Unity AI-使用Ollama本地大语言模型运行框架运行本地Deepseek等模型实现聊天对话(一)
一、Ollama介绍
官方网页:Ollama官方网址
中文文档参考:Ollama中文文档
相关教程:Ollama教程
Ollama 是一个开源的工具,旨在简化大型语言模型(LLM)在本地计算机上的运行和管理。它允许用户无需复杂的配置即可在本地部署和运行如Llama 3.3、DeepSeek-R1、Phi-4、Mistral、Gemma 2 和其他模型,适合开发者、研究人员以及对隐私和离线使用有需求的用户。
二、核心功能
- 本地运行模型
直接在个人电脑或服务器上运行模型,无需依赖云服务,保障数据隐私和离线可用性。 - 多平台支持
支持 macOS、Linux、Windows,并提供 Docker 镜像,方便跨平台部署。 - 模型管理
通过命令行轻松下载、更新或删除模型(如 ollama run llama2)。 - API 集成
提供 RESTful API,便于与其他应用(如 Python 脚本、自定义工具)集成。 - 多模型支持
兼容Llama 3.3、DeepSeek-R1、Phi-4、Mistral、Gemma 2 等,部分支持自定义模型加载。
三、Ollama安装
1、硬件要求
内存至少 8GB RAM,运行较大模型时推荐 16GB 或更高。部分大模型需显卡加速(如 NVIDIA GPU + CUDA)。
2、下载安装

官方网站下载对应版本。
下载完成后,打开安装程序并按照提示完成安装。
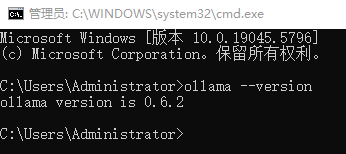
安装完成可以打开命令行管理器(CMD)或Powershell输入下面指令验证安装是否成功
ollama --version
3、运行模型
ollama run llama3.2
执行以上命令如果没有该模型会去下载 llama3.2 模型
ollama run deepseek-r1:7b
如果使用deepseekR1模型将命令替换为deepseek即可,7b是运行的模型大小
支持的模型访问ollama模型
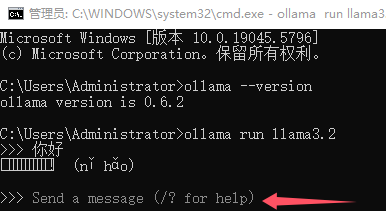
输入内容实现与模型对话(示例为llama3.2模型)