方法没有释放锁,而wait方法释放了锁 。timeout是等待时间。
public final void wait(long timeout, int nanos) throws InterruptedException
多了nanos参数,这个参数表示额外时间(以毫微秒为单位,范围是 0-999999)。 所以超时的时间还需要加上nanos毫秒。
public final void wait() throws InterruptedException
跟之前的2个wait方法一样,只不过该方法一直等待,没有超时时间这个概念。
protected void finalize() throws Throwable { }
实例被垃圾回收器回收的时候触发的操作。
五、Java异常处理
5.1 异常处理的基本体系
在Java中,异常处理是一种非常重要的机制,它允许程序在运行时处理错误或异常情况,而不是直接崩溃。Java提供了异常处理的基本体系,包括以下几个关键概念:
1. 异常类型
Java中的异常可以分为两大类:
检查型异常(Checked Exceptions):这些异常在编译时期被检查。例如,IOException,SQLException等。
非检查型异常(Unchecked Exceptions):这些异常包括运行时异常(RuntimeException及其子类)和错误(Error)。例如,NullPointerException,ArrayIndexOutOfBoundsException,IllegalArgumentException等。
2. 异常的层次结构
所有的异常都继承自java.lang.Exception类(检查型异常)或者java.lang.RuntimeException类(非检查型异常)。错误(Error)通常不是由程序直接处理的,而是由JVM处理的。
3. 异常处理机制
Java通过try-catch-finally语句来处理异常。
try-catch 语句
try {
// 可能会抛出异常的代码
} catch (ExceptionType1 e1) {
// 处理ExceptionType1类型的异常
} catch (ExceptionType2 e2) {
// 处理ExceptionType2类型的异常
} finally {
// 无论是否发生异常,都会执行的代码
}
try-with-resources 语句(Java 7+)
用于自动管理资源,如流、文件等,确保它们在使用后能够被正确关闭。
try (Resource res = new Resource()) {
// 使用资源
} catch (Exception e) {
// 处理异常
}
这里的Resource必须实现AutoCloseable或Closeable接口。
4. 抛出异常
可以使用throw关键字抛出异常。
if (someCondition) {
throw new ExceptionType("错误信息");
}
5. 自定义异常
可以通过继承Exception类或其子类来创建自定义异常。
public class CustomException extends Exception {
public CustomException(String message) {
super(message);
}
}
然后可以在代码中抛出或捕获这个自定义异常。
6. 注意事项
不要捕获然后忽略异常:这会导致潜在的问题不被发现。应该至少记录日志或在捕获块中做一些恢复尝试。
不要捕获所有异常:除非有特定的理由,否则应该捕获具体的、已知的异常类型。捕获Exception或Throwable是不好的做法,除非你知道自己在做什么。
使用资源时总是使用try-with-resources:这样可以避免资源泄露。
通过以上机制,Java的异常处理体系提供了一种灵活而强大的方式来处理程序中的错误情况,从而增强程序的健壮性和可维护性。
5.2 异常处理的方式
在Java中,异常处理是一种非常重要的机制,它允许开发者在程序运行期间捕捉和处理错误,从而避免程序崩溃。Java提供了多种方式来处理异常,包括使用try-catch块、throws关键字、以及自定义异常类。下面是一些基本的异常处理方式:
1. 使用try-catch块
try-catch块是处理异常的最基本方式。你可以在try块中放置可能抛出异常的代码,然后在catch块中捕获并处理这些异常。
try {
// 可能会抛出异常的代码
int result = 10 / 0;
} catch (ArithmeticException e) {
// 处理ArithmeticException异常
System.out.println("发生除以零的错误: " + e.getMessage());
} catch (Exception e) {
// 处理其他类型的异常
System.out.println("发生其他类型的错误: " + e.getMessage());
} finally {
// 无论是否发生异常,finally块中的代码都会执行
System.out.println("清理资源...");
}
2. 使用throws关键字
如果你不想在方法内部处理异常,而是希望调用者处理,你可以在方法签名中使用throws关键字声明该方法可能抛出的异常。
public void myMethod() throws IOException {
// 可能抛出IOException的代码
throw new IOException("文件未找到");
}
调用这个方法时,你需要处理或者继续向上抛出这个异常。
public static void main(String[] args) {
