Redis数据结构SDS,IntSet,Dict
1.字符串:SDS
SDS的底层是C语言编写的构建的一种简单动态字符串 简称SDS,是redis比较常见的数据结构。
由于以下几种缺点,Redis并没有直接采用C语言的字符串。
1.获取长度需要计算
2.非二进制安全 :中间不能有 \0,否则就中断。
3.不可修改 :char * s = "hello"

在这里Redis会在底层的创建两个SDS,一个是 “key” 的SDS ,一个是value。
由于不能直接采用C语言字符串,所以采用了一个结构体。

注意:len的比特位数每一位就是单位是字节
举例:对于name字符串来说,redis底层的SDS结构体中,长度是4字节,向内存申请的字节数是4字节,flags则表示不同的编码格式。
编码格式有什么作用?
核心目的是优化内存使用 和 操作效率 对于不同长度的字符串可以使用不同的头结构。

1.1.为什么叫做动态字符串
因为它具备动态扩容能力,好比一个 “hy”字符串的SDS
| len:2 | alloc:2 | flags:1 | h | y | \0 |
如果要给它追加字符”Boy“,那么它首先会申请新的内存空间
如果新的字符串空间 < 1M,那么新空间是扩展后的2倍+1
如果新的字符串空间 > 1M,那么新空间是扩展后字符串长度 + 1M + 1
这个就是内存预分配。
| len:5 | alloc:11 | flags:1 | h | y | B | o | y | \0 |
优点:
1.获取字符串的长度时间复杂度为O(1)
2.支持动态扩容
3.二进制安全(中间可以有\0存在)
4.减少内存分配次数
2.IntSet
IntSet是Redis中集合的一种实现方式,基于整数数组来实现,并且具备长度可变,有序的特征。

encoding包含三种工作模式,表示储存的整数大小不同:
分别可储存2字节整数,4字节整数,8字节整数。
如果IntSet中储存三个数那么它的储存结构应该是这样的:采用默认的encoding,每个数字2字节
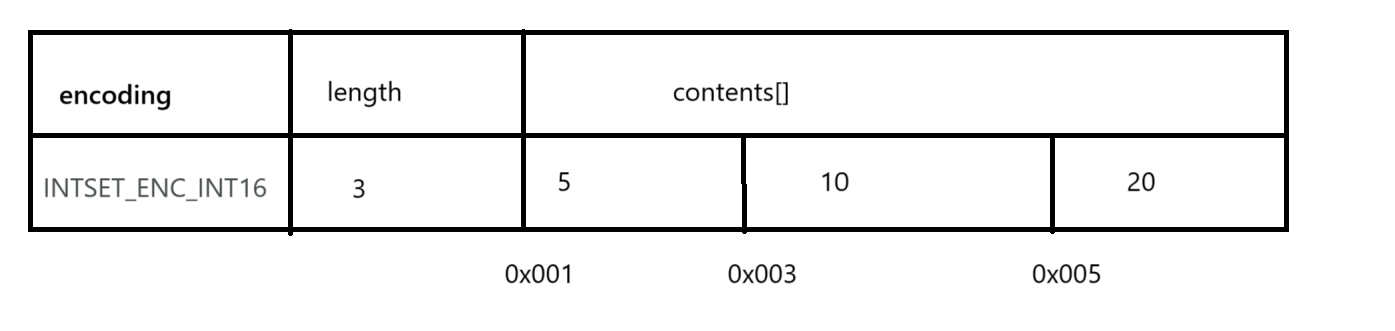
length大小是元素的个数,contents数组保存元素。
2.1.inset如何保存大于当前编码的最大数字?
当encoding采用int16_t 也就是2个字节大小来存放每个数字,所以每个数字不应该超过两个字节,最大是32767。当存下99999时会升级编码的方式去找到合适大小.
