机器学习第三篇 模型评估(交叉验证)
- Sklearn:可以做数据预处理、分类、回归、聚类,不能做神经网络。
- 原始的工具包文档:
- scikit-learn: machine learning in Python — scikit-learn 1.6.1 documentation
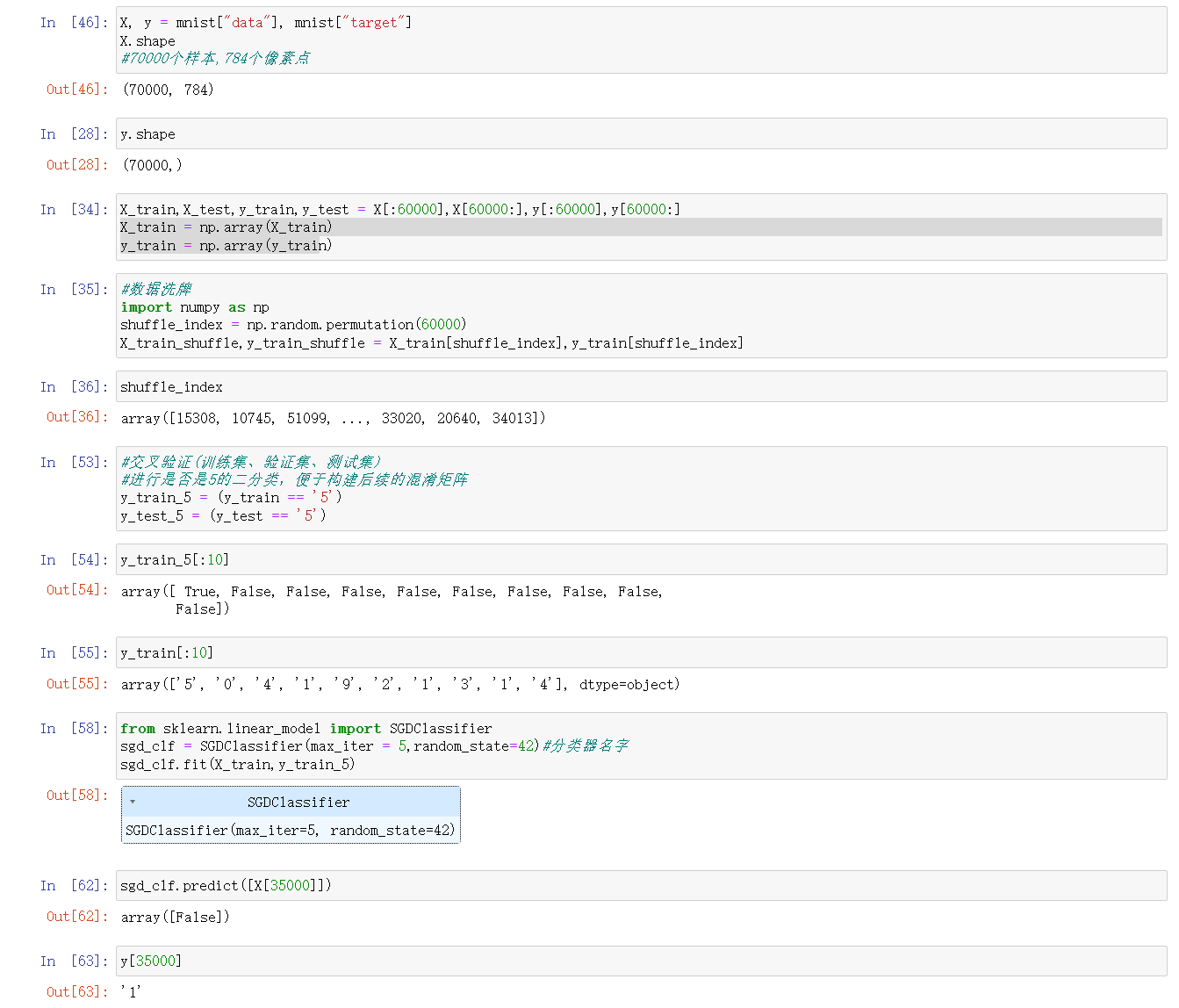
- 数据集:使用的是MNIST手写数字识别技术,大小为70000,数据类型为784个像素点。