try {
myMethod();
} catch (IOException e) {
System.out.println("捕获到异常: " + e.getMessage());
}
}
3. 自定义异常类
Java允许你自定义异常类。这通常是通过继承标准异常类(如Exception或其子类)来实现的。
class MyCustomException extends Exception {
public MyCustomException(String message) {
super(message);
}
}
使用自定义异常:
public void checkCondition() throws MyCustomException {
if (someConditionIsNotMet) {
throw new MyCustomException("条件未满足");
}
}
4. 使用try-with-resources语句(Java 7及以上)
对于实现了AutoCloseable接口的资源(如文件流、数据库连接等),可以使用try-with-resources语句来自动管理资源,即使在发生异常的情况下也能确保资源被正确关闭。
try (Scanner scanner = new Scanner(new File("somefile.txt"))) {
while (scanner.hasNext()) {
System.out.println(scanner.nextLine());
}
} catch (FileNotFoundException e) {
System.out.println("文件未找到: " + e.getMessage());
} // try-with-resources会自动关闭scanner资源,即使在发生异常的情况下。
以上是Java中处理异常的几种主要方式。通过合理使用这些机制,你可以编写更加健壮和可靠的程序。
5.3 异常处理的应用场景
在Java中,异常处理是一种非常重要的编程实践,它允许程序在遇到错误、异常情况时能够优雅地处理这些问题,而不是直接崩溃。异常处理的应用场景非常广泛,以下是一些常见的应用场景:
资源管理:
当处理文件、数据库连接、网络通信等资源时,如果在操作过程中发生异常,应该确保这些资源被正确关闭或释放。例如,使用try-with-resources语句可以自动管理资源,确保即使在发生异常时也能释放资源。
try (BufferedReader br = new BufferedReader(new FileReader("file.txt"))) {
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}
数据验证:
在处理用户输入或外部数据时,验证数据的有效性是非常重要的。如果数据不符合预期格式或范围,可以通过抛出或捕获异常来处理这种情况。
try {
int number = Integer.parseInt("abc");
} catch (NumberFormatException e) {
System.out.println("Invalid number format.");
}
网络通信:
在进行网络请求或响应时,可能会遇到各种网络异常,如连接超时、服务器错误等。通过异常处理可以优雅地处理这些情况,比如重试请求或返回错误信息给用户。
try {
URL url = new URL("http://example.com");
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.connect();
// 处理响应等
} catch (IOException e) {
System.out.println("Failed to connect.");
}
数据库操作:
在数据库操作中,如查询、更新或插入数据时,可能会遇到SQL异常。使用异常处理可以帮助捕获这些错误,并进行相应的错误处理或回滚事务。
try (Connection conn = DriverManager.getConnection(url, username, password)) {
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM users");
// 处理结果集等
} catch (SQLException e) {
e.printStackTrace();
}
算法错误处理:
在实现算法时,如果输入不符合预期(例如数组越界、空指针引用等),应该通过异常来通知调用者发生了错误。
public void processArray(int[] array) {
try {
for (int i = 0; i <= array.length; i++) { // 故意造成数组越界错误
System.out.println(array[i]);
}
} catch (ArrayIndexOutOfBoundsException e) {
System.out.println("Array index out of bounds.");
}
}
业务逻辑错误:
在业务逻辑中,如果某些条件不满足(例如余额不足进行转账),可以通过自定义异常来更精确地控制业务逻辑流程。
public class InsufficientFundsException extends Exception {
public InsufficientFundsException(String message) {
super(message);
}
}
使用时:
try {
if (balance < amount) {