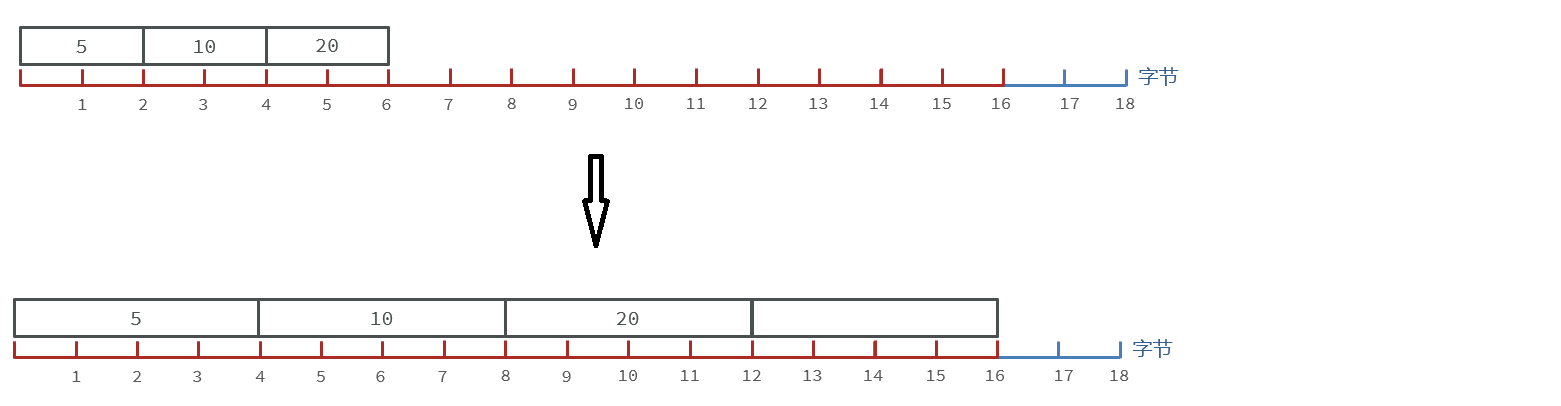
如图是升级编码前后的contents数组占用空间大小的情况
1.升级编码到INT_32,每个数字占4字节
2.依次将每个元素向后拷贝到正确的位置
3.将要添加的元素放入末尾
4.最后将encoding的属性改为INT_32,length的值更新。
源码:
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {uint8_t valenc = _intsetValueEncoding(value);// 获取当前值编码uint32_t pos; // 要插入的位置if (success) *success = 1;// 判断编码是不是超过了当前intset的编码if (valenc > intrev32ifbe(is->encoding)) {// 超出编码,需要升级return intsetUpgradeAndAdd(is,value);} else {// 在当前intset中查找值与value一样的元素的角标posif (intsetSearch(is,value,&pos)) {if (success) *success = 0; //如果找到了,则无需插入,直接结束并返回失败return is;}// 数组扩容is = intsetResize(is,intrev32ifbe(is->length)+1);// 移动数组中pos之后的元素到pos+1,给新元素腾出空间if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1);}// 插入新元素_intsetSet(is,pos,value);// 重置元素长度is->length = intrev32ifbe(intrev32ifbe(is->length)+1);return is;
}
static intset* intsetUpgradeAndAdd(intset* is, int64_t value) {// 获取当前intset编码uint8_t curenc = intrev32ifbe(is->encoding);// 获取新编码uint8_t newenc = _intsetValueEncoding(value);// 获取元素个数int length = intrev32ifbe(is->length);// 判断新元素是大于0还是小于0 ,小于0插入队首、大于0插入队尾int prepend = value < 0 ? 1 : 0;// 重置编码为新编码is->encoding = intrev32ifbe(newenc);// 重置数组大小is = intsetResize(is, intrev32ifbe(is->length) + 1);// 倒序遍历,逐个搬运元素到新的位置,_intsetGetEncoded按照旧编码方式查找旧元素while (length--) // _intsetSet按照新编码方式插入新元素_intsetSet(is, length + prepend, _intsetGetEncoded(is, length, curenc));/* 插入新元素,prepend决定是队首还是队尾*/if (prepend)_intsetSet(is, 0, value);else_intsetSet(is, intrev32ifbe(is->length), value);// 修改数组长度is->length = intrev32ifbe(intrev32ifbe(is->length) + 1);return is;
}总结:
1.InSet确保元素唯一,有序
2.具备类型升级,可以节省空间
3.底层采用二分查找来查询元素
4.如果数组过长,扩容时移动元素效率不高
3.Dict
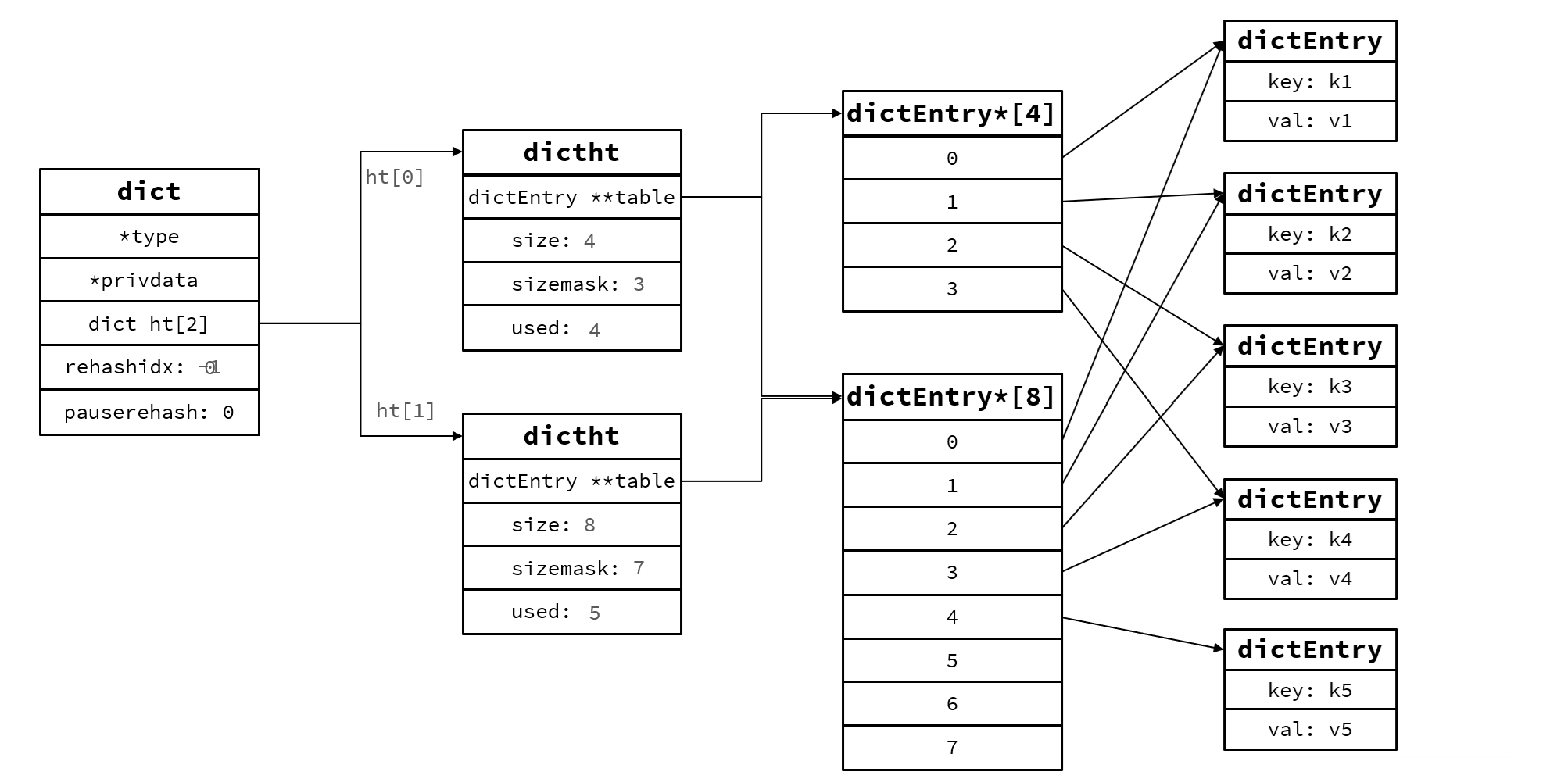
Redis是一种键-值型的数据库,那么键和值间关系的维护就要靠Dict维护。
Dict是由三部分组成,分别是哈希表(DictHashTable) ,哈希节点(DictEntry),字典(Dict)


当向Dict添加键值对时,Redis首先根据key计算哈希值(h),然后利用 h & sizemask(图上掩码)计算出元素应放索引的位置,假设哈希值 h = 1, 则 1 & 3 = 1, 因此储存到角标1位
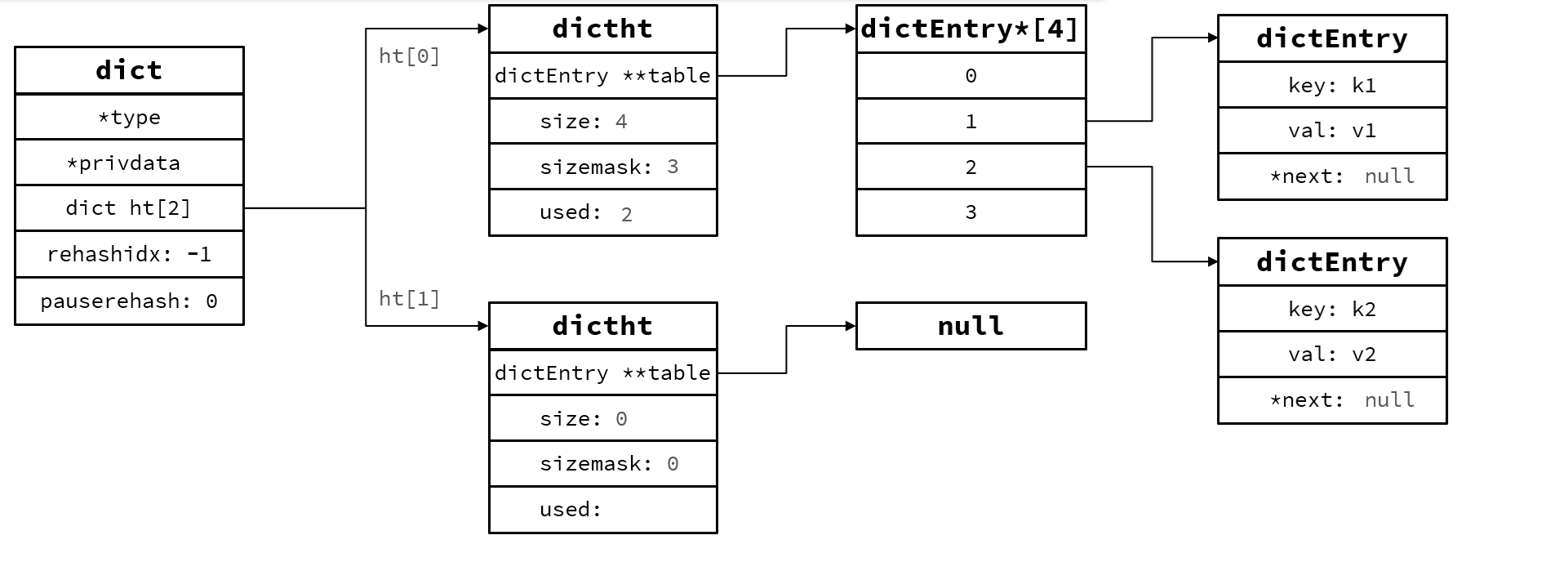
一个Dict包含两个hash表,其中一个一般是空,rehash才使用,比如负载因子超过阈值,扩展,收缩,初始化时使用。
3.1Dict的扩容
DIct中的HashTable就是数组结合单项链表实现,当集合中的元素过多必然导致hash冲突,同时链表过长hash的查询效率也会越来越低。
每次新增键值都会查询负载因子(LoadFactor = used / size)
1.如果LoadFactor >= 1 同时服务器没有执行BGSAVE/BGREWRITEAOF等后台进程。
2.哈希表的LoadFactor > 5,此时就算后台执行进程也会强制扩容。
扩容的大小为used + 1,以下是扩容操源码
static int _dictExpandIfNeeded(dict *d){// 如果正在rehash,则返回okif (dictIsRehashing(d)) return DICT_OK; // 如果哈希表为空,则初始化哈希表为默认大小:4if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);// 当负载因子(used/size)达到1以上,并且当前没有进行bgrewrite等子进程操作// 或者负载因子超过5,则进行 dictExpand ,也就是扩容if (d->ht[0].used >= d->ht[0].size &&(dict_can_resize || d->ht[0].used/d->ht[0].size > dict_force_resize_ratio){// 扩容大小为used + 1,底层会对扩容大小做判断,实际上找的是第一个大于等于 used+1 的 2^nreturn dictExpand(d, d->ht[0].used + 1);}return DICT_OK;
}
首先判断是否正在rehash 是就返回ok,否则向下执行。如果哈希表是空的就会初始化4个单位,
如果负载因子 >= 1 ,并且没有进行后台进程 或者 负载因子>= 5. 开始进行扩容。
3.2Dict的收缩
DIct除扩容之外还可以 收缩,每次执行删除后如果 负载因子 < 0.1 就会执行。
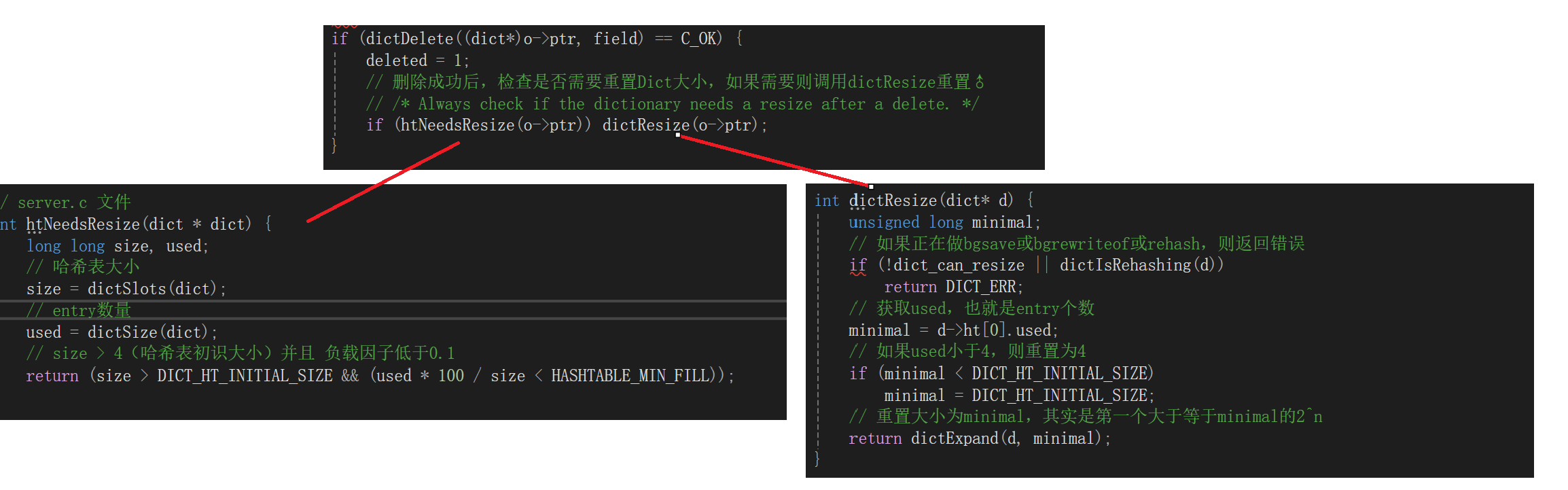
3.3.rehash
不管是扩容还是收缩,每次变化都会导致size 和 sizemask(掩码)变化,而key的查询与sizemask有关。所以必须对哈希表中每一个key重新计算索引,插入新的哈希表,这个过程就是rehash。
1.重新计算hash表的realeSize,值取决于当前要做的是扩容还是收缩
扩容:则新的size是第一个 >= dict.ht[0].used + 1 的 2^n
删除:则新的size是第一个 >= dict.ht[0].used 的 2^n (不小于 4)
2.按照新的realeSize申请内存空间,创建dictht,并赋值给dict.ht[1]
3.设置dict.rehashidx = 0,标识开始rehash
4.将dict.ht[0]的每个dictEntry都rehash到dict.h1
5.将dict.ht[1]的值赋给dict.ht[0] ,给dict.ht[1]初始化为 空哈希表,释放原来的dict.ht[0]的内存。
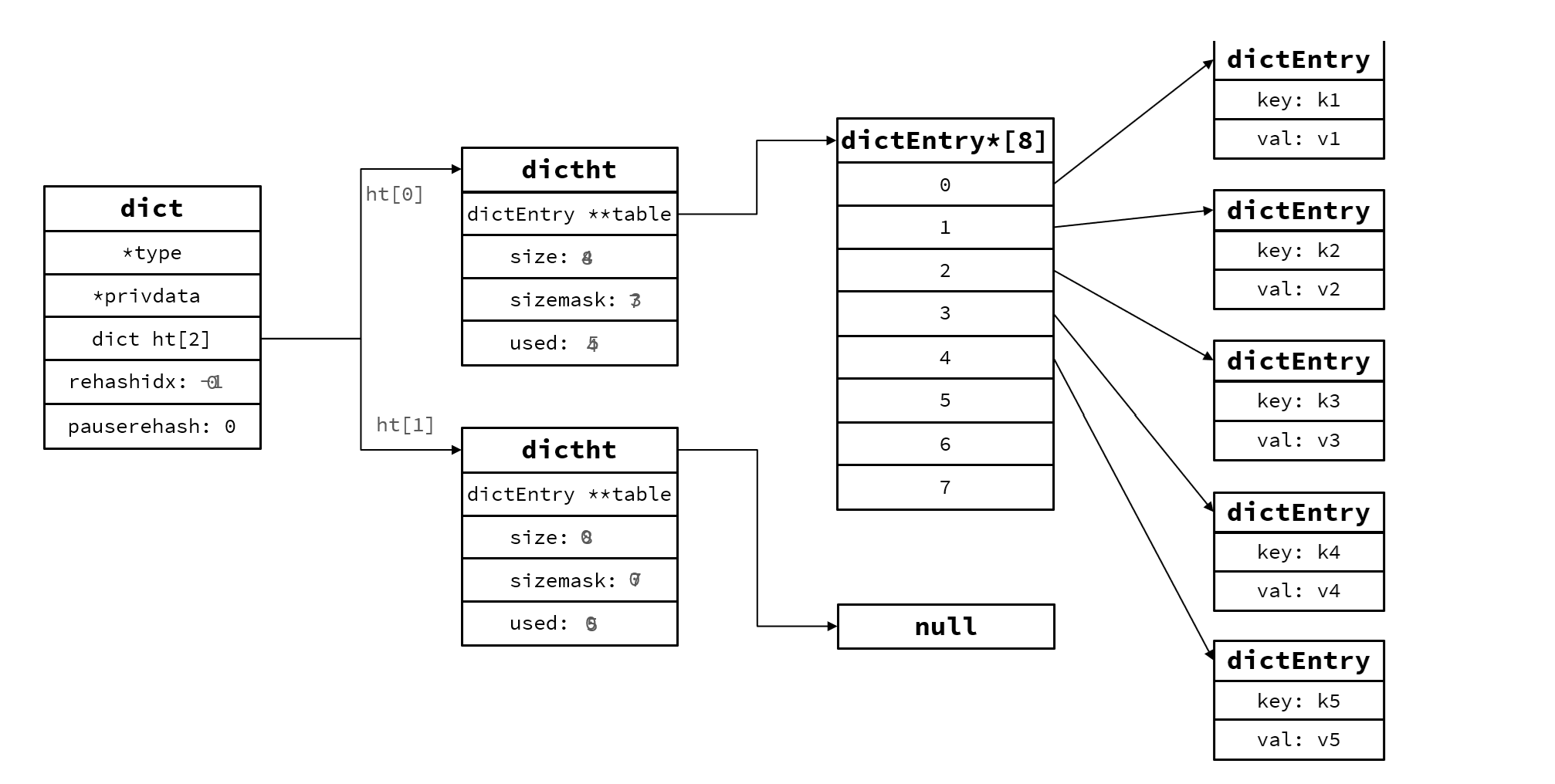
rehash不是一次能够完成的,如果数据百万entry则需要分批次完成,否则可能导致线程阻塞
所以叫渐进式rehash
1.重新计算hash表的realeSize,值取决于当前要做的是扩容还是收缩
扩容:则新的size是第一个 >= dict.ht[0].used + 1 的 2^n
删除:则新的size是第一个 >= dict.ht[0].used 的 2^n (不小于 4)
2.按照新的realeSize申请内存空间,创建dictht,并赋值给dict.ht[1]
3.设置dict.rehashidx = 0,标识开始rehash
4.将dict.ht[0]的每个dictEntry都rehash到dict.h1
5.每次增删查改都检查dict.rehashidx是否 > -1,如果是则将dict.ht[0].table[rehashidx]的entry链表rehash到dict.ht[1],并且将rehashidx++,直到所有数据都rehsh到dict.ht[1]
6.将dict.ht[1]的值赋给dict.ht[0] ,给dict.ht[1]初始化为 空哈希表,释放原来的dict.ht[0]的内存。
7.rehashidx赋值-1,代表rehash结束
8.在rehash过程中,新增操作,则直接写入ht[1],查询、修改和删除则会在dict.ht[0]和dict.ht[1]依次查找并执行。这样可以确保ht[0]的数据只减不增,随着rehash最终为空