排序算法详解笔记(一)
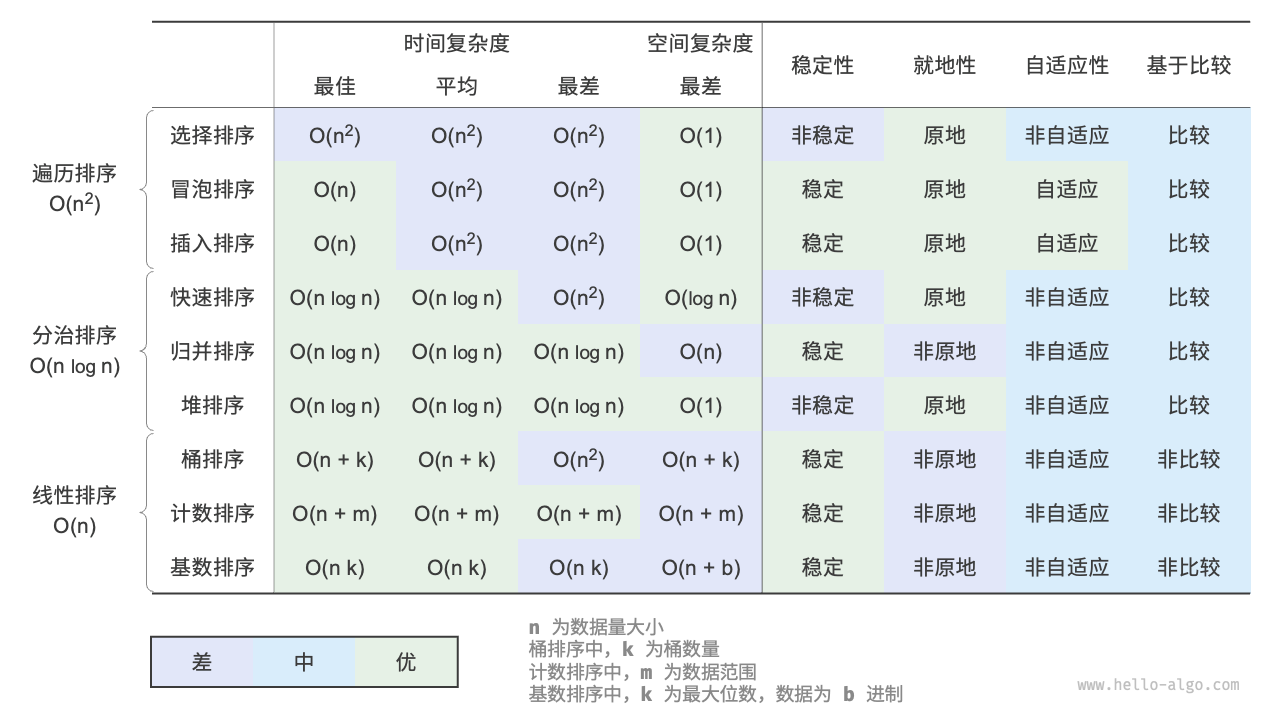
评价维度
- 运行效率
- 就地性
- 稳定性
自适应性:自适应排序能够利用输入数据已有的顺序信息来减少计算量,达到更优的时间效率。自适应排序算法的最佳时间复杂度通常优于平均时间复杂度。
是否基于比较:基于比较的排序依赖比较运算符(<、=、>)来判断元素的相对顺序,从而排序整个数组,理论最优时间复杂度为 O(nlogn) 。而非比较排序不使用比较运算符,时间复杂度可达 O(n) ,但其通用性相对较差。
非比较排序可以突破下界
如果都要比较,那比较次数也会影响性能,比较次数少性能就会好一点
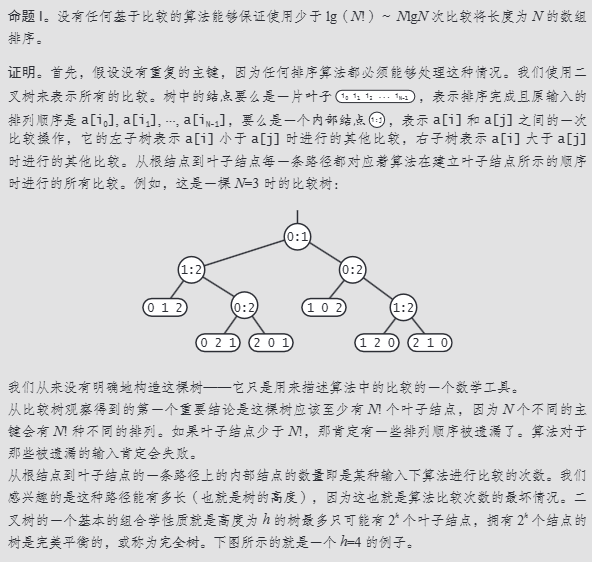
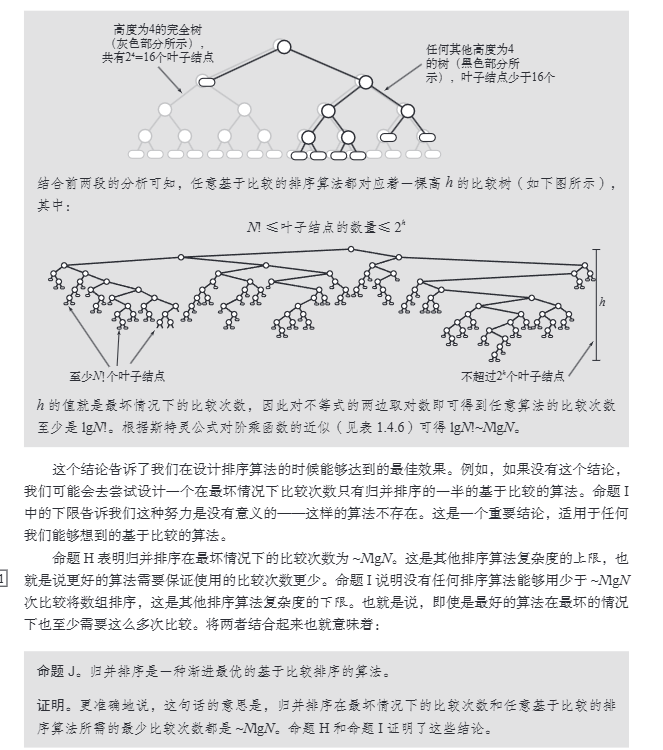
比较排序 O(N^2)
选择排序
选择排序(selection sort)的工作原理非常简单:开启一个循环,每轮从未排序区间选择最小的元素,将其放到已排序区间的末尾。
设数组的长度为 n 。
- 初始状态下,所有元素未排序,即未排序(索引)区间为 [0,n−1] 。
- 选取区间 [0,n−1] 中的最小元素,将其与索引 0 处的元素交换。完成后,数组前 1 个元素已排序。
- 选取区间 [1,n−1] 中的最小元素,将其与索引 1 处的元素交换。完成后,数组前 2 个元素已排序。
- 以此类推。经过 n−1 轮选择与交换后,数组前 n−1 个元素已排序。
- 仅剩的一个元素必定是最大元素,无须排序,因此数组排序完成。
/* 选择排序 */
void selectionSort(vector<int> &nums) {int n = nums.size();// 外循环:未排序区间为 [i, n-1]for (int i = 0; i < n - 1; i++) {// 内循环:找到未排序区间内的最小元素int k = i;for (int j = i + 1; j < n; j++) {if (nums[j] < nums[k])k = j; // 记录最小元素的索引}// 将该最小元素与未排序区间的首个元素交换swap(nums[i], nums[k]);}
}
- 时间复杂度为 O(n^2)、非自适应排序:外循环共 n−1 轮,第一轮的未排序区间长度为 n ,最后一轮的未排序区间长度为 2 ,即各轮外循环分别包含 n、n−1、…、3、2 轮内循环,求和为 (n−1)(n+2) 。
- 空间复杂度为 O(1)、==原地排序==:指针 i 和 j 使用常数大小的额外空间。
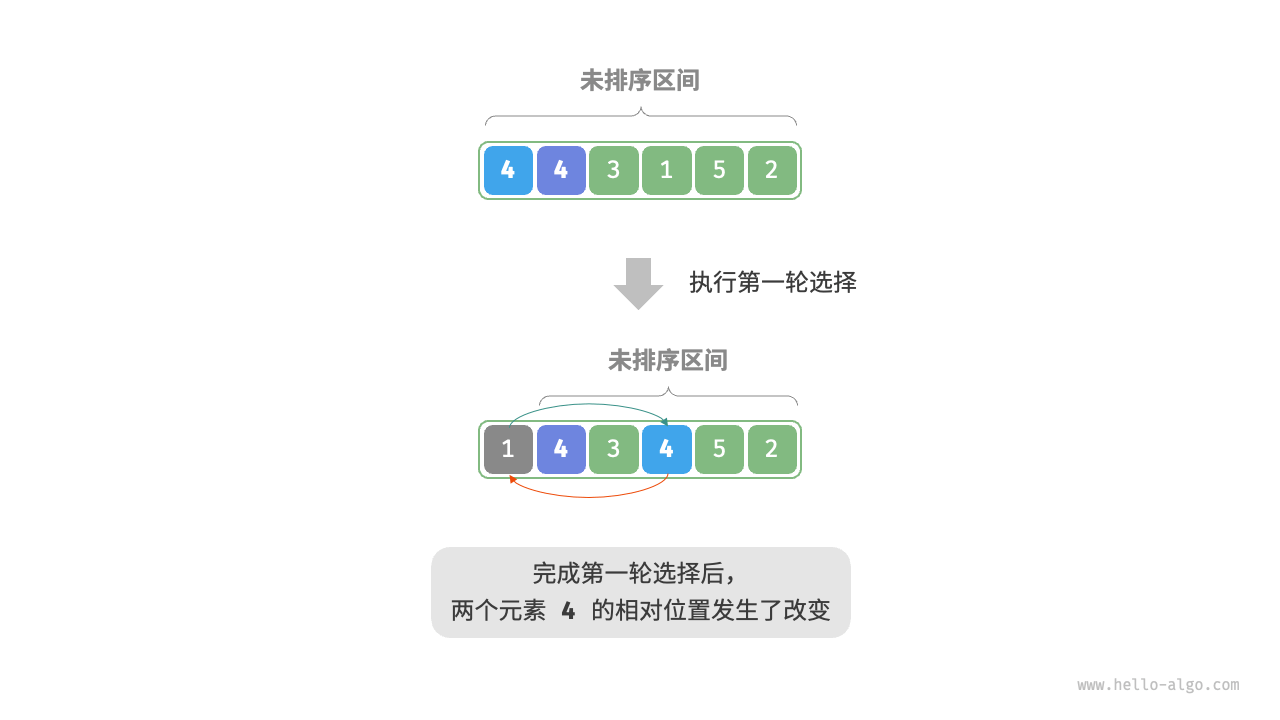
- 非稳定排序:如下图所示,元素
nums[i]有可能被交换至与其相等的元素的右边,导致两者的相对顺序发生改变。
冒泡排序 O(N^2)
冒泡排序(bubble sort)通过连续地比较与交换相邻元素实现排序。这个过程就像气泡从底部升到顶部一样,因此得名冒泡排序。
冒泡过程可以利用元素交换操作来模拟:从数组最左端开始向右遍历,依次比较相邻元素大小,如果“左元素 > 右元素”就交换二者。遍历完成后,最大的元素会被移动到数组的最右端。
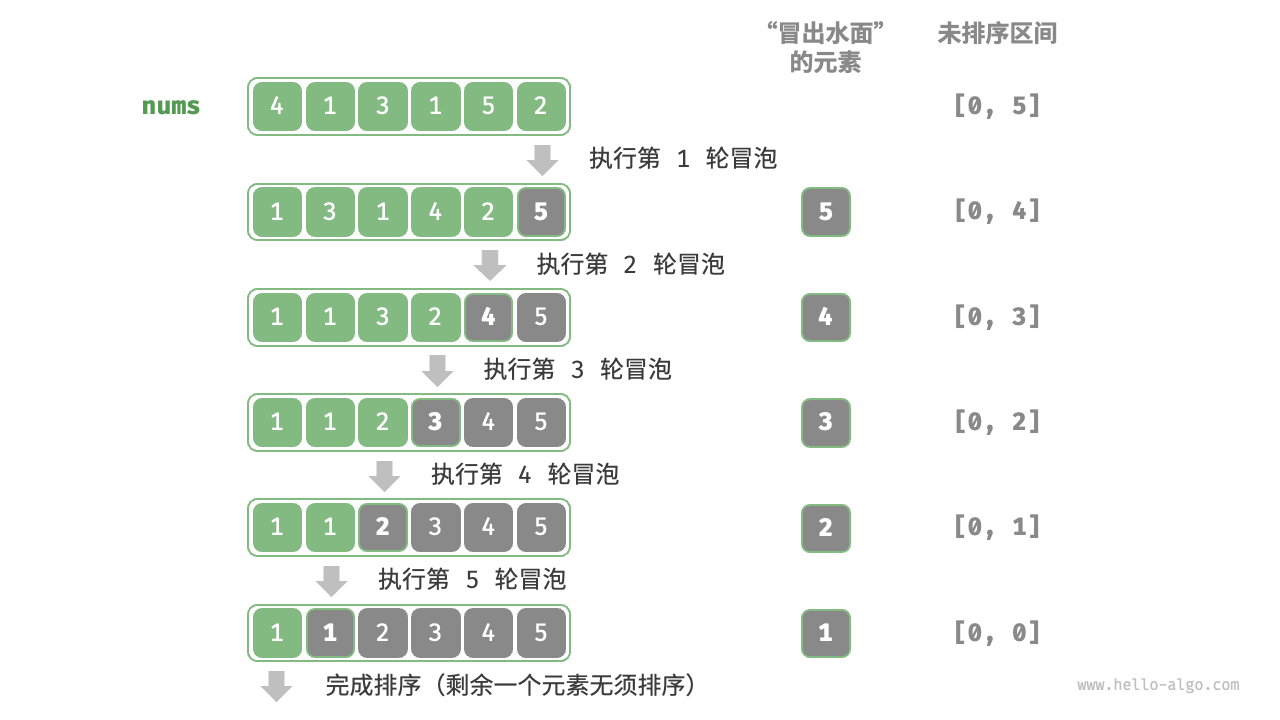
设数组的长度为 n ,冒泡排序的步骤如图 所示。
- 首先,对 n 个元素执行“冒泡”,将数组的最大元素交换至正确位置。
- 接下来,对剩余 n−1 个元素执行“冒泡”,将第二大元素交换至正确位置。
- 以此类推,经过 n−1 轮“冒泡”后,前 n−1 大的元素都被交换至正确位置。
- 仅剩的一个元素必定是最小元素,无须排序,因此数组排序完成。
void bubbleSort(vector<int> &nums){for(int i = nums.size()-1;i>0;i++){for(int j = 0;j<i;j++){if(nums[j]>nums[j+1]){swap(nums[j],nums[j+1]);}}}
}
引入flag优化
引入flag 优化
经过优化,冒泡排序的最差时间复杂度和平均时间复杂度仍为 𝑂(𝑛2) ;但当输入数组完全有序时,可达到最佳时间复杂度 𝑂(𝑛) 。
/* 冒泡排序(标志优化)*/
void bubbleSortWithFlag(vector<int> &nums) {// 外循环:未排序区间为 [0, i]for (int i = nums.size() - 1; i > 0; i--) {bool flag = false; // 初始化标志位// 内循环:将未排序区间 [0, i] 中的最大元素交换至该区间的最右端for (int j = 0; j < i; j++) {if (nums[j] > nums[j + 1]) {// 交换 nums[j] 与 nums[j + 1]// 这里使用了 std::swap() 函数swap(nums[j], nums[j + 1]);flag = true; // 记录交换元素}}if (!flag)break; // 此轮“冒泡”未交换任何元素,直接跳出}
}
- 时间复杂度为 O(n2)、自适应排序:各轮“冒泡”遍历的数组长度依次为 n−1、n−2、…、2、1 ,总和为 (n−1)n/2 。在引入
flag优化后,最佳时间复杂度可达到 O(n) 。 - 空间复杂度为 O(1)、原地排序:指针 i 和 j 使用常数大小的额外空间。
- 稳定排序:由于在“冒泡”中遇到相等元素不交换。
插入排序 O(N^2)
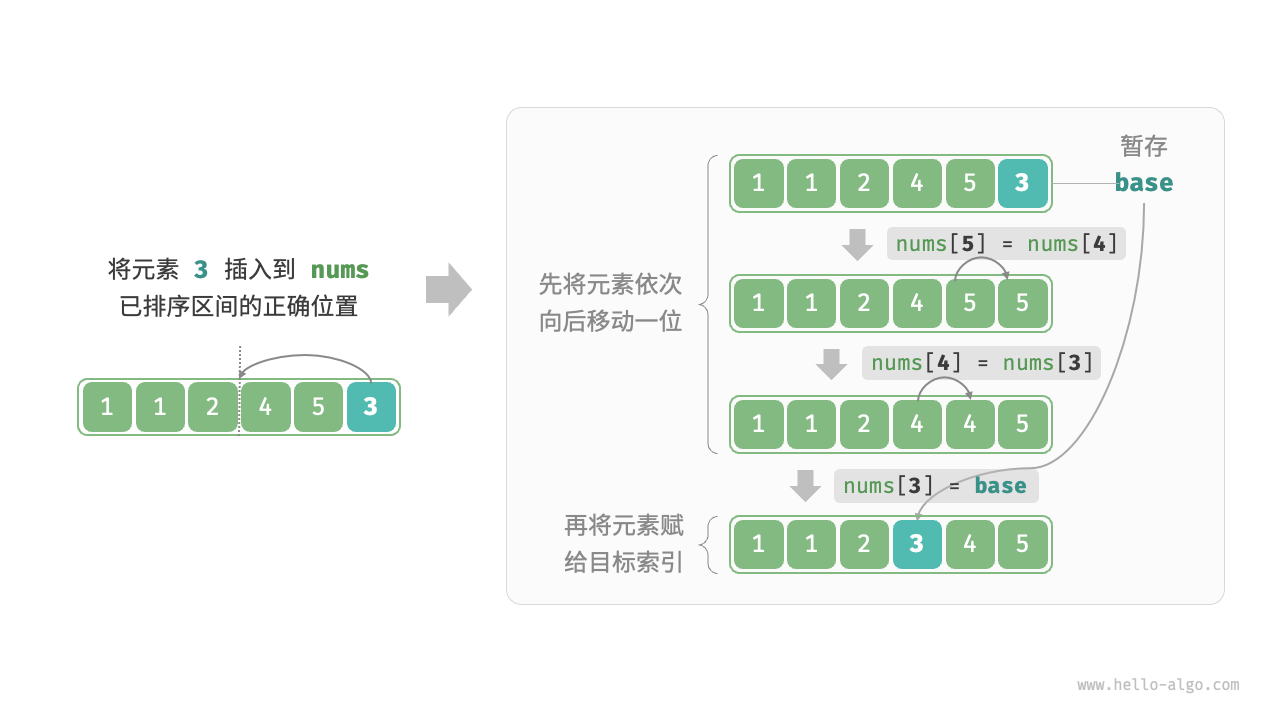
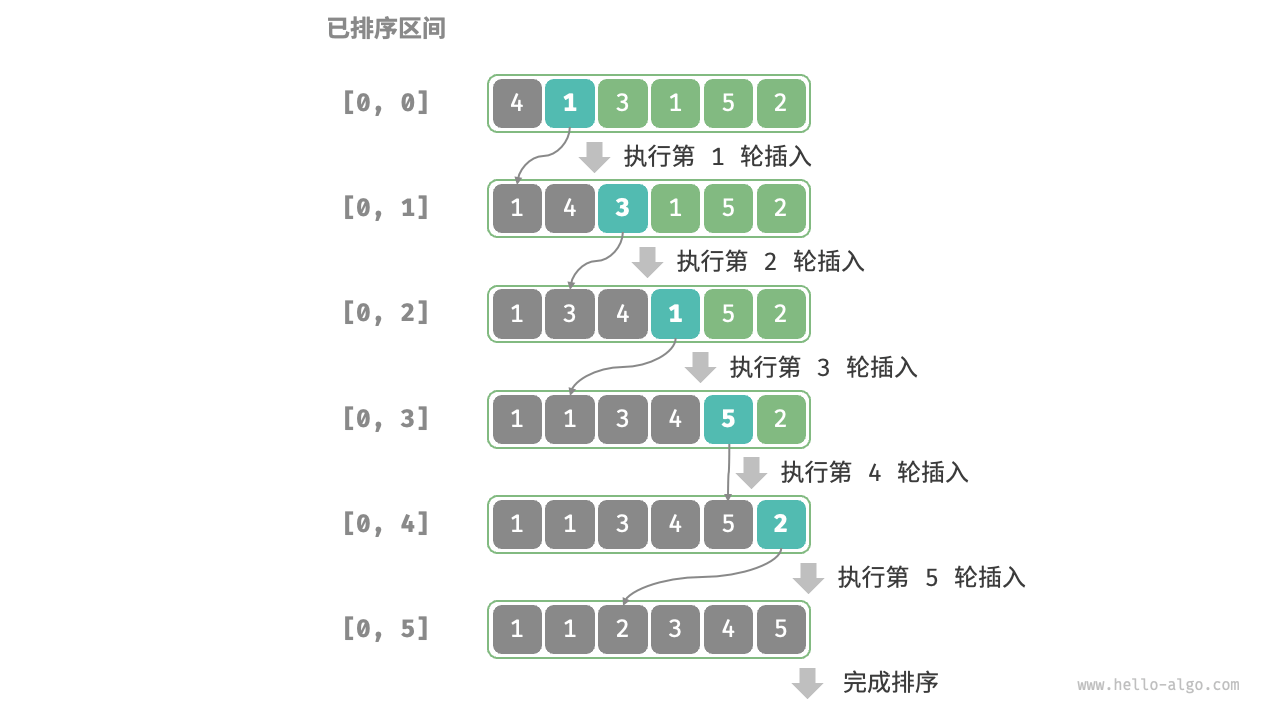
插入排序的整体流程。
- 初始状态下,数组的第 1 个元素已完成排序。
- 选取数组的第 2 个元素作为
base,将其插入到正确位置后,数组的前 2 个元素已排序。 - 选取第 3 个元素作为
base,将其插入到正确位置后,数组的前 3 个元素已排序。 - 以此类推,在最后一轮中,选取最后一个元素作为
base,将其插入到正确位置后,所有元素均已排序。
/* 插入排序 */
void insertionSort(vector<int> &nums) {// 外循环:已排序区间为 [0, i-1]for (int i = 1;i<nums.size();i++) {int base = nums[i],j = i-1;// 内循环:将 base 插入到已排序区间 [0, i-1] 中的正确位置while (j>=0&&nums[j]>base) {nums[j+1] = nums[j];j--;}// 将 base 赋值到正确位置nums[j+1] = base;}
}
- 时间复杂度为 O(n2)、自适应排序:在最差情况下,每次插入操作分别需要循环 n−1、n−2、…、2、1 次,求和得到 (n−1)n/2 ,因此时间复杂度为 O(n2) 。在遇到有序数据时,插入操作会提前终止。当输入数组完全有序时,插入排序达到最佳时间复杂度 O(n) 。
- 空间复杂度为 O(1)、原地排序:指针 i 和 j 使用常数大小的额外空间。
- 稳定排序:在插入操作过程中,我们会将元素插入到相等元素的右侧,不会改变它们的顺序。

优势
插入排序的时间复杂度为 O(n2) ,而我们即将学习的快速排序的时间复杂度为 O(nlogn) 。尽管插入排序的时间复杂度更高,但在数据量较小的情况下,插入排序通常更快。
这个结论与线性查找和二分查找的适用情况的结论类似。快速排序这类 O(nlogn) 的算法属于基于分治策略的排序算法,往往包含更多单元计算操作。而在数据量较小时,n2 和 nlogn 的数值比较接近,复杂度不占主导地位,每轮中的单元操作数量起到决定性作用。
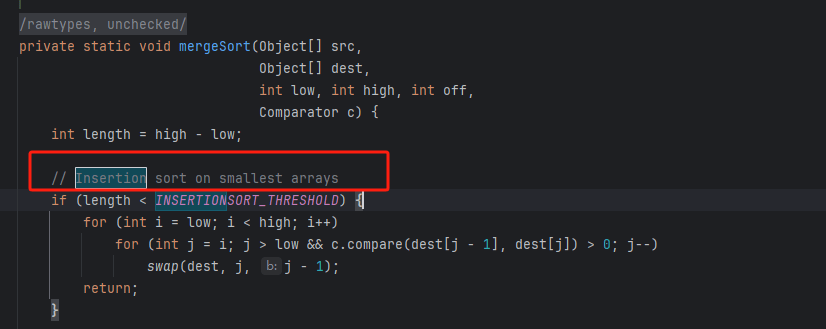
实际上,许多编程语言(例如 Java)的内置排序函数采用了插入排序,大致思路为:对于长数组,采用基于分治策略的排序算法,例如快速排序;对于短数组,直接使用插入排序。如下图所示。
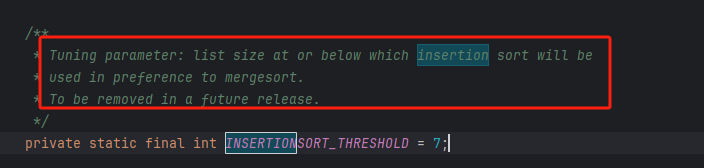
/** * Tuning parameter: list size at or below which insertion sort will be * used in preference to mergesort. * To be removed in a future release. */private static final int INSERTIONSORT_THRESHOLD = 7; /** * Src is the source array that starts at index 0 * Dest is the (possibly larger) array destination with a possible offset * low is the index in dest to start sorting * high is the end index in dest to end sorting * off is the offset to generate corresponding low, high in src * To be removed in a future release. */@SuppressWarnings({"unchecked", "rawtypes"})