- 模型评估方法有留一法、交叉验证法、自助法。
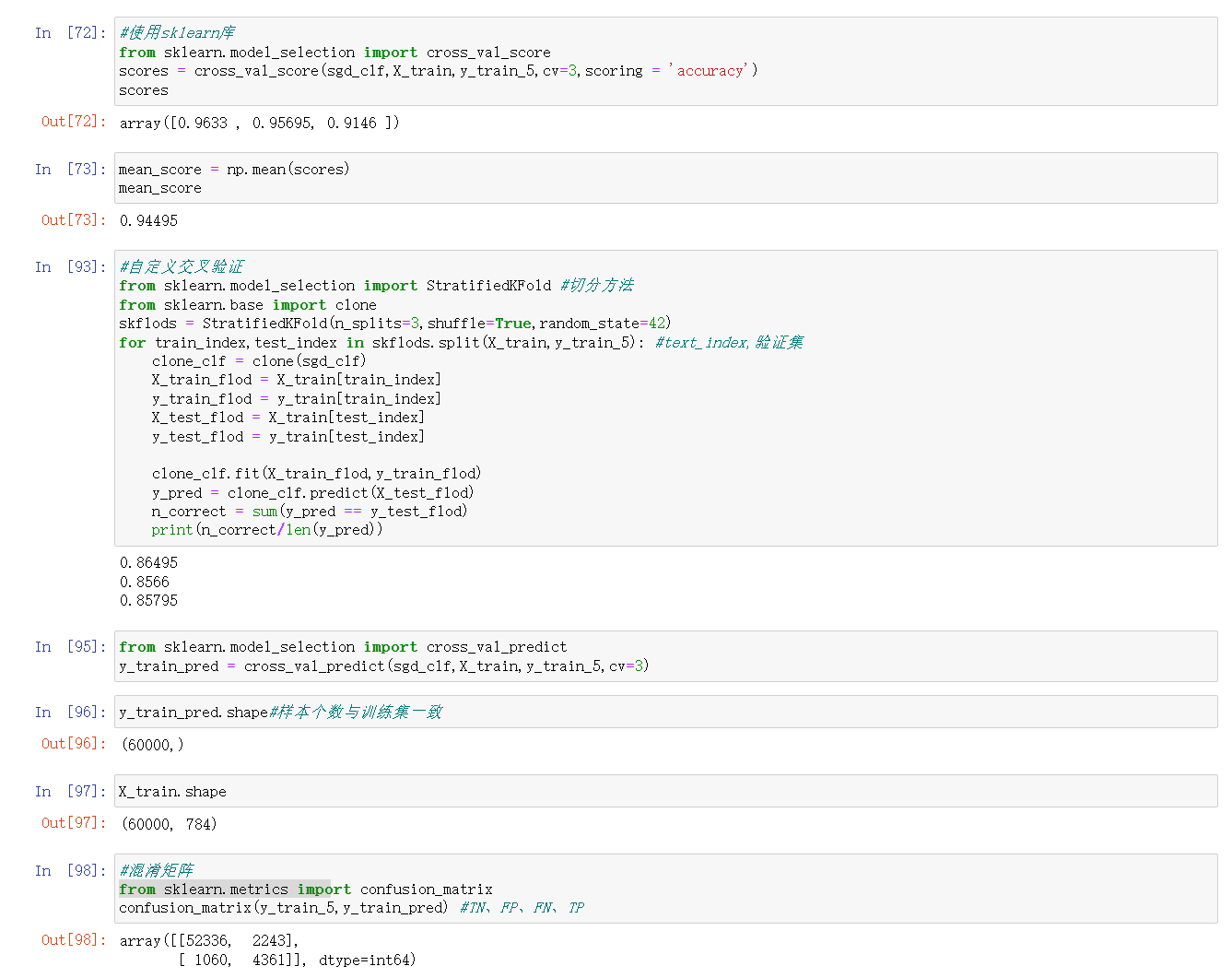
- 交叉验证:将数据集划分为K个大小相似的互斥子集,又称K折交叉验证,准确率为K次评估的平均值。
