Sam算法基本原理解析
Sam是Segmantation anything model的缩写,也就是可以分割一切的模型,2023年4月份横空出世,记忆中这是第一个引爆CV圈的大模型,如今两年过去了,来拜读一下Sam的源码。
1.Sam算法推理流程
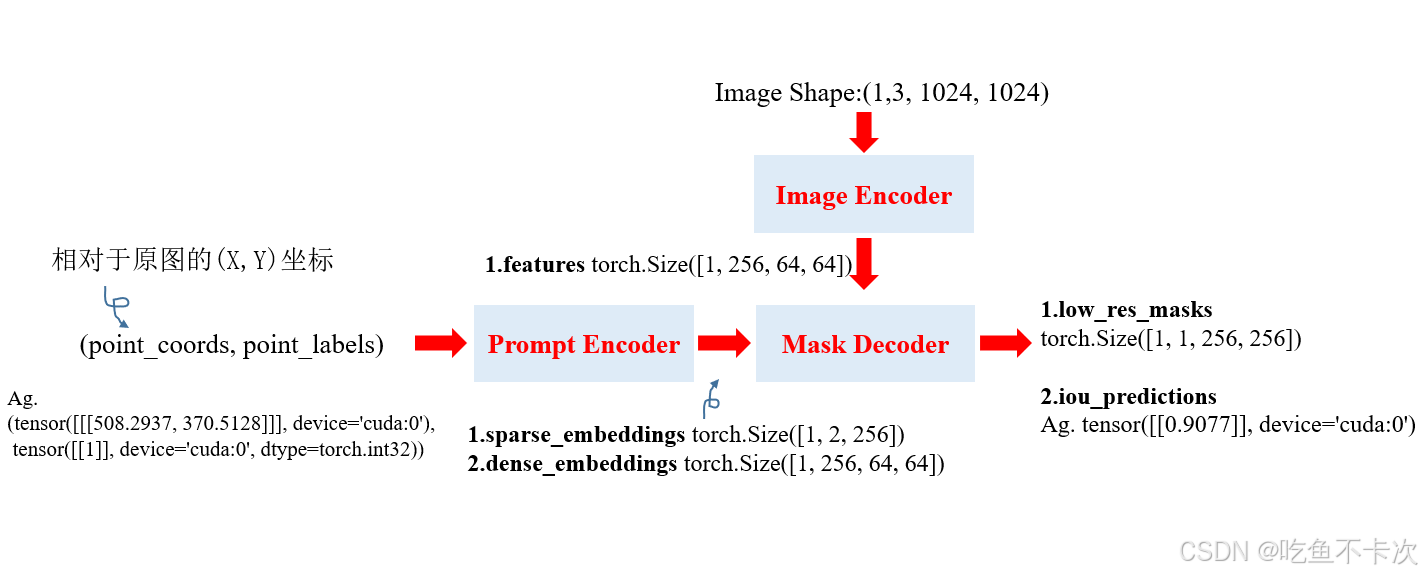
Sam算法的推理流程可以用下面这张图来概括,输入一张图,经过3个Step,可以按照中途输入的提示点(五角星),其中![]() 表示标记的正向点(前景),
表示标记的正向点(前景),![]() 表示标记的负向点(背景),最后输出正向点解码得到的分割结果。
表示标记的负向点(背景),最后输出正向点解码得到的分割结果。

Step1就是载入模型权重,这是官方使用极大量的数据集训练出来的模型,在不进行微调训练的前提下也能对各种场景下的物体有很好的分割效果。
我使用的是sam_vit_b_01ec64.pth模型,有357MB,这是最小的一个模型,官方提供了"vit_h"、"vit_l"、"vit_b"三种模型,,模型大小是从大到小。另外,从模型名字我们还可以知道,sam模型里面会包含vit网络,也就是应用在视觉领域的Transformer。
Step2包括图像预处理(Preprocess)和图像编码网络(Image_encoder)。
Step3包括提示词编码网络(Prompt_encoder)和掩码解码网络(Mask_decoder)。
其中Step2和Step3中包含最重要的三个部分:Image_encoder、Prompt_encoder和Mask_decoder,他们的关系可以用下图来表示:
Image_encoder负责对预处理后的图片进行图像编码,得到(1,256,64,64)的特征图,此时features特征图的分辨率已经从(1024,1024)缩放到(64,64);
Prompt_encoder负责对输入的提示(可以是point,box和mask,我这里暂时只对提示点作为例子说明),提示点包括了点的坐标(point_coords),以及点的类别(point_labels)。点的坐标是相对于原图的(x,y)坐标,比如输入图像的宽高分辨率是( 967,546),那么输入的点坐标就是基于( 967,546)分辨率的坐标,而不是经过预处理后的(1024,1024)分辨率的坐标。点的类别就是1和0,分别表示前景和背景。Prompt_encoder会输出稀疏嵌入sparse_embeddings和密集嵌入dense_embeddings。
Mask_decoder主要就是对Image_encoder和Prompt_encoder的输出结果进行解码,最后得到掩码结果low_res_masks和置信度iou_predictions(这个暂时就先理解为置信度吧)。这个是multimask_output=False的结果,后面再详细看看multimask_output=True的区别。
2.Preprocess
Preprocess过程就是要把任意输入图像的分辨率调整成统一的(1024,1024)分辨率,同时将图片的数据进行标准化,即将均值和方差标准化为0和1。
分辨率调整有点像YOLO中的letterbox,先选择长边然后等比例调整到1024,然后在短边填充黑边,像素值为(0,0,0),如下图所示。