private static void mergeSort(Object[] src, Object[] dest, int low, int high, int off) { int length = high - low; // Insertion sort on smallest arrays if (length < INSERTIONSORT_THRESHOLD) { for (int i=low; i<high; i++) for (int j=i; j>low && ((Comparable) dest[j-1]).compareTo(dest[j])>0; j--) swap(dest, j, j-1); return; } // Recursively sort halves of dest into src int destLow = low; int destHigh = high; low += off; high += off; int mid = (low + high) >>> 1; mergeSort(dest, src, low, mid, -off); mergeSort(dest, src, mid, high, -off); // If list is already sorted, just copy from src to dest. This is an // optimization that results in faster sorts for nearly ordered lists. if (((Comparable)src[mid-1]).compareTo(src[mid]) <= 0) { System.arraycopy(src, low, dest, destLow, length); return; } // Merge sorted halves (now in src) into dest for(int i = destLow, p = low, q = mid; i < destHigh; i++) { if (q >= high || p < mid && ((Comparable)src[p]).compareTo(src[q])<=0) dest[i] = src[p++]; else dest[i] = src[q++]; }
}
虽然冒泡排序、选择排序和插入排序的时间复杂度都为 O(n2) ,但在实际情况中,插入排序的使用频率显著高于冒泡排序和选择排序,主要有以下原因。
- 冒泡排序基于元素交换实现,需要借助一个临时变量,共涉及 3 个单元操作;插入排序基于元素赋值实现,仅需 1 个单元操作。因此,冒泡排序的计算开销通常比插入排序更高。
- 选择排序在任何情况下的时间复杂度都为 O(n2) 。如果给定一组部分有序的数据,插入排序通常比选择排序效率更高。
- 选择排序不稳定,无法应用于多级排序。
快速排序 O(NlogN)
快速排序(quick sort)是一种基于分治策略的排序算法,运行高效,应用广泛。
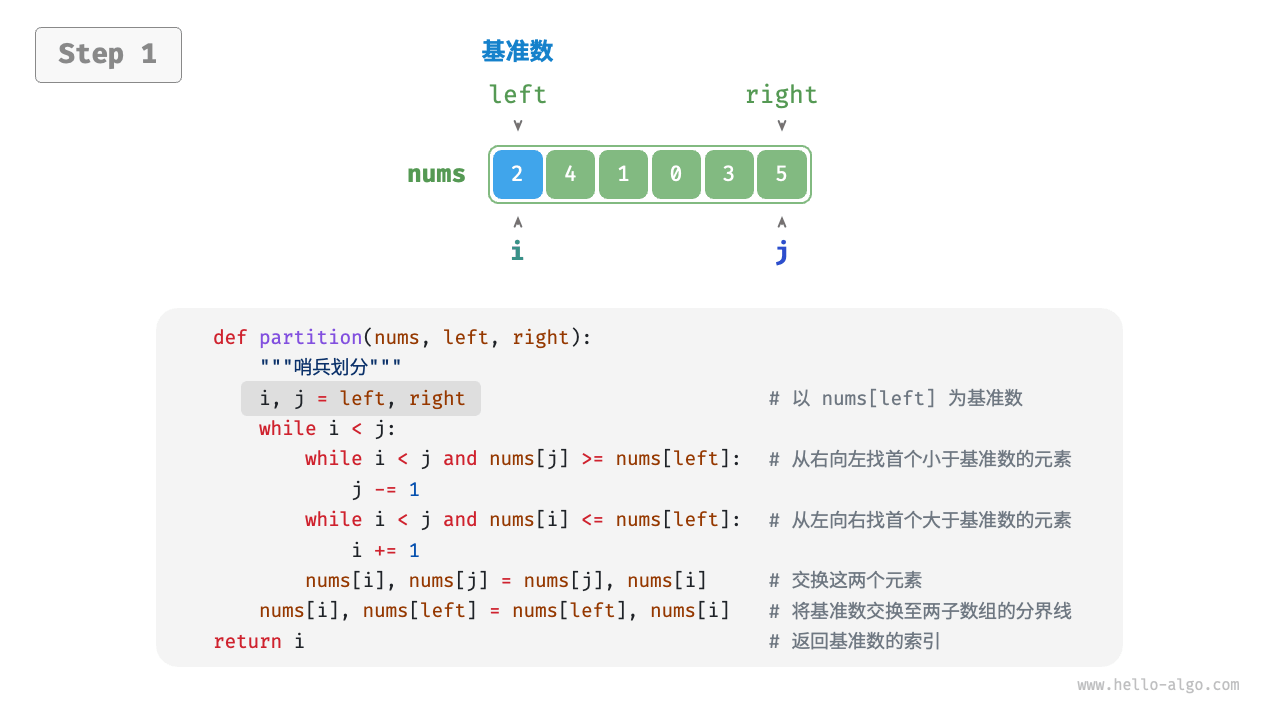
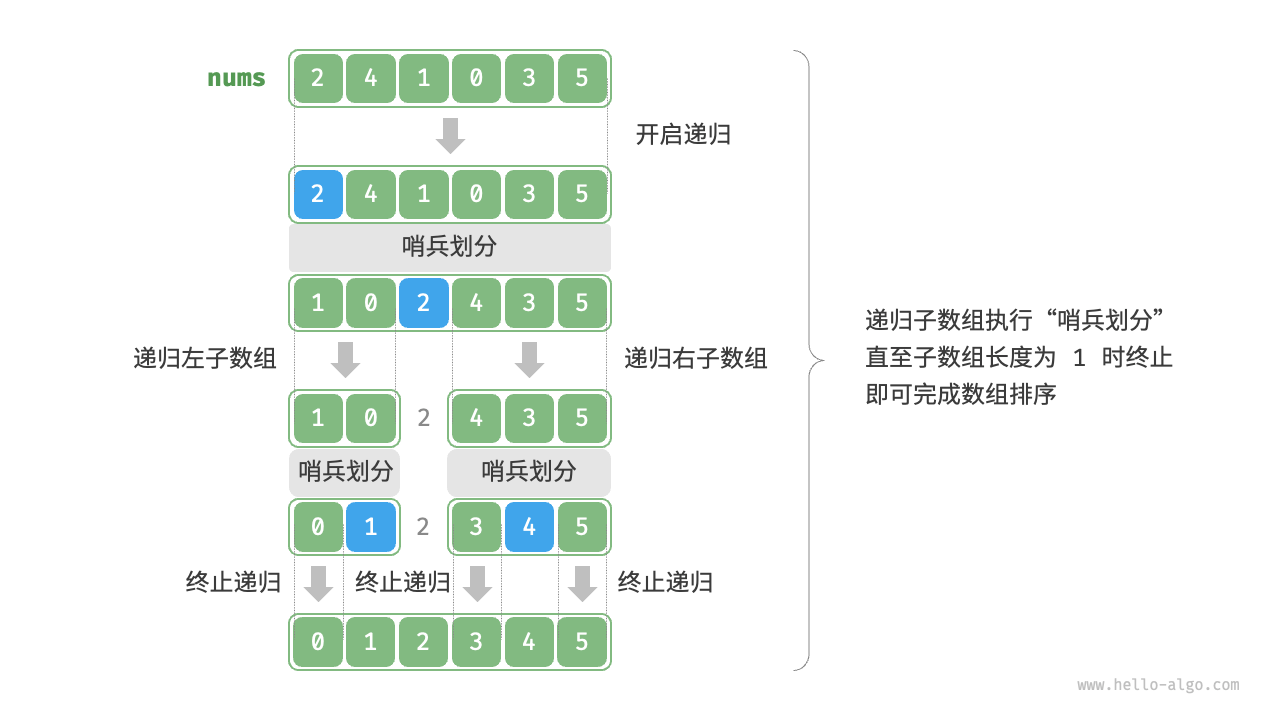
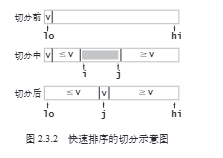
快速排序的核心操作是“哨兵划分”,其目标是:选择数组中的某个元素作为“基准数”,将所有小于基准数的元素移到其左侧,而大于基准数的元素移到其右侧。具体来说,哨兵划分的流程。
- 选取数组最左端元素作为基准数,初始化两个指针
i和j分别指向数组的两端。 - 设置一个循环,在每轮中使用
i(j)分别寻找第一个比基准数大(小)的元素,然后交换这两个元素。 - 循环执行步骤
2.,直到i和j相遇时停止,最后将基准数交换至两个子数组的分界线。
/* 哨兵划分 */
int partition(vector<int> &nums, int left, int right) {// 以 nums[left] 为基准数int i = left, j = right;while (i < j) {while (i < j && nums[j] >= nums[left])j--; // 从右向左找首个小于基准数的元素while (i < j && nums[i] <= nums[left])i++; // 从左向右找首个大于基准数的元素swap(nums[i], nums[j]); // 交换这两个元素}swap(nums[i], nums[left]); // 将基准数交换至两子数组的分界线return i; // 返回基准数的索引
}
/* 快速排序 */
void quickSort(vector<int> &nums, int left, int right) {// 子数组长度为 1 时终止递归if (left >= right)return;// 哨兵划分int pivot = partition(nums, left, right);// 递归左子数组、右子数组quickSort(nums, left, pivot - 1);quickSort(nums, pivot + 1, right);
}
- 时间复杂度为 O(nlogn)、非自适应排序:在平均情况下,哨兵划分的递归层数为 logn ,每层中的总循环数为 n ,总体使用 O(nlogn) 时间。在最差情况下,每轮哨兵划分操作都将长度为 n 的数组划分为长度为 0 和 n−1 的两个子数组,此时递归层数达到 n ,每层中的循环数为 n ,总体使用 O(n2) 时间。
- 空间复杂度为 O(n)、原地排序:在输入数组完全倒序的情况下,达到最差递归深度 n ,使用 O(n) 栈帧空间。排序操作是在原数组上进行的,未借助额外数组。
- 非稳定排序:在哨兵划分的最后一步,基准数可能会被交换至相等元素的右侧。
优化
原始的切分:
- 对于某个j,a[j]已排定
- a[lo]到a[j-1]中的所有袁术都不大于a[j]
- a[j+1]到a[hi]中的所有元素都不小于a[j]
对于小数组,快速排序比插入排序慢
因为递归,快速排序在小数组中也会调用自己
- 三取样切分
/* 选取三个候选元素的中位数 */
int medianThree(vector<int> &nums, int left, int mid, int right) {int l = nums[left], m = nums[mid], r = nums[right];if ((l <= m && m <= r) || (r <= m && m <= l))return mid; // m 在 l 和 r 之间if ((m <= l && l <= r) || (r <= l && l <= m))return left; // l 在 m 和 r 之间return right;
}/* 哨兵划分(三数取中值) */
int partition(vector<int> &nums, int left, int right) {// 选取三个候选元素的中位数int med = medianThree(nums, left, (left + right) / 2, right);// 将中位数交换至数组最左端swap(nums[left], nums[med]);// 以 nums[left] 为基准数int i = left, j = right;while (i < j) {while (i < j && nums[j] >= nums[left])j--; // 从右向左找首个小于基准数的元素while (i < j && nums[i] <= nums[left])i++; // 从左向右找首个大于基准数的元素swap(nums[i], nums[j]); // 交换这两个元素}swap(nums[i], nums[left]); // 将基准数交换至两子数组的分界线return i; // 返回基准数的索引
}
- 递归优化

在某些输入下,快速排序可能占用空间较多。以完全有序的输入数组为例,设递归中的子数组长度为 m ,每轮哨兵划分操作都将产生长度为 0 的左子数组和长度为 m−1 的右子数组,这意味着每一层递归调用减少的问题规模非常小(只减少一个元素),递归树的高度会达到 n−1 ,此时需要占用 O(n) 大小的栈帧空间。
为了防止栈帧空间的累积,我们可以在每轮哨兵排序完成后,比较两个子数组的长度,仅对较短的子数组进行递归。由于较短子数组的长度不会超过 n/2 ,因此这种方法能确保递归深度不超过 logn ,从而将最差空间复杂度优化至 O(logn) 。代码如下所示
/* 快速排序(尾递归优化) */
void quickSort(vector<int> &nums, int left, int right) {// 子数组长度为 1 时终止while (left < right) {// 哨兵划分操作int pivot = partition(nums, left, right);// 对两个子数组中较短的那个执行快速排序if (pivot - left < right - pivot) {quickSort(nums, left, pivot - 1); // 递归排序左子数组left = pivot + 1; // 剩余未排序区间为 [pivot + 1, right]} else {quickSort(nums, pivot + 1, right); // 递归排序右子数组right = pivot - 1; // 剩余未排序区间为 [left, pivot - 1]}}
}
- 三向切分


#include <vector>
using namespace std;// 交换函数
template<typename T>
void exch(vector<T>& a, int i, int j) {T temp = a[i];a[i] = a[j];a[j] = temp;
}// 插入排序
template<typename T>
void insertionSort(vector<T>& a, int lo, int hi) {for (int i = lo + 1; i <= hi; i++) {T temp = a[i];int j = i;while (j > lo && a[j-1] > temp) {a[j] = a[j-1];j--;}a[j] = temp;}
}// Bentley-McIlroy三向切分快速排序
template<typename T>
void quickSortBentleyMcIlroy(vector<T>& a, int lo, int hi, int M) {if (hi - lo + 1 <= M) {insertionSort(a, lo, hi);return;}int p = lo; // p指向等于pivot的左侧区域的右边界+1int q = hi; // q指向等于pivot的右侧区域的左边界-1int i = lo; // i指向小于pivot的区域的右边界+1int j = hi; // j指向大于pivot的区域的左边界-1T pivot = a[lo];while (i <= j) {// 处理小于pivot的元素while (i <= j && a[i] <= pivot) {if (a[i] == pivot) {exch(a, p, i);p++;}i++;}// 处理大于pivot的元素while (i <= j && a[j] >= pivot) {if (a[j] == pivot) {exch(a, j, q);q--;}j--;}if (i <= j) {exch(a, i, j);i++;j--;}}// 将左侧的等于pivot的元素移到中间int k = lo;while (k < p) {exch(a, k, j);k++;j--;}// 将右侧的等于pivot的元素移到中间k = hi;while (k > q) {exch(a, i, k);k--;i++;}// 递归排序左右两部分quickSortBentleyMcIlroy(a, lo, j, M);quickSortBentleyMcIlroy(a, i, hi, M);
}// 排序入口函数
template<typename T>
void sort(vector<T>& a, int M = 10) {quickSortBentleyMcIlroy(a, 0, a.size() - 1, M);
}
实验验证
小规模数组 (1000 个元素)
| 测试类型 | 普通快速排序 | 三向切分快速排序 | 速度比较 |
|---|---|---|---|
| 随机数组 | 0.2322 ms | 0.2369 ms | 普通快排略快 (1.02×) |
| 重复元素较多 (唯一元素数量: 10) | 0.1399 ms | 0.0153 ms | 三向快排明显更快 (9.14×) |
中等规模数组 (100,000 个元素)
| 测试类型 | 普通快速排序 | 三向切分快速排序 | 速度比较 |
|---|---|---|---|
| 随机数组 | 4.4053 ms | 6.7698 ms | 普通快排更快 (1.54×) |
| 重复元素较多 (唯一元素数量: 100) | 29.5879 ms | 1.8805 ms | 三向快排显著更快 (15.73×) |
大规模数组 (1,000,000 个元素)
| 测试类型 | 普通快速排序 | 三向切分快速排序 | 速度比较 |
|---|---|---|---|
| 随机数组 | 57.8245 ms | 64.6942 ms | 普通快排略快 (1.12×) |
| 重复元素较多 (唯一元素数量: 1000) | 272.8528 ms | 31.4603 ms | 三向快排极大提升 (8.67×) |
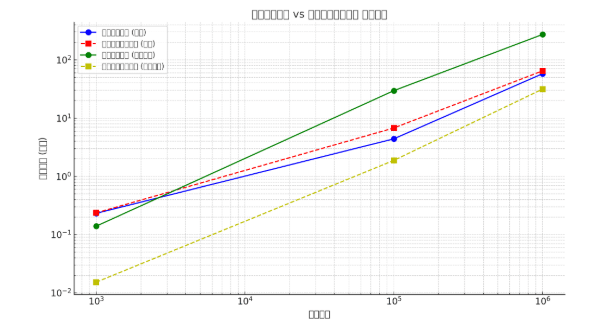
结论
- 随机数据:普通快速排序在所有规模上都略微快于三向切分快速排序
- 重复元素较多的数据:三向切分快速排序有巨大优势,在中等规模数组上最高可达15.73倍性能提升
- 数据规模影响:随着数据规模增大,处理重复元素时三向切分方法的优势愈发明显
在实际应用中,如果预期数据中重复元素较多,特别是在处理大规模数据时,三向切分快速排序会是更好的选择。

import java.util.Arrays;
import java.util.Random;public class QuickSortTest {// 普通快速排序public static void quickSort(int[] arr, int low, int high) {if (low < high) {int pivot = partition(arr, low, high);quickSort(arr, low, pivot - 1);quickSort(arr, pivot + 1, high);}}private static int partition(int[] arr, int low, int high) {int pivot = arr[high];int i = low - 1;for (int j = low; j < high; j++) {if (arr[j] <= pivot) {i++;swap(arr, i, j);}}swap(arr, i + 1, high);return i + 1;}// 三向切分的快速排序public static void quickSort3Way(int[] arr, int low, int high) {if (high <= low) return;int lt = low, i = low + 1, gt = high;int pivot = arr[low];while (i <= gt) {if (arr[i] < pivot) {swap(arr, lt++, i++);} else if (arr[i] > pivot) {swap(arr, i, gt--);} else {i++;}}quickSort3Way(arr, low, lt - 1);quickSort3Way(arr, gt + 1, high);}private static void swap(int[] arr, int i, int j) {int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}// 生成随机数组private static int[] generateRandomArray(int size, int maxValue) {Random random = new Random();int[] arr = new int[size];for (int i = 0; i < size; i++) {arr[i] = random.nextInt(maxValue);}return arr;}// 生成有大量重复元素的数组private static int[] generateArrayWithDuplicates(int size, int uniqueCount) {Random random = new Random();int[] arr = new int[size];for (int i = 0; i < size; i++) {arr[i] = random.nextInt(uniqueCount);}return arr;}// 验证数组是否排序正确private static boolean isSorted(int[] arr) {for (int i = 1; i < arr.length; i++) {if (arr[i - 1] > arr[i]) {return false;}}return true;}// 运行测试private static void runTest(String testName, int size, int maxValue, int uniqueCount) {System.out.println("=== " + testName + " ===");System.out.println("数组大小: " + size);// 测试随机数组int[] arr1 = generateRandomArray(size, maxValue);int[] arr2 = Arrays.copyOf(arr1, arr1.length);System.out.println("随机数组测试:");// 测试普通快速排序long startTime = System.nanoTime();quickSort(arr1, 0, arr1.length - 1);long endTime = System.nanoTime();double duration = (endTime - startTime) / 1_000_000.0;System.out.println("普通快速排序时间: " + duration + " ms");System.out.println("排序正确: " + isSorted(arr1));// 测试三向切分快速排序startTime = System.nanoTime();quickSort3Way(arr2, 0, arr2.length - 1);endTime = System.nanoTime();duration = (endTime - startTime) / 1_000_000.0;System.out.println("三向切分快速排序时间: " + duration + " ms");System.out.println("排序正确: " + isSorted(arr2));// 测试大量重复元素的数组int[] arr3 = generateArrayWithDuplicates(size, uniqueCount);int[] arr4 = Arrays.copyOf(arr3, arr3.length);System.out.println("\n重复元素较多的数组测试 (唯一元素数量: " + uniqueCount + "):");// 测试普通快速排序startTime = System.nanoTime();quickSort(arr3, 0, arr3.length - 1);endTime = System.nanoTime();duration = (endTime - startTime) / 1_000_000.0;System.out.println("普通快速排序时间: " + duration + " ms");System.out.println("排序正确: " + isSorted(arr3));// 测试三向切分快速排序startTime = System.nanoTime();quickSort3Way(arr4, 0, arr4.length - 1);endTime = System.nanoTime();duration = (endTime - startTime) / 1_000_000.0;System.out.println("三向切分快速排序时间: " + duration + " ms");System.out.println("排序正确: " + isSorted(arr4));System.out.println();}public static void main(String[] args) {// 测试小规模数组runTest("小规模数组", 1000, 1000, 10);// 测试中等规模数组runTest("中等规模数组", 100000, 100000, 100);// 测试大规模数组runTest("大规模数组", 1000000, 1000000, 1000);}
}归并排序 O(NlogN)
“划分阶段”从顶至底递归地将数组从中点切分为两个子数组。
- 计算数组中点
mid,递归划分左子数组(区间[left, mid])和右子数组(区间[mid + 1, right])。 - 递归执行步骤
1.,直至子数组区间长度为 1 时终止。
“合并阶段”从底至顶地将左子数组和右子数组合并为一个有序数组。需要注意的是,从长度为 1 的子数组开始合并,合并阶段中的每个子数组都是有序的。
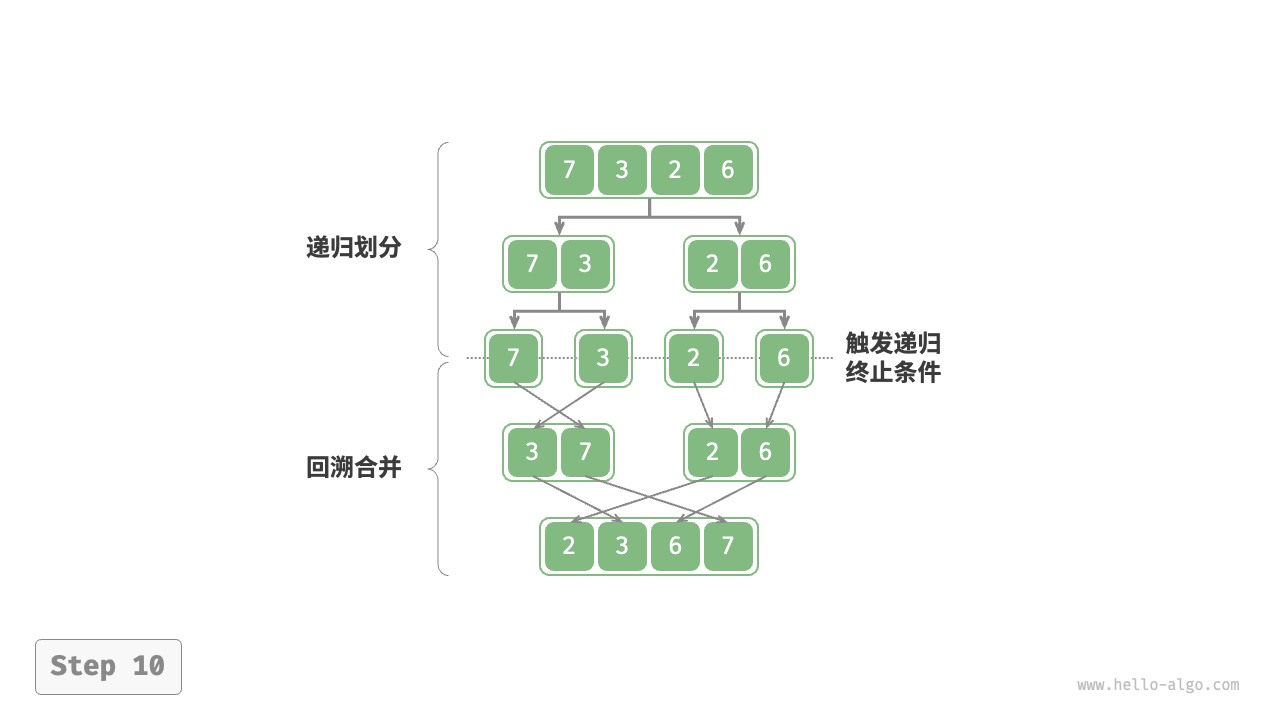
观察发现,归并排序与二叉树后序遍历的递归顺序是一致的。
- 后序遍历:先递归左子树,再递归右子树,最后处理根节点。
- 归并排序:先递归左子数组,再递归右子数组,最后处理合并。
归并排序的实现如以下代码所示。请注意,nums 的待合并区间为 [left, right] ,而 tmp 的对应区间为 [0, right - left] 。
/* 合并左子数组和右子数组 */
void merge(vector<int> &nums, int left, int mid, int right) {// 左子数组区间为 [left, mid], 右子数组区间为 [mid+1, right]// 创建一个临时数组 tmp ,用于存放合并后的结果vector<int> tmp(right - left + 1);// 初始化左子数组和右子数组的起始索引int i = left, j = mid + 1, k = 0;// 当左右子数组都还有元素时,进行比较并将较小的元素复制到临时数组中while (i <= mid && j <= right) {if (nums[i] <= nums[j])tmp[k++] = nums[i++];elsetmp[k++] = nums[j++];}// 将左子数组和右子数组的剩余元素复制到临时数组中while (i <= mid) {tmp[k++] = nums[i++];}while (j <= right) {tmp[k++] = nums[j++];}// 将临时数组 tmp 中的元素复制回原数组 nums 的对应区间for (k = 0; k < tmp.size(); k++) {nums[left + k] = tmp[k];}
}/* 归并排序 */
void mergeSort(vector<int> &nums, int left, int right) {// 终止条件if (left >= right)return; // 当子数组长度为 1 时终止递归// 划分阶段int mid = left + (right - left) / 2; // 计算中点mergeSort(nums, left, mid); // 递归左子数组mergeSort(nums, mid + 1, right); // 递归右子数组// 合并阶段merge(nums, left, mid, right);
}
- 时间复杂度为 O(nlogn)、非自适应排序:划分产生高度为 logn 的递归树,每层合并的总操作数量为 n ,因此总体时间复杂度为 O(nlogn) 。
- 空间复杂度为 O(n)、非原地排序:递归深度为 logn ,使用 O(logn) 大小的栈帧空间。合并操作需要借助辅助数组实现,使用 O(n) 大小的额外空间。
- 稳定排序:在合并过程中,相等元素的次序保持不变。
对于链表,归并排序相较于其他排序算法具有显著优势,可以将链表排序任务的空间复杂度优化至 O(1) 。
- 划分阶段:可以使用“迭代”替代“递归”来实现链表划分工作,从而省去递归使用的栈帧空间。
- 合并阶段:在链表中,节点增删操作仅需改变引用(指针)即可实现,因此合并阶段(将两个短有序链表合并为一个长有序链表)无须创建额外链表。
#include <iostream>// 定义链表节点结构
struct ListNode {int val;ListNode* next;ListNode(int x) : val(x), next(nullptr) {}
};// 合并两个有序链表,返回合并后的头指针
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {ListNode dummy(0);ListNode* tail = &dummy;while (l1 && l2) {if (l1->val < l2->val) {tail->next = l1;l1 = l1->next;} else {tail->next = l2;l2 = l2->next;}tail = tail->next;}tail->next = l1 ? l1 : l2;return dummy.next;
}// 计算链表长度
int getLength(ListNode* head) {int len = 0;while (head) {++len;head = head->next;}return len;
}// 非递归自底向上归并排序
ListNode* mergeSortList(ListNode* head) {if (!head || !head->next) return head;int n = getLength(head);ListNode dummy(0);dummy.next = head;ListNode* left;ListNode* right;ListNode* tail;for (int step = 1; step < n; step <<= 1) {ListNode* curr = dummy.next;tail = &dummy;while (curr) {left = curr;// 划分左子链表int leftSize = step;for (int i = 1; i < leftSize && curr->next; ++i) {curr = curr->next;}right = curr->next;curr->next = nullptr; // 切断左链表curr = right;// 划分右子链表int rightSize = step;for (int i = 1; i < rightSize && curr && curr->next; ++i) {curr = curr->next;}ListNode* nextSub = nullptr;if (curr) {nextSub = curr->next;curr->next = nullptr; // 切断右链表}// 合并左右链表ListNode* merged = mergeTwoLists(left, right);// 将合并后的部分链接回主链表tail->next = merged;while (tail->next) tail = tail->next;// 继续处理剩余部分curr = nextSub;}}return dummy.next;
}// 辅助:打印链表
void printList(ListNode* head) {while (head) {std::cout << head->val;if (head->next) std::cout << " -> ";head = head->next;}std::cout << std::endl;
}int main() {// 测试示例ListNode* head = new ListNode(4);head->next = new ListNode(2);head->next->next = new ListNode(1);head->next->next->next = new ListNode(3);head->next->next->next->next = new ListNode(2);std::cout << "排序前: ";printList(head);head = mergeSortList(head);std::cout << "排序后: ";printList(head);return 0;
}堆排序 O(NlogN)
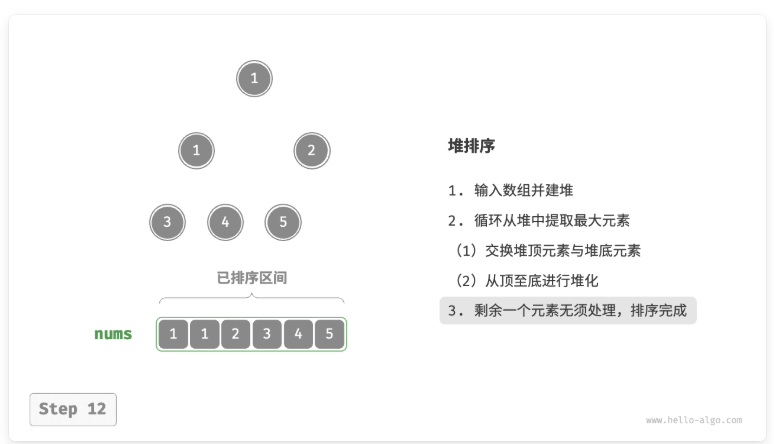
设数组的长度为 n ,堆排序的流程。
- 输入数组并建立大顶堆。完成后,最大元素位于堆顶。
- 将堆顶元素(第一个元素)与堆底元素(最后一个元素)交换。完成交换后,堆的长度减 1 ,已排序元素数量加 1 。
- 从堆顶元素开始,从顶到底执行堆化操作(sift down)。完成堆化后,堆的性质得到修复。
- 循环执行第
2.步和第3.步。循环 n−1 轮后,即可完成数组排序。
/* 堆的长度为 n ,从节点 i 开始,从顶至底堆化 */
void siftDown(vector<int> &nums, int n, int i) {while (true) {// 判断节点 i, l, r 中值最大的节点,记为 maint l = 2 * i + 1;int r = 2 * i + 2;int ma = i;if (l < n && nums[l] > nums[ma])ma = l;if (r < n && nums[r] > nums[ma])ma = r;// 若节点 i 最大或索引 l, r 越界,则无须继续堆化,跳出if (ma == i) {break;}// 交换两节点swap(nums[i], nums[ma]);// 循环向下堆化i = ma;}
}/* 堆排序 */
void heapSort(vector<int> &nums) {// 建堆操作:堆化除叶节点以外的其他所有节点for (int i = nums.size() / 2 - 1; i >= 0; --i) {siftDown(nums, nums.size(), i);}// 从堆中提取最大元素,循环 n-1 轮for (int i = nums.size() - 1; i > 0; --i) {// 交换根节点与最右叶节点(交换首元素与尾元素)swap(nums[0], nums[i]);// 以根节点为起点,从顶至底进行堆化siftDown(nums, i, 0);}
}
- 时间复杂度为 O(nlogn)、非自适应排序:建堆操作使用 O(n) 时间。从堆中提取最大元素的时间复杂度为 O(logn) ,共循环 n−1 轮。
- 空间复杂度为 O(1)、原地排序:几个指针变量使用 O(1) 空间。元素交换和堆化操作都是在原数组上进行的。
- 非稳定排序:在交换堆顶元素和堆底元素时,相等元素的相对位置可能发生变化。
非比较排序
桶排序
考虑一个长度为 n 的数组,其元素是范围 [0,1) 内的浮点数。桶排序的流程。
- 初始化 k 个桶,将 n 个元素分配到 k 个桶中。
- 对每个桶分别执行排序(这里采用编程语言的内置排序函数)。
- 按照桶从小到大的顺序合并结果。
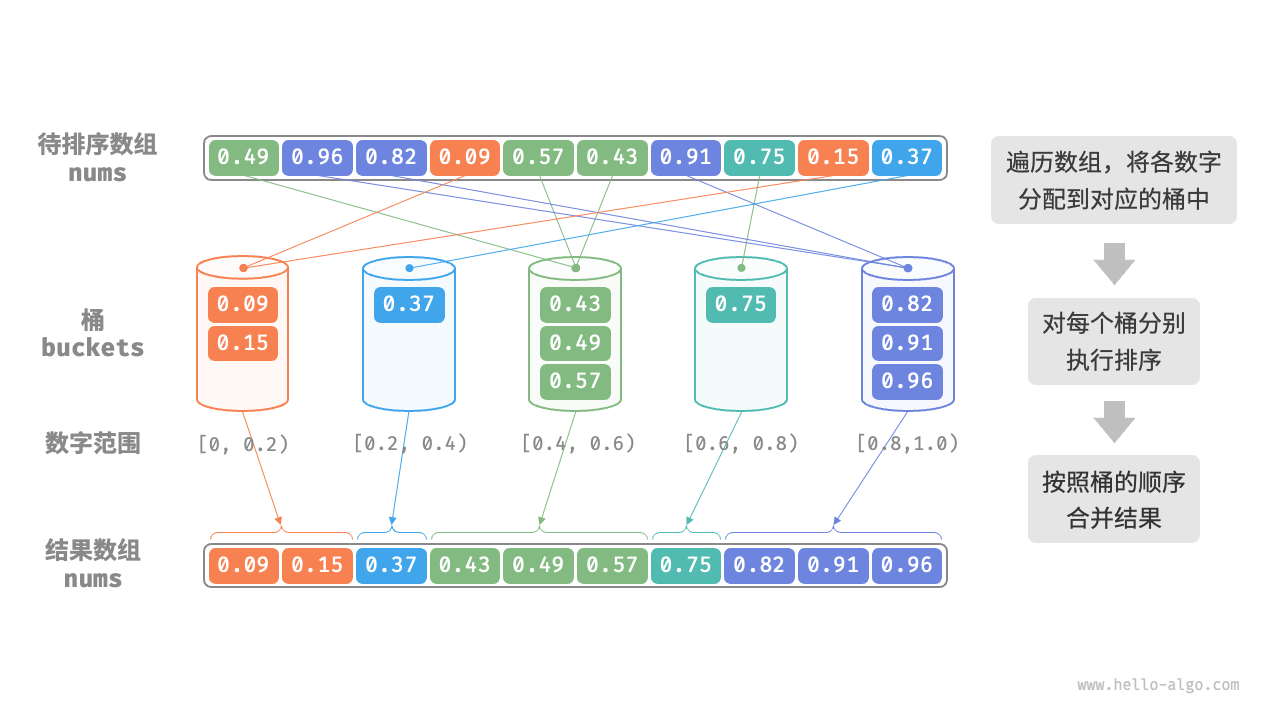
数组元素 num 的取值区间是 [0,1),所以最简单直接的映射就是
int idx = static_cast<int>(num * k);
num * k会把 “0 → k” 这个区间线性映射到 [0, k),- 再取整 (
static_cast<int>或floor) 就得到合法的桶索引 0…k–1。
为了保险起见(万一有极小的浮点误差把 num*k 变成正好等于 k),可以再做一次上界截断:
int idx = std::min(static_cast<int>(num * k), k - 1);
buckets[idx].push_back(num);
如果输入范围不是固定在 [0,1),而是任意 [minVal, maxVal),那么对应的映射公式就是
int idx = static_cast<int>((num - minVal) / (maxVal - minVal) * k);
idx = std::min(std::max(idx, 0), k - 1);
这样就能将任意区间 [minVal, maxVal) 上的数均匀分配到 k 个桶里。
/* 桶排序 */
void bucketSort(vector<float> &nums) {// 初始化 k = n/2 个桶,预期向每个桶分配 2 个元素int k = nums.size() / 2;vector<vector<float>> buckets(k);// 1. 将数组元素分配到各个桶中for (float num : nums) {// 输入数据范围为 [0, 1),使用 num * k 映射到索引范围 [0, k-1]int i = num * k;// 将 num 添加进桶 bucket_idxbuckets[i].push_back(num);}// 2. 对各个桶执行排序for (vector<float> &bucket : buckets) {// 使用内置排序函数,也可以替换成其他排序算法sort(bucket.begin(), bucket.end());}// 3. 遍历桶合并结果int i = 0;for (vector<float> &bucket : buckets) {for (float num : bucket) {nums[i++] = num;}}