- Positove:正例;necative:负例。分类结果混淆矩阵(TP、FN、FP、TN)
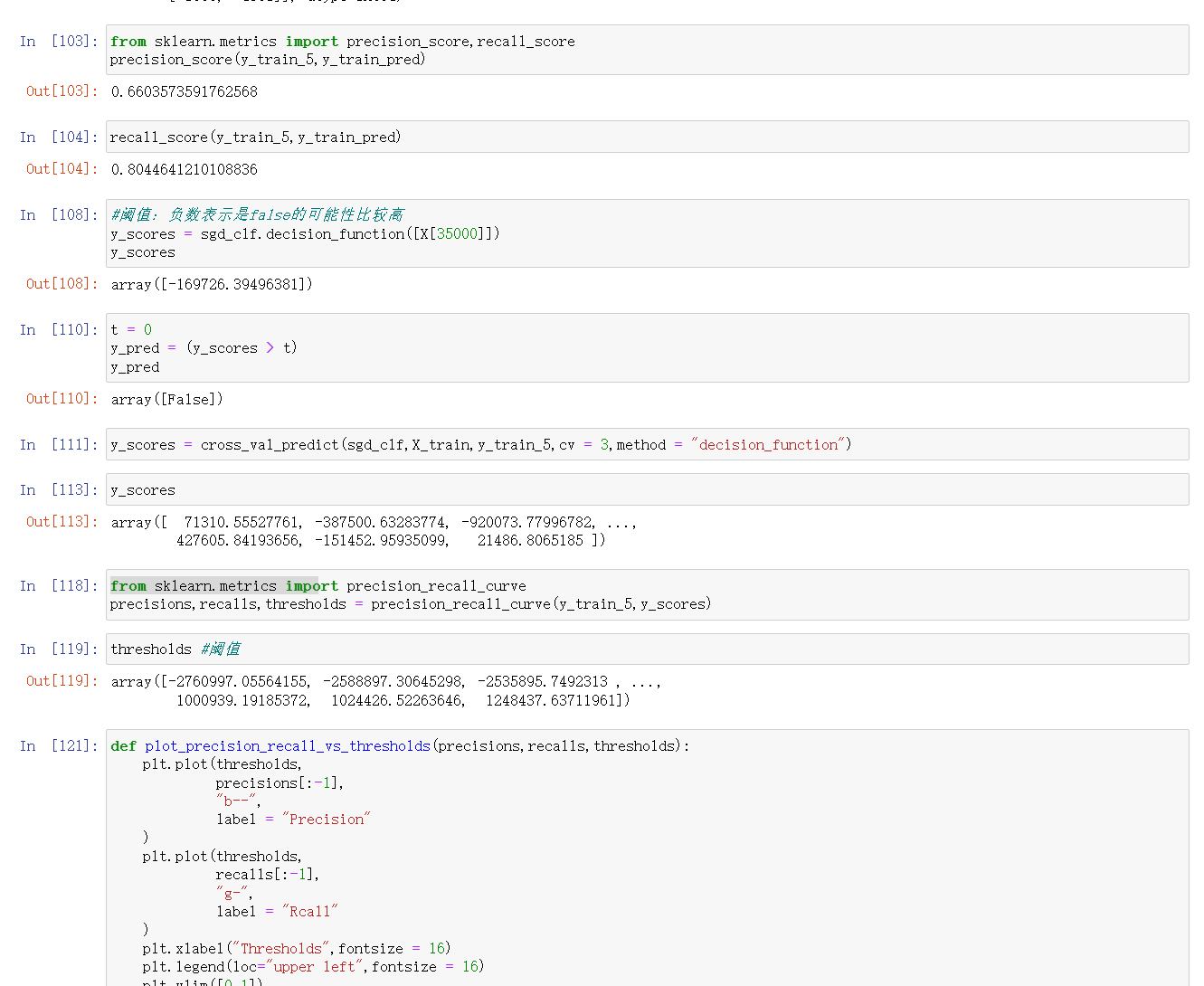
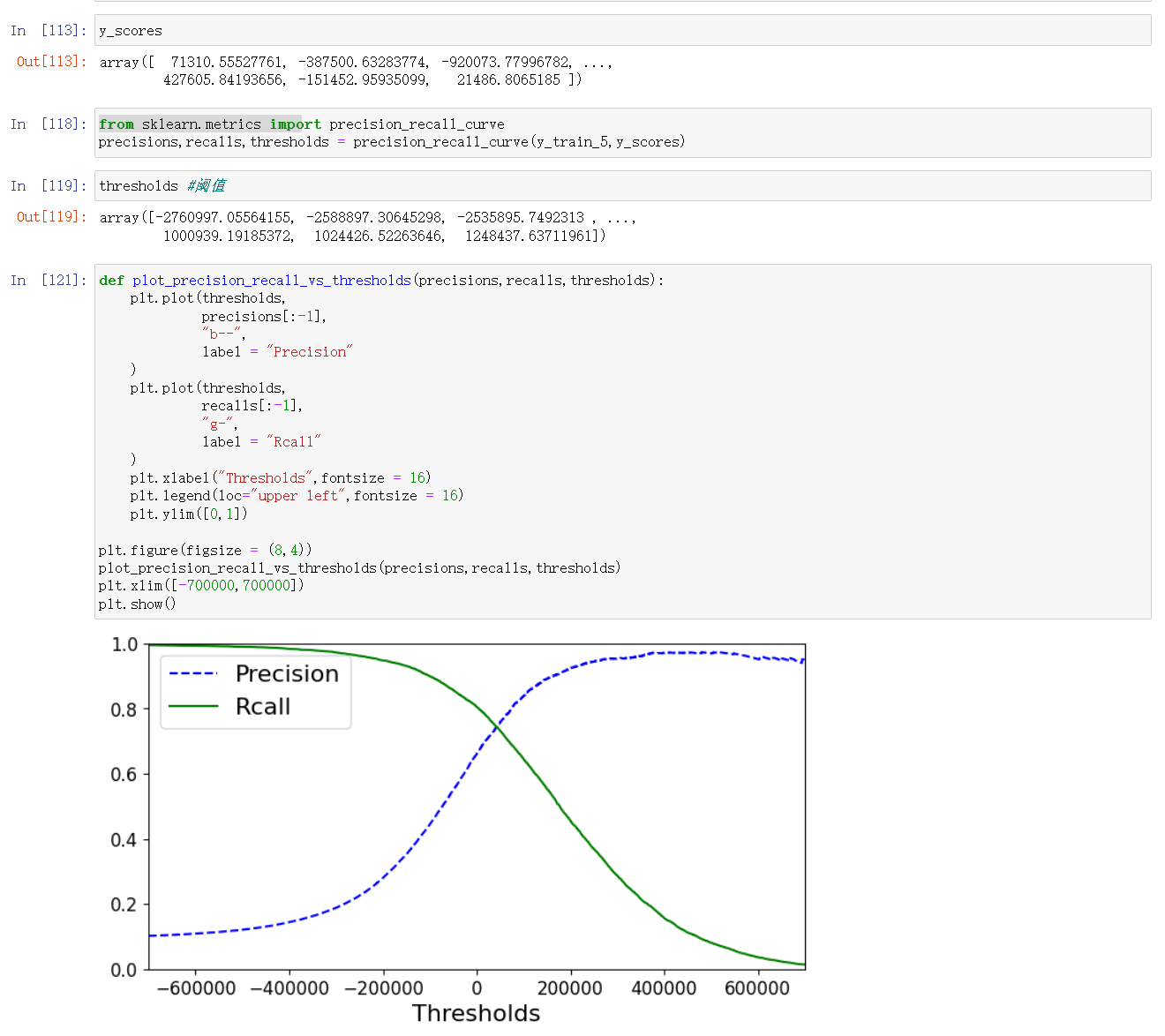
