【Redis——通用命令】
文章目录
- Redis为什么快?
- 生产环境的概念
- Redis中最核心的两个命令
- get:通过key拿value
- set:将key和value存入数据库
- 其他通用命令
- keys
- exist判定key是否存在
- del
- expire:为指定的key设置一个过期时间TTL(Time To Live)
- ttl:查看指定key的过期时间
- Redis的key的过期策略
- type命令:返回key对应的value的数据类型
Redis为什么快?

启动redis的方式:(可以通过redis的配置文件,将redis服务器设置成守护进程(后台进程))
redis-server /etc/redis/redis.conf
systemctl start redis(需要centos8以上)
停止redis
ps aux | grep redis :查看redis服务器的进程pid
kill -9 + pid
第二种方法:(需要centos8以上)
systemctl stop redis
生产环境的概念

Redis中最核心的两个命令
redis是按照键值对的方式存储数据的。
key和value都是字符串。
redis命令不区分大小写。
get:通过key拿value
输入一个key,返回对应的value,如果key不存在,返回nil(跟nullptr/NULL一个意思)
set:将key和value存入数据库
其他通用命令
由于Redis支持多种数据结构,所以,key是固定的字符串,但是value实际上会有很多种类型:字符串,哈希表,列表,集合,有序集合。
所以操作不同的数据结构,就能使用同一个命令来操作,就叫通用命令(全局命令)
keys
- 1)keys pattern
?:匹配任意一个字符
*:匹配0个或多个任意字符
[aeb] :只能匹配到a e b ,别的不行。相当于给固定选项。
[^e]:排除e,除了e之外,其他都能匹配。相当于排除错误答案。
[a-e]:匹配a到e范围内的字符,包括a和e。
注意事项:
keys命令的时间复杂度O(n)
keys *:这个操作上大杀器,遍历整个Redis存储数据。

exist判定key是否存在
exists key key key…(这些key可以是1个,可以是多个)
返回值:返回key存在的个数。
针对多个key来说,是非常有用的。
时间复杂度O(1):检查几个key,这个时间复杂度就是O几。
注意一个问题:
先set hello 1
set hbllo 1
然后执行
exists hello
exists hbllo
和
exists hello hbllo
两者的查询有什么区别??
区别非常大!!
记住一句话:redis是一个客户端-服务器结构的程序!!
而客户端和服务器之间,是通过网络进行通信的!!
执行两次exists命令,相当于客户端发送两次网络请求给服务器。
只执行一次exists命令,只发送一次网络请求。
发一次数据,要从应用层开始往下经过每一层都要进行一次协议封装。
然后通过路由器发送到目的IP主机,再层层解封到上层,解析处理好数据后,同样需要封装好响应发送回给请求主机。
del
del key key key …
删除一个或者多个key。
时间复杂度O(1),删除几个key,时间复杂度就是O几。
返回值:删除掉的key个数
注意事项:

expire:为指定的key设置一个过期时间TTL(Time To Live)
expire key 秒数
返回1表示成功,0失败
所以,要想成功,key必须存在。
还有一个命令:pexpire:,这个也是给一个key设置过期时间,只不过单位是ms(毫秒)
ttl:查看指定key的过期时间
ttl key
返回剩余的过期时间(秒),返回-1表示这个key没有设置过期时间,一直存在,返回-2表示key不存在
所以这个指令可以配合expire使用。
同理,pttl:返回的是毫秒,其他的都一样。
Redis的key的过期策略
经典面试题:redis服务器如何知道哪些key已经过期要被删除,哪些key还没过期?
redis的策略:
1.定期删除
每次抽取一部分key,验证过期时间,这相当于有一个while循环检查过期时间,但是要保证验证过期时间要快!因为redis是单线程程序,主要的任务就是处理命令,如果检查一部分key的过期时间这个动作占用太长时间,就会导致出现像keys *这样的操作,正常处理命令的任务就被阻塞了。
2.惰性删除
假设这个key已经到过期时间了,但是还没删除它,这个key还存在。紧接着,后面一次访问,用到了这个key,于是这次访问就会让服务器删除这个key,同时再返回nil。(这个机制有点像懒汉模式实现单例)
虽然有了上述两种策略,但是仍然可能有很多过期的key被残留了,没有及时删除掉。
Redis为了对上述补充,提供了一系列的内存淘汰策略,具体后面讲。

虽然redis没有采用定时器的方案作为过期策略,但是还是要学习一下定时器的设置的。
定时器的实现原理:
1.基于优先级队列/堆

假设此时来了三个key,设置过期时间分别是12:00,13:00,14:00,此时是11点整。
此时只需要分配一个线程负责定时器的模块,让这个定时器去检查堆的堆顶即可。
如果堆顶的key没过期,那堆中的其他每个key都不会过期。此时就可以让该线程去休眠,然后在快到12点时唤醒该线程即可。(休眠时间=过期时间 - 当前时间)