}
桶排序适用于处理体量很大的数据。例如,输入数据包含 100 万个元素,由于空间限制,系统内存无法一次性加载所有数据。此时,可以将数据分成 1000 个桶,然后分别对每个桶进行排序,最后将结果合并。
- 时间复杂度为 O(n+k) :假设元素在各个桶内平均分布,那么每个桶内的元素数量为 nk 。假设排序单个桶使用 O(nklognk) 时间,则排序所有桶使用 O(nlognk) 时间。当桶数量 k 比较大时,时间复杂度则趋向于 O(n) 。合并结果时需要遍历所有桶和元素,花费 O(n+k) 时间。在最差情况下,所有数据被分配到一个桶中,且排序该桶使用 O(n2) 时间。
- 空间复杂度为 O(n+k)、非原地排序:需要借助 k 个桶和总共 n 个元素的额外空间。
- 桶排序是否稳定取决于排序桶内元素的算法是否稳定。
计数排序
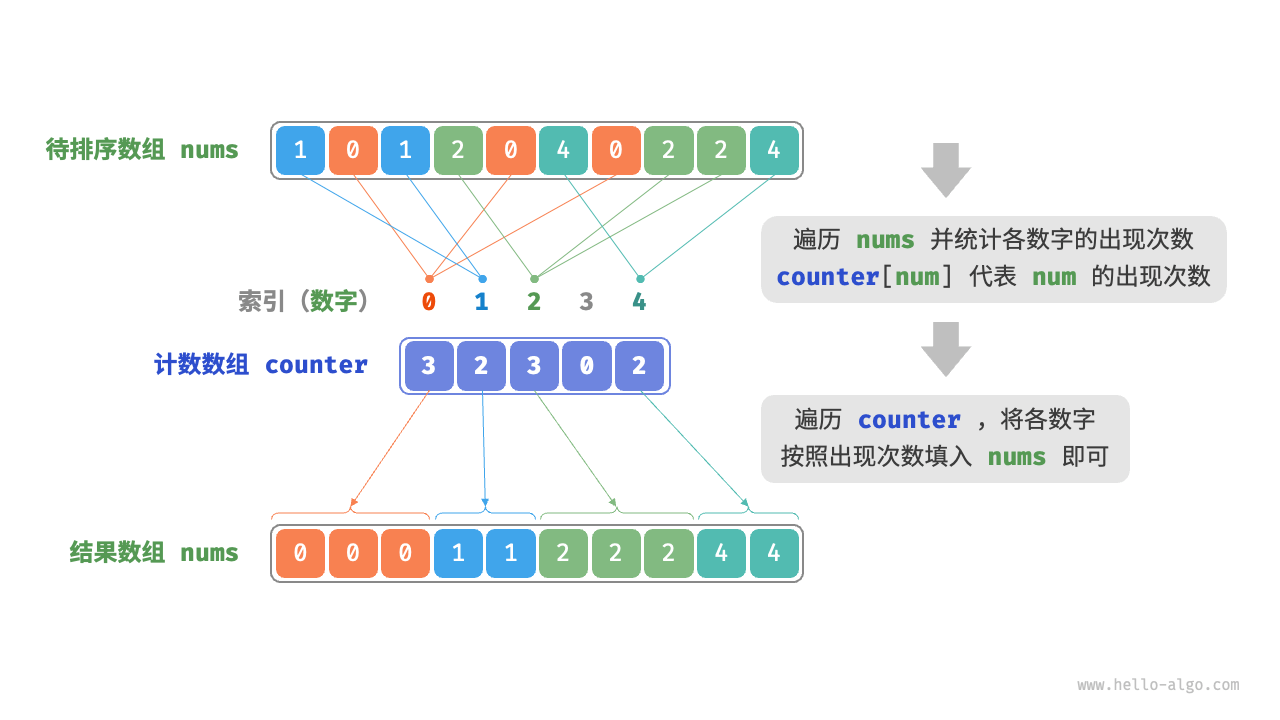
计数排序(counting sort)通过统计元素数量来实现排序,通常应用于整数数组。
- 遍历数组,找出其中的最大数字,记为 m ,然后创建一个长度为 m+1 的辅助数组
counter。 - 借助
counter统计nums中各数字的出现次数,其中counter[num]对应数字num的出现次数。统计方法很简单,只需遍历nums(设当前数字为num),每轮将counter[num]增加 1 即可。 - 由于
counter的各个索引天然有序,因此相当于所有数字已经排序好了。接下来,我们遍历counter,根据各数字出现次数从小到大的顺序填入nums即可。
/* 计数排序 */
// 简单实现,无法用于排序对象
void countingSortNaive(vector<int> &nums) {// 1. 统计数组最大元素 mint m = 0;for (int num : nums) {m = max(m, num);}// 2. 统计各数字的出现次数// counter[num] 代表 num 的出现次数vector<int> counter(m + 1, 0);for (int num : nums) {counter[num]++;}// 3. 遍历 counter ,将各元素填入原数组 numsint i = 0;for (int num = 0; num < m + 1; num++) {for (int j = 0; j < counter[num]; j++, i++) {nums[i] = num;}}
}
- 时间复杂度为 O(n+m)、非自适应排序 :涉及遍历
nums和遍历counter,都使用线性时间。一般情况下 n≫m ,时间复杂度趋于 O(n) 。 - 空间复杂度为 O(n+m)、非原地排序:借助了长度分别为 n 和 m 的数组
res和counter。 - 稳定排序:由于向
res中填充元素的顺序是“从右向左”的,因此倒序遍历nums可以避免改变相等元素之间的相对位置,从而实现稳定排序。实际上,正序遍历nums也可以得到正确的排序结果,但结果是非稳定的。
基数排序
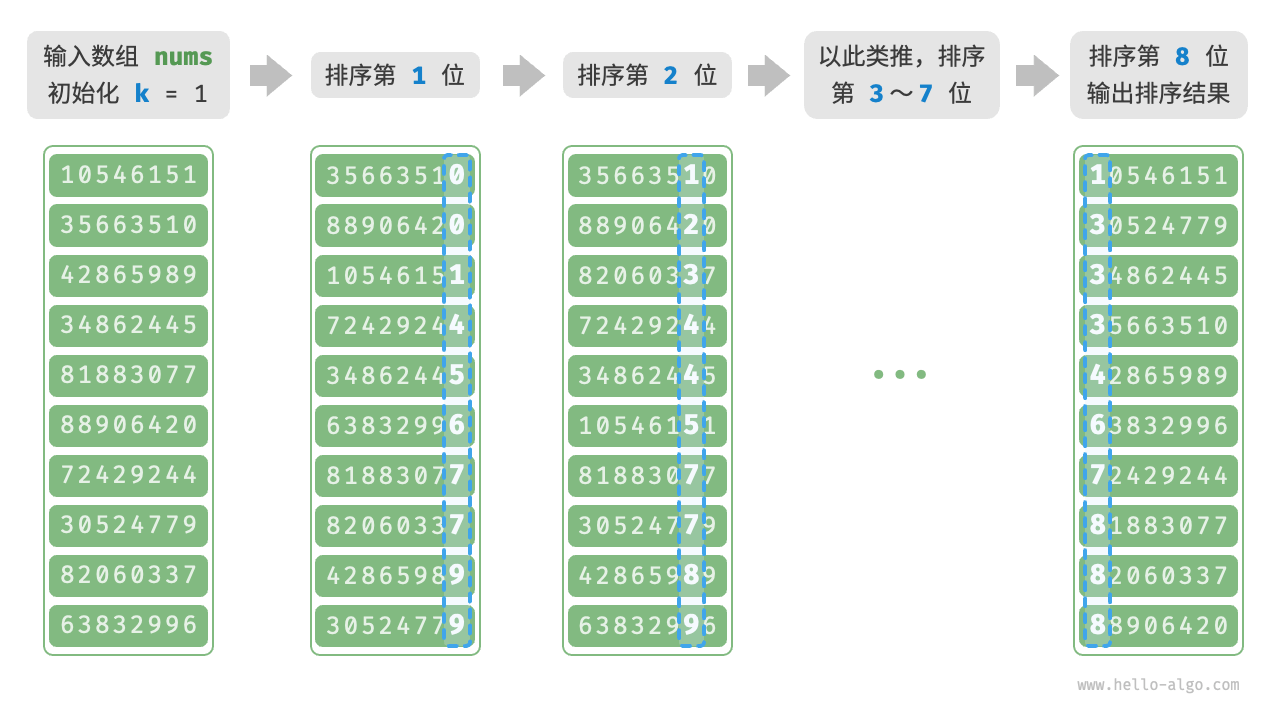
以学号数据为例,假设数字的最低位是第 1 位,最高位是第 8 位,基数排序的流程如图 11-18 所示。
- 初始化位数 k=1 。
- 对学号的第 k 位执行“计数排序”。完成后,数据会根据第 k 位从小到大排序。
- 将 k 增加 1 ,然后返回步骤
2.继续迭代,直到所有位都排序完成后结束。

/* 获取元素 num 的第 k 位,其中 exp = 10^(k-1) */
int digit(int num, int exp) {// 传入 exp 而非 k 可以避免在此重复执行昂贵的次方计算return (num / exp) % 10;
}/* 计数排序(根据 nums 第 k 位排序) */
void countingSortDigit(vector<int> &nums, int exp) {// 十进制的位范围为 0~9 ,因此需要长度为 10 的桶数组vector<int> counter(10, 0);int n = nums.size();// 统计 0~9 各数字的出现次数for (int i = 0; i < n; i++) {int d = digit(nums[i], exp); // 获取 nums[i] 第 k 位,记为 dcounter[d]++; // 统计数字 d 的出现次数}// 求前缀和,将“出现个数”转换为“数组索引”for (int i = 1; i < 10; i++) {counter[i] += counter[i - 1];}// 倒序遍历,根据桶内统计结果,将各元素填入 resvector<int> res(n, 0);for (int i = n - 1; i >= 0; i--) {int d = digit(nums[i], exp);int j = counter[d] - 1; // 获取 d 在数组中的索引 jres[j] = nums[i]; // 将当前元素填入索引 jcounter[d]--; // 将 d 的数量减 1}// 使用结果覆盖原数组 numsfor (int i = 0; i < n; i++)nums[i] = res[i];
}/* 基数排序 */
void radixSort(vector<int> &nums) {// 获取数组的最大元素,用于判断最大位数int m = *max_element(nums.begin(), nums.end());// 按照从低位到高位的顺序遍历for (int exp = 1; exp <= m; exp *= 10)// 对数组元素的第 k 位执行计数排序// k = 1 -> exp = 1// k = 2 -> exp = 10// 即 exp = 10^(k-1)countingSortDigit(nums, exp);
}
相较于计数排序,基数排序适用于数值范围较大的情况,但前提是数据必须可以表示为固定位数的格式,且位数不能过大。例如,浮点数不适合使用基数排序,因为其位数 k 过大,可能导致时间复杂度 O(nk)≫O(n2) 。
- 时间复杂度为 O(nk)、非自适应排序:设数据量为 n、数据为 d 进制、最大位数为 k ,则对某一位执行计数排序使用 O(n+d) 时间,排序所有 k 位使用 O((n+d)k) 时间。通常情况下,d 和 k 都相对较小,时间复杂度趋向 O(n) 。
- 空间复杂度为 O(n+d)、非原地排序:与计数排序相同,基数排序需要借助长度为 n 和 d 的数组
res和counter。 - 稳定排序:当计数排序稳定时,基数排序也稳定;当计数排序不稳定时,基数排序无法保证得到正确的排序结果。
结论
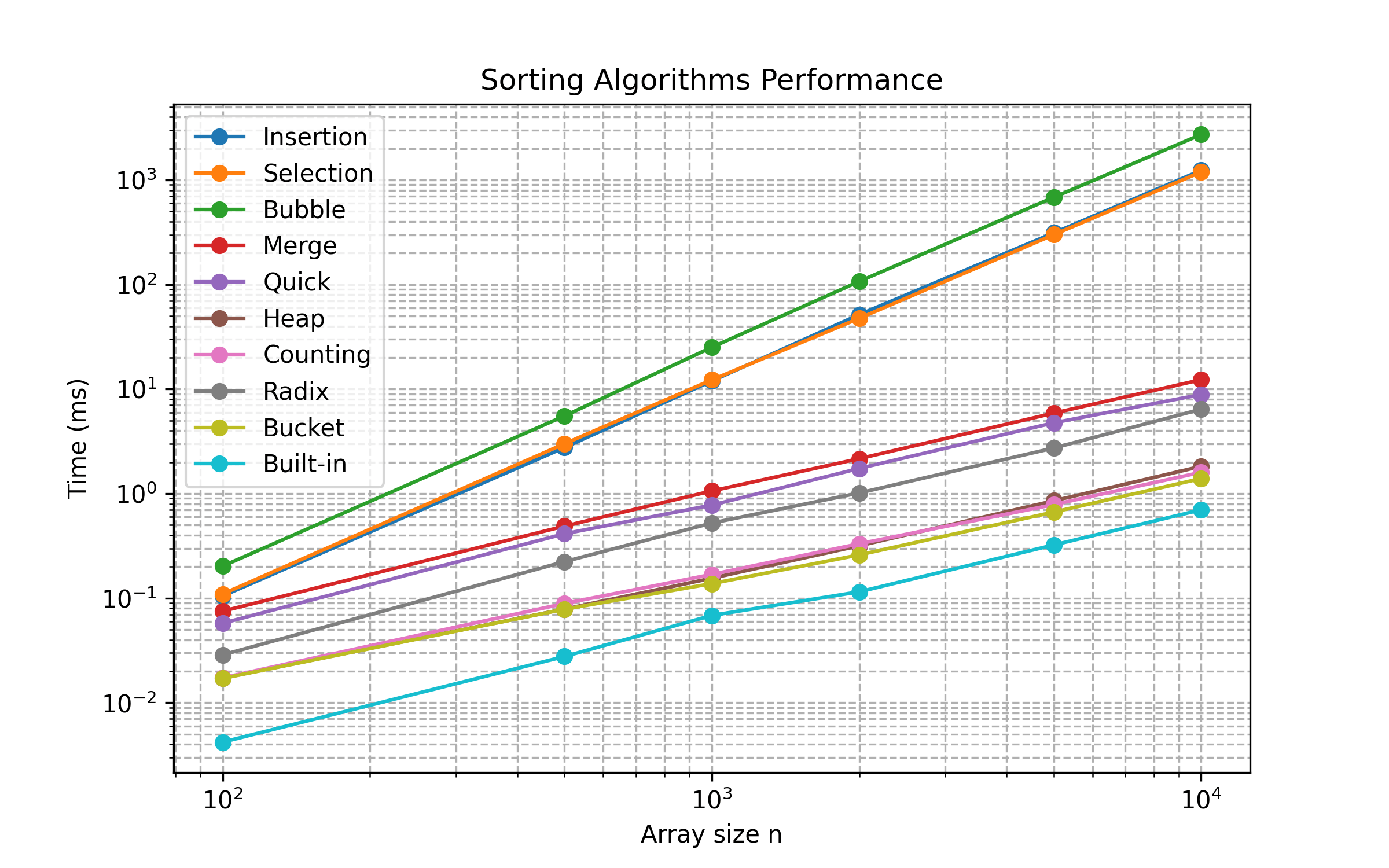
import time
import random
import matplotlib
matplotlib.use('TkAgg') # 或 'TkAgg'import matplotlib.pyplot as plt # 10 common sorting algorithms
def insertion_sort(arr): a = arr.copy() for i in range(1, len(a)): key = a[i] j = i - 1 while j >= 0 and a[j] > key: a[j + 1] = a[j] j -= 1 a[j + 1] = key return a def selection_sort(arr): a = arr.copy() for i in range(len(a)): min_idx = i for j in range(i+1, len(a)): if a[j] < a[min_idx]: min_idx = j a[i], a[min_idx] = a[min_idx], a[i] return a def bubble_sort(arr): a = arr.copy() for i in range(len(a)): for j in range(len(a) - i - 1): if a[j] > a[j + 1]: a[j], a[j + 1] = a[j + 1], a[j] return a def merge_sort(arr): if len(arr) <= 1: return arr mid = len(arr) // 2 left = merge_sort(arr[:mid]) right = merge_sort(arr[mid:]) return merge(left, right) def merge(left, right): result = [] i = j = 0 while i < len(left) and j < len(right): if left[i] < right[j]: result.append(left[i]); i += 1 else: result.append(right[j]); j += 1 result.extend(left[i:]); result.extend(right[j:]) return result def quick_sort(arr): if len(arr) <= 1: return arr pivot = arr[0] less = [x for x in arr[1:] if x <= pivot] greater = [x for x in arr[1:] if x > pivot] return quick_sort(less) + [pivot] + quick_sort(greater) def heap_sort(arr): import heapq a = arr.copy() heapq.heapify(a) return [heapq.heappop(a) for _ in range(len(a))] def counting_sort(arr): if not arr: return arr min_val, max_val = min(arr), max(arr) count = [0] * (max_val - min_val + 1) for num in arr: count[num - min_val] += 1 res = [] for i, c in enumerate(count): res.extend([i + min_val] * c) return res def radix_sort(arr): if not arr: return arr def counting_radix(a, exp): output = [0]*len(a) count = [0]*10 for num in a: count[(num//exp) % 10] += 1 for i in range(1,10): count[i] += count[i-1] for num in reversed(a): idx = (num//exp) % 10 output[count[idx]-1] = num count[idx] -= 1 return output max_val = max(arr) exp = 1 a = arr.copy() while max_val // exp > 0: a = counting_radix(a, exp) exp *= 10 return a def bucket_sort(arr): if not arr: return arr min_val, max_val = min(arr), max(arr) bucket_count = 10 interval = (max_val - min_val) / bucket_count buckets = [[] for _ in range(bucket_count)] for num in arr: idx = int((num - min_val) / interval) if idx == bucket_count: idx -= 1 buckets[idx].append(num) res = [] for b in buckets: res.extend(sorted(b)) return res def builtin_sort(arr): return sorted(arr) # test parameters
sizes = [100, 500, 1000, 2000, 5000, 10000]
algos = [insertion_sort, selection_sort, bubble_sort, merge_sort, quick_sort, heap_sort, counting_sort, radix_sort, bucket_sort, builtin_sort]
names = ['Insertion', 'Selection', 'Bubble', 'Merge', 'Quick', 'Heap', 'Counting', 'Radix', 'Bucket', 'Built-in']
times = {n: [] for n in names} for n in sizes: arr = [random.randint(0, n) for _ in range(n)] for fn, nm in zip(algos, names): t0 = time.perf_counter() fn(arr) t1 = time.perf_counter() times[nm].append((t1 - t0)*1000) # plot
plt.figure(figsize=(8,5))
for nm in names: plt.plot(sizes, times[nm], marker='o', label=nm)
plt.xscale('log'); plt.yscale('log')
plt.xlabel('Array size n')
plt.ylabel('Time (ms)')
plt.title('Sorting Algorithms Performance')
plt.legend()
plt.grid(True, which='both', ls='--') # save to file to avoid backend issue
plt.savefig('sorting_performance.png', dpi=300)
print("Plot saved as sorting_performance.png") # optionally display
plt.show()
决定排序算法稳定性的关键因素
-
相等元素的比较和交换逻辑
-
稳定排序:当两个元素相等时,算法不会交换它们或改变它们的相对位置
-
不稳定排序:当两个元素相等时,算法可能会改变它们的相对位置
-
-
排序过程中元素移动/交换的方式
-
如果算法中的元素移动方式会导致相等元素的相对顺序发生变化,则该算法是不稳定的
-
特别是当算法进行跨距离的元素交换或移动时,更容易导致不稳定性
-
-
算法实现细节
-
有些算法(如快速排序)在标准实现中是不稳定的,但可以通过特定的修改变为稳定排序
-
这些修改通常会增加额外的时间或空间复杂度
-
稳定性分析
稳定的排序算法
1. 冒泡排序 (Bubble Sort)
-
稳定原因:只有当前一个元素严格大于后一个元素时才交换
-
代码中的体现:
if (arr[j] > arr[j+1]) swap(arr[j], arr[j+1]); -
关键判断:使用
>而非>=,确保相等元素不会被交换
for (int i = 0; i < n-1; i++) {for (int j = 0; j < n-i-1; j++) {// 只有当前元素大于后一个元素时才交换,保证稳定性if (arr[j] > arr[j+1]) { swap(arr[j], arr[j+1]);}}
}
2. 插入排序 (Insertion Sort)
- 稳定原因:在找插入位置时,相等元素不会继续向前查找
- 代码中的体现:
while (j >= 0 && arr[j] > key) { arr[j+1] = arr[j]; j--; } - 关键判断:使用
>而非>=,确保相等元素的相对顺序保持不变
for (int i = 1; i < n; i++) {int key = arr[i];int j = i - 1;// 关键:使用 > 而非 >=,确保当遇到相等元素时停止移动while (j >= 0 && arr[j] > key) {arr[j + 1] = arr[j];j--;}arr[j + 1] = key;
}
3. 归并排序 (Merge Sort)
- 稳定原因:合并两个已排序序列时,相等元素的选取有固定的顺序
- 代码中的体现:
if (arr[i] <= arr[j]) { temp[k++] = arr[i++]; } else { temp[k++] = arr[j++]; } - 关键判断:使用
<=而非<处理左侧数组元素,确保在相等时选择左侧元素
// 合并两个有序子数组的函数
void merge(int arr[], int left, int mid, int right) {// ... 初始化临时数组和指针 ...while (i <= mid && j <= right) {// 关键:使用 <= 确保在元素相等时优先选择左侧数组的元素// 这保证了相同元素的相对顺序不变if (arr[i] <= arr[j]) {temp[k++] = arr[i++];} else {temp[k++] = arr[j++];}}// ... 处理剩余元素 ...
}
4. 计数排序 (Counting Sort)
- 稳定原因:处理相同值的元素时按照它们在原始数组中出现的顺序
- 关键实现:从右向左扫描原数组并放入结果数组,或使用累加频率数组
void countingSort(int arr[], int n) {// ... 初始化计数数组和结果数组 ...// 计算每个元素的频率for (int i = 0; i < n; i++) {count[arr[i]]++;}// 计算累加频率for (int i = 1; i <= max; i++) {count[i] += count[i-1];}// 关键:从右向左遍历原数组,保证稳定性// 对于相同的元素,先出现的将被放置在较高位置for (int i = n-1; i >= 0; i--) {output[count[arr[i]]-1] = arr[i];count[arr[i]]--;}
}
不稳定的排序算法
1. 选择排序 (Selection Sort)
- 不稳定原因:可能会进行相隔较远的元素交换
- 关键问题代码:对找到的最小元素进行交换而非移动
for (int i = 0; i < n-1; i++) {int min_idx = i;for (int j = i+1; j < n; j++) {if (arr[j] < arr[min_idx]) {min_idx = j;}}// 问题点:这里的交换可能会改变相等元素的相对顺序// 例如[4,2,3,2,1]中,第一次交换后两个2的相对位置就变了swap(arr[i], arr[min_idx]);
}
2. 快速排序 (Quick Sort)
- 不稳定原因:分区过程中的交换可能改变相等元素的相对顺序
- 关键问题代码:分区函数中的元素交换
int partition(int arr[], int low, int high) {int pivot = arr[high];int i = low - 1;for (int j = low; j < high; j++) {if (arr[j] <= pivot) {i++;// 问题点:这里的交换可能会改变与pivot相等元素的相对顺序swap(arr[i], arr[j]);}}swap(arr[i+1], arr[high]);return i+1;
}
3. 堆排序 (Heap Sort)
- 不稳定原因:堆调整过程中的元素交换不考虑元素相等情况
- 关键问题代码:下沉操作中的交换
void heapify(int arr[], int n, int i) {int largest = i;int left = 2*i + 1;int right = 2*i + 2;if (left < n && arr[left] > arr[largest])largest = left;if (right < n && arr[right] > arr[largest])largest = right;if (largest != i) {// 问题点:这里的交换不考虑相等元素的原始顺序// 如果有多个子节点与父节点相等,选择哪个交换将影响稳定性swap(arr[i], arr[largest]);heapify(arr, n, largest);}
}
4. 希尔排序 (Shell Sort)
- 不稳定原因:跳跃式的比较和交换会打乱相等元素的相对顺序
- 关键问题代码:跨距离的插入排序
void shellSort(int arr[], int n) {for (int gap = n/2; gap > 0; gap /= 2) {for (int i = gap; i < n; i++) {int temp = arr[i];int j;// 问题点:由于gap大于1,相等元素可能会被错过或交换顺序for (j = i; j >= gap && arr[j-gap] > temp; j -= gap) {arr[j] = arr[j-gap];}arr[j] = temp;}}
}
使不稳定排序变为稳定排序的方法
-
附加索引信息
// 为元素添加原始位置信息 struct Element {int value;int originalIndex;// 比较运算符重载bool operator<(const Element& other) const {if (value == other.value)return originalIndex < other.originalIndex; // 保持原始顺序return value < other.value;} };void stableSort(int arr[], int n) {// 创建带索引的元素数组Element* elements = new Element[n];for (int i = 0; i < n; i++) {elements[i].value = arr[i];elements[i].originalIndex = i;}// 使用任意排序算法// 由于比较运算符的重载,相等元素将保持原始顺序sort(elements, elements + n);// 将排序结果复制回原数组for (int i = 0; i < n; i++) {arr[i] = elements[i].value;}delete[] elements; } -
修改比较逻辑
// 三路快排示例 - 处理相等元素以保持稳定性 void threeWayQuickSort(int arr[], int low, int high) {if (low >= high) return;int lt = low, gt = high;int pivot = arr[low];int i = low + 1;while (i <= gt) {if (arr[i] < pivot) {swap(arr[lt++], arr[i++]);} else if (arr[i] > pivot) {swap(arr[i], arr[gt--]);} else {// 相等元素不交换,保持原有顺序i++;}}threeWayQuickSort(arr, low, lt - 1);threeWayQuickSort(arr, gt + 1, high); }
稳定性的实际应用
稳定排序在以下情况特别重要:
-
多级排序
// 使用稳定排序实现多级排序 // 例如:按照分数排序,分数相同的按照学号排序 void multiLevelSort(Student students[], int n) {// 首先,按照学号排序(次要关键字)// 使用稳定的排序算法如归并排序mergeSort(students, 0, n-1, compareByStudentId);// 然后,按照分数排序(主要关键字)// 由于使用了稳定排序,分数相同的学生将保持按学号排序的顺序mergeSort(students, 0, n-1, compareByScore); } -
保留用户自定义顺序 在用户界面应用中,当多个元素具有相同优先级时,保持它们的原始排列顺序可以提供更一致的用户体验。
-
数据可视化和报表生成 当相等数据的显示顺序对用户体验有影响时,稳定排序可以确保一致的呈现方式,增强用户对数据的理解和分析。
现实排序库的实现 (o4mini)
在工业级、通用排序库里,最常见的组合是“归并(或归并变种)+小规模时用插入”,主要原因有以下几点:
1. 插入排序(Insertion Sort)在小规模或近乎有序时最快
- 低常数开销:插入排序的逻辑非常简单,几乎只做一趟向前比较/搬移。对于 n≤16 甚至更小的规模,其函数调用、递归或复杂分支带来的开销往往高于算法本身的比较和交换成本。
- 适应性强:对于已经“部分有序”的数据(例如几乎排好序的数组、或者只有少量乱序),插入排序能接近线性表现 O(n+f),而普通的 O(n log n) 算法就难以利用这点优势。
- 简单易实现、易优化:很容易写出分支预测友好、基于移动(memmove)的高性能版本。
因此主流的各种分治式排序(快速、归并、希尔、堆……)在分到一定阈值时,普遍会切换成插入排序来“收尾”。
2. 归并排序(Merge Sort)及其变种的优势
- 最坏时间复杂度稳定:总是 O(n log n),不会像快速排序那样在某些输入(例如几乎有序、极端分布)退化到 O(n²)。
- 稳定性:天然保持相等元素的相对先后次序。对于需要稳定排序(比如数据库多字段排序)几乎是唯一选择。
- 外部排序友好:归并可以在磁盘/SSD等外存上分批读写,很容易做 k 路归并;而其他比较排序就不那么自然。
- 易于并行化、多路归并:现代 CPU 的向量化、NUMA 内存架构,都能通过分块归并更好利用。
所以像 C++ 的 std::stable_sort 底层就是归并;Java、Python 等语言的内置稳定排序(Java 的 TimSort、Python 的 Timsort)都是在归并的基础上,又加入了对已有“递增/递减 runs” 的“天然合并”+“galloping”(快速跳跃)技术。
3. 为什么不广泛用“其他”算法?
- 快速排序(Quick Sort):常数因子小、平均最快,但最差 O(n²),需额外防护(随机化、三数取中、切换堆排序)才能保证线性对数级别。
- 堆排序(Heap Sort):最坏 O(n log n)、不占额外空间,但常数因子较大,内存访问不连贯,分支预测差,实际比归并/快速都慢。
- 希尔排序(Shell Sort):对一般类型不稳定,增量序列调优困难,对各种分布的普适性和可预测性不如归并/快速。
- 基数排序(Radix Sort):虽然能到 O(n) 级别,但对类型(整数、浮点)、键长度/位宽敏感,需要额外内存,不如归并在接口上通用。
4. 实际库里常见的“混合套路”
- C++
std::sort:典型的 Introsort ——先快速排序,若递归层数过深再切堆排序,分到小块时切插入排序。 - C++
std::stable_sort:归并排序+分块优化+插入排序收尾。 - Java
Arrays.sort(Object[])& Pythonlist.sort():都是 TimSort(归并+插入+“galloping”合并),利用已有有序片段,对典型数据集(部分排序、少量乱序)非常快。
TimSort
小结:
- 插入排序 ——「小规模/近乎有序最优,常数开销极小」。
- 归并(及变种) ——「最坏 O(n log n)、稳定、外部/并行友好、可利用已有 runs」。
- 其他算法 或要么在常数因子上不占优,要么最坏情况不够可靠,要么通用性不足。
- 因此成熟库都会把它们“拼”在一起,既能兼顾最坏情况的理论保证,又能在常见场景下跑出接近线性的超高性能。
参考
- hello算法
- 算法第四版
- TimSort