- 查准率:TP/(TP+FP);查全率:TP/(TP+FN);
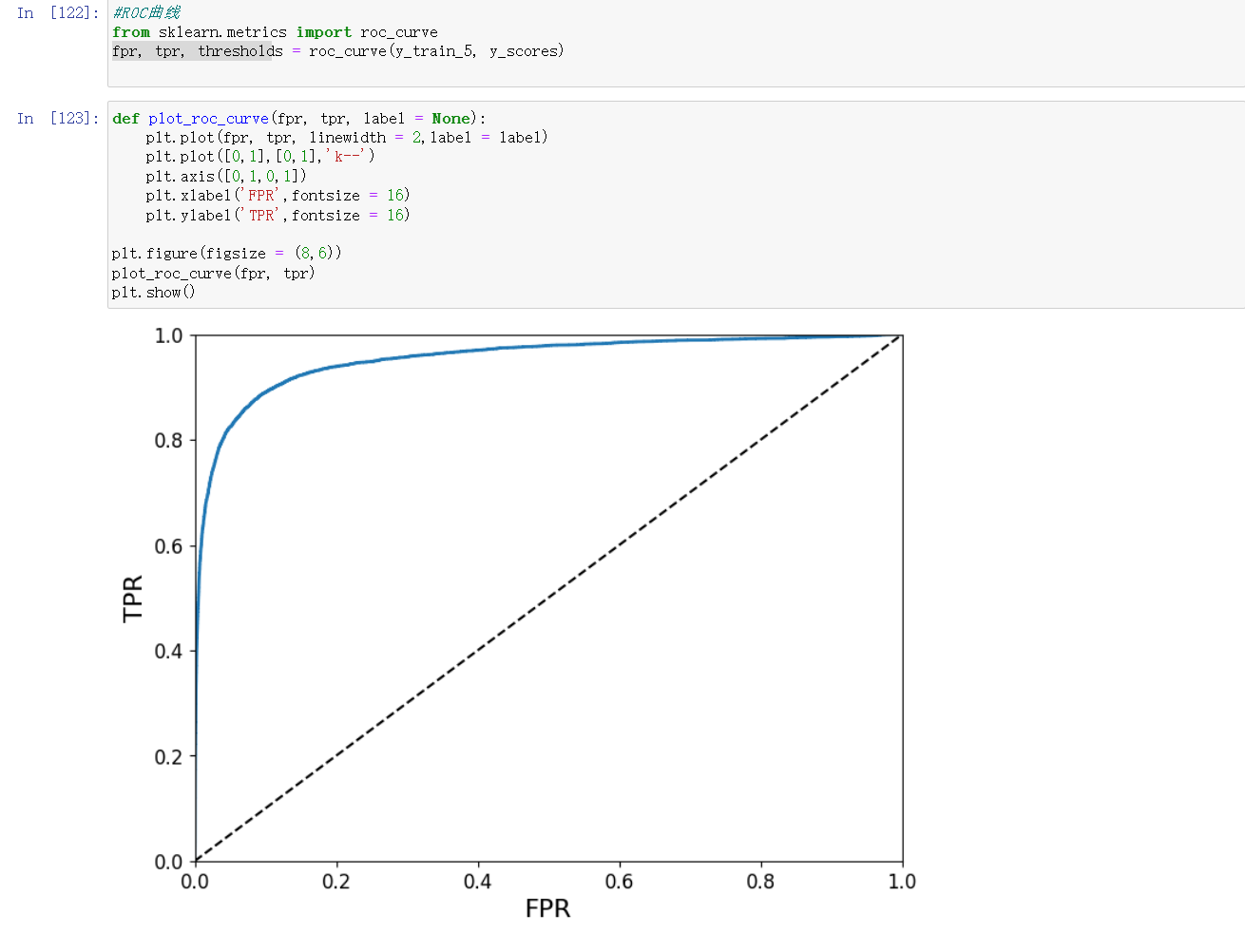
- ROC曲线全称是“受试者工作特征”曲线,纵轴为TPR(真正例率),横轴为FPR(假正例率)。
代码: