文本向量化
1. 文本向量化
文本表示是自然语言处理中的基础工作,文本表示的好坏直接影响到整个自然语言处理系统的性能。因此,研究者们投入了大量的人力物力来研究文本表示方法,以期提高自然语言处理系统的性能。在自然语言处理研究领域,文本向量化是文本表示的一种重要方式。顾名思义,文本向量化就是将文本表示成一系列能够表达文本语义的向量。无论是中文还是英文,词语都是表达文本处理的最基本单元。当前阶段,对文本向量化大部分的研究都是通过词向量化实现的。与此同时,也有相当一部分研究者将文章或者句子作为文本处理的基本单元,于是产生了doc2vec 和str2vec技术。
1.1 One-hot编码
Word2Vec是google在2013年推出的一个NLP工具,它的特点是能够将单词转化为向量来表示,这样词与词之间就可以定量的去度量他们之间的关系,挖掘词之间的联系。用词向量来表示词并不是Word2Vec的首创,在很久之前就出现了。最早的词向量采用One-Hot编码,又称为一位有效编码,就是用一个很长的向量来表示一个词,向量的长度为词典的大小,向量中只有一个 1 , 其他全为 0 ,1 的位置对应该词在词典中的位置。比如我们有下面的5个词组成的词汇表,单词Queen在该词汇表中的独热编码就是:01000。
采用One-Hot编码方式来表示词向量非常简单,但缺点也是显而易见的,一方面我们实际使用的词汇表很大,经常是百万级以上,这么高维的数据处理起来会消耗大量的计算资源与时间。另一方面,One-Hot编码中所有词向量之间彼此正交,没有体现词与词之间的相似关系。
1.2 Distributed representation
Distributed representation可以解决One-Hot编码存在的问题,其基本想法是:通过训练将某种语言中的每一个词 映射成一个固定长度的短向量(当然这里的“短”是相对于One-Hot Representation的“长”而言的),所有这些向量构成一个词向量空间,而每一个向量则可视为 该空间中的一个点,在这个空间上引入“距离”,就可以根据词之间的距离来判断它们之间的语法、语义上的相似性了。
下图是采用Distributed representation的一个例子,我们将词汇表里的词用"Royalty",“Masculinity”, "Femininity"和"Age"4个维度来表示,King这个词对应的词向量可能是(0.99,0.99,0.05,0.7)。当然在实际情况中,我们并不能对词向量的每个维度做一个很好的解释。
有了用Distributed Representation表示的较短的词向量,我们就可以较容易的分析词之间的关系了,比如我们将词的维度降维到2维,有一个有趣的研究表明,用下图的词向量表示我们的词时,我们可以发现:
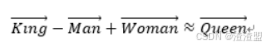
可见我们只要得到了词汇表里所有词对应的词向量,那么我们就可以做很多有趣的事情了。不过,怎么训练才能得到合适的词向量呢?针对这个问题,Google的Tomas Mikolov在他的论文中提出了CBOW和Skip-gram两种神经网络模型,通过训练得到词向量的权重。
1.3 Word2Vec
Word2Vec 的训练模型本质上是只具有一个隐含层的神经元网络(如下图)。
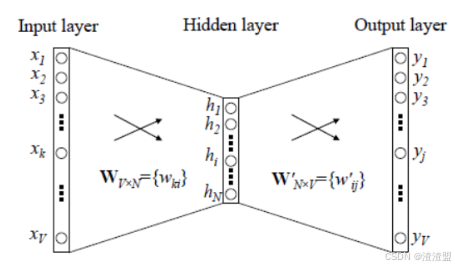
它的输入是采用One-Hot编码的词汇表向量,它的输出也是One-Hot编码的词汇表向量。使用所有的样本,训练这个神经元网络,等到收敛之后,从输入层到隐含层的那些权重,便是每一个词的采用Distributed Representation的词向量。
1.4 doc2vec
上一节介绍了word2vec的原理以及生成词向量神经网络模型的常见方法,word2vec基于分布假说理论可以很好地提取词语的语义信息,因此,利用word2vec技术计算词语间的相似度有非常好的效果。同样word2vec技术也用于计算句子或者其他长文本间的相似度,其一般做法是对文本分词后,提取其关键词,用词向量表示这些关键词,接着对关键词向量求平均或者将其拼接,最后利用词向量计算文本间的相似度。这种方法丢失了文本中的语序信息,而文本的语序包含重要信息。例如“小王送给小红一个苹果”和“小红送给小王一个苹果”虽然组成两个句子的词语相同,但是表达的信息却完全不同。为了充分利用文本语序信息,有研究者在word2vec的基础上提出了文本向量化(doc2vec),又称str2vec和para2vec。下面介绍doc2vec的相关原理。
2. 语料
巧妇难为无米之炊,语料库就是NLP的“米”,常常用到的语料库主要有:
(1)中文维基百科
维基百科是最常用且权威的开放网络数据集之一,作为极少数的人工编辑、内容丰富、格式规范的文本语料,各类语言的维基百科在NLP等诸多领域应用广泛。维基百科提供了开放的词条文本整合下载,可以找到你需要的指定时间、指定语言、指定类型、指定内容的维基百科数据,中文维基百科数据是维基提供的语料库。
