维度的语法:从列表的散文到 ndarray 的十四行诗
🌟 嗨~我是阳光开朗大男孩(๑•̀ㅂ•́)و✧
还在为数据处理头疼?3 分钟带你吃透 Numpy,0 基础也能玩转高效数据处理!
💡 聚焦核心优势:多维数据随便装、计算速度狂飙 1000 倍、内存省一半,轻松碾压 Python 列表!
🚀 手把手教你创建数组、玩转向量化运算、避开维度大坑,实操代码直接复制就能跑~
👍 含超全速查表 + 避坑指南,建议收藏✨ 点赞分享给更多小伙伴,一起告别数据处理低效!
引言:为什么需要 Numpy?先搞懂数组的 “超能力”
你是否遇到过这些问题:
- 用 Python 列表存 10 万条数据,计算时卡到怀疑人生?
- 想处理表格或 3D 数据(比如图像、视频),列表根本存不了?
💡 答案就是 Numpy!它的核心武器
ndarray(多维数组)就像一个 “数据集装箱”:
- 能装多维数据:一维像绳子([1,2,3]),二维像 Excel 表格,三维像魔方,甚至支持 100 维!
- 计算速度开挂:底层用 C 语言优化,比列表循环快 100~1000 倍!
- 内存超省空间:所有数据类型统一,内存连续存储,比列表节省 50% 以上空间!
📊 列表 vs Numpy 数组:一目了然的对比
特性 Python 列表 Numpy 数组 (ndarray) 数据类型 可混存(如同时存数字、字符串) 必须统一(如全是整数或全是小数) 维度支持 仅一维(嵌套列表模拟多维,效率极低) 支持 1~N 维,原生多维结构 内存占用 高(每个元素需额外存储类型信息) 低(连续存储,仅存数据值) 数值计算 需循环遍历,速度慢 支持向量化操作,一行代码算整个数组
一、Numpy 核心:ndarray 的 “数据基因” 解析
| 属性 | 技术定义 | 生活类比 | 典型用法 |
|---|---|---|---|
shape | 各维度长度元组 | 数据的 “长宽高” | 调整数组形状:arr.reshape(2,3) |
ndim | 维度数量(轴数) | 数据的 “空间维度” | 判断数据形态:图像(2D)/ 视频(3D) |
dtype | 元素数据类型 | 数据的 “语言种类” | 控制内存:用float32替代float64节省空间 |
itemsize | 单个元素字节大小 | 数据的 “个体体重” | 计算总内存:arr.itemsize * arr.size |
size | 元素总数 | 数据的 “家庭人口” | 批量操作循环边界:for i in range(arr.size) |
代码演示:
1. 对象方法获取属性(推荐)
# 1. 构建1个3行5列的 ndarray对象(n维数字), 即: 3行5列.
arr = np.arange(15).reshape((3, 5)) # arange(15)类似于Python的range(15), 然后把0~15(包左不包右)的数据放到 3个 长度维5的一维数组中.
print(f'ndarray对象: {arr}') # ndarray对象.print(f'数组的形状(维度): {arr.shape}') # (3, 5), 简单理解为: 3行5列
print(f'数组的轴: {arr.ndim}') # 2, 几维数组, 维度(轴)就是几.
print(f'数组的长度: {arr.size}') # 15, 即所有元素的个数.
print(f'数组的每个元素的类型: {arr.dtype}') # int64
print(f'数组的每个元素的大小(字节数): {arr.itemsize}') # 8
print(f'数组的类型: {type(arr)}') # <class 'numpy.ndarray'>

2. 函数方法获取属性
# 扩展: 上述的 shape, ndim, size等属性, 可以改写成: np.属性名(对象对)的形式.
print(f'数组的形状(维度): {np.shape(arr)}') # (3, 5), 简单理解为: 3行5列
print(f'数组的轴: {np.ndim(arr)}') # 2, 几维数组, 维度(轴)就是几.
print(f'数组的长度: {np.size(arr)}') # 15, 即所有元素的个数.
# print(f'数组的每个元素的类型: {np.dtype(arr)}') # 报错, 无该函数
# print(f'数组的每个元素的大小(字节数): {np.itemsize(arr)}') # 报错, 无该函数
# print(f'数组的类型: {np.type(arr)}') # 报错, 无该函数
二、ndarray 创建:7 大场景对应的最佳实践
ndarray介绍
-
NumPy数组是一个多维的数组对象(矩阵),称为ndarray(N-Dimensional Array)
-
具有矢量算术运算能力和复杂的广播能力,并具有执行速度快和节省空间的特点
-
注意:ndarray的下标从0开始,且数组里的所有元素必须是相同类型。
1. 基础转换:从列表到数组的 “数据升级”
# int数组
arr1 = np.array([1, 2, 3, 4, 5])
print(f'数组对象: {arr1}')
print(f'数组类型: {type(arr1)}')
print(f'数组元素类型: {arr1.dtype}')
2. 快速初始化:3 类 “模板数组” 的适用场景
| 函数 | 适用场景 | 核心参数 | 内存特性 | 示例 |
|---|---|---|---|---|
zers | 全零矩阵(如掩码、初始化) | shape=(行,列), dtype | 分配内存并填充 0 | mask = np.zeros((1024,1024), dtype=np.uint8) |
ones | 全一矩阵(如权重初始化) | 同上 | 同上 | weights = np.ones((3,4), dtype=np.float32) |
empty | 快速创建未初始化数组 | 仅需shape | 不初始化内存(速度最快) | temp = np.empty((2,2))(需手动赋值!) |
(1)zeros()
# zeros() 创建全是0的数组, 即: ndarray对象
arr3 = np.zeros((2, 3)) # 2行3列, 即: 二维数组, 有2个一维数组, 每个一维数组的元素个数为: 3
print(f'数组对象: {arr3}') # [[0. 0. 0.] [0. 0. 0.]]
print(f'数组类型: {type(arr3)}') # <class 'numpy.ndarray'>
print(f'数组元素类型: {arr3.dtype}') # float64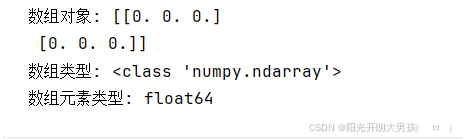
(2)ones()
# ones() 创建全是1的数组, 即: ndarray对象
# arr4 = np.ones((2, 3)) # 2行3列, 即: 二维数组, 有2个一维数组, 每个一维数组的元素个数为: 3
arr4 = np.ones((2, 3, 4)) # 三维数组, 2个二维数组, 每个2位数组有3个一维数组, 每个一维数组有4个元素
print(f'数组对象: {arr4}') # [[1. 1. 1.] [1. 1. 1.]]
print(f'数组类型: {type(arr4)}') # <class 'numpy.ndarray'>
print(f'数组元素类型: {arr4.dtype}') # float64
(3)empty()
# empty() 创建内容随机, 且依赖内存状态的随机值, 即: ndarray对象
arr5 = np.empty((2, 3)) # 2行3列, 即: 二维数组, 有2个一维数组, 每个一维数组的元素个数为: 3
print(f'数组对象: {arr5}') # [[1. 1. 1.] [1. 1. 1.]]
print(f'数组类型: {type(arr5)}') # <class 'numpy.ndarray'>
print(f'数组元素类型: {arr5.dtype}') # float64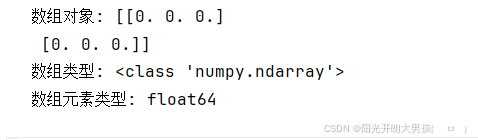
3. arange()函数, 创建ndarray对象
# arange(起始值, 结束值, 步长, 类型), 它类似于Python中的 range()
arr6 = np.arange(1, 5, 2, dtype=np.float32) # 生成 1 ~ 5之间, 步长为2的数据, 包左不包右. 类型: int32, int64, float32, float64
print(f'数组对象: {arr6}') #
print(f'数组类型: {type(arr6)}') # <class 'numpy.ndarray'>
print(f'数组元素类型: {arr6.dtype}') # float64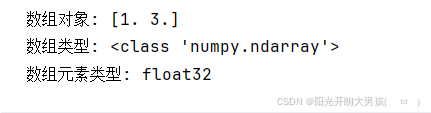
这里博主用的pycharm环境,pycharm 与 jupyter notebook 格式可能有点不同,如下:
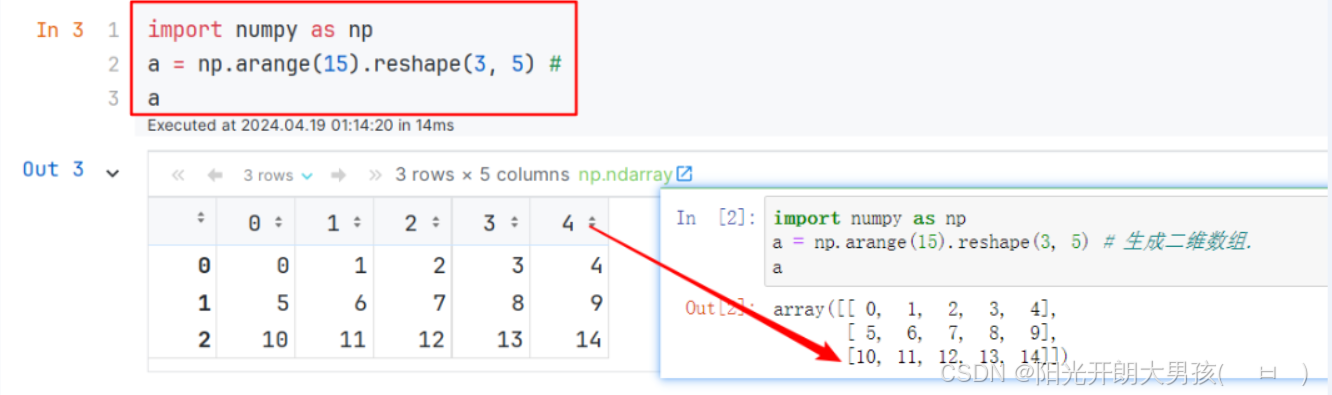
4. matrix() 生成二维数组
# matrix()属于ndarry的子集, 生成 二维数组的.
# arr7 = np.mat('1 2; 3 4') # 生成 二维数组
# arr7 = np.mat('1,2;3,4') # 生成 二维数组
# arr7 = np.mat([[1, 2, 3], [4, 5, 6]]) # 生成 二维数组
arr7 = np.matrix([[1, 2, 3], [4, 5, 6]]) # 生成 二维数组 你写 mat() 和 matrix()效果是一致的
print(f'数组对象: {arr7}') # [[1 2] [3 4]]
print(f'数组类型: {type(arr7)}') # <class 'numpy.matrix'>, 即: matrix是ndarray的子类.
print(f'数组元素类型: {arr7.dtype}') # float64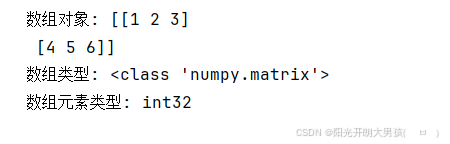
5. rand(), randint(), uniform() 生成ndarray对象
(1)rand()
# rand(), 生成0.0 ~ 1.0之间的 随机数组. 包左不包右.
arr8 = np.random.rand(2, 3) # 2行3列
print(f'数组对象: {arr8}') # [[1 2] [3 4]]
print(f'数组类型: {type(arr8)}') # <class 'numpy.ndarray'>
print(f'数组元素类型: {arr8.dtype}') # float64 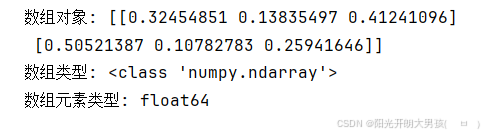
(2)randint()
# randint(), 生成指定范围之间的 随机数组. 包左不包右.
arr9 = np.random.randint(-1, 5, size=(2, 3)) # 2行3列, -1 ~ 5之间, 随机整数
print(f'数组对象: {arr9}') # [[1 2] [3 4]]
print(f'数组类型: {type(arr9)}') # <class 'numpy.ndarray'>
print(f'数组元素类型: {arr9.dtype}') # int64 
(3)uniform()
# uniform(), 生成指定范围之间的 随机数组. 包左不包右.
arr10 = np.random.uniform(-1, 5, size=(2, 3)) # 2行3列, -1 ~ 5之间, 随机小数(浮点数)
print(f'数组对象: {arr10}') # [[1 2] [3 4]]
print(f'数组类型: {type(arr10)}') # <class 'numpy.ndarray'>
print(f'数组元素类型: {arr10.dtype}') # float64
6. 通过 astype()函数, 把ndarray => ndarray
# 1. 创建1个 float类型的 数组.
arr11 = np.ones((2, 3), dtype=np.float32) # 2行3列
print(f'数组对象: {arr11}') # [[1. 1. 1.] [1. 1. 1.]]
print(f'数组类型: {type(arr11)}') # <class 'numpy.ndarray'>
print(f'数组元素类型: {arr11.dtype}') # float32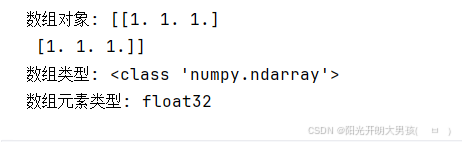
# 2. 把 arr11的元素类型, 从 float32 => int64
arr12 = arr11.astype(np.int64)
print(f'数组对象: {arr12}') # [[1 1 1] [1 1 1]]
print(f'数组类型: {type(arr12)}') # <class 'numpy.ndarray'>
print(f'数组元素类型: {arr12.dtype}') # int64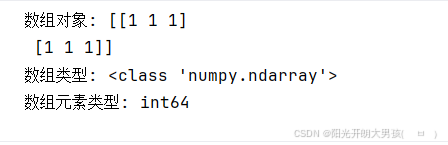
7. logspace()等比数列 和 linspace()等差数列
(1)logspace()等比数列
# logspace(起始幂值, 结束幂值, 元素个数, base=底数) 生成10^起始幂值 ~ 10^结束幂值范围内的, 指定个数的数据, 底数默认是10, 可以自定义
# arr13 = np.logspace(0, 5, 10) # 10^0 ~ 10^5之间, 10个元素, 等比数列
arr13 = np.logspace(0, 5, 10, base=2) # 2^0 ~ 2^5之间, 10个元素, 等比数列
print(f'数组对象: {arr13}') # [[1 1 1] [1 1 1]]
print(f'数组类型: {type(arr13)}') # <class 'numpy.ndarray'>
print(f'数组元素类型: {arr13.dtype}') # int64
(2)linspace()等差数列
# linspace(起始值, 结束值, 元素个数, endpoint=True|False) 生成起始值 ~ 结束值之间的, 指定元素个数的值, 等差数列, endpoint=True(默认), 包含结束值. False:不包含
arr14 = np.linspace(0, 5, 5) # 0 ~ 5之间, 5个数, 等差数列, endpoint=True(默认值)
arr14 = np.linspace(0, 5, 5, endpoint=False) # 0 ~ 5之间, 5个数, 等差数列, 包左不包右
print(f'数组对象: {arr14}') # [[1 1 1] [1 1 1]]
print(f'数组类型: {type(arr14)}') # <class 'numpy.ndarray'>
print(f'数组元素类型: {arr14.dtype}') # int64
三、Numpy的内置函数
1. 基本函数
# 基本函数如下: ceil(), floor(), rint(), isnan(), abs(), multiply(), divide(), where()
# np.ceil(): 向上最接近的整数,参数是 number 或 array
# np.floor(): 向下最接近的整数,参数是 number 或 array
# np.rint(): 四舍五入,参数是 number 或 array
# np.isnan(): 判断元素是否为 NaN(Not a Number),参数是 number 或 array
# np.multiply(): 元素相乘,参数是 number 或 array
# np.divide(): 元素相除,参数是 number 或 array
# np.abs():元素的绝对值,参数是 number 或 array
# np.where(condition, x, y): 三元运算符,x if condition else y
# 注意: 需要注意multiply/divide 如果是两个ndarray进行运算 shape必须一致代码演示:
# 1. 生成ndarray对象.
arr = np.random.randn(2, 3) # 获取1个标准的正态分布的 2行3列的数据.
print(f'arr的值为: {arr}') # [[-2.9442457 0.98108089 -0.10675188] [ 0.99740282 0.89240409 1.36733958]]# 2. 演示函数.
print(np.ceil(arr)) # [[-2 1 0] [ 1 1 2]]
print(np.floor(arr)) # [[-3 0 -1] [ 0 0 1]]
print(np.rint(arr)) # [[-3 1 -0] [ 1 1 1]]
print(np.isnan(arr)) # [[False False False] [ False False False]]
print(np.abs(arr)) # [[2.9442457 0.98108089 0.10675188] [ 0.99740282 0.89240409 1.36733958]]
print(np.multiply(arr, arr)) # [[...] [... ]]
print(np.divide(arr, arr)) # [[1 1 1] [1 1 1 ]]
print(np.where(arr > 0, 1, -1)) # [[-1 1 -1] [ 1 1 1]]2. 统计函数
# 统计函数介绍
# np.mean(), np.sum():所有元素的平均值,所有元素的和,参数是 number 或 array
# np.max(), np.min():所有元素的最大值,所有元素的最小值,参数是 number 或 array
# np.std(), np.var():所有元素的标准差,所有元素的方差,参数是 number 或 array
# np.argmax(), np.argmin():最大值的下标索引值,最小值的下标索引值,参数是 number 或 array
# np.cumsum(), np.cumprod():返回一个一维数组,每个元素都是之前所有元素的 累加和 和 累乘积,参数是 number 或 array
# 多维数组默认统计全部维度,axis参数可以按指定轴心统计,值为0则按列统计,值为1则按行统计。代码演示:
# 1. 生成1个ndarray对象
arr = np.arange(12).reshape((3, 4)) # 3行4列
print(f'元素内容: {arr}')# 2. 演示 cumsum(), 累加和.
print(np.cumsum(arr)) # [ 0 1 3 6 10 15 21 28 36 45 55 66]# 3. 演示 sum()求和.
print(np.sum(arr)) # 66
print(np.sum(arr, axis=0)) # [12, 15, 18, 21], 0是列.
print(np.sum(arr, axis=1)) # [6, 22, 38], 1是行.
3. 比较函数
# any() 任意1个元素满足即可, 返回True, 否则返回False
# all() 所有元素都要满足, 返回True, 否则返回False代码演示:
# 1. 生成1个数列.
arr = np.random.randn(2, 3) # 2行3列的 正态分布的数据.
print(arr) # [[-0.29235619 -1.00893783 -1.19750865] [ 0.10427346 1.45389378 0.26985633]]
print(np.any(arr > 0)) # 只要arr的任意1个元素大于0即可. True
print(np.all(arr > 0)) # arr的所有元素都要大于0即可. False
4. 排序函数
# 方式1: np.sort(arr) 排序, 并返回新的副本.
# 方式2: arr.sort() 对原数组排序.代码演示:
# 1. 获取ndarray对象
arr = np.array([1, 5, 3, 2, 6])
print(f'排序前: {arr}')# 2. 排序
# arr_copy = np.sort(arr)
# print(f'np.sort()方式: {arr_copy}')arr.sort() # 直接对 原数组排序# 3. 排序后
print(f'排序后: {arr}')
5. 去重函数
# unique(): 去重函数, 类似于Python的 set()集合.代码演示:
# 1. 创建ndarray对象
arr = np.array([[1, 2, 1, 6], [1, 3, 2, 5]]) # 细节: 列数要一致.
print(f'去重前: {arr}')# 2. 去重.
new_arr = np.unique(arr)# 3. 打印结果.
print(f'去重后: {new_arr}')
四、Numpy运算
1. 基本运算
# 数组的算数运算是按照元素的。新的数组被创建并且被结果填充。# 示例代码
import numpy as npa = np.array([20, 30, 40, 50])
b = np.arange(4)
c = a - b
print("数组a:", a)
print("数组b:", b)
print("数组运算a-b:", c)
2. 矩阵运算
arr_a.dot(arr_b) 前提arr_a 列数 = arr_b行数
(1)情况1: 行列数一致
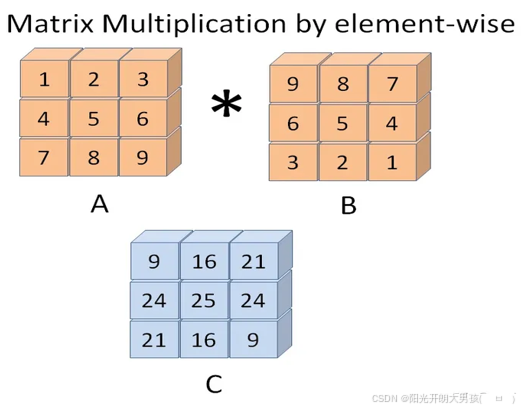
import numpy as npa = np.array([[1, 2, 3], [4, 5, 6]])
b = np.array([[1, 2, 3], [4, 5, 6]])
print(a * b)print(np.multiply(a, b))
(2)情况2: 行列数相反
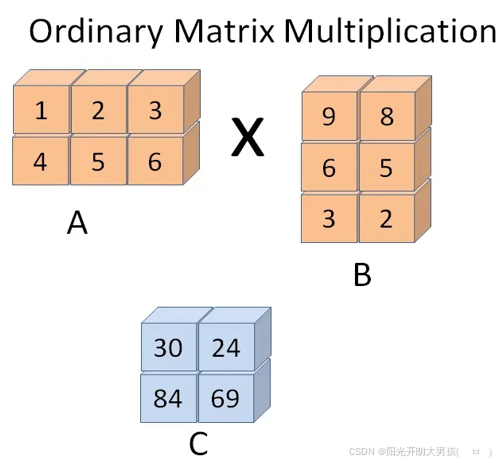
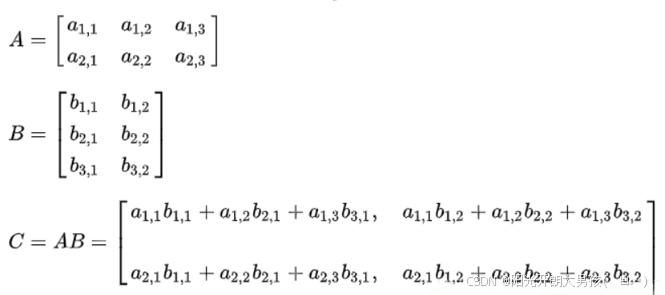
import numpy as npx = np.array([[1, 2, 3], [4, 5, 6]])
y = np.array([[6, 23], [-1, 7], [8, 9]])
print(x)
print(y)
print(x.dot(y))
print(np.dot(x, y))