3.Image Encoder
3.1patch embedding
在正式对图片数据进行Transformer编码前,还需要对图片进行patch_embed处理和pos_embed处理,这个是Vit的常规操作,这部分推荐去看看大佬的博客(Vision Transformer详解-CSDN博客)。
下面我来谈谈我对patch_embed这部分的理解:
还是先看看输入和输出,输入是一张经过预处理后的3通道且分辨率为(1024,1024)的图片,Shape为(1,3,1024,1024);输出是Shape为(1,64,64,768)的特征图,在这里我们要清楚,1x3x1024x1024=1x64x64x768,说明了经过patch_embed只是对输入的特征图的Shape进行了某种变换,并没有让他的元素有任何损失,下面来看看进行了什么样的Shape变换。
现在假设我想将图片划分出一个个宽高都为16像素的正方形,那么宽高为(1024,1024)的图片在水平方向有1024/16=64个正方形,垂直方向有1024/16=64个正方形,且每个正方形的Shape为(16,16,3),拉直后变成(768,1)的向量,因此我们就能看到Shape为(1,3,1024,1024)的特征图经过patch_embed后得到Shape为(1,64,64,768)的特征图。
接着再来看看是怎么实现的,实际上就是通过一个普通的卷积核实现的,代码如下。卷积核的大小为k=16x16,卷积核的步长s=16,卷积核的通道数为c=768.通过这样一个卷积就可以对Shape为(1,3,1024,1024)特征图进行划分出若干个正方形,并且正方形之间没有重合,最后的输出特征图Shape为(1,768,64,64),再交换下维度就变成了(1,64,64,768)。
#Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16))self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=kernel_size, stride=stride, padding=padding)接着就是pos_embed,这块是给(1,64,64,768)特征图对应位置上的元素加上一个绝对位置编码,这个相对位置编码是经过训练而学习来的,在代码中对应的是self.pos_embed.
# Initialize absolute positional embedding with pretrain image size.
self.pos_embed = nn.Parameter(torch.zeros(1, img_size // patch_size, img_size // patch_size, embed_dim)) 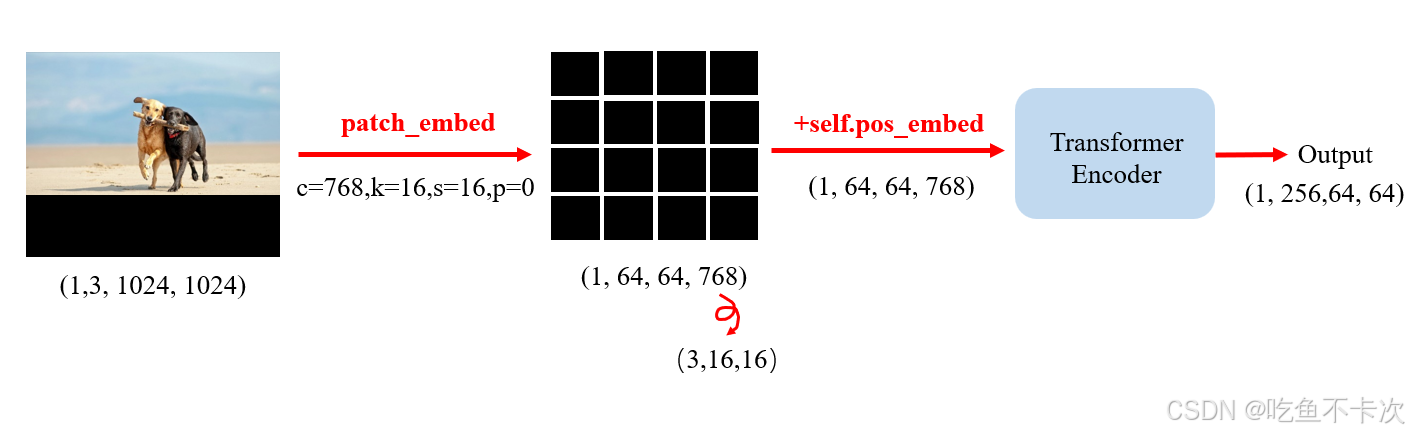
接下来就是Image Encoder的重头戏了—Transformer Encoder,输入Shape为(1,64,64,768)的特征图,经过Transformer Encoder之后,将得到Shape为(1,256,64,64),下一节将详细介绍下里面的细节。
3.2Transformer Encoder
未完待续。。。