(2)搜狗新闻语料库
来自若干新闻站点2012年6月~ 7月期间国内、国际、体育、社会、娱乐等18个频道的新闻数据,提供URL和正文信息。
(3)IMDB情感分析语料库
互联网电影资料库( Internet Movie Database,简称IMDb)是-一个关于电影演员、电影、电视节目、电视明星和电影制作的在线数据库。IMDb 的资料中包括了影片的众信息、演员、片长、内容介绍、分级、评论等。对于电影的评分目前使用最多的就是IMDb评分。还有豆瓣读书相关语料(爬虫获取)、邮件相关语料等。
任务实施:
本实例主要介绍的是选取wiki中文语料,并使用python完成Word2vec模型构建的实践过程,旨在一步一步的了解自然语言处理的基本方法和步骤。任务实施主要包含了开发环境准备、数据的获取、数据的预处理、模型构建和模型测试五大内容,对应的是实现模型构建的五个步骤。
1.开发环境准备
1.1 安装相关的python依赖库
- genism:Word2vec需要使用第三方gensim模块;
- jieba:用于中文分词;
- zhconv:提供基于 MediaWiki 和 OpenCC 词汇表的最大正向匹配简繁转换。
!pip install gensim==4.2.0
!pip install jieba==0.42.1
!pip install zhconv==1.4.3
!pip install pandas==1.3.5
1.2 导入相关的依赖库
- gensim:是一个简单高效的自然语言处理Python库,用于抽取文档的语义主题。Gensim的输入是原始的、无结构的数字文本(纯文本),内置的算法包括Word2Vec,FastText,LSA,LDA等。
- warnings:有时候运行代码时会有很多 warning 输出,如提醒新版本之类的,如果不想这些乱槽槽的输出,可以用 warnings.filter 过滤掉;
- logging:输出程序运行时的log信息。
import os
from gensim.corpora import WikiCorpus
from gensim.models import word2vec
import warnings
warnings.filterwarnings(action='ignore', category=FutureWarning)
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
2. 数据的获取
训练词向量等一些任务的时候,往往需要一些较大规模的中文语料,而维基百科语料是一个很好的选择。维基百科每段时间都会备份数据,我们可以选择不同时间段的语料来下载使用。维基百科的语料的下载地址:https://dumps.wikimedia.org/zhwiki/
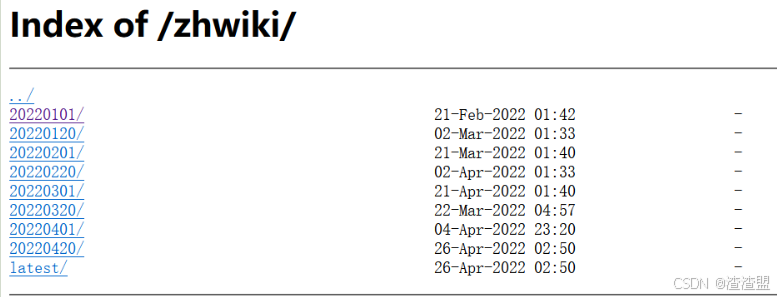
可以选择时间最近的语料,比如该任务选择了202201的语料库。选择其中某一个时间段会发现其中有很多下载地址链接,可以根据自己的需求下载不同的语料内容。
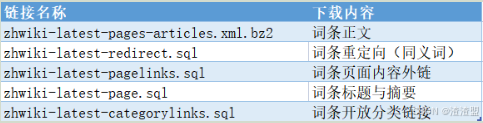
由于我们的需求是训练词向量,所以选择"zhwiki-20220101-pages-articles1.xml-p1p187712.bz2",也就是包含词条正文的链接进行下载,选择200.9M包进行下载,当然下载的包越大,使用其训练的词向量也就越精确。
动手练习1
根据上述操作方法,下载时间最近的词条正文语料。
3. 数据的预处理
3.1 转换格式
下载好的语料格式为XML文件,需要将XML的Wiki数据转换为text格式,这里使用gensim.corpora中的WikiCorpus函数来处理维基百科的数据,可以将维基百科文章处理为只读、流式处理、内存效率高的语料库。文档是动态提取的,以便整个大规模转储可以在磁盘上保持压缩状态。
支持的格式为:
<LANG>wiki-<YYYYMMDD>-pages-articles.xml.bz2<LANG>wiki-latest-pages-articles.xml.bz2
WikiCorpus语法:
gensim.corpora.wikicorpus.WikiCorpus(fname, processes=None, lemmatize=None, dictionary=None, filter_namespaces=('0', ), tokenizer_func=<function tokenize>, article_min_tokens=50, token_min_len=2, token_max_len=15, lower=True, filter_articles=None)
参数说明:
- fname (str):下载的语料地址;
- dictionary (Dictionary, optional):将语料扫描一遍,检查词汇量;
- article_min_tokens (int, optional):文章中的最小token数量,若该文章token数量较少,则将忽略文章;
- token_min_len (int, optional):最小token长度;
- token_max_len (int, optional):最长token长度;
- lower (bool, optional):如果为True,转化为小写。
fname = 'zhwiki-20220101-pages-articles1.xml-p1p187712.bz2'
wiki = WikiCorpus(fname, dictionary={}, article_min_tokens=10, token_min_len=1, token_max_len=100, lower=True)
使用了gensim库中的维基百科处理类WikiCorpus,该类中的get_texts方法原文件中的文章转化为一个数组,其中每一个元素对应着原文件中的一篇文章。然后通过for循环便可以将其中的每一篇文章读出,然后进行保存。因为语料内容比较多,运行时间会大概在12分钟左右。
# 提取文本
if not os.path.exists('./result/zhwiki.txt'):texts_num = 0with open('./result/zhwiki.txt', 'w', encoding='utf-8') as f:for text in wiki.get_texts():f.write(' '.join(text) + '\n')texts_num += 1if texts_num % 10000 == 0:logging.info("已处理 %d 篇文章" % texts_num)
3.2 中文繁体替换成简体
用文本编辑器打开zhwiki.txt文件,可以看到提取出的语料中繁简混杂,所以我们需要借助工具将繁体部分也转换为简体。
zhconv 提供基于 MediaWiki 词汇表的最大正向匹配简繁转换。Python 2, 3 通用。支持以下地区词转换:
- zh-cn 大陆简体
- zh-tw 台灣正體
- zh-hk 香港繁體
- zh-sg 马新简体(无词汇表,需要手工指定)
- zh-hans 简体
- zh-hant 繁體
import zhconv
zhconv.convert("人体内存在很多微生物", 'zh-hk')
动手练习2
将"zhwiki.txt"转换为简体,输出为"wiki.cn.simple.txt"。
- 在<1>处填写代码,将文本从繁体转为简体,使用
zh-hans参数。

#在这里手敲上面代码并填补缺失代码
运行以下代码,查看“wiki.cn.simple.txt”文件,若已转换为简体,说明填写正确。
input_file_name = "./result/wiki.cn.simple.txt"
input_file = open(input_file_name, 'r', encoding='utf-8')
lines = input_file.readlines()
lines[5]
3.3 分词
对于中文来说,分词是必须要经过的一步处理,下面就需要进行分词操作。在这里使用了大名鼎鼎的jieba库。调用其中的cut方法即可。
#中文分词需5分钟
import jiebaprint('主程序执行开始...')input_file_name = './result/wiki.cn.simple.txt'
output_file_name = './result/wiki.cn.simple.separate.txt'
input_file = open(input_file_name, 'r', encoding='utf-8')
output_file = open(output_file_name, 'w', encoding='utf-8')print('开始读入数据文件...')
lines = input_file.readlines()
print('读入数据文件结束!')print('分词程序执行开始...')
count = 1
for line in lines:# jieba分词的结果是一个list,需要拼接,但是jieba把空格回车都当成一个字符处理output_file.write(' '.join(jieba.cut(line.split('\n')[0].replace(' ', ''))) + '\n')count += 1if count % 10000 == 0:print('目前已分词%d条数据' % count)
print('分词程序执行结束!')print('主程序执行结束!')
input_file_name = "./result/wiki.cn.simple.separate.txt"
input_file = open(input_file_name, 'r', encoding='utf-8')
lines = input_file.readlines()
lines[5]
3.4 去除非中文词
可以看到,经过上面的处理之后,现在的结果已经差不多了,但是还存在着一些非中文词,所以下一步便将这些词去除。具体做法是通过正则表达式判断每一个词是不是符合汉字开头、汉字结尾、中间全是汉字。
“\u4e00”和“\u9fa5”是unicode编码,并且正好是中文编码的开始和结束的两个值,所以这个正则表达式可以用来判断字符串中是否包含中文。
动手练习3
- 在<1>处填写代码,设置开头结尾中间全是汉字的正则表达式;
- 在<2>处填写代码,判断字符是否符合正则表达式。

#在这里手敲上面代码并填补缺失代码
运行以下代码,查看“wiki.txt”文件,若全部为中文,说明填写正确。
input_file_name = "./result/wiki.txt"
input_file = open(input_file_name, 'r', encoding='utf-8')
lines = input_file.readlines()
lines[5]
4. 模型构建与训练
上面的工作主要是对wiki语料库进行数据预处理,接下来才真正的词向量训练。也是使用了gensim库,通过其中的Word2Vec类进行了模型训练,并将最终的词向量保存起来。
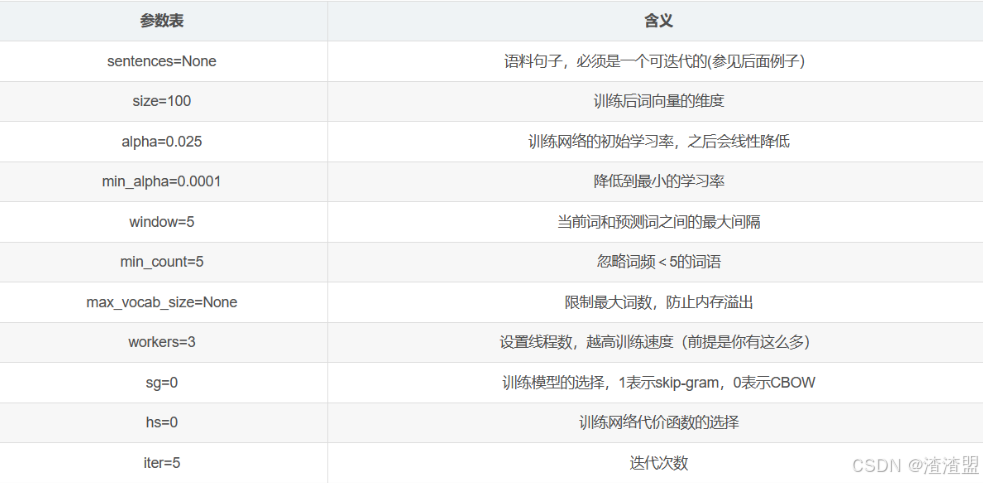
动手练习4
配置Word2Vec参数,进行模型训练。
- 在<1>中填入代码,将原始的训练语料转化成一个sentence的迭代器,每一次迭代返回的sentence是一个word(utf8格式)的列表。可以使用LineSentence()方法实现;
- 在<2>中填入代码,将词向量长度设置为400;
- 在<3>中填入代码,将当前词和预测词之间的最大间隔设置为5;
- 在<4>中填入代码,忽略词频<5的词语;
- 在<5>中填入代码,设置线程数为
multiprocessing.cpu_count()。

#在这里手敲上面代码并填补缺失代码
5.模型测试
#加载模型
w2v_model = word2vec.Word2Vec.load("./models/wiki.model")
词汇类比
使用乘法组合对象(multiplicative combination objective)找到前N个最相似的单词,当positive和negative同时使用的话,就是词汇类比
most_similar_cosmul(positive=None, negative=None, topn=10)
w2v_model.wv.most_similar_cosmul(positive=['女人', '国王'], negative=['男人'], topn=3)
找出与其他词差异最大的词汇
w2v_model.wv.doesnt_match('早餐 谷物 晚餐 午餐'.split())
计算词汇间相似度
基于cosine余弦计算词汇之间的相似度,数值越大代表相似度越高
w2v_model.wv.similarity('女人', '男人')
最相近文本
给出与给出文本最相近的3个词。
w2v_model.wv.similar_by_word('猫', topn=3)
如果测试词汇不在词向量中,那么测试时就会报错。所以最好先判断词汇是否在模型中:
word = '美好'
if word in w2v_model.wv.index_to_key:print(w2v_model.wv.most_similar(word))
词距离
计算两个词的距离,结果越大越不相似
w2v_model.wv.distance('媒体', '你好')
w2v_model.wv.distance('爱', '喜欢')
词列表相似度
计算两个词列表之间的余弦相似度
w2v_model.wv.n_similarity(['寿司', '商店'], ['日语', '餐厅'])
运行以上代码,查看文本相似度,若结果为0.936附近,则说明填写正确。