throw new InsufficientFundsException("Insufficient funds.");
} else {
// 转账逻辑等
}
} catch (InsufficientFundsException e) {
System.out.println(e.getMessage());
}
通过以上示例可以看出,Java的异常处理机制非常灵活且强大,它不仅可以帮助开发者在程序出错时进行调试和错误追踪,还能使程序更加健壮和易于维护。合理使用异常处理机制是提高代码质量和用户体验的重要手段。
六、Java序列化
6.1 序列化的概念
在Java中,序列化是将对象的状态信息转换为可以存储或传输的格式的过程。这个过程通常用于将对象保存到文件系统、数据库或者通过网络发送对象。Java提供了java.io.Serializable接口来实现序列化。
序列化的步骤
实现Serializable接口:要使一个类可被序列化,该类必须实现java.io.Serializable接口。这个接口是一个标记接口,即它不包含任何方法,只用于表明类的对象可以被序列化。
import java.io.Serializable;
public class Employee implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private int age;
// 构造方法、getter和setter省略
}
序列化对象:使用ObjectOutputStream将对象写入文件或输出流。
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
public class SerializeExample {
public static void main(String[] args) {
Employee emp = new Employee();
emp.setName("John Doe");
emp.setAge(30);
try (FileOutputStream fileOut = new FileOutputStream("employee.ser");
ObjectOutputStream out = new ObjectOutputStream(fileOut)) {
out.writeObject(emp);
System.out.println("Employee object has been serialized.");
} catch (IOException i) {
i.printStackTrace();
}
}
}
反序列化对象:使用ObjectInputStream从文件或输入流读取对象。
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
public class DeserializeExample {
public static void main(String[] args) {
Employee emp = null;
try (FileInputStream fileIn = new FileInputStream("employee.ser");
ObjectInputStream in = new ObjectInputStream(fileIn)) {
emp = (Employee) in.readObject();
} catch (IOException i) {
i.printStackTrace();
return;
} catch (ClassNotFoundException c) {
System.out.println("Employee class not found");
c.printStackTrace();
return;
}
System.out.println("Deserialized Employee...");
System.out.println("Name: " + emp.getName());
System.out.println("Age: " + emp.getAge());
}
}
注意事项和最佳实践
serialVersionUID:在实现Serializable接口的类中定义一个serialVersionUID常量,这是一个版本控制机制,确保序列化对象的版本兼容性。如果类结构发生变化,更改serialVersionUID可以避免反序列化时出现InvalidClassException。
安全性:尽管Java序列化提供了便利,但也存在安全风险,例如反序列化恶意构造的数据可能执行恶意代码(反序列化漏洞)。为了增强安全性,可以考虑使用外部化(Externalizable)接口代替Serializable,或者使用Java的序列化过滤器。
性能考虑:虽然序列化和反序列化提供了很大的便利,但在性能敏感的应用中,频繁的序列化和反序列化可能会成为性能瓶颈。在这种情况下,考虑使用更轻量级的数据交换格式如JSON或Protocol Buffers。
通过这些步骤和注意事项,你可以有效地在Java中使用序列化和反序列化技术来存储和传输对象状态。
6.2 序列化的类型
-
Java原生序列化:这是Java标准库提供的一种序列化技术,通过实现
java.io.Serializable接口来实现。Java原生序列化可以将Java对象转换为字节流进行传输和存储,但其性能和兼容性存在一些问题1。 -
JSON序列化:JSON是一种轻量级的数据交换格式,广泛用于前后端交互。在Java中,可以使用Gson、Jackson等第三方库实现JSON序列化。JSON序列化具有高可读性、跨平台和跨语言支持的良好特性,但体积相对较大,包含较多冗余内容12。
-
XML序列化:XML是一种常用的数据交换格式,可以通过JAXB等工具实现XML序列化。XML序列化适用于需要严格数据结构的场景,但其体积较大,解析效率较低1。
-
Protocol Buffers序列化:由Google开发,是一种高效的数据交换格式。Protocol Buffers可以将结构化数据序列化为二进制格式,具有高效、可扩展、跨语言等优点。在Java中,可以使用Google提供的protobuf-java库实现Protocol Buffers序列化1。
-
Kryo序列化:Kryo是一种高效的序列化框架,适用于需要高性能序列化的场景。Kryo序列化速度快,体积小,但不如原生序列化兼容性好1。
应用场景:
- 跨平台传输:JSON和Protocol Buffers适用于跨平台的数据交换,因为它们具有良好的跨语言支持。
- 高效存储和传输:Protocol Buffers和Kryo在处理大量数据时表现出色,适合需要高性能序列化的场景。
- 数据持久化:所有这些序列化方式都可以用于对象的持久化存储,但选择时应考虑数据的可读性、兼容性和性能需求。
七、Java网络编程
7.1 Socket套接字
<在Java中,使用Java Socket进行网络编程是一种常见且强大的方式。Java Socket编程允许你创建客户端和服务器,以便在不同的计算机之间进行通信。下面是一些基本概念和步骤,帮助你了解如何使用Java Socket。
1. 服务器端
服务器端需要做的第一件事是创建一个ServerSocket对象,并绑定到某个端口上。然后,它可以通过accept()方法监听连接请求。一旦有客户端连接,accept()方法将返回一个Socket对象,你可以通过这个Socket对象与客户端进行通信。
import java.io.*;
import java.net.*;
public class Server {
public static void main(String[] args) {
int port = 12345; // 定义端口号
try (ServerSocket serverSocket = new ServerSocket(port)) {
System.out.println("服务器启动,监听端口:" + port);
Socket clientSocket = serverSocket.accept(); // 等待客户端连接
System.out.println("客户端已连接");
// 通过输入流读取客户端发送的数据
BufferedReader in = new BufferedReader(new InputStreamReader(clientSocket.getInputStream()));
String inputLine;
while ((inputLine = in.readLine()) != null) {
System.out.println("收到客户端消息:" + inputLine);
// 可以根据需要回复客户端
PrintWriter out = new PrintWriter(clientSocket.getOutputStream(), true);
out.println("服务器回应:" + inputLine);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
2. 客户端
客户端首先需要创建一个Socket对象,连接到服务器端的指定IP地址和端口。然后,客户端可以通过这个Socket对象的输入输出流与服务器进行通信。
import java.io.*;
import java.net.*;
public class Client {
public static void main(String[] args) {
String hostname = "localhost"; // 服务器地址
int port = 12345; // 服务器端口号
try (Socket socket = new Socket(hostname, port)) {
System.out.println("已连接到服务器");
// 向服务器发送数据
PrintWriter out = new PrintWriter(socket.getOutputStream(), true);
out.println("你好,服务器!");
// 从服务器读取响应
BufferedReader in = new BufferedReader(new InputStreamReader(socket.getInputStream()));
String response;
while ((response = in.readLine()) != null) {
System.out.println("收到服务器消息:" + response);
}
} catch (UnknownHostException e) {
System.err.println("找不到服务器");
e.printStackTrace();
} catch (IOException e) {
System.err.println("I/O 错误");
e.printStackTrace();
}
}
}
3. 异常处理和资源管理
在Java中,推荐使用try-with-resources语句来自动管理资源,例如ServerSocket和Socket对象。这样可以确保在操作完成后自动关闭这些资源,避免资源泄露。
4. 多线程处理多个客户端连接
为了处理多个客户端连接,服务器通常需要为每个连接创建一个新的线程。这可以通过实现一个线程池或者为每个连接创建一个新的线程来实现。例如,可以使用java.util.concurrent包中的ExecutorService来管理线程。
ExecutorService executor = Executors.newFixedThreadPool(10); // 创建固定大小的线程池
while (true) {
final Socket clientSocket = serverSocket.accept(); // 接受客户端连接
executor.execute(() -> handleClient(clientSocket)); // 为每个连接创建一个新任务并执行它
}
executor.shutdown(); // 在服务器关闭时关闭线程池
在handleClient方法中,你可以像前面示例中那样处理每个客户端的输入输出流。
总结
通过以上步骤,你可以在Java中实现基本的客户端-服务器通信。记得处理异常和资源管理是确保程序稳定运行的关键部分。对于更复杂的应用场景,可以考虑使用框架如Netty来简化网络编程工作。
7.2 RPC框架(扩展)
在Java中实现RPC(远程过程调用)框架,有多种方法和库可以选择,每种方法都有其特点和适用场景。下面我将介绍几种常见的RPC框架和一些扩展方法:
1. 使用成熟的RPC框架
1.1 Apache Dubbo
Dubbo 是一个高性能、轻量级的开源Java RPC框架。它提供了丰富的功能,如服务治理、负载均衡、容错等。
特点:
支持多种通信协议(如 Dubbo、HTTP、REST等)。
提供了服务治理功能,如服务注册与发现、负载均衡、容错处理等。
易于扩展和集成。
使用示例:
<!-- pom.xml -->
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo</artifactId>
<version>2.7.8</version>
</dependency>
服务提供者:
@Service(version = "1.0.0")
public class GreetingServiceImpl implements GreetingService {
@Override
public String sayHello(String name) {
return "Hello, " + name;
}
}
服务消费者:
@Reference(version = "1.0.0")
private GreetingService greetingService;
1.2 gRPC
gRPC 是由Google开发的一个高性能、开源和通用的RPC框架。它基于HTTP/2协议,支持多种语言。
特点:
支持多种语言。
使用Protocol Buffers作为接口定义语言(IDL)。
提供了负载均衡、认证等高级功能。
使用示例:
<!-- pom.xml -->
<dependency>
<groupId>io.grpc</groupId>
<artifactId>grpc-netty-shaded</artifactId>
<version>1.34.1</version>
</dependency>
<dependency>
<groupId>io.grpc</groupId>
<artifactId>grpc-protobuf</artifactId>
<version>1.34.1</version>
</dependency>
<dependency>
<groupId>io.grpc</groupId>
<artifactId>grpc-stub</artifactId>
<version>1.34.1</version>
</dependency>
定义服务:
syntax = "proto3";
package example;
service Greeter {
rpc SayHello (HelloRequest) returns (HelloReply) {}
}
message HelloRequest {
string name = 1;
}
message HelloReply {
string message = 1;
}
2. 自定义RPC框架扩展方法
如果你需要更灵活的控制或者特定的需求,可以考虑实现一个自定义的RPC框架。以下是一些扩展方法:
2.1 网络通信协议选择(如TCP/UDP)
选择合适的网络通信协议,例如TCP或UDP,根据性能需求和服务类型。TCP通常用于可靠的数据传输,而UDP则适用于实时性要求高的场景。
2.2 序列化与反序列化技术(如JSON、Protocol Buffers)
选择合适的序列化技术来高效地传输数据。Protocol Buffers和JSON是常用的选择,它们各有优缺点。Protocol Buffers在性能上通常优于JSON。
2.3 负载均衡与容错策略实现(如随机、轮询、重试)
实现负载均衡算法和容错策略,例如轮询、随机、最少连接等,以及重试机制和超时设置。
2.4 服务注册与发现机制(如ZooKeeper、Consul)
使用服务注册中心来管理服务的生命周期,如ZooKeeper或Consul,实现服务的自动发现和注册。
3. 示例代码 - 自定义RPC框架的简化版本:
以下是一个非常简化的自定义RPC服务端和客户端示例:
// 服务端代码示例(简化版)省略细节...
// 客户端代码示例(简化版)省略细节...
在实际开发中,你需要详细设计并实现网络通信、序列化、服务注册与发现等功能。这通常涉及到多线程编程、网络编程等较复杂的操作。对于复杂的项目,考虑使用成熟的框架会更加高效和稳定。