如何评价 DeepSeek 的 DeepSeek-V3 模型?
DeepSeek-V3 是由杭州 DeepSeek 公司于 2024 年 12 月 26 日发布的一款开源大语言模型,其性能和创新技术在国内外引起了广泛关注。从多个方面来看,DeepSeek-V3 的表现令人印象深刻,具体评价如下:
-
性能卓越
DeepSeek-V3 拥有 6710 亿参数和 370 亿激活参数,采用 MoE(混合专家)架构,并在 14.8 万亿 token 上进行了预训练。在多项基准测试中,DeepSeek-V3 的表现超越了其他开源模型如 Qwen2-72B 和 Llama-3.1-405B,同时与顶尖的闭源模型 GPT-4o 和 Claude-3.5-Sonnet 相媲美。例如,在 MMLU-Pro、GPQA-Diamond 和数学推理任务(如 AIME 2024 和 MATH-500)中,DeepSeek-V3 的准确率均达到行业领先水平。 -
技术优势
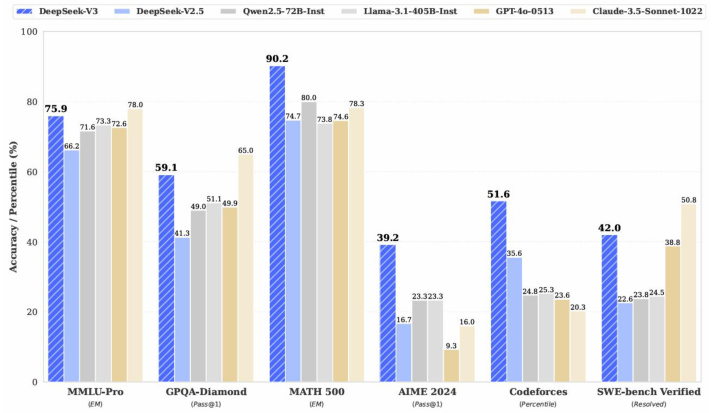
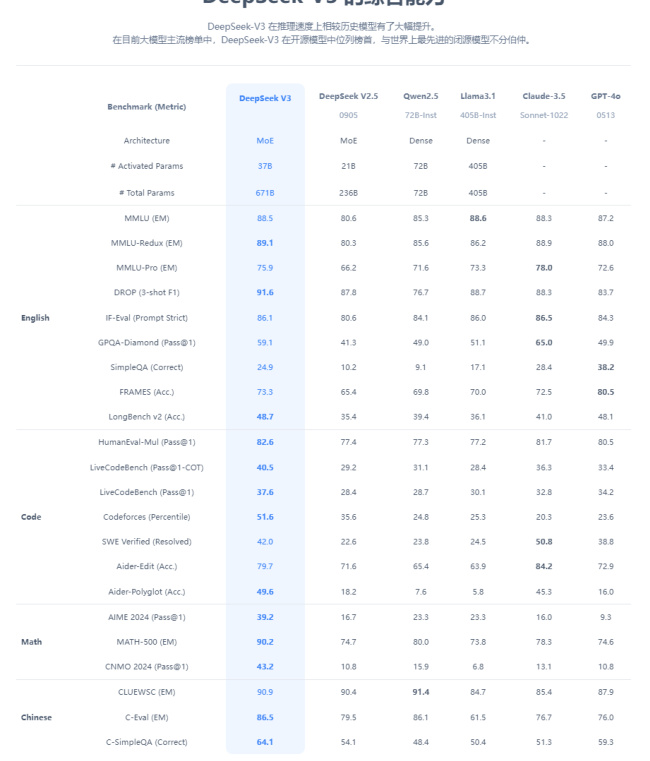
DeepSeek-V3 在多个领域展现了强大的能力:- 知识类任务:在 MMLU、HumanEval 等任务中表现优异,超越了前代模型 DeepSeek-V2.5。
- 长文本处理:在长文本测评(如 DROP、FRAMES 和 LongBench)中,DeepSeek-V3 的表现优于其他模型。
- 代码生成与算法推理:在 Codeforces 和 SWE-bench 验证等代码类任务中,DeepSeek-V3 表现突出,甚至逼近 Claude-3.5-Sonnet 的水平。
- 数学能力:在数学推理任务中,DeepSeek-V3 完全超越了 GPT-4o,展现了其在复杂逻辑推理中的强大能力。
-
成本效益
DeepSeek-V3 的训练成本显著低于同类模型。据报道,其训练成本仅为 GPT-4o 的二十分之一,同时生成速度提升了 200%,达到每秒 60 token 的吞吐量。这种低成本高效率的特点使其成为企业部署 AI 模型时的理想选择。 -
开源与社区支持
DeepSeek-V3 是一款开源模型,允许用户自由商用和定制化开发。这一特性不仅推动了 AI 技术的普及,还促进了社区的协作与创新。此外,DeepSeek 提供了详细的文档和技术报告,帮助开发者更好地理解和应用该模型。 -
应用场景广泛
DeepSeek-V3 已被广泛应用于多种场景,包括办公自动化、客户服务、数据分析、代码生成等。其在前端开发、中文搜索和角色扮演等领域的表现也得到了显著提升。此外,DeepSeek-V3 还被用于教育领域,如全国高中数学联赛中的表现优于其他模型。 -
创新点
DeepSeek-V3 的成功得益于多项技术创新:- MoE 架构:通过将问题空间划分为同质区域并使用多个专家子网络进行处理,提高了模型的效率和推理能力。
- 多 token 预测(MTP)技术:提升了模型的推理速度和上下文理解能力。
- 低精度训练框架:降低了内存占用和计算开销,同时保持了高水平性能。
-
市场反响
DeepSeek-V3 的发布引发了全球范围内的关注。它不仅登顶了 App Store 的免费应用排行榜,还在多个基准测试中超越了国际顶尖模型。此外,DeepSeek-V3 的低成本特性和高性能使其成为 AI 应用落地的重要驱动力。
DeepSeek-V3 是一款兼具性能、成本效益和技术创新的开源大语言模型。它不仅在多项基准测试中展现了卓越的能力,还通过低成本和开源特性推动了 AI 技术的普及与应用。无论是从技术层面还是市场反响来看,DeepSeek-V3 都标志着国产大模型技术迈向了一个新的高度。