但是,万一在线程休眠期间,来了个新任务,是要11:30执行,怎么办?
其实可以在新任务添加进定时器(优先级队列/堆)时,唤醒一下刚才的线程,重新检查堆顶元素,然后调整一下休眠时间即可。
2.基于时间轮实现的定时器(我的项目中就是采用这种方案)
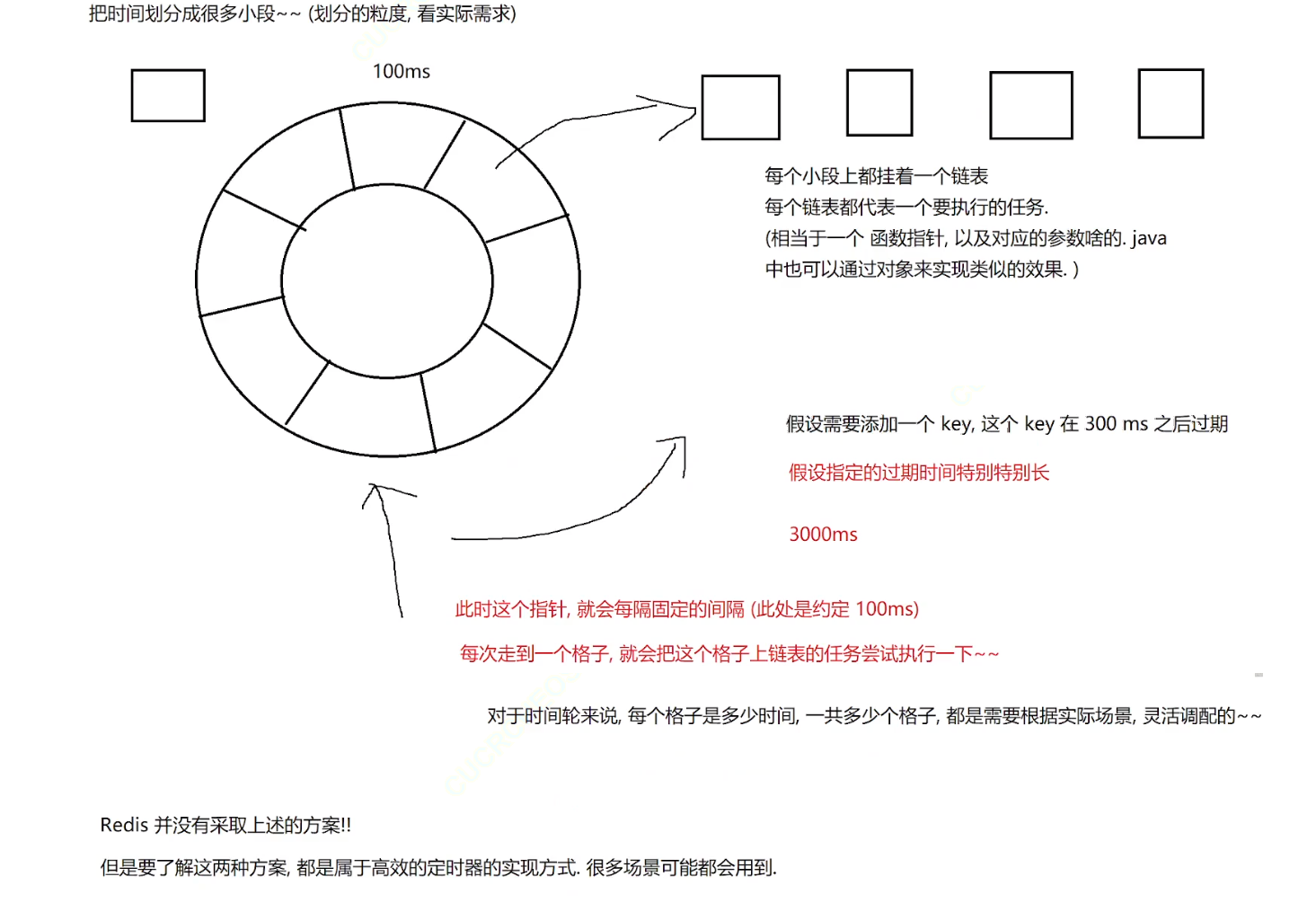
假设我的时间轮大小就是5个格子,每个格子代表每过100ms就走一格,此时来了个要定时3000ms的定时任务,格子不够放,就会重新循环遍历,直到数到第30个格子,然后将该定时任务链接到格子的链表后,每当指针走到这个格子时,回去判断第一个链表是否过期,如果没过期,就继续往后走。(链表的第一个节点如果没过期,那后面的节点就不会过期。像优先级队列一样)
虽然redis没有采取上面两种实现方案,但在其他地方也是高频出现的作为定时器设置的方案。
type命令:返回key对应的value的数据类型
要知道,key的数据类型都是string,而value的数据类型可能不是。

时间复杂度:O(1),跟获取key对应的value的时间复杂度没